1.本发明涉及智慧农田技术领域,尤其涉及一种基于深度学习算法的土壤有机碳密度制图方法、系统、计算机设备和存储介质。
背景技术:
2.目前,全球土壤有机碳soc(soil organic carbon)储量约为15500亿吨,约为大气碳储量的两倍,化石燃烧年排放量的150倍。soc显著影响土壤肥力和作物产量,同时,在调节全球气候变化方面也发挥着重要作用。在全球土壤碳库研究中,土壤有机碳密度socd(soil organic carbon density)是一种表征土壤有机碳储量的常用指标。准确监测socd对调控土壤碳汇以及合理利用土壤资源具有重要意义。
3.近年来,可见光近红外高光谱技术在土壤属性的估算方面有着广泛的应用。该技术能够较为精准的获取土壤属性信息,如土壤侵蚀、重金属污染和土壤有机质等。近端的土壤光谱受外界干扰较小,预测模型往往较为准确。因此,近端光谱技术得到了快速发展,拥有较为成熟的光谱数据处理流程。
4.然而,近端光谱数据只能提供点对点的数据,不适合对土壤属性进行连续的空间预测和制图。卫星遥感可以获取土壤图像信息,为精确的数字土壤制图提供了有效的数据支撑。尽管卫星遥感平台能够获取大范围的土壤影像数据,但其较低的空间分辨率难以满足小尺度农田土壤的精细化监测。
5.相比较卫星平台,机载平台具有更高的空间分辨率和更好的灵活性。以飞机作为遥感监测平台在小规模农田土壤制图中具有更大的优势。机载平台通过搭载rgb、多光谱和高光谱等传感器,采集地表空间连续的光谱信息。由于高光谱影像可以提供更为丰富的光谱信息以确定与土壤属性关系密切的特征波段。因此,机载高光谱影像是土壤属性估算研究中的重要数据源。
6.然而,机载高光谱数据在采集过程中,易受天气条件、植被覆盖等外部因素的干扰,进而降低模型的预测精度。这对机载高光谱数据的处理提出了更高的要求,而目前仍缺乏一套适合机载高光谱数据处理的方法。
技术实现要素:
7.为了解决上述问题,本发明提出一种基于深度学习算法的土壤有机碳密度制图方法、系统、计算机设备和存储介质。
8.本发明通过以下技术方案实现的:
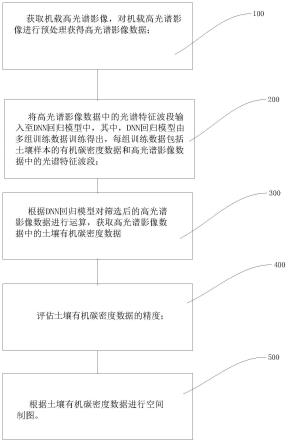
9.一种基于深度学习算法的土壤有机碳密度制图方法,包括如下步骤:
10.对机载高光谱影像进行预处理获得高光谱影像数据;
11.通过遗传算法对高光谱影像数据进行处理,筛选高光谱影像数据中的光谱特征波段;
12.将高光谱影像数据中的光谱特征波段输入至dnn回归模型中,其中,dnn回归模型由多组训练数据训练得出,每组训练数据包括土壤样本的有机碳密度数据和高光谱影像数据中的光谱特征波段;
13.获取高光谱影像数据中的土壤有机碳密度数据;
14.评估土壤有机碳密度数据的精度;
15.根据土壤有机碳密度数据进行空间制图。
16.进一步地,所述获取机载高光谱影像,并对机载高光谱影像进行预处理获得高光谱影像数据的步骤包括:
17.剔除机载高光谱影像中的近红外光范围内的光谱以获得第一处理数据;
18.对第一处理数据进行几何校正处理、镶嵌处理、辐射定标处理和大气校正处理,获取第二处理数据;
19.对第二处理数据进行滤波处理,获取高光谱影像数据。
20.进一步地,所述获取机载高光谱影像,对机载高光谱影像进行预处理获得高光谱影像数据的步骤之前还包括:
21.获取土壤样本的数量及有机碳密度值。
22.进一步地,所述对第二处理数据进行滤波处理的步骤包括:使用savitzky-golay滤波拟合法对第二处理数据进行滤波处理。
23.进一步地,所述通过遗传算法对高光谱影像数据进行处理,筛选高光谱影像数据中的光谱特征波段的步骤包括:
24.获取高光谱影像数据,将高光谱数据的特征波段的编码成变量,获取种群的大小、适应度函数、突变率、迭代次数和初始变量集;其中,种群的大小代表变量的数量,适应度函数为偏最小二乘法的交叉验证均方根误差;
