1.本发明涉及声纹识别和对抗样本领域,具体地说,是一种基于声纹识别对抗性样本的物理域身份伪装系统及方法。
技术背景
2.近年来,语音以其自然的、以人为中心的体验成为最重要的人机交互界面之一。在智能助手、智能家居、自动导航等个人和生产领域的快速发展和部署,进一步刺激了声纹识别成为一种新兴的生物识别技术。随着深度学习技术的发展,基于声纹的身份认证技术取得了显著的性能提升,从而引起了声纹识别技术的广泛应用。有行业研究报告表明,2020年全球声纹识别市场规模达到107亿美元,并将有望在2026年超过271亿美元,充分显示了声纹识别技术广阔的发展前景。然而,这些基于深度学习的解决方案由于其固有的神经网络结构特点,很容易受到基于对抗性样本的攻击。对抗性样本攻击是一种利用目标神经网络模型结构特点,通过对输入样本添加定向的人类不可感知的微小扰动,使得模型数值偏差在传递的过程中不断放大,最终导致目标模型产生错误决策,甚至定向决策的一种可用性攻击。这种现象引发了广泛的公众关注和学界的大量研究。本发明利用亚音素级对抗性扰动构筑人声实时同步的流式对抗性扰动,并结合基于信道增强技术和迁移性增强技术,使得扰动能够在物理空间内对黑盒目标系统产生误导作用,最终对原始人声实现物理域内的定向伪装以欺骗声纹识别系统。
3.现有的面向声纹识别系统(下称“声纹系统”)的基于对抗性样本的身份伪装方法已经能够基于主流的对抗样本生成方法实现对声纹识别系统的说话人身份伪装攻击。但这些技术主要依托于纯数字化系统,面向结构透明的白盒模型,存在没有充分考虑到真实物理场景下面临的新的挑战,并且其实现形式与真实的应用场景不相适应,对物理系统构成的干扰有限等问题,进而导致无法在真实的物理域场景中实现。具体来说现有技术缺乏以下三个方面的能力。(1)流式对抗性扰动生成和注入:为了避免引起周围的人关注,伪装者不能直接播放对抗性样本,而应该根据人声以实时产生扰动并进行物理注入;(2)信道干扰抗性:物理传播过程为对抗性样本中引入了复杂的信道干扰,因此攻击需要是跨信道的,即能够抵抗设备和环境干扰;(3)攻击未知模型的可转移性:在现实世界中,目标声纹系统的实现细节对于伪装者往往是不可知的,这表明存在一个严格的黑盒设定。综上所述,现有的基于对抗性样本的身份伪装技术面向场景过于理想化,无法适应真实物理域场景的需求。
技术实现要素:
4.本发明对现有技术的技术方案作出了改进,提供了一种基于声纹识别对抗性样本的物理域身份伪装系统及方法,本发明是通过以下技术方案来实现的:
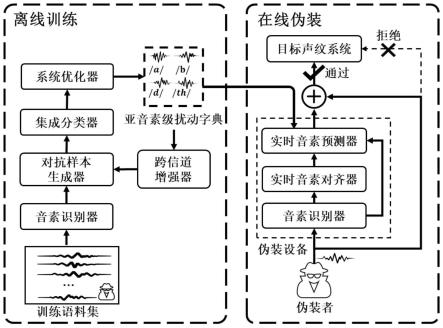
5.本发明公开了一种基于声纹识别对抗性样本的物理域身份伪装系统,系统包括离线训练部分和在线伪装部分:
6.离线训练部分包括亚音素级扰动字典、音素识别器、对抗性样本生成器、声纹分类
器、系统优化器和训练语料集;信号自训练语料集输入音素识别器后输出携带音素对齐信息的对齐语音,对抗样本生成器将亚音素级扰动字典中的亚音素扰动按音素信息叠加到输入对抗性样本生成器中的对齐语音中生成对抗性样本,对抗性样本在声纹分类器中前向传播,输出经过系统优化器反向传播后用于优化亚音素级及扰动字典;
7.在线伪装部分依托于便携式实时伪装设备,伪装设备的软件组成包括音素识别器、实时音素对齐器和实时音素预测器;伪装者产生的实时语音输入音素识别器中产生实时音素序列,实时音素对齐器根据实时音素序列定位当前时刻音素,推导出待播放的音素序列,输入实时音素预测器,实时音素预测器基于根据实时音素序列和待播放的音素序列确定序列中每一个音素的具体时长,并从根据预测结果与人声同步播放亚音素级扰动,从而在物理域中合成具有信道鲁棒性、模型鲁棒性的对抗性样本,最终实现面向声纹识别系统的身份伪装。
8.作为进一步地改进,本发明所述的离线训练部分还包括位于亚音素级扰动字典和对抗样本生成器之间的跨信道增强器,用于增强亚音素级扰动的信道鲁棒性,跨信道增强器利用maximum length sequence信号采集信道脉冲响应采集,并且采集过程同时包含了不同环境、不同设备以及不同距离条件。
