1.本发明涉及自动驾驶技术领域,更具体地,涉及一种基于激光雷达和事件相机融合的深度估计方法。
背景技术:
2.近年来,无人驾驶技术逐渐成为国内外高校和企业的研究热点,因其在商业应用测试中的频频亮相引起大众的关注。其中,信息感知系统是无人车自动驾驶的关键基础,是保证无人车安全稳定,无碰撞正常行驶的前提。随着近年来车载感知传感器精度及集成度的提高,越来越多的传感器被部署在无人驾驶汽车平台上,以精细的感知外界环境,其中激光雷达以其高精度的距离探测,信息的丰富性,以及相较视觉摄像头具有的对光照变换不敏感的高可靠性等优势,逐渐成为无人自动驾驶汽车上主要的传感器之一。然而,由于环境的复杂性以及感知任务的高准确性要求,往往需要高分辨率的稠密点云数据。高线束激光雷达往往具有高昂的成本,这极大地限制了其在行业的广泛应用和部署。如何基于低线束激光雷达获得稠密的点云数据和深度信息是亟待解决的关键问题。
3.相比于传统的视觉相机,事件相机是一种新型的低延迟低冗余的传感器,具有高动态范围,高分辨率的特性,在自动驾驶车辆高速运动中不会产生运动模糊。因此,高分辨率的事件相机能够为点云提供稠密的环境信息。但是事件相机无法直接获取深度信息,因此需要点云数据为事件流提供先验的深度信息。综上所述,将低线束激光雷达与事件相机进行有效融合是一种潜在的解决方案。
4.到目前为止,有许多研究集中于组合不同的传感器来进行数据融合,获取高质量的感知信息,从而实现自动驾驶相关场景中的环境感知任务,包括物体目标的检测、分类、跟踪等。由于利用低线束激光雷达所获得的三维激光点云非常稀疏,将三维激光点云投影到二维平面上,物体与物体之间的实际间隔距离会产生扭曲,同时三维激光点云在空间分布中是随机且散乱的,无法通过直接的地址索引或者迭代器获取到空间坐标点。而事件相机仅对环境光线变化的梯度进行响应,数据以流的形式输出。在实际场景中,往往是环境中的物体的几何边缘触发事件,而事件流不能覆盖整个物体的表面,同时环境中其他微小的光线变化会导致许多噪声。因此如何利用多传感器来进行数据融合,获取高质量的感知信息仍有许多问题有待解决。
技术实现要素:
5.本发明为克服上述现有技术中的缺陷,提供一种基于激光雷达和事件相机融合的深度估计方法,实现了自动驾驶车辆室外高速运动等复杂场景下的深度估计。
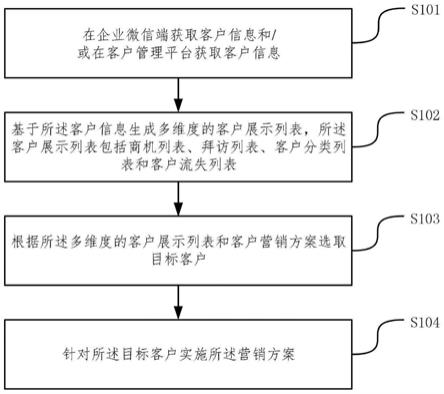
6.为解决上述技术问题,本发明采用的技术方案是:一种基于激光雷达和事件相机融合的深度估计方法,包括以下步骤:
7.s1.通过激光雷达获取三维点云数据,通过事件相机获取事件流数据;对于点云数据,进行去噪操作;对于事件相机生成的事件流数据,进行时间片截取、事件流降噪、事件流
膨胀操作;
8.s2.根据事件相机的视角,对激光雷达生成的点云进行提取,以获得目标点云;
9.s3.基于事件的空间扫描,实现对事件流数据的反投影,以获得事件流数据的三维表示;
10.s4.对点云数据使用基于加权欧式距离的密度聚类后进行三维目标建模;
11.s5.使用bowyer-watson算法对构造立体表面模型的聚类簇中所有空间坐标点进行合理的三角剖分;
12.s6.对建模的目标物体表面以及三维化的事件进行快速相交检测并实现空间坐标点重建,完成事件深度估计;
13.s7.对事件在三维空间中进行空间坐标点重建,完成事件信息和点云的前端融合,最后通过深度扩张和孔洞填充的方法,对局部稀疏的点云进行深度填充。
14.本发明仅使用事件相机和激光雷达相融合,不需要依赖于定位信息和位姿估计。通过充分地利用事件相机和激光雷达传感器的特性,可以实现自动驾驶车辆室外高速运动等复杂场景下的深度估计。本发明相比于依赖单一传感器的深度估计方法,获得了令人满意的结果和性能提升。
15.进一步的,所述的进行时间片段截取具体包括:首先以激光雷达的时间戳为基础,以设定的时间长度来截取事件流;假设使用的激光雷达输出点云数据的频率为f,假设某一帧三维激光点云的时间戳为t,得到上一帧的激光点云时间戳为t-1/f秒,则在接近时刻t的某一段极小的时间窗口δt内,事件相机所产生的事件流所对应的环境几何信息,与t时刻得到的三维激光点云所建立的模型一致;然后,利用时间窗口δt来截断事件流并投影到二维像素平面上,以时刻 t为基准,选择响应时间最接近时刻t的事件为该位置的最终输出事件;事件流 e
t
则表示为四元组(u,v,t,p)的集合,即:
16.e
t
={(u,v,t,p)|t-δt<t<t,0<δt<1/fs}
ꢀꢀ
(1)
17.式中,(u,v)表示像素位置,t表示时间戳,p表示光强度变化的极性。
18.进一步的,所述的事件流降噪具体包括:s
uv
为事件点坐标为(u,v)、大小为 m
×
n的滤波器窗口,计算每一个事件点e