25.对种群进行多次繁殖和突变;
26.当适应度函数不再增加或者达到迭代次数时,输出变量组合,再将变量组合转化为高光谱数据的特征波段的数目。
27.进一步地,所述获取dnn回归模型的步骤中,dnn回归模型包括:
28.将筛选后的高光谱影像数据中的光谱特征波段进行压缩,获得输入层;
29.通过隐藏层对光谱特征波段进行分类;
30.通过输出层线性输出土壤有机碳密度。
31.进一步地,所述评估土壤有机碳密度数据的精度的步骤包括:
32.根据交叉验证决定系数、平均绝对误差、交叉验证的均方根误差和相对均方根误差的大小,对土壤有机碳密度数据的精度进行评估;
33.其中,交叉验证决定系数表示为:
[0034][0035]
平均绝对误差表示为:
[0036][0037]
交叉验证的均方根误差表示为:
[0038][0039]
相对均方根误差表示为:
[0040][0041]
式中,表示输出层线性输出的土壤有机碳密度值,为土壤样本的有机碳密度值的平均值,yi为土壤样本的有机碳密度值,n为土壤样本的数量。
[0042]
本发明还提出一种基于机载高光谱影像和深度学习算法的农田土壤有机碳密度制图系统,包括:
[0043]
获取模块,所述获取模块用于获取机载高光谱影像;
[0044]
筛选模块,所述筛选模块用于根据遗传算法对高光谱影像数据进行处理;
[0045]
运算模块,所述运算模块用于根据dnn回归模型对筛选后的高光谱影像数据进行运算;
[0046]
评估模块,所述评估模块用于评估土壤有机碳密度数据的精度。
[0047]
本发明还提出一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项方法的步骤。
[0048]
本发明还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项方法的步骤。
[0049]
本发明的有益效果:
[0050]
本发明采用了遗传算法和dnn回归模型相结合的方法,其中,遗传算法可以筛选对土壤有机碳密度估算至关重要的光谱变量,还能保留了原始光谱变量的物理意义,深度学习算法建立土壤有机碳密度与光谱变量间复杂的非线性关系,充分结合发挥了二者的优势,可有效提高土壤有机碳密度估算的精度。
附图说明
[0051]
图1为本发明的实施例中的基于深度学习算法的土壤有机碳密度制图方法的原理图;
[0052]
图2为本发明的预设区的机载高光谱影像及采样点分布示意图;
[0053]
图3为本发明进行sg滤波前后的光谱曲线比较示意图;
[0054]
图4为本发明的遗传算法示意图;
[0055]
图5为本发明的plsr模型的原理示意图;
[0056]
图6为本发明的ga模型运行结果示意图;
[0057]
图7为本发明的dnn回归模型结构示意图;
[0058]
图8为本发明的dnn模型训练过程rmse与损失值的变化示意图;
[0059]
图9为本发明的光谱波段在ga模型中的使用频率示意图;
[0060]
图10为本发明的ga模型所选特征波段所在位置示意图;
[0061]
图11为本发明的dnn模型估算socd的散点图;
[0062]
图12为本发明的模拟出的socd空间分布图。
具体实施方式
[0063]
为使本发明的目的、技术方案及效果更加清楚、明确,以下对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0064]
请参考图1,一种基于深度学习算法的土壤有机碳密度制图方法,包括如下步骤:
[0065]
100、获取机载高光谱影像,对机载高光谱影像进行预处理获得高光谱影像数据;
[0066]