9.作为进一步地改进,本发明所述的声纹分类器是集成分类器,用于增强亚音素级扰动的跨模型迁徙能力,将对抗性样本同时输入多个模型架构、模型训练集不相同的预训练的声纹模型中进行前向传播,将输出的得分通过加权平均操作求和;其中,模型架构为d-vector、x-vector和deepspeaker中的一种或多种,模型训练集为voxceleb1/voxceleb2中的子集,加权平均操作利用注意力机制在迭代过程中动态调整各个模型输出的权重;伪装设备为搭载麦克风、扬声器以及处理芯片硬件设备的嵌入式设备。
10.本发明还公开了一种基于声纹识别对抗性样本的物理域身份伪装方法,具体包括以下步骤:
11.离线训练部分:
12.1)亚音素级扰动字典为使用的每一个音素提供一个匹配的10-20ms长度的亚音素级扰动,初始化为符合正态分布的随机扰动;
13.2)为了增强扰动的抗信道干扰能力,在叠加到语音上以前,通过跨信道增强器,利用基于事先采集的信道脉冲响应模拟多种不同设备和房间环境的信道状态,对亚音素级扰动进行数据增广;
14.3)为了能够正确叠加亚音素级扰动到语音上,利用音素识别器从训练集语料中的每一条中提取音素信息,音素信息包含音素种类和起讫时间戳,与原语音组成对齐语音;
15.4)通过对抗样本生成器将经过数据增广的亚音素级扰动与对齐语音按音素叠加,叠加方式为重复填充亚音素级扰动直至填满整个音素,输出对抗性样本;
16.5)为了提高跨模型迁移能力,对抗性样本通过集成分类器将其输入多个声纹识别模型后将多个模型的输出通过加权的形式集成为一个;
17.6)根据集成分类器的识别结果,系统优化器求解系统优化问题并更新对亚音素级扰动字典进行迭代更新,最终得到一个训练好的亚音素级扰动字典。
18.在线伪装部分:
19.7)伪装者事先录制同文本的语音,使用音素识别器提取出音素序列,包括语音中
的所有音素和持续时间,作为标准音素序列,供实时伪装过程中参考;
20.8)伪装过程中开始,伪装者手持伪装设备口述预设口令,伪装设备通过麦克风实时接收语音;
21.9)语音信号通过音素识别器被识别为实时音素序列;
22.10)实时音素序列通过实时音素对齐器与事先给定的标准音素序列进行对齐,进而获得接下来说话人会说的待播放音素序列;
23.11)实时音素预测器基于实时音素序列、标准音素序列和持续时间待估计的待播放音素序列,估计出待播放音素序列中的音素的持续时间;
24.12)根据音素序列及其各音素的持续时间,伪装设备通过扬声器准确播放出对应的亚音素级对抗性扰动,最终实现与实时语音的在线同步过程,达到物理域流式伪装攻击的目的。
25.作为进一步地改进,本发明所述的步骤6)中采用的系统优化问题如下:
[0026][0027][0028]
s.t.||p||
∞
≤∈,
[0029][0030]
13)其中,x为输入样本,y
t
为目标标签,p为亚音速及扰动字典,g(
·
,
·
)为对抗样本生成器,分类器输出判断输入样本为说话人i的置信度,θ为系统判断输入样本为伪装样本的阈值上界,l
s,θ
(x,y
t
)为样本x在阈值为θ的系统s下被判断为y
t
的损失函数,为求期望操作,μ、χ、σ分别为训练样本分布、信道冲激响应分布以及用于集成模型的模型分布,αs为集成分类器中各分类器的权重因子。
[0031]
作为进一步地改进,本发明所述的步骤3)和步骤9)中音素识别器用于提取语音中的音素序列及其时间信息,基于双向rnn神经网络模型架构,其工作流程为:对输入音频进行分帧操作,对每一帧进行26维mfcc提取后输入双向rnn网络,输入层为尺寸为26
×
1,隐藏层采用尺寸为256的gru单元,输出层尺寸为40(与使用的音素对应),输出结果经过合并重复音素、纠正错误音素处理后输出音素序列。
[0032]
作为进一步地改进,本发明所述的实时音素对齐器的实现流程为:首先从事先录制的与实时语音同文本语音中提取出来的音素信息构建基准音素序列,利用音素识别器对录制的实时语音不断进行音素识别获得实时音素序列,并利用滑动窗口机制将识别出来的音素序列与基准音素序列进行对齐,以此确认接下来说话人语音中的音素序列。
[0033]
作为进一步地改进,本发明所述的滑动窗口机制利用了长短期滑动窗口,其中长期滑动窗口用于确定短期滑动窗口的搜索范围,短期滑动窗口成对存在于基准音素序列与实时音素序列中,用于比较窗口内容的匹配度。