t
在局部范围s
uv
内的均值;使用极性p 的绝对值|p|进行卷积运算;根据噪声在二维平面上的稀疏特性,引入一个阈值 e
th
,提出的改进均值滤波公式如下:
[0019][0020]
当局部滤波器窗口内均值超过e
th
,那么保留该位置的事件信息;反之则被认为是噪声而去除;g(s,t)表示s
uv
中的事件极性。
[0021]
进一步的,所述的事件流膨胀具体包括:利用数字图像处理中的膨胀操作对事件流信息进行增强;定义一个结构元素s,利用结构元素b在二维平面化的事件e
t
上进行移动,当结构元素s移动到某个像素坐标位置(x,y)上时,如果结构元素s与二维平面化的事件e
t
的交集不为空集,那么将像素坐标位置(x,y)上的信息修改成一个事件(x,y,t,1);通过控制结构元素s在二维平面化的事件e
t
上进行移动的次数,约束事件信息膨胀的范围大小,得到膨胀处理后的事件流ed:
[0022][0023]
进一步的,所述的步骤s2具体包括:通过将三维空间中的激光点云投影到事件相机的二维像素平面上的方式,利用像素坐标的阈值进行约束,筛选符合要求的激光点云;采取小孔成像模型,利用提供的事件相机内部参数以及外部参数,计算三维激光点云的二维像素平面坐标,保留像素坐标落在事件相机像素平面的空间坐标点;同时,基于随机抽样一致ransac算法对三维激光点云进行地面点云提取并去除弧线影响。
[0024]
进一步的,所述的步骤s3具体包括:将二维平面上的事件流信息进行反投影实现空间扫描,然后根据对事件相机建立的小孔成像模型进行逆运算,得到单一事件对应的空间三维归一化坐标;再结合事件相机中心坐标点,计算事件的方位向量。
[0025]
进一步的,所述的步骤s4具体包括:
[0026]
s41.基于加权欧式距离的三维点云密度聚类;使用dbscan密度聚类算法对三维激光点云进行点集划分,在进行三维激光点云密度聚类时,并非直接使用欧氏距离,而是在欧式距离的基础上考虑水平距离和竖直距离的不同权重,具体的距离公式如下:
[0027][0028]
式中,a,b为不同的空间坐标点,为三维笛卡尔坐标系中不同坐标轴的权重;为了使得聚类过程中能够将同一位置上不同高度的空间坐标点归类在同一聚类簇中,设置的权重条件为:
[0029]wx
=wy>wz;
ꢀꢀꢀ
(5)
[0030]
s42.三维目标建模;利用立体平面进行事件的深度估计,也就是通过计算事件的方位向量与空间中的平面相交点得到对应的三维坐标;利用每一个聚类簇求它的凸包,得到目标物体最外部的表面的粗略表示,为了能够方便快速地进行方位向量与平面相交检测计算,对聚类簇的凸包进行三角剖分,利用各不相交的三角面片来表示,从而,目标物体的表面上任意一个位置都能用唯一的最小三角面片进行计算得到。
[0031]
进一步的,在所述的步骤s42中,为了使构建的目标表面模型能够充分表示实际的目标表面,在构建表面模型的时候,在点云聚类簇中增加一些辅助构造表面模型的虚拟点云,其x,y坐标与实际的点云保持一致,但z坐标需要重新计算;具体的计算方法包括:
[0032]
假设某一个点云聚类簇为p
cluster
={(xi,yi,zi)|i=1,2,
…
,m},对于用于辅助计算虚拟点坐标的实际坐标点pi(xi,yi,zi)∈p
cluster
,该点到激光雷达的距离为d=xi;利用三角函数、已知的激光雷达安装高度h和激光雷达的角分辨率α,计算到聚类簇p
cluster
中最高的点云线束距离上方激光线束的高度h4:
[0033][0034]
同理,计算聚类簇p
cluster
中最低的点云线束距离下方激光线束的高度h1:
[0035][0036]
为了保证在竖直方向上空间的覆盖程度和避免相互重叠,实现增加虚拟点云的时候,使用激光雷达角分辨率的一半进行计算,并考虑道路环境中目标物体的高度,加入上限约束和下限约束;所以,最终的高度计算公式如下:
[0037][0038][0039]
进一步的,所述的步骤s6中的快速相交检测的方法具体包括:
[0040]
从事件相机的中心出发,以事件相机中心指向图像平面上的事件的归一化向量为方向,在三维空间环境中进行扫描;
[0041]
在空间扫描的过程中,需要判断以及计算方位向量和空间环境中的目标表面是否存在交点;在利用三角剖分对目标物体表面进行建模的前提下,利用三角面的顶点(v0,v1,v2)来构建三角面的参数方程;因此,任意给定一个三维空间中的目标点坐标p,假如该点落在某个三角面中,利用重心坐标系表示:
[0042]
p=a(v
1-v0) b(v
2-v0) v0[0043]
=(1-a-b)v0 av1 bv2ꢀꢀꢀ
(10)
[0044]
式中,a>0,b>0,a b<1;式(10)表示三角面中任意一点,通过以任意一个顶点作为起点的相邻的两条边作为向量的加权和进行表示;