在一些采样方式中,通过在飞机或直升机上搭载headwall micro-hyperspec传感器,在预设区域获取高光谱影像(图2),再获取高光谱影像的过程中,环境条件要保持阳光充足、天空无云。高光谱传感器主要包括a系列(可见光-近红外)和x系列(近红外)。由于土壤有机碳soc(soil organic carbon)对可见光区域的光谱反射率影响最为显著,因此,本发明使用a系列成像光谱仪采集的高光谱影像数据。由于高光谱影像是直接拍摄获取的,高光谱影像内含有外部干扰产生的部分影像,需要对有干扰的部分进行消除,所以需要对高光谱影像进行预处理。
[0067]
200、通过遗传算法对高光谱影像数据进行处理,筛选高光谱影像数据中的光谱特征波段。
[0068]
对于高光谱影像数据而言,其包含多个光谱变量,光谱变量中往往包含噪声或者干扰信号,这可能会降低后续的计算精度。将受噪声影响严重或对响应变量不敏感的光谱变量剔除,往往能够提高模型的精度。高光谱影像数据变量筛选的方法主要有小波分析、连续投影法和主成分分析法等,相比于这几种在数据层面上的降维算法,其不能保存光谱变量的物理意义,并且会造成数据的部分丢失。本发明将遗传算法进行高光谱影像数据的光谱特征波段的筛选。不仅保留了原始光谱变量的物理意义,还能筛选出对土壤有机碳密度socd(soil organic carbon density)估算至关重要的光谱变量。
[0069]
300、将高光谱影像数据中的光谱特征波段输入至dnn回归模型中,其中,dnn回归模型由多组训练数据训练得出,每组训练数据包括土壤样本的有机碳密度数据和高光谱影像数据中的光谱特征波段;
[0070]
根据dnn回归模型对筛选后的高光谱影像数据进行运算,获取高光谱影像数据中的土壤有机碳密度数据。
[0071]
400、评估土壤有机碳密度数据的精度。通过对土壤有机碳密度数据的精度的评估,可以判定模型的准确性,也能为优化和修改dnn回归模型提供依据。
[0072]
500、根据土壤有机碳密度数据进行空间制图。
[0073]
本发明采用了遗传算法和dnn回归模型相结合的方法,其中,遗传算法可以筛选对土壤有机碳密度估算至关重要的光谱变量,还能保留了原始光谱变量的物理意义,深度学习算法建立土壤有机碳密度与光谱变量间复杂的非线性关系,充分结合发挥了二者的优势,可有效提高土壤有机碳密度估算的精度。
[0074]
进一步地,步骤200包括:
[0075]
剔除机载高光谱影像中的近红外光范围内的光谱以获得第一处理数据;近红外范围内的一些波长的光谱由于受水汽的严重影响,故予以剔除。
[0076]
对第一处理数据进行几何校正处理、镶嵌处理、辐射定标处理和大气校正处理,获取第二处理数据;
[0077]
对第二处理数据进行滤波处理,获取高光谱影像数据。
[0078]
在一些实施例中,使用savitzky-golay滤波拟合法对第二处理数据进行滤波处理。
[0079]
采用标准的rgb正射数字航空影像对机载高光谱影像进行几何校正和镶嵌处理;再采用黑、白、灰标准的标定布对影像进行辐射定标处理,以得到具有实际物理意义的辐射亮度数据;使用flaash(fast line-of-sight-atmospheric analysis of spectral hypercubes)模型进行大气校正,以剔除大气、阳光或其他外部因素的影响;最后,对原始高光谱影像进行savitzky-golay滤波处理(下文也称sg滤波),以减少原始光谱的噪声,在滤波平滑的同时,能够更有效地保留信号的变化信息,更好地保持数据的观测信息。
[0080]
在一些实施例中,savitzky-golay滤波中,较低的多项式次数能够产生平滑结果,但是有可能出现偏置。较高的多项式次数能降低偏置,但有可能过拟合而导致结果噪声过多。为了使滤波后的数据更加平滑,savitzky-golay滤波处理的滤波窗口设为20,多项式次数设为2。
