1.本发明涉及个性化数据推荐研究领域,特别涉及一种基于三重自编码机结合知识图谱的电影推荐方法。
背景技术:
2.现如今,在所有与信息相关的应用场景中,随着互联网的快速发展,迫切需要个性化推荐来解决信息超载问题。
3.值得注意的是,许多成功的推荐系统共享了特征表示学习的各个方面,并已被广泛应用于许多在线服务,如电子商务和社交网络。现有的推荐系统方法大致可以分为三类:基于内容的推荐、协同过滤(cf)和混合方法。
4.基于内容的推荐方法学习项目的描述性特征,根据这些特征计算新项目与用户喜欢的项目之间的相似度,并生成最终的推荐,但要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况。协同过滤方法通过考虑用户的历史行为发现用户的倾向,并产生推荐,但是面临着评分矩阵的稀疏问题以及泛化能力弱问题,为了解决这些问题,矩阵分解技术被提出,主要操作是从评分矩阵中学习用户或者商品的隐特征来优化推荐准确性,并且在实际应用中取得了重大的成功,但是矩阵分解方法在特征表示学习能力上存在局限性,因为大多方法通过直接对评分矩阵分解来学习用户以及商品的特征表示而没考虑额外信息。混合推荐方法将多种方法结合在一起,并尝试结合这些方法的优点,但是很难从其他信息源中获得辅助信息,而且大部分辅助信息本身很稀疏,很难有效、直接地融入推荐系统提高推荐精度。
技术实现要素:
5.本发明的目的是克服现有技术缺陷,提供一种基于三重自编码机结合知识图谱的电影推荐方法,能够利用用户和电影之间的交互信息和知识图谱对电影信息进行特征扩展,并将半自动编码机和自动编码机串行连接,为用户进行更准确推荐。
6.本发明的目的是这样实现的:一种基于三重自编码机结合知识图谱的电影推荐方法,包括以下步骤:
7.1)将用户和电影之间的评论信息编码为情感分类,作为自动编码机的输入,用于生成项目的辅助信息;
8.2)基于电影的评级、辅助信息和生成的评论表示合并到半自动编码器中用于重构输出,通过半自动编码器学习获得扩展信息的低维特征表示,将获得的低维特征表示融合到电影的原始特征空间中,并将新的特征作为额外信息输入到半自编码机模型中;
9.3)设计半自动编码器和自动编码器的串行连接,通过获取半自动编码器生成的输出,再将生成的输出重新输入到第三个自动编码器中,将第三个自编码器的输出预测评分矩阵与原始的评分矩阵进行对比,计算预测精度,进行更精确的电影的推荐。
10.进一步的,所述步骤1)具体包括:
11.步骤1.1)使用beautifulsoup网页爬虫技术,对movielens数据集中的对应电影进行评论信息的搜索;
12.步骤1.2)解析爬取评论的所在语句“'#main》section》div.lister》div.lister-list》div》div.review-container》div.lister-item-content》div.content》div.text.show-more__control'”,对搜索到的网页结果进行筛选,提取出需要的评论信息,结果作为初始特征扩展。
13.进一步的,所述步骤2)具体包括:
14.步骤2.1)通过公式(1)以及公式(2)完成自编码机模型进行训练,保留评论信息模型参数:
15.ξs=f(wsc bs)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
16.s=g(w
′s·
ξs b
′s)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
17.其中,ws∈r
k1
×n和w
′s∈rn×
k1
是自编码机的权值矩阵,bs∈r
k1
×1,b
′s∈rn×1是偏置向量,f和g是非线性激活函数,k1是隐藏层单位的特征维数,s
′
为s的低维度表示第一个自动编码机的隐藏特征;并将其合并到第二个半自动编码机中,用于从所有输入中采样不同的子集来捕获不同的表示并进行重构;
18.步骤2.2)在获得重构的评论特征之后,应用半自动编码机,引用电影i的评分向量ri和其他的辅助信息ai,重构评论特征si和扩展特征li,将四个向量连接得到con(ri,ai,si,li):
19.con(ri,ai,si,li)=concatenation of ri,a,s
i and liꢀꢀꢀꢀꢀ
(3)
20.通过得到的组合向量,再将所有的电影信息合并连接,得到半自动编码机的输入为con(ri,ai,si,li):
21.步骤2.3)通过步骤2.2)得到的con(ri,ai,si,li)作为输入数据输入到半自编码机模型中获得压缩的重构输出;半自动编码器的编码级定义如公式(4)所示:
22.r
′
semi
=g(w
′
f(wcon(ri,ai,si,li) b) b1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
23.其中,和w
′
∈rk×m代表权重矩阵;和是偏置向量,f和g是非线性激活函数。
24.进一步的,所述步骤3)体包括:
25.步骤3.1)设计第三个自动编码机模型来学习整个输入的重构,三重自编码器的编码和解码阶段分别表示为如公式(5)和(6)所示:
26.θ=f(w
tr′
semi
b
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
27.r
′
=g(w
′
t
θ b
′
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
28.权重矩阵w
t
和w
′
t
的2范数正则化被添加到目标函数,其被表示如公式(7)所示:
[0029][0030]
因此,三重自动编码器的最终目标函数如公式(8)所示:
[0031]jitem
=||(r
′‑r′
semi
)||2 αjrꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0032]
利用l-fbgs算法,迭代计算w
t
,w
′
t
,b
t
,b
′
t
,迭代计算完成后,得到整个输入的重构矩阵r
′
,根据r
′
,将user对item得分超过0.5的物品对用户进行推荐。
[0033]
本发明采用以上技术方案,与现有技术相比,有益效果为:1)使用自编码机模型学
习用户于与电影之间的交互信息的特征表示,自编码机模型具有收敛速度快,不需要标签和有效性好的特点,使本方法具有更强的实用性;
[0034]
2)本发明使用知识图谱对电影信息进行特征扩展,同时扩展得到的额外特征使用自编码机抽取低维特征表示,将原始用户电影评分矩阵、原始特征以及通过自编码机处理的扩展特征通过半自编码机再一次特征提取,再将输出重构输入到自编码机里,从而可以更加方便、灵活的应用到推荐模型中。
[0035]
3)本发明设计了半自动编码器和自动编码器的串行连接,以学习更好的特征表示从而提高模型推荐的准确率。
附图说明
[0036]
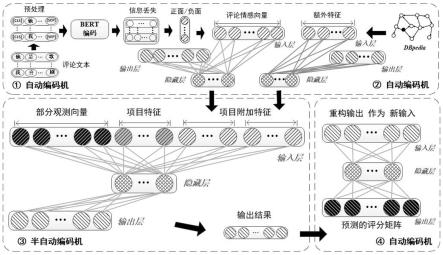
图1本发明的总体框架图。
[0037]
图2本发明中自编码机模型结构示意图。
[0038]
图3本发明中半自编码机模型结构示意图。
具体实施方式
[0039]
如图1所示的一种基于三重自编码机结合知识图谱的电影推荐方法,包括以下步骤:
[0040]
1)将用户和电影之间的评论信息编码为情感分类,作为自动编码机的输入,用于生成项目的辅助信息;
[0041]
步骤1.1)使用beautifulsoup网页爬虫技术,对movielens数据集中的对应电影进行评论信息的搜索;“https://www.imdb.com/title/tt' value '/reviews?ref_=tt_urv”,该url中参数value值分别设置为电影对应的imdbid;
[0042]
步骤1.2)解析爬取评论的所在语句“'#main》section》div.lister》div.lister-list》div》div.review-container》div.lister-item-content》div.content》div.text.show-more__control'”,对搜索到的网页结果进行筛选,提取出需要的评论信息,结果作为初始特征扩展。
[0043]
2)基于电影的评级、辅助信息和生成的评论表示合并到半自动编码器中用于重构输出,通过半自动编码器学习获得扩展信息的低维特征表示,将获得的低维特征表示融合到电影的原始特征空间中,并将新的特征作为额外信息输入到半自编码机模型中实现更准确的电影推荐;
[0044]
步骤2.1)通过公式(1)以及公式(2)完成自编码机模型进行训练,保留评论信息模型参数:
[0045]
ξs=f(wsc bs)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0046]
s=g(w
′s·
ξs b
′s)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0047]
其中,ws∈r
k1
×n和w
′s∈rn×
k1
是自编码机的权值矩阵,bs∈r
k1
×1,b
′s∈rn×1是偏置向量,f和g是非线性激活函数,k1是隐藏层单位的特征维数,s