[0045]
事件投影公式表示为:
[0046]rcp
=c dt
ꢀꢀꢀ
(11)
[0047]
式中,c表示相机中心坐标,d为归一化向量,t为待求解的向量长度;
[0048]
因此,判断和计算方位向量是否与某一个三角面相交的问题,转换成了求解公式(10)以及公式(11)的联立方程:
[0049]
c dt=(1-a-b)v0 av1 bv2ꢀꢀꢀ
(12)
[0050]
将公式进行移项并整理为矩阵形式,最终可得到求解方程为∶
[0051][0052]
式中,e1=v
1-v0,e2=v
2-v0,e3=c-v0。
[0053]
进一步的,所述的步骤s7具体包括:
[0054]
s71.空间坐标点重建:首先,利用事件的方位向量以及目标物体表面模型进行深度估计,需要准确地判断导致该事件响应的原目标表面;通过利用激光点云聚类簇的空间范围对事件的方位向量进行约束,筛选出距离激光雷达和事件相机最近的、与事件的方位向量相交的目标物体表面模型,然后进行深度计算和重建该三维空间点;针对深度的空间约束,具体的约束条件如下:
[0055][0056]
式中,aq为求出与三维事件射线相交的聚类簇;
[0057]
在筛选出目标物体表面模型并进行初步深度计算之后,将该目标物体的三维激光点云进行二维投影,然后利用德劳内三角剖分,对二维投影后的三维激光点云进行三角剖分,进一步利用三维空间射线与三角面相交检测的算法进行深度计算和重建该三维空间点;
[0058]
s72.深度扩张:首先,具有深度信息的点云附近的空白像素最有可能与点云深度接近甚至相同,因此借助已有的深度信息对这些空白像素进行深度扩张;根据点云二维投影之后的稀疏特点和激光雷达线束的扫描特性,通过设计一个自定义内核,利用数字图像处理技术中的膨胀操作,对二维点云附近的像素进行深度估计;
[0059]
s73.孔洞填充:在进行深度扩张之后,由于扩张的谨慎操作,并不会大规模地进行深度填充,深度图中点云视野之间仍然存在许多空白像素;对于深度图中的较小的孔洞,通过连接空白像素附近的目标物体边缘深度信息进行深度估计,利用形态学中的关闭操作对较小孔洞进行关闭;对于深度图中的较大孔洞,使用设定大小的内核进行深度填充。
[0060]
与现有技术相比,有益效果是:
[0061]
1、本发明不同于现有工作侧重于解决室内环境或者近距离三维重建,本方法侧重于室外开放道路场景,解决中远距离的深度估计和点云稠密化问题,仅使用单目事件相机和单个激光雷达,并且不依赖于精确的定位信息和位姿估计,而是根据传感器特性以及采集到的数据完成深度估计;
[0062]
2、本发明提出利用光线投射的原理,通过将事件进行反投影,实现基于事件的空间扫描。由于事件信息来自环境光线亮度梯度的变化,基于事件的空间扫描在弱光环境下依旧能够有效地工作;
[0063]
3、本发明充分利用激光雷达测距精准的特性和事件相机捕捉亮度变化信息的特点,在三维空间中对二维事件进行深度估计。为了能够在三维空间中确实触发事件的目标表面,本发明基于密度聚类算法设计了一种加权欧氏距离,并利用聚类点云簇构造三维点云凸包,并通过德劳内三角剖分来确定最小的三角面片,从而准确地估计事件的深度。
附图说明
[0064]
图1是本发明的方法流程示意图。
[0065]
图2是本发明激光雷达线束投射示意图。
[0066]
图3是本发明三维空间射线与三角面相交检测示意图。
[0067]
图4是本发明稀疏点云稠密化流程图。
[0068]
图5是本发明实施例中稠密深度图。
具体实施方式
[0069]
附图仅用于示例性说明,不能理解为对本发明的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,
附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本发明的限制。
[0070]
如图1所示,本实施例提供一种基于激光雷达和事件相机融合的深度估计方法,数据来源主要为两部分:从激光雷达中得到的三维点云,其中包含环境物体的三维几何信息;事件相机得到的事件流。对于激光雷达的三维点云数据,通过改进的密度聚类算法对其进行聚类,并构建每个簇的三维立体表面模型。对于事件相机的事件流信息,根据光线的投射原理和相机模型,将数据进行反投影从而实现空间扫描,结合立体表面模型完成事件的空间坐标点重建;然后将空间坐标系变换统一到激光雷达坐标系中完成点云稠密化;最后,利用深度扩张和孔洞填充得到稠密的深度图。具体包括以下步骤:
[0071]
步骤1.对于点云数据,进行去噪操作;对于事件相机生成的事件流数据,进行时间片截取、事件流降噪、事件流膨胀操作。
[0072]