[0034]
作为进一步地改进,本发明所述的实时音素预测器的实现流程为:基于实时音素序列和基准音素序列的相对关系,利用指数加权移动平均算法,估计当前语速,再将基准音素序列中的音素持续时间与当前语速进行逆运算获得实时语音中音素的持续时间。
[0035]
本发明的有益效果如下:
[0036]
本发明提出一种基于声纹识别对抗性样本的物理域身份伪装系统及方法。现有的技术方法针对单条语音构成一次性的对抗扰动,且需要在生成扰动以前获得完整的语音,存在实时性差、通用性差、生成效率低等问题,与真实的流式物理域攻击场景不相适应。本发明创新性地提出一种将扰动与生成过程与施加过程分离的实时流式伪装攻击方法,利用实时音素对齐器和实时音素预测器预测并定位实时语音中的音素,并在音素级别生成细粒度的通用亚音素级对抗扰动,从而使得一次生成的亚音素级对抗性扰动能够实时施加到流式语音中,最终实现适应于真实物理域场景的伪装攻击形式。在实时性的评估中,本发明每次实时同步的平均时间开销为0.11s,这表明本发明的同步机制能够在0.5s的同步间隔下实现良好的实时性能;音素延迟的中位数为50ms,超过75%的音素延迟小于100ms,具有良好的同步性能。本发明的实时音素预测机制的平均音素命中率达到了61.3%,有效预测了音素及其出现的时间。
[0037]
为了满足降低扰动生成过程对已知目标模型细节的需求,现有技术方法采用基于查询的梯度估计技术优化对抗性扰动,该方法训练单条对抗性扰动需要向目标系统发起上万次的查询请求,存在严重的效率低下问题,且易被目标系统感知,不具备实际的可操作性。本发明提出的基于集成分类器增强对抗性扰动的跨模型迁移能力,扰动生成过程无需知晓目标模型的细节,也无需查询目标系统,通过将多种不同架构、数据集的声纹识别模型引入到扰动的训练过程中,扰动能够有效学习发现语音本身存在的和声纹模型普遍存在的易受扰动影响的安全性漏洞,从而对声纹识别系统具有泛化的攻击能力,实现更加符合真实攻击场景的黑盒攻击。在迁移性评估中,本发明在跨训练数据、跨模型架构和两者数据和架构三种不同攻击类型下分别达到了94.8%、89.5%和85.5%asr,分别比单独攻击模型提高了27.9%、29.4%和37.2%,这表明与单个模型相比,集成模型有助于提高攻击不同黑盒模型的鲁棒性。
[0038]
现有的技术方法面向纯数字化系统进行对抗性扰动生成,无法在物理播放的过程中抵御设备、环境等信道干扰,从而在物理域场景中造成严重的性能下降。本发明充分考虑到信道干扰音素,引入跨信道增强器,从环境、设备两个维度对亚音素级对抗扰动进行数据增广,有效提高扰动的信道鲁棒性,最终保证其在物理播放过程中保持良好的性能。在信道鲁棒性评估中,本发明分别在四种设备型号上分别实现了85.5%、91.0%、86.9%和97.3%的asr,平均asr高于没有经过增强的对照组44.4%;同时,本发明分别在三种不同的房间环境下达到了90.5%、91.3%和88.5%asr,分别高于对照组56.1%、53.2%、63.7%,这充分证明了本发明提出的信道增强技术确实提高了物理伪装中对抗性干扰的鲁棒性。
[0039]
在综合性能效果评估中,本发明相比现有的fakebob实现了更低的mcd,同时asr提高了15.5%,在d-vector、x-vector和deepspeaker三种主流的声纹识别模型上分别达到了80.5%、85.5%和90.5%的asr,充分证明了本发明在不同系统上的有效性。
附图说明
[0040]
图1为本发明的系统框架图;
[0041]
图2为基于亚音素级扰动的对抗性样本生成示例图;
[0042]
图3为集成分类器示意图;
[0043]
图4为实时音素对齐器示意图;
[0044]
图5本发明流式同步性能图;
[0045]
图6为本发明的流式实时伪装的性能图;
[0046]
图7为本发明在不同信道环境下的性能图;
[0047]
图8为本发明在不同模型下的性能图;
[0048]
图9为本发明的噪声和听感测试结果图。
具体实施方式
[0049]
下面通过具体实施案例对本发明的技术方案作进一步地说明:
[0050]