′
为s的低维度表示第一个自动编码机的隐藏特征;并将其合并到第二个半自动编码机中,用于从所有输入中采样不同的子集来捕获不同的表示并进行重构;
[0048]
步骤2.2)在获得重构的评论特征之后,应用半自动编码机,引用电影i的评分向量ri
和其他的辅助信息ai,重构评论特征si和扩展特征li,将四个向量连接得到con(ri,ai,si,li):
[0049]
con(ri,ai,si,li)=concatenation of ri,a,s
i and liꢀꢀꢀꢀꢀ
(3)
[0050]
通过得到的组合向量,再将所有的电影信息合并连接,得到半自动编码机的输入为con(ri,ai,si,li);
[0051]
步骤2.3)通过步骤2.2)得到的cat(ri,ai,si,li)作为输入数据输入到半自编码机模型中获得压缩的重构输出;半自动编码器的编码级定义如公式(4)所示:
[0052]r′
semi
=g(w
′
f(wcon(ri,ai,si,li) b) b1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0053]
其中,和w
′
∈rk×m代表权重矩阵;和是偏置向量,f和g是非线性激活函数。
[0054]
3)设计半自动编码器和自动编码器的串行连接,通过获取半自动编码器生成的输出,再将生成的输出重新输入到第三个自动编码器中,以学习用于个性化推荐的更抽象和更高级的特征表示,将第三个自编码器的输出(预测评分矩阵)与原始的评分矩阵进行对比,计算预测精度,极大的提高了电影推荐的准确度;
[0055]
步骤3.1)设计第三个自动编码机模型来学习整个输入的重构,三重自编码器的编码和解码阶段分别表示为如公式(5)和(6)所示:
[0056]
θ=f(w
tr′
semi
b
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0057]r′
=g(w
′
t
θ b
′
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0058]
权重矩阵w
t
和w
′
t
的2范数正则化被添加到目标函数,其被表示如公式(7)所示:
[0059][0060]
因此,三重自动编码器的最终目标函数如公式(8)所示:
[0061]jitem
=||(r
′‑r′
semi
)||2 αjrꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0062]
利用l-fbgs算法,迭代计算w
t
,w
′
t
,b
t
,b
′
t
,迭代计算完成后,得到整个输入的重构矩阵r
′
,根据r
′
,将user对item得分超过0.5的物品对用户进行推荐。
[0063]
本发明可通过以下实验进一步说明:
[0064]
为了测试本发明的有效性,分别在movielens 100k和movielens 1m数据集上实现预测结果,其中movielens 100k数据集包括943个用户对1682部电影的100000个评分,movielens 1m数据集包括6040个用户对3706部电影的1000209个评分,评价指标用均方根误差(rmse),计算公式如下,这个值越小,推荐系统越好。
[0065][0066]
其中,r
u,i
和分别表示原始的和重构的用户u对电影i的评分,|testset|表示的整个测试集。
[0067]
为了表明测试结果的性能,100k数据集选择了非负矩阵分解(nmf)、改进版奇异值分解(svd )和一种知识图谱结合自编码机推荐系统(prkg)作为对比;1m选择了非负矩阵分解(nmf)、基于多层感知机的推荐系统(ncf)和基于半自编码机推荐系统(hcrsa)作为对
比,数据集预测结果如表1所示,由表1可知本发明在三种数据集上的预测结果方根误差(rmse)指标优于其他方法。
[0068]
表1 rmse指标的实验结果
[0069][0070]
本发明能够使用用户和电影之间的交互信息和知识图谱对电影进行特征扩展,然后使用自编码机对获得的稀疏特征信息进行降维,提取高效的特征表示,从而解决推荐面临的辅助信息缺少以及稀疏的问题。其次,通过半自编码机对原始特征信息和扩展特征信息进行降维,提取特征,输出预测结果。最后将预测结果通过自编码机进行再一次的特征压缩提取,半自动编码器和自动编码器的串行连接,以学习用于个性化推荐的更抽象和更高级的特征表示,为用户实现更准确的推荐。
[0071]
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。