数据预处理主要是针对事件流数据,点云数据仅进行一些常规的去噪等操作。对于事件相机来说,由于存在环境光等多种干扰因素,事件流数据往往存在诸多的噪声。在预处理过程中,我们按照时间片对事件流进行截断,并转为帧的形式进行降噪,然后通过事件配准,将运动中产生的事件变换到关键帧中,从而填充和丰富事件信息并提高信噪比。
[0073]
1.1按时间片截取事件流
[0074]
由于事件相机与点云数据的形式和结构并不相同,为了实现异构数据的有效融合。首先以激光雷达的时间戳为基础,以一定的时间长度来截取事件流。所使用的激光雷达输出点云数据的频率为20hz,假设某一帧三维激光点云的时间戳为t,可以得到上一帧的激光点云时间戳为t-0.05s。可以合理地认为,在接近时刻t的某一段极小的时间窗口δt内,事件相机所产生的事件流所对应的环境几何信息,与t时刻得到的三维激光点云所建立的模型一致。
[0075]
本方法利用时间窗口δt来截断事件流并投影到二维像素平面上。考虑到在这个时间窗口内,二维像素平面内同一位置的感光元器件可能会输出不同极性的事件,因此,本方法以时刻t为基准,选择响应时间最接近时刻t的事件为该位置的最终输出事件。事件流e
t
则可以表示为四元组(u,v,t,p)的集合,即:
[0076]et
={(u,v,t,p)|t-δt<t<t,0<δt<0.05s}
ꢀꢀꢀ
(1)
[0077]
其中(u,v)表示像素位置,t表示时间戳,p表示光强度变化的极性。
[0078]
1.2事件流降噪
[0079]
在实际场景中,二维像素平面上的事件噪声往往是孤立的,局部范围内没有更多的事件点。s
uv
为事件点坐标为(u,v)、大小为m
×
n的滤波器窗口,计算每一个事件点e
t
在局部范围s
uv
内的均值。为了避免在卷积运算当中事件点正负极性p产生抵消,造成正常的事件点被过滤掉,本方法使用极性p的绝对值|p|进行卷积运算。均值滤波器在计算过程中可能会产生浮点数,而事件相机产生的事件数据极性只有1和-1,同时会导致原本没有产生事件响应的像素位置出现非零数值,这可能会导致错误的深度估计,从而导致在三维空间中形成原本就不存在的障碍物。因此,根据噪声在二维平面上的稀疏特性,本方法引入了一个阈值e
th
,提出的改进均值滤波公式如下:
[0080][0081]
当局部滤波器窗口内均值超过e
th
,那么保留该位置的事件信息;反之则被认为是噪声而去除。g(s,t)表示s
uv
中的事件极性。由于事件的极性只有1和-1,且在滤波计算中采用了绝对值进行计算,公式(2)相当于统计了局部滤波窗口中的事件数量,保留了在局部范围内仍然稠密的事件信息。
[0082]
1.3事件流膨胀
[0083]
在事件相机或者环境目标物体运动的过程中,事件相机与三维空间环境的相对运动,导致事件相机产生事件响应的来源往往是环境目标物体的几何边缘。如果单纯地依赖于点云时间戳进行事件匹配,只能获取少量的有效事件信息。为了合理地增强事件流信息,本方法利用数字图像处理中的膨胀操作对事件流信息进行增强。定义了一个结构元素s,利用结构元素b在二维平面化的事件e
t
上进行移动。当结构元素s移动到某个像素坐标位置(x,y)上时,如果结构元素s 与二维平面化的事件e
t
的交集不为空集,那么将像素坐标位置(x,y)上的信息修改成一个事件(x,y,t,1)。通过控制结构元素s在二维平面化的事件e
t
上进行移动的次数,约束事件信息膨胀的范围大小,得到膨胀处理后的事件流ed:
[0084][0085]
尽管膨胀操作会导致事件流信息所表示的目标区域范围变大,使得目标边界向外部扩张。但由于事件信息的特性,膨胀操作会将接触目标边缘的中空的目标区域合并到目标物体中,最终可以填补事件信息中的目标区域空洞,有效地增强事件流信息。
[0086]
步骤2.根据事件相机的视角,对激光雷达生成的点云进行提取,以获得目标点云。
[0087]
激光雷达的水平视角为360
°
,能够获取到传感器周围360
°
的环境数据。而本方法所使用的数据集中的事件相机水平视角为65
°
,远远小于激光雷达的水平视角。因此,三维激光点云和事件流信息在空间中重叠部分只有65
°
,其余的三维激光点云为没有落在事件相机视野内。为了能够提取到在事件相机可视范围内的激光点云,本方法通过将三维空间中的激光点云投影到事件相机的二维像素平面上的方式,利用像素坐标的阈值进行约束,筛选符合要求的激光点云。采取小孔成像模型,利用提供的事件相机内部参数以及外部参数,计算三维激光点云的二维像素平面坐标,保留像素坐标落在事件相机像素平面的空间坐标点。在具体实现中,综合考虑了激光雷达在城市道路环境中的有效测距距离和道路障碍物的实际高度,对三维激光点云的提取加入了深度和高度的约束。
[0088]