本发明公开了一种基于声纹识别对抗性样本的物理域身份伪装系统及方法,在如下攻击场景中进行:伪装者拟冒充合法用户经物理空间访问搭载目标声纹系统设备,以便检索用户的语音信息或激活敏感的语音命令,达到身份伪装的目的。假设伪装者没有注册到目标系统中,因此在正常情况下应被视为非法用户,而被拒绝登录。受限于便携性,伪装者只能携带配备扬声器和麦克风的小型伪装设备,用于播放对抗性干扰。此外,伪装者对目标声纹系统没有任何先验知识,包括声纹系统、信号处理技术等。这表明伪装者应该发起黑盒攻击。另一方面,假设伪装者可以从公共对话或社交媒体中收集目标用户的一些语音样本用于训练。但需要明确的是,收集的样本不需要涵盖进一步伪装中使用的文本。在伪装过程中,伪装者不受空间限制,也就是说,伪装者和目标声纹系统周围可能有其他人。为了避免引起他人的注意,伪装者不能在没有现场讲话的情况下播放合法用户的声音,这是不自然的,很容易引起周围人的注意。
[0051]
本发明公开了一种基于声纹识别对抗性样本的物理域身份伪装系统,所述的系统包括离线训练部分和在线伪装部分,图1为本发明的系统框架图。离线训练部分包括亚音素级扰动字典、音素识别器、对抗性样本生成器、跨信道增强器、集成分类器、系统优化器和训练语料集。语音信号自事先录制自伪装者的训练语料集输入音素识别器后输出携带音素对齐信息的对齐语音;对抗样本生成器将亚音素级扰动字典中的亚音素扰动经过跨信道增强器增广后按音素信息叠加到对齐语音中生成对抗性样本;对抗性样本在集成分类器中前向传播,输出经过系统优化器反向传播后用于优化亚音素级及扰动字典。在线伪装部分依托于便携式实时伪装设备,伪装设备包括音素识别器(与离线训练部分中所述音素识别器结构相同)、实时音素对齐器和实时音素预测器。伪装者产生的实时语音输入音素识别器中产生实时音素序列,实时音素对齐器根据实时音素序列定位当前时刻音素,推导出待播放的音素序列,输入实时音素预测器,实时音素预测器基于根据实时音素序列和待播放的音素序列确定序列中每一个音素的具体时长,并从根据预测结果与人声同步播放亚音素级扰动,从而在物理域中合成具有信道鲁棒性、模型鲁棒性的对抗性样本,最终实现面向声纹识别系统的身份伪装。
[0052]
本发明公开了一种基于声纹识别对抗性样本的物理域身份伪装方法,所述的方法主要分为离线训练阶段和在线伪装阶段,其开展步骤如下:
[0053]
离线训练阶段
[0054]
14)亚音素级扰动字典为使用的每一个音素提供一个匹配的10-20ms长度的亚音素级扰动,初始化为符合正态分布的随机扰动;
[0055]
15)为了增强扰动的抗信道干扰能力,在叠加到语音上以前,通过跨信道增强器,利用基于事先采集的信道脉冲响应模拟多种不同设备和房间环境的信道状态,对亚音素级扰动进行数据增广;
[0056]
16)为了能够正确叠加亚音素级扰动到语音上,利用音素识别器从训练集语料中的每一条中提取音素信息,所述的音素信息包含音素种类和起讫时间戳,与原语音组成对齐语音;
[0057]
17)通过对抗样本生成器将经过数据增广的亚音素级扰动与对齐语音按音素叠加,叠加方式为重复填充亚音素级扰动直至填满整个音素,输出对抗性样本;
[0058]
18)为了提高跨模型迁移能力,对抗性样本通过集成分类器将其输入多个声纹识别模型后将多个模型的输出通过加权的形式集成为一个;
[0059]
19)根据集成分类器的识别结果,系统优化器计算目标损失并将梯度反向传播更新对亚音素级扰动字典进行迭代更新,最终得到一个训练好的亚音素级扰动字典。
[0060]
在线伪装阶段
[0061]
20)伪装者事先录制同文本的语音,使用音素识别器提取出音素序列,包括语音中的所有音素和持续时间,作为标准音素序列,供实时伪装过程中参考。
[0062]
21)伪装过程中开始,伪装者手持伪装设备口述预设口令,伪装设备通过麦克风实时接收语音
[0063]
22)语音信号通过音素识别器被识别为实时音素序列
[0064]
23)实时音素序列通过实时音素对齐器与事先给定的标准音素序列进行对齐,进而获得接下来说话人会说的待播放音素序列
[0065]
24)实时音素预测器基于实时音素序列、标准音素序列和持续时间待估计的待播放音素序列,估计出待播放音素序列中的音素的持续时间。