[0081]
图3展示了原始光谱曲线与经sg滤波后的光谱曲线形态,可以看出原始光谱曲线中具有较多噪声,影响光谱质量,而经过sg滤波后的光谱曲线则较为平滑,减少了大量噪声的同时又保留了原始光谱曲线的形态特征。
[0082]
进一步地,步骤100之前还包括:获取土壤样本的数量及有机碳密度值。
[0083]
设定采样点间距,在预设区域内搜集表层土壤样本。将土壤样本分析仪测量土壤有机碳soc。采用重量法测量土壤的水分。土壤容重sbd(soil bulk density)由金属环中湿土的体积和重量计算。筛分和称量砾石得到砾石浓度。土壤有机碳密度socd采用现有公式计算:
[0084][0085][0086]
式中,θi为砾石浓度,sbdi为土壤容重,soci为土壤有机碳含量,hi为土壤厚度,soil
wet
为金属环内湿土的重量,v为金属环的体积,m为土壤湿度。
[0087]
进一步地,步骤300包括:
[0088]
图4展示的是遗传算法(也称ga模型)的基本流程。
[0089]
首先以光谱变量作为输入数据,进行变量的编码,用由0和1组成的字串表示种群中的个体(即染色体),0代表变量未被选中,1表示变量被选中。
[0090]
第二步生成初始群体,随机生成指定个数(如32、64、128)的染色体,染色体的个数称为种群大小,这些染色体构成了一个初始群体。
[0091]
第三步进行适应度评价,通常采用偏最小二乘法的交叉验证均方根误差作为适应
度函数,因为其可以表明每个个体的预测能力。
[0092]
第四步遗传繁殖,生成新的染色体群体,可被视为下一代,其包含两个过程:复制和交叉,在复制过程中最好的染色体会更容易被选中,在交叉过程中染色体之间会进行随机搭配进行重组,即某染色体的一部分会与其他染色体的一部分进行交换重组。
[0093]
最后一步为突变,在此过程中会随机对染色体中的编码进行改变,若为1则会变为0,突变的概率通常被设定为相当小的值。
[0094]
在遗传算法模型的适应度评价环节中,本发明结合了最小二乘回归plsr(partial least squares regression)方法,将遗传算法选择的个体(变量组合)与socd的实测值进行plsr建模,采用交叉验证求出均方根误差,交叉验证的均方根误差越小代表该个体(变量组合)的预测能力越佳。
[0095]
plsr能够对给定的自变量进行压缩,并将其投影到几个潜在变量lvs(latent variables)中去。这些少量的lvs既能够很好地表达自变量,又与因变量高度相关。
[0096]
图5显示了plsr中的变量关系,光谱变量的反射率即为plsr模型的自变量x,假设其为n
×
m的矩阵。socd即为因变量y。
[0097]
通过投影变换将自变量x矩阵转换为n
×
a(a<m)的矩阵t,实现数据降维。则有x=t
×
p e,其中,p为投影矩阵,e为残差矩阵。则在plsr中,构建x与y的关系就变成了求解t与y的关系,提高了模型效率与精度。
[0098]
在遗传算法中,种群大小代表变量组合的数量,数量越大,每次迭代的时间就越多;窗口宽度表示组合在一起的相邻变量的个数;初始变量集表示初始群体中编码为1的数量占总变量数的大致比例,初始变量集的多少将影响模型选择的最终变量数量;收敛百分比,可理解为当满足要求的个体数目达到一定比例时收敛;突变率是指变量组合中的变量被其他变量替换的概率,突变率过高将导致最终变量集中特征变量的数量不足。
[0099]
在一些实施例中,遗传算法的具体参数设置如表一所示。
[0100]
表1 ga模型参数设置
[0101][0102]
图6所示的是ga模型的运行结果,由图6(a)可以看出当模型使用的变量组合中包