此外,本方法的工作重点在于对三维环境中的障碍物进行深度估计,并不关注道路地面的深度信息。由于激光雷达的原理特性,三维激光点云中可能存在多条投影在道路地面上的离散化的弧线。在利用密度聚类算法对三维激光点云进行聚类的时候,这些弧线会对聚类的结果产生非常大的影响,导致聚类结果出现比较大的误差并影响后续的三维表面重建。因此,本方法基于随机抽样一致(ransac)算法对三维激光点云进行地面点云提取并去除弧线影响。
[0089]
步骤3.基于事件的空间扫描,实现对事件流数据的反投影,以获得事件流数据的三维表示。
[0090]
由于经过降噪后的事件流数据属于二维空间的信息,无法直接与三维激光点云的
数据进行融合。因此,需要将二维数据进行反投影以获得事件流数据的三维表示。将二维平面上的事件流信息进行反投影实现空间扫描,然后根据对事件相机建立的小孔成像模型进行逆运算,得到单一事件对应的空间三维归一化坐标。再结合相机中心坐标点,计算事件的方位向量。
[0091]
需要注意的是,像素平面坐标是图像平面量化后得到的坐标,而光心可以通过相机的外部参数计算得到激光雷达坐标系下的三维坐标。因此本方法通过计算事件的三维归一化坐标来计算方位向量,而非直接利用事件的像素平面坐标。因此我们实现了对事件的反投影以及空间扫描,获得了事件的三维表示方式,统一了事件以及三维激光点云的参考坐标系。
[0092]
步骤4.对点云数据使用基于加权欧式距离的密度聚类后进行三维目标建模。
[0093]
该步骤主要是针对与处理后的三维激光点云进一步处理。通过目标点云提取之后的三维激光点云,依旧属于三维空间的离散点集,而且并不一定能够和事件信息具有唯一的对应关系。也就是说,三维激光点云中的某一个点,很大可能并不能够用上一个步骤中得到的任何一个方位向量进行表示。同样,并不一定所有的方位向量都能指向三维激光点云中的确定的一个空间坐标点。因此,利用三维激光点云进行进一步立体几何表面建模,从而得到三维环境中目标障碍物的立体平面表示,通过三维目标表面和方位向量相交检测最终完成深度估计。具体分为以下几步:
[0094]
4.1基于加权欧式距离的三维点云密度聚类
[0095]
利用离散的三维激光点云进行立体表面建模,需要划分归属不同平面的空间坐标点,确定坐标点在三维空间中的空间关联关系。本方法使用dbscan密度聚类算法对三维激光点云进行点集划分。需要注意的是,三维激光点云在水平方向上是稠密的,但是在竖直方向上的稠密度取决于激光雷达的线束数量,竖直方向的点云相对于水平方向上是非常稀疏的。如果在密度聚类算法中不对此加以考虑,聚类的结果可能在竖直方向上是断层的,也就是垂直于地面的同一个物体,可能会在竖直方向上被划分成多个部分,不利于立体平面建模。另外,在自动驾驶场景中的道路环境中,大多数的障碍物都是在地面上的而非悬浮在空中的,落在同一个位置不同高度的空间坐标点往往归属于同一个物体。基于这个假设,为了尽可能在水平距离上划分不同的目标物体,并且尽可能保证一个聚类簇中的点云属于同一个物体。本方法在进行三维激光点云密度聚类时,并非直接使用欧氏距离,而是在欧式距离的基础上考虑水平距离和竖直距离的不同权重,具体的距离公式如下,该公式为自定义的加权欧式距离:
[0096][0097]
在公式(4)中,a,b为不同的空间坐标点,为三维笛卡尔坐标系中不同坐标轴的权重。在本方法工作中,为了使得聚类过程中能够将同一位置上不同高度的空间坐标点归类在同一聚类簇中,设置的权重条件为:
[0098]wx
=wy>wzꢀꢀꢀ
(5)
[0099]
4.2三维目标建模
[0100]
经过三维激光点云密度聚类之后得到的每一个聚类簇,其中的三维空间点只能独立地表示目标物体的某一个局部位置的坐标。在本方法的工作中,需要利用立体平面进行事件的深度估计,也就是通过计算事件的方位向量与空间中的平面相交点得到对应的三维坐标。因此,本方法利用每一个聚类簇求它的凸包,得到目标物体最外部的表面的粗略表示。为了能够方便快速地进行方位向量与平面相交检测计算,本方法对聚类簇的凸包进行三角剖分,利用各不相交的三角面片来表示,从而,目标物体的表面上任意一个位置都能用唯一一个的最小三角面片进行计算得到。
[0101]
但是,在实际情况中,由于激光雷达的线束限制,三维激光雷达在竖直方向上非常稀疏,激光线束往往只能投射到目标物体表面内部,导致线束之间覆盖的物体表面仅为实际物体表面的一部分。在远距离的目标物体上,16线激光雷达很可能只有一条激光线束投射到其表面上。而在经过三维激光点云聚类之后,得到的只有一条线束的激光点云聚类簇。这种聚类簇在竖直方向上难以构建立体几何表面。为了使得构建的目标表面模型能够充分表示实际的目标表面,在构建表面模型的时候,本方法在点云聚类簇中增加一些辅助构造表面模型的虚拟点云,其x,y坐标与实际的点云保持一致,但z坐标需要重新计算。