[0066]
25)根据音素序列及其各音素的持续时间,伪装设备能够准确播放出对应的亚音素级对抗性扰动,最终实现与实时语音的在线同步过程,达到物理域流式伪装攻击的目的。
[0067]
以下就亚音素级对抗性扰动字典及其生成过程做具体说明,该过程尚未包含集成分类器和跨信道增强器。亚音素级扰动是经过训练的,能够通过叠加到语音中对应音素上从而快速生成对抗性样本的定长、限幅的音频噪声。亚音素级扰动字典是一个包含了40个亚音素级扰动的字典容器,其中每个扰动与表1所示的39个音素一一对应,额外的一个扰动与语间停顿对应,每个扰动的长度为10-20ms。定义p作为亚音素级扰动的字典,键值为40个音素符号,实值为对应的定长音频扰动。为了干扰目标声纹系统s,首先基于p为输入音频x生成语音级别的对抗性样本x
′
。具体而言,假设x中有m个不同的音素,对应了字典p中的p0,
…
,p
m-晦
。对于每一个音素i,通过重复对应的亚音素级扰动pi并注入到x中相应的位置中生成对抗性样本x
′
,图2为基于亚音素级扰动的对抗性样本生成示例图;为了发动成功的伪装,生成的对抗性示例x
′
应该使得针对目标用户y
t
的输出分数应在所有注册用户中最大,同时大于预设阈值θ。因此,设计损失函数如下:
[0068][0069]
为了产生用于对于来自不同语音的音素的p,使其具有泛化干扰能力,进一步使用了训练语料集μ用于扰动优化,而不是单个样本,系统优化器待解决的系统优化问题如下:
[0070][0071]
s.t.||p||
∞
≤∈,
[0072]
其中,是损失函数的期望,g(x,p)表示从原始音频x基于扰动字典p对抗生成对抗性样本x
′
的生成函数,即x
′
=g(x,p),∈是幅度阈值。通过解决上述优化问题,就能够得到一个亚音素级对抗性扰动字典。基于这个字典,能够通过将扰动注入到每一个对应的音素上实现对不同文本内容的语音的对抗性干扰,进而实时伪装。
[0073]
表1语音识别中常用音素
[0074][0075]
以下就跨信道增强器做具体说明。为了增强上述对抗性扰动的物理信道鲁棒性,在上述生成过程中加入了跨信道增强器对亚音素级扰动进行了信道增强。该方法的基本思想是将信道干扰建模成信道脉冲响应c,再通过卷积操作逆向求得被信道干扰后的信号。为了得到信道脉冲响应,本发明采用iso标准中的基本声学测量方法之一基于mls信号测量脉冲响应。具体来说,用发射机播放一个mls信号(即一种特定的伪随机二进制信号),然后在特定环境中传播,最后由接收机接收。通过对接收到的信号和传输的mls信号进行卷积运算,可以导出物理传播系统(包括收发设备模型和环境)的cir。使用这种方法,伪装者只需要在每个设备型号下的每个环境中收集一个样本,以产生不同的信道响应。在获得不同信道的单位脉冲响应之后,在将亚音素级扰动其注入语音之前,先通过卷积操作来增强语音级别的对抗性扰动。因此,系统优化器待解决的系统优化问题转换为如下形式
[0076][0077]
s.t.||p||
∞
≤∈,
[0078]
y(
·
,c)是用单位脉冲响应c增强后的语音,χ是一个收集自多个真实收发设备和多个环境的单位脉冲响应分布。通过使用收集到的单位脉冲响应增强扰动,可以实现跨越各种设备模型和不同环境,最终在物理域发起成功的身份伪装。
[0079]
以下就集成分类器做具体说明。除了信道鲁棒性以外,本发明还公开了集成分类器技术,对亚音素级对抗性扰动的迁移性进行了增强,以满足在不同声纹系统上进行黑盒攻击的需要。具体来说,该技术在扰动优化过程中融合了多个声纹系统的输出,当一个声音样本x输入到优化过程,相应的对抗性扰动基于p生成;然后,将生成的对抗性样本输入给从
预定义的声纹模型集合σ中选择的n个声纹模型,而不仅仅是一个模型,以获得各种输出。在那之后,将n个输出通过加权求和的方式聚合为一个整体。考虑到不同声纹模型在集合中的不同贡献度,本发明还进一步引入注意机制用于实时调整各个模型的权重,即通过迭代注意力系数动态调整每个模型si的组成比,图3为集成分类器示意图;因此,系统优化器待解决的系统优化问题转换为如下形式:
[0080][0081]s·
t.||p||