含29个波段时,适应度最小,这表明由ga选择的最佳波段数量为29。图6(b),上方的曲线为平均适应度曲线,下方的曲线为最佳适应度曲线,表明随着迭代次数的增加,模型的适应度呈现降低的趋势,当迭代次数达到63时,程序被终止。图6(c)显示了ga使用波段的数量随着迭代次数增加而减少,使用波段数量为29时达到最佳数量。图6(d)展示了各波段在ga中的使用频率,一般来说,某个波段的使用频率越高则该波段对模型的作用越显著。
[0103]
进一步地,所述获取dnn回归模型的步骤中,dnn回归模型包括:
[0104]
将筛选后的高光谱影像数据中的光谱特征波段进行压缩,获得输入层;
[0105]
隐藏层,所述隐藏层具有三个全连接层;
[0106]
为提高socd估算的准确性,本发明采用dnn回归模型。一个浅层神经网络结构一般由一个输入层、一个隐藏层和一个输出层组成,其中隐藏层中包含许多神经元,这些神经元的数量对最终的模型输出具有重要影响。不同于浅层神经网络,本发明采用的dnn回归模型通常具有更多的隐藏层,这使其具有更出色的学习能力,可以解决更为复杂的非线性问题。本发明设计了由一个输入层、三个隐藏层和一个输出层组成的dnn回归模型结构(参考图7)。光谱数据将被压缩成对应于每个采样点的一维向量,并作为模型的输入层。隐藏层为三个全连接层,由第一至第三个隐藏层分别具有10、8、5个神经元。
[0107]
在dnn回归模型中,每一层的输出都是上一层的线性函数,为提升模型解决非线性问题的能力,往往需要引入激活函数,激活函数可将其非线性化,避免单纯的线性组合,从而提高预测能力。线性整流函数relu(rectified linear unit)是神经元常用的激活函数,具有较为优异的表现,其表示为:
[0108][0109]
为了防止过拟合,本发明还添加了一个dropout函数(丢弃函数),丢弃率为0.1,可随机丢弃一部分神经网络单元,使其不参与训练,提高模型的泛化能力。
[0110]
输出层,所述输出层线性输出土壤有机碳密度;
[0111]
dnn回归模型以某个指标为线索寻找最优权重参数,该指标称为损失函数(loss),损失函数可指示网络性能的优劣程度,损失函数表示为:
[0112][0113]
其中,n为样本的数量,yi表示为土壤样本的有机碳密度值,代表输出层线性输出的田土壤有机碳密度值。
[0114]
dnn回归模型网络中的初始权值是随机分配的,为取得最佳效果需要不断地更新权值,本发明采用自适应矩估计adam(adaptive moment estimation)优化器的梯度下降算法进行权值更新。参数(网络权值)的学习更新速率由学习率(learn rate)控制,更新的方向与梯度相反。adam优化器将动态修改每个参数的学习率,因此每个参数都具有不同的自适应学习率。学习率可控制模型的学习进度,学习率若设置过大,则易造成损失过大,学习率过小则易产生过拟合、收敛速度满等现象。
[0115]
在一些实施例中,dnn回归模型的参数设置如下。
[0116]
表2 dnn回归模型具体参数设置
[0117][0118]
将高光谱影像数据中的光谱特征波段输入至dnn回归模型中,其中,dnn回归模型由多组训练数据训练得出,每组训练数据包括土壤样本的有机碳密度数据和高光谱影像数据中的光谱特征波段;训练过程历时约30秒,共进行了100次迭代。图8展示了dnn模型训练过程中的均方根误差rmse、损失loss随迭代的变化过程,可以看出,随着迭代次数的增加rmse整体上呈现下降的趋势,损失值loss也在不断地减少。
[0119]
进一步地,所述评估土壤有机碳密度数据的精度的步骤包括:
[0120]
通过交叉验证决定系数、平均绝对误差、交叉验证的均方根误差和相对均方根误差对土壤有机碳密度数据的精度进行评估;交叉验证决定系数越大(越接近1),平均绝对误差、交叉验证的均方根误差和相对均方根误差越小,土壤有机碳密度数据的精度也就越高。