[0102]
如图2所示,在点云聚类簇中增加虚拟点云,需要考虑其他激光线束的遮挡问题,如果增加的虚拟点云过高或者过低,会导致在空间扫描和深度估计中将不属于该目标物体的点云被错误估计,违反了实际中激光雷达的线束投射情况。在图2中,线束2和线束3是实际点云聚类簇中的最低和最高线束,对应高度为h2和h3;线束1和线束4是添加的虚拟点云的最低和最高线束,对应高度为h1和h4。
[0103]
假设某一个点云聚类簇为p
cluster
={(xi,yi,zi)|i=1,2,
…
,m},对于用于辅助计算虚拟点坐标的实际坐标点pi(xi,yi,zi)∈p
cluster
,该点到激光雷达的距离为d=xi,利用三角函数、已知的激光雷达安装高度h和激光雷达的角分辨率α,可以计算到聚类簇p
cluster
中最高的点云线束距离上方激光线束的高度h4:
[0104][0105]
同理,可以计算聚类簇p
cluster
中最低的点云线束距离下方激光线束的高度 h1:
[0106][0107]
但是,如果在增加虚拟点云的时候,直接利用公式(6-10)以及公式(6-11)计算的高度,那么利用扩增后点云聚类簇所构建的表面模型在竖直方向上会相互重叠,会导致远距离的事件被错误估计到近距离的目标物体上。因此,为了保证在竖直方向上空间的覆盖程度和避免相互重叠,本方法在实现增加虚拟点云的时候,使用激光雷达角分辨率的一半进行计算,并考虑道路环境中目标物体的高度,加入上限约束和下限约束。所以,最终的高度计算公式如下:
[0108][0109][0110]
步骤5.使用bowyer-watson算法对构造立体表面模型的聚类簇中所有空间坐标点进行合理的三角剖分。
[0111]
在完成立体表面建模之后,可以结合基于事件的空间扫描和立体表面模型确定某一个事件与空间中的目标物体的匹配。但是,这只能大致确定该事件在三维空间中的大致方位,无法直接准确地获取事件的深度,因为稀疏三维激光点云丢失了这部分的深度信息,因此需要借助已有的空间坐标点完成深度的估计。为了能够充分利用已有的空间坐标点,本方法需要对构造立体表面模型的聚类簇中所有空间坐标点进行合理的三角剖分,对目标物体表面划分成尽可能多且尽可能小的面片。另外,由于在三维空间环境中目标物体靠近激光雷达的一侧反射激光束,且三维空间中的三角剖分会穿过目标物体内部。因此本方法将三维空间坐标点投影到二维空间中进行三角剖分。利用德劳内三角剖分得到的三角网格中,任意一个三角形的外接圆内部都为空,也就是不存在其他的顶点,并且最大化了三角形的最小内角。这种特点,使得德劳内三角剖分不会得到狭长三角形,避免了深度估计的较大误差。此外,德劳内三角剖分在构建三角形的过程中,利用最为邻近的三个顶点,保证了所有的三角形的各条边互不相交,从而使得在事件反投影之后,如果存在触发该事件的三角面,那么这个三角面具有唯一性。最后,德劳内三角剖分能够在最外层的边界形成一个凸多边形,这使得构建的模型能够反映出尽可能地大的目标表面。
[0112]
在本方法工作中,选取了bowyer-watson算法进行实现。bowyer-watson算法是一种实现德劳内三角剖分的经典算法,分别由bowyer和watson在1981年独立提出。
[0113]
步骤6.对建模的目标物体表面以及三维化的事件进行快速相交检测并实现空间坐标点重建,完成事件深度估计。
[0114]
点云聚类后,利用聚类簇建模得到的几何表面并不一定真实存在于当前环境,也就是说也不能确定凸包中面片是否是表示真实的物理表面。凸包中的面片只能粗略估计目标点的大致范围,不能准确地估计深度。因此,本方法需要利用建模得到的目标物体表面以及三维化的事件进行相交检测并实现空间坐标点重建,完成事件深度估计。
[0115]
对快速相交检测算法进行更详细的介绍:
[0116]
利用小孔成像模型对事件反投影进行空间扫描的时候,每一个事件都可以计算出一个以相机中心为原点,长度未知的方位向量。可以参考光线投射的原理,空间中的目标物体表面反射的光线以直线的形式穿过相机的图像平面并导致了该事件的产生。所以,可以合理地认为相机中心、图像平面上的事件以及目标物体平面上的光线反射点落在同一直线上。而事件反投影得到的方位向量,同样落在该直线上,方向与光线投射的方向相反,终点落在目标物体平面上的光线反射点上,也就是本方法工作中深度估计以及稀疏点云稠密化需要还原的三维空间坐标。在事件反投影并进行深度估计的过程中,需要快速并准确地判断以及计算方位向量的终点。通过结合经过三角剖分之后的目标物体表面模型,本方法将事件的深度估计问题简化成三维空间射线与立体三角面片相交检测问题,通过计算事件空间扫描过程与物体表面模型的交点完成对事件的深度估计。