∞
≤∈,
[0082][0083]
通过集成学习和注意机制,经过校准的扰动将其目标从单一声纹模型扩展到各种声纹模型,从而实现黑盒攻击能力。
[0084]
以下就系统优化器做具体说明。本发明使用的系统优化器为基于pytorch平台的adam优化器,采用mini batch技术进行训练优化。
[0085]
以下就音素识别器做具体说明。音素识别器用于从语音信号中提取音素序列及每一个音素对应的持续时间。在离线训练阶段和在线伪装阶段应用的音素识别器属于同一神经网络系统,其工作流程为:基于双向rnn神经网络模型架构,其工作流程为:对输入音频进行分帧操作,对每一帧进行26维mfcc提取后输入双向rnn网络,输入层为尺寸为26
×
1,隐藏层采用尺寸为256的gru单元,输出层尺寸为40(与使用的音素对应),输出结果经过合并重复音素、纠正错误音素处理后输出音素序列。
[0086]
以下就实时音素对齐器做具体说明。在完成了亚音素级、跨信道和可迁移的对抗干扰的生成后,伪装者需要使用伪装设备需要将扰动注入实时语音。扰动实时注入的前提是准确预测后续音素的类型及定位其在语音中的出现时间。为了定位并预测音素,本发明提出了基准音素序列,该基准音素序列为事先从伪装者在实施攻击前设定的语音文本中推导得到,由输入语音中使用到的音素及其时间戳信息组成,用作对齐的参考。伪装设备将最新录制的语音与伪装者提前设定的基准音素序列对齐,并识别后续同步的音素的正确类型。基准音素序列可以与每次同步的实时语音中最后录制的音素对齐。图4为实时音素对齐器示意图,完整语音的音素序列可以被分为录制到的已录音素序列和待播放音素序列。为了将基准音素序列与已录音素序列中最近录到的音素进行对齐,引入了长期滑动窗口和短期滑动窗口。长期窗口确定一个大范围的搜索区间,该区间从上一次对齐的音素开始,预设持续时间为l,该区间应该包含音素对齐位置。然后,使用一个短期窗口来更准确地定位最新录制的音素。特别是,一个短期窗口在整个基准音素序列的长期窗口中滑动,并应用levenshtein距离来衡量其与覆盖最新录制音素的窗口的相似性。只有当所有测量的音素之间的距离是最佳的,并且不超过预设的阈值时,设备才会将相应的短期窗口中的最后一个音素作为语音中的对齐位置。否则,将录音中的短期窗口向后拉一个音素,并重复上述过程。由于伪装者的语速并不固定,上述对齐会实时不断重复,以避免对齐中累积的错误。
[0087]
以下就实时音素预测器做具体说明,虽然可以通过参考基准音素序列来确定估计的音素序列,但亚音素级扰动的同步仍然需要确定音素的持续时间。然而,这种持续时间在
估计的序列中仍然未知。因此,实时音素预测器应用了一种基于ewma算法的音素持续时间估计方法,该方法动态调整音素级对抗性干扰的持续时间,以跟踪实时流式语音。音素持续时间估计的基本思想是将不同语音的语速标准化为与基准音素序列相同的尺度。具体来说,首先为第i个音素推导出相对于基准音素序列的语速vi,即其中是第i个音素在基准音素序列中的持续时间,是对应音素在已录语音中的持续时间。为了估计音素的持续时间,基于ewma根据之前k个音素推到一个累积语速,即,
[0088][0089]
其中,β是预设的权重。考虑到人类的说话行为近似于lti系统,速度应在一段时间内保持稳定。因此,根据估计的速度,可以将基准音素序列中的音素持续时间重新调整为待播放音素的持续时间,即,
[0090][0091]
其中,m是预测音素段的大小。此后,可以估计下一次校准之前的接下来的音素持续时间,并确定相应亚音素级扰动的数量。特别地,假设每个生成的亚音素级扰动的持续时间是当每个后续音素被预测为p随着时间的流逝根据等式(8),伪装设备重复相应的亚音素级扰动时间为音素水平扰动,然后用扬声器进行播放。
[0092]