[0121]
交叉验证决定系数表示为:
[0122][0123]
平均绝对误差表示为:
[0124][0125]
交叉验证的均方根误差表示为:
[0126][0127]
相对均方根误差表示为:
[0128]
[0129]
式中,n为样本的数量,yi表示为土壤样本的有机碳密度值,代表输出层线性输出的土壤有机碳密度值。
[0130]
图9显示了各光谱波段在ga模型中的使用频率。若一个变量被使用的频率越高表明它更有可能是特征波段。被选择的特征波段位置如图10所示。与socd有关的光谱特征波段主要集中在420-530nm、600-700nm和770-860nm的光谱区域,而在730nm附近的光谱区域缺乏特征波段。经过ga模型的变量选择,最终选取了29个光谱特征波段,大大减少了数据冗余。
[0131]
为评价ga模型在socd预测过程中的作用,本发明比较了使用ga特征波段与使用全波段进行socd预测的效果,回归模型采用pls方法。由表3可以看出,与使用全波段的方法预测socd相比,使用ga模型的特征波段的预测精度要更佳。
[0132]
因此,使用ga模型进行波段选择可提高模型的预测精度。
[0133][0134]
图11展示了利用dnn回归模型估算socd的散点图,可以看出使用dnn回归模型估算socd具有较高的精度,表现为较高的r2(0.9224),以及较低的rmsecv(0.2152)、mae(0.1376)和rrmse(5.032%)。
[0135]
为突出本发明中dnn回归模型的预测效果,本发明还采用了pls回归模型对socd进行估算,并比较dnn回归模型与pls回归模型的预测精度。
[0136]
如表4所示,dnn回归模型的r2(0.9224)显著高于pls模型(r2=0.6721),与pls模型相比,dnn回归模型具有更为出色的预测效果。上述结果表明回归模型适用于socd的估算,具有较高的估算精度,为本发明采用回归模型对整个研究区的socd进行制图提供了可靠保障。
[0137]
表4 dnn与pls回归模型的socd预测效果比较
[0138][0139]
基于光谱特征波段采用dnn回归模型估算整幅影像的socd,其空间分布如图12所示。在研究区内socd的差异显著,整体上呈现“南高北低”和“东西高,中部低”的趋势。在研究区中南部的socd较低,socd最低的区域位于研究区中部靠近河流南侧的位置。研究区内socd的变化范围在1.0~7.1kg/m2之间。
[0140]
本发明还提出一种基于机载高光谱影像和深度学习算法的农田土壤有机碳密度制图系统,包括:
[0141]
获取模块,所述获取模块用于获取机载高光谱影像;
[0142]
筛选模块,所述筛选模块用于根据遗传算法对高光谱影像数据进行处理;
[0143]
运算模块,所述运算模块用于根据dnn回归模型对筛选后的高光谱影像数据进行运算;
[0144]
评估模块,所述评估模块用于评估土壤有机碳密度数据的精度。
[0145]
本发明还提出一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项方法的步骤。
[0146]
本发明还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项方法的步骤。
[0147]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0148]
当然,本发明还可有其它多种实施方式,基于本实施方式,本领域的普通技术人员在没有做出任何创造性劳动的前提下所获得其他实施方式,都属于本发明所保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。