[0117]
本方法实现的深度估计算法基于tomas等人在1997年提出的方法,应用于
判断空间中一根射线是否与某一个三角形相交,并求出交点。该算法非常适合用于三角网格中,只需要三角形的三个顶点,不需要动态地计算或者读取保存好的平面方程,能够快速的进行判断以及计算。从相机中心出发,以相机中心指向图像平面上的事件的归一化向量为方向,在三维空间环境中进行扫描。
[0118]
如图3所示,在空间扫描的过程中,需要判断以及计算方位向量和空间环境中的目标表面是否存在交点。在本方法工作利用三角剖分对目标物体表面进行建模的前提下,可以利用三角面的顶点(v0,v1,v2)来构建三角面的参数方程。因此,任意给定一个三维空间中的目标点坐标p,假如该点落在某个三角面中,利用重心坐标系表示:
[0119]
p=a(v
1-v0) b(v
2-v0) v0[0120]
=(1-a-b)v0 av1 bv2ꢀꢀꢀꢀ
(10)
[0121]
其中,a>0,b>0,a b<1。公式(6-13)表示三角面中任意一点,可以通过以任意一个顶点作为起点的相邻的两条边作为向量的加权和进行表示。
[0122]
事件投影公式表示为:
[0123]rcp
=c dt
ꢀꢀꢀ
(11)
[0124]
其中,c表示相机中心坐标,d为归一化向量,t为待求解的向量长度。
[0125]
因此,判断和计算方位向量是否与某一个三角面相交的问题,转换成了求解公式(10)以及公式(11)的联立方程:
[0126]
c dt=(1-a-b)v0 av1 bv2ꢀꢀꢀ
(12)
[0127]
将公式进行移项并整理为矩阵形式,最终可得到求解方程为:
[0128][0129]
其中,e1=v
1-v0,e2=v
2-v0,e3=c-v0。
[0130]
根据最终的公式(13),本方法可以仅需要利用三角面的顶点以及方位向量的表达式,快速地进行判断空间射线是否和目标表面是否相交并求出交点,而不需要求解目标表面的平面方程.
[0131]
步骤7对事件在三维空间中进行空间坐标点重建,完成事件信息和点云的前端融合,最后通过深度扩张和孔洞填充的方法,对局部稀疏的点云进行深度填充。
[0132]
在完成数据的预处理、事件空间扫描以及深度估计算法之后,事件信息和点云信息依旧为独立的异构数据。本方法通过对事件在三维空间中进行空间坐标点重建,完成事件信息和点云的前端融合,最后通过深度扩张和孔洞填充的方法,对局部稀疏的点云进行深度填充。主要包含空间坐标点重建,深度扩张与空洞填充三个步骤。
[0133]
7.1空间坐标点重建
[0134]
首先,利用事件的方位向量以及目标物体表面模型进行深度估计,需要准确地判断导致该事件响应的原目标表面。但是事件的方位向量表示的是一条射线,在三维空间中可能存在多个目标表面和该射线相交。根据光线的反射以及投射原理,假设自动驾驶场景道路环境中的目标物体都能够良好地反射激光,本方法工作通过利用激光点云聚类簇的空间范围对事件的方位向量进行约束,筛选出距离激光雷达和事件相机最近的、与事件的方位向量相交的目标物体表面模型,然后进行深度计算和重建该三维空间点。针对深度的空
间约束,具体的约束条件如下:
[0135][0136]
其中,aq为求出与三维事件射线相交的聚类簇。
[0137]
但是,考虑到三维空间中存在环状等特殊形状的目标物体,为了得到三维坐标更加精确的空间坐标点,实现较精准的深度估计,本方法工作在筛选出目标物体表面模型并进行初步深度计算之后,将该目标物体的三维激光点云进行二维投影,然后利用德劳内三角剖分,对二维投影后的三维激光点云进行三角剖分,进一步利用三维空间射线与三角面相交检测的算法进行深度计算和重建该三维空间点。流程图如图4所示。
[0138]
在流程图中,使用了事件流的方位向量集合de,各个聚类簇的集合作为输入。首先,针对每一个事件的方位向量de,遍历所有三维激光点云密度聚类后得到的聚类簇的集合,针对当中的每一个聚类簇点云进行坐标均值计算得到该聚类簇的质心坐标。然后通过质心坐标的深度,利用公式(11)计算方位向量 de在该深度下的空间坐标点。如果该空间坐标点落在当前的聚类簇内(利用坐标点集的最大值和最小值进行快速判断),那么针对该聚类簇中所建立的表面模型,利用公式(14)对方位向量de与表面模型中的每一个面片进行相交检测。如果存在面片与方位向量相交,即交点存在,那么将该面片投影到像素平面并进行德劳内三角剖分,返回对应的三维空间面片,重新计算计算方位向量de与三角剖分后面片的交点,并保存最靠近传感器的空间坐标点。最后,得到最终的计算到的方位向量de对应的空间坐标点。
[0139]
7.2深度扩张与孔洞填充。
[0140]