为了验证本发明的技术效果,在amax服务器(intel xeon silver 4210r、256gb ram、nvidia rtx a6000)上通过最小化目标函数生成该亚音素级扰动。默认情况下,设置振幅阈值∈=0.02,亚音级扰动持续时间为12.5ms。使用8种不同的录音设备型号和3种不同的环境测量了24个cir用于进行数据增强。此外采用了3种主流声纹模型架构(d-vector、x-vector以及deep speaker)和3个训练数据集(取自voxceleb1/2数据集),一共训练了9个不同的声纹模型,并在测试过程中,取其中1个作为目标系统,采用4个具有不同的结构和训练数据集的白盒模型用于模型集成训练扰动。将本发明部署在seeed respeaker core v2上,作为伪装者的伪装设备。为了控制实验变量,用扬声器edifier m230播放人声,而不是简单地由人说话。而目标声纹系统则部署在带有外部接收前端(即全向麦克风runpu m10w,领夹式话筒takstar tcm-340)的联想小新pro 13上。在每个实验中,播放m230语音作为伪装者的实时语音。在语音播放过程中,伪装设备通过固定在m230附近的领夹式麦克风接收信号,然后根据信号推导出相应的扰动。之后,分别使用两个扬声器(即jbl clip 3和hp dhs)对扰动进行广泛投射,以便在语音中注入。为了模拟物理域攻击,用于播放伪装者语音的m230距离声纹系统前端50cm(40cm
×
30cm),而另一个扬声器(即jbl clip 3或hp dhs)距离为5cm。为了消除累积误差,每0.5s对人声扰动进行一次校准。此外,将延迟设置为0.2~0.4s,以补偿数据处理的时间成本(约0.17~0.23s,从的实施中测量)和信号传输(取值服从均匀分布u(0.05,0.1))。实验在三种不同的室内环境中进行:实验室(7.4
×
5.6m2,38.7dba)、办公室(18.0
×
6.0m2,43.1dba)和阅览室(3.1
×
4.4m2,37.2dba)。
[0093]
作为一种物理伪装,本发明允许伪装者以口述的方式进行认证,同时实时播放相应的干扰。因此,其性能在很大程度上取决于干扰和声音之间同步的准确性。图5本发明流
式同步性能图;图5(a)显示了本发明绝对音素延迟的累积分布函数(cdf)。可以发现,音素延迟的中位数为50ms,超过75%的音素延迟小于100ms,这表明对齐的延迟是可接受的。考虑到同步是定期执行的(例如,在的实现中,每0.5s执行一次),大多数音素的延迟都小于50ms。尽管存在预测错误,但同步过程也会引入音素延迟。考虑到常规同步,这样的时间开销可能会显著影响音素对齐的性能。因此,还评估了同步的时间开销,结果表明,最大、最小和平均时间开销分别为0.13s、0.06s和0.11s,小于同步周期(即0.5s)。因此,所设计的同步机制可以有效地支持所提出的物理攻击。另一方面,图5(b)显示了本发明的命中率cdf。命中率从41.0%到80.9%不等,其中主题值和平均值分别为61.2%和61.3%,表明本发明产生的干扰平均正确地注入了超过60%的音素,有效预测了音素及其出现的时间。此外,还评估了不同同步机制下的性能。除了本发明中提出的机制外,还实现了另外两种机制作为比较,即:(1)真实基准音素序列:使用准确的音素序列和持续时间作为基准音素序列,(2)同步一次:同步仅进行一次。图6为本发明的流式实时伪装的性能图,图6显示了使用本发明和另外两种机制的命中率和攻击成功率(asr)。与同步一次相比,本发明的平均asr和命中率分别高出29.7%和35.1%。这一结果表明,本发明的同步机制对提高物理域的伪装性能具有重要作用。另一方面,可以发现,本发明的命中率比真实基准音素序列低21.8%,但asr只下降了2.4%。这是因为即使一个音素没有被准确估计,由于规则的排列,相应的扰动仍然可能被注入音素附近。这一结果进一步证明了本发明的同步性能良好。
[0094]
物理伪装对各种信道干扰的鲁棒性是另一个重要特性。评估了本发明在不同设备模型和环境通道下的性能。在实验中,实现了另外两种数据增强机制作为比较,即(1)针对性增强:仅应用一个设备模型对(即clip3-m10w)和一个环境(即实验室)进行增强。(2)不增强:不适用数据增广技术产生扰动。图7为本发明在不同信道环境下的性能图,图7(a)显示了四种不同设备型号对(即clip3和dhs作为扬声器,m10w和tcm340作为接收器)下的asr。可以看到,本发明在四种设备型号上分别实现了85.5%、91.0%、86.9%和97.3%的asr。m10w作为接收器的asr稍低,因为m10w是一种灵敏度更高、感应范围更大的会议话筒,因此会引入更多的环境噪声。此外,与不增强相比,本发明的平均asr高出44.4%。这一结果表明,信道增强确实提高了物理伪装中对抗性干扰的鲁棒性。对于针对性增强,其asr在设备模型(即clip3-m10w)上为97.8%,但在其他未知设备模型下分别快速下降至53.9%、51.6%和42.5%。这表明引入足够多的通道响应来增强亚音素级扰动可以显著提高性能。图7(b)显示了三种不同环境(即实验室、办公室和研究)中的asr。可以观察到,asr分别为90.5%、91.3%和88.5%,高于正常值分别为56.1%、53.2%、63.7%。这表明本发明对不同的环境也很健壮。而对于针对性增强,三种环境下的asr分别为92.3%、85.4%和81.5%,差异较小。请注意,这可能是由实验中选择的相对稳定的环境造成的。更复杂的环境可能会引入更多的噪音。但是,只要使用了信道增强技术,本发明就可以保持对不同通道的鲁棒性。
[0095]
进一步评估了本发明在不同模型中的可转移性。图8为本发明在不同模型下的性能图;图8(a)显示了在不同迁移攻击类型(即白盒、跨训练数据、跨模型架构和两者数据和架构)下,使用集成模型和单一模型训练的亚音素级对抗性扰动的asr。可以看到,在三种不同的迁移攻击类型下,采用集成模型的asr分别为94.8%、89.5%和85.5%,分别比单独攻击模型的asr高27.9%、29.4%和37.2%。这表明,与单个模型相比,集成模型有助于提高攻击不同黑盒模型的鲁棒性。此外,还可以观察到,与其他迁移攻击类型相比,跨结构和数据
集攻击表现最差。但是,即使在这种最接近真实物理攻击的情况下,本发明也能实现80%以上的asr,从而验证其有效性。图8(b)显示了集成不同数量的模型下的asr。可以看到,在2、3和4个模型下,平均asr分别为69.7%、82.2%和85.5%,并且随着模型数量的增加呈现出增加的趋势。但结果也表明,随着模型数的增加,asr的增加逐渐变小。这是因为集成模型只能构造更广义的解空间,而不是目标模型的精确解空间。但即使在这样一个不完整的空间中,本发明在4个集合模型下也平均实现了85.5%的asr,证明了它在黑盒模型下的鲁棒性。
[0096]
最后,还通过客观实验评估了本发明在运行过程中产生噪声噪声水平及其引起的人耳感知程度。首先在播放扰动时测量了周围环境中的spl,其中spl由分贝计smart sensor ar844(30~80db,a权重)测量。图9为本发明的噪声和听感测试结果图,图9(a)显示了不同距离和角度下伪装设备周围的spl分布。可见伪装设备前方的spl(即大约0
°
~30
°
)比其他角度都要高。当角度大于30
°
时,超过1米处的声压级低于39.2db,仅比周围环境高0.5db。这一结果表明,只有当周围的人以特定角度出现在伪装设备上时,他/她才能感知到干扰。此外,从距离的角度来看,最大spl 45.1db出现在距离约0.5m处。但当距离增加到2米时,spl迅速衰减到38.9db。考虑到世卫组织共同的社会距离(即1米),如此小的spl很难被周围的人察觉。此外,伪装者可以有意识地控制他/她的设备的方向,以避免周围人的注意。除了使用spl,用梅尔倒谱失真(mcd)进一步评估了物理域中对抗性样本的可听性。此处引入了另一个典型的主流工作fakebob作为基准。然后,以相同的原始语音作为参考,推导出本发明和其他两个基线的mcds。图9(b)分别显示了本发明和mcds。可以看到,三种方法的平均mcd分别为2.45db、2.24db和4.15db。与原始噪声相比,本发明的mcd增加了0.21db,表明由本发明引起的失真与环境噪声的失真相似。另一方面,本发明的平均mcd比fakebob的平均mcd低1.7db。这些结果进一步证明了本发明在正常距离下不会引起周围人群的察觉。
[0097]
最后,还需要注意的是,以上列举的仅是本发明的具体实施例。显然,本发明不限于以上实施例,还可以有许多变形,本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。