完成事件的空间坐标点重建之后,事件的有效边界信息已经融入了稀疏点云当中。但是由于事件在二维平面上相对稀疏,点云之间的空间存在许多的间隙,已知的深度信息没有得到充分利用,点云局部区域比较稠密,整体上相对稀疏。为了充分利用先验的深度信息,获取稠密的深度图,利用深度扩张和孔洞填充的方式,在已有深度信息的基础上,对空白像素进行深度填充以实现深度补全。
[0141]
首先,具有深度信息的点云附近的空白像素最有可能与点云深度接近甚至相同,因此可以借助已有的深度信息对这些空白像素进行深度扩张。根据点云二维投影之后的稀疏特点和激光雷达线束的扫描特性,本方法通过设计一个自定义内核,利用数字图像处理技术中的膨胀操作,对二维点云附近的像素进行深度估计。
[0142]
在进行深度扩张之后,由于扩张的谨慎操作,并不会大规模地进行深度填充,深度图中点云视野之间仍然存在许多空白像素。此时的空白像素距离有效的点云深度较远,不适合直接填充深度。对于深度图中的较小的孔洞,考虑到交通环境中目标物体的结构,可以通过连接空白像素附近的目标物体边缘深度信息进行深度估计。因此本方法利用形态学中的关闭操作对较小孔洞进行关闭,使用了5
×
5的内核。关闭操作保留了已有的目标物体深度边缘信息,同时对较小孔洞的像素也能很好地进行深度估计。对于深度图中的较大孔洞,由于远离具有准确深度的点云,需要使用更大的内核进行填充,本方法利用了7
×
7的内核进行深度填充。需要注意的是,深度扩张以及孔洞填充的操作仅对空白像素进行深度填充,保留已有的深度信息不变,避免增加深度误差。另外,深度图中更大的空白区域往往属于超
距离的范围,例如无遮挡的前景或者天空区域,对于这部分深度空白的区域,本方法不做进一步的操作,以避免带来错误的深度估计。
[0143]
实验工作的实验平台参数信息以及所使用的公开数据集信息
[0144]
1.1实验环境与平台
[0145]
本方法实验工作所使用的实验平台的配置参数如表1所示。
[0146]
表1配置参数表
[0147][0148][0149]
ros是开源的机器人开发系统框架,提供类似的操作系统的服务,方便研究人员或者工程师进行机器人开发。ros的主要功能有底层驱动程序管理、硬件抽象描述、共用功能的执行、程序发行包管理以及程序间消息传递。在ros 上进行机器人开发和研究,能够极大地提高代码复用率。另外,ros具有分布式处理的特点,利用运行时低耦合、松散的运行架构,使得单独的模块可执行文件能够独立运行,甚至能够让单独的模块独立运行于不同的设备、不同的网络之间。
[0150]
1.2实验数据集
[0151]
本方法工作所采用的开源数据集为多设备立体时间相机数据集(mvsec, multi vehicle stereo event camera dataset),该数据集是由宾夕法尼亚大学的研究人员在2018年所发布,为研究和开发基于事件相机的三维感知算法而设计并采集的数据集。通过从多个平台,包括汽车、摩托车、六旋翼无人机和手持平台,分别在白天和黑夜、室内和室外的场景下,采集了激光雷达、imu、gps、事件相机等传感器的数据,并对数据进行融合得到真值数据和深度图像。针对事件的生成,mvsec数据集将两个davis 346b相机以x轴对齐,基线为 10cm的方式进行配置安装,并且通过使用从左摄像机(主摄像机)生成的触发信号经过外部电线将同步脉冲传递到右摄像机(从摄像机)来对摄像机进行时间戳同步。每个相机的分辨率均为346
×
260,配备4nm的镜头和65
°
的垂直视野范围。对于三维激光点云的采集,考虑到激光雷达需要提供其他传感器视觉范围内的精确的深度信息,在安装的过程中考虑了使激光雷达的较小垂直视场与立体事件相机的垂直视场之间完全重叠。
[0152]
在mvsec数据集中,采集三维激光点云和事件流的激光雷达和事件相机的传感器参数及其特性如下表2所示。
[0153]
表2 mvsec数据集中部分传感器及其特性
[0154][0155]
本方法工作使用了该数据集中提供的在汽车平台上采集的激光雷达和事件相机的原始数据进行实验,并利用对应的真值数据进行测试,场景为白天和黑夜条件下的室外道路环境。
[0156]
1.3实验性能
[0157]
利用彩虹色条,也就是红色至紫色的色阈值表示距离的由近到远。实验结果如图5所示,可以看出数据融合后,加入事件相机能够很好的处理在环境光条件中局部过曝或者局部阴暗而难以识别的问题。并且,之前由于点云过于稀疏而无法难以识别的车辆和行人,都在稠密深度图中得到了很好得还原。
[0158]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
[0159]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。