1.本文件涉及人工智能领域,尤其涉及一种需融资企业识别方法、模型训练方法、装置和设备。
背景技术:
2.近年来,近年来,金融需求探索(financial needs exploration,fne)引起了金融机构和学术研究者的极大关注,其目的是探索金融受限的中小企业。由于中小企业在经济发展中的重要性,以及这些企业在财务上的受限制情况,fne变得越来越重要。金融机构较为关注的一个问题是如何有效地发现资金紧缺需要融资的中小企业,从而降低金融机构的营销成本并更好地助力中小企业的成长。针对该问题,金融机构尝试基于数据挖掘技术,从中小企业的属性和历史行为中发现需融资企业的共性,以定位到需融资企业。
3.但是,现有的方案在定位需融资企业的准确度较差。
技术实现要素:
4.本说明书实施例提供一种需融资企业识别方法、装置和电子设备,能够准确高效地定位到资金紧缺的企业。
5.本说明书实施例提供一种需融资企业识别方法,包括:
6.将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量;
7.基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组并确定各关系三元组的分数;
8.基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件,其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关;
9.基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型;
10.基于训练后的需融资企业识别模型,以及不具有融资需求标签的目标企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,识别目标企业是否为需融资企业。
11.本说明书实施例提供一种需融资企业识别模型的训练方法,包括:
12.将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量;
13.基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组并确定
各关系三元组的分数;
14.基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件,其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关;
15.基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型。
16.本说明书实施例还提供一种需融资企业识别装置,包括:
17.邻域结构学习模块,将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量;
18.关系三元组生成模块,基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组;
19.关系三元组分数确定模块,确定各关系三元组的分数;
20.图卷积网络参数调整模块,基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件,其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关;
21.识别模型训练模块,基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型;
22.预测模块,基于训练后的需融资企业识别模型,以及不具有融资需求标签的目标企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,识别目标企业是否为需融资企业。
23.本说明书实施例还提供一种电子设备,包括:
24.处理器;以及
25.被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处理器执行以下操作:
26.将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量;
27.基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组并确定各关系三元组的分数;
28.基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件,其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关;
29.基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型;
30.基于训练后的需融资企业识别模型,以及不具有融资需求标签的目标企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,识别目标企业是否为需融资企业。
31.本说明书实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如下操作:
32.将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量;
33.基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组并确定各关系三元组的分数;
34.基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件,其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关;
35.基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型;
36.基于训练后的需融资企业识别模型,以及不具有融资需求标签的目标企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,识别目标企业是否为需融资企业。
37.本说明书实施例采用的上述至少一个技术方案实现了以下技术效果:
38.通过根据目标企业群体的图谱信息进行邻域结构学习和邻域连接学习,再根据学习完毕后得到的企业节点的嵌入向量和企业节点的融资需求标签训练需融资企业识别模型,以便根据训练好的需融资企业识别模型和目标企业节点的嵌入向量预测目标企业是否为需融资企业,从而能够大大提高需融资企业的定位准确度,以便融资产品投放机构能够将融资产品高效地投放到需要融资的企业中。
附图说明
39.此处所说明的附图用来提供对本说明书的进一步理解,构成本说明书的一部分,本说明书的示意性实施例及其说明用于解释本说明书,并不构成对本说明书的不当限定。在附图中:
40.图1为本说明书提供的企业资金关系场景示意图。
41.图2是本说明书实施例的一种需融资企业识别方法流程图。
42.图3是本说明书实施例基于实体关系组合算子和多头自注意力机制的节点的嵌入向量汇聚过程示意图。
43.图4是本说明书实施例节点的嵌入向量投影到关系超平面的示意图。
44.图5为本说明书一实施例提供的需融资企业识别装置的结构示意图。
45.图6为本说明书一实施例提供的一种电子设备的结构示意图。
具体实施方式
46.为使本说明书的目的、技术方案和优点更加清楚,下面将结合本说明书具体实施例及相应的附图对本说明书技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本文件保护的范围。
47.为便于理解本说明书实施例,下面引入一些名词解释。
48.异构图(heterogeneousgraph):是描述一组对象的结构,其中某些对象对在某种意义上是“相关的”。这些对象对应于称为节点的数学抽象,并且每个相关的节点对都称为边。异构图中可以存在不只一种节点和边的类型。
49.中小企业图谱(small and medium-sized graph):是一种基于图的数据结构,其中节点代表的是小微企业,链接代表的是中小企业之间的关系,如控股关系、合资关系、上下游关系、转账关系等。
50.资金紧缺(financially constrained):是一种企业状态,指企业所拥有的资金量少于维持企业正常生产所需要的资金量。银行需要从海量的小微企业中定位到资金紧缺的小微企业,以更好地助力小微企业的发展。
51.嵌入(embedding):在深度学习网络模型中常见的一个层,主要是用来处理稀疏特征的向量表示。它不但可以解决one-hot向量的长度问题,还可以将特征之间的相似性表征出来。
52.注意力机制(attention mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制。深度学习中注意力机制的核心是从关注深度网络中的全部信息到关注重点信息。
53.图卷积网络(graph convolution network):是一种能处理图结构数据的军妓神经网络,通过对目标节点的邻域进行信息聚合或传递,从而更新节点上的embedding,进而进行下游任务的神经网络。
54.图注意力网络(graphattentionnetwork):是图卷积网络的一种改进,在聚合邻居信息的过程中,通过学习邻居的权重,图注意力网络可以实现对邻居的加权聚合。因此,它不仅对于噪音邻居较为鲁棒,注意力机制也赋予了模型一定的可解释性。
55.超平面(hyperplane):是指n维线性空间中维度为n-1的子空间。它可以把线性空间分割成不相交的两部分,从而使得在分割前难以区分的两个向量在分割后得以区分。
56.关系平移(relational translation):是一种异构图上的计算两个节点之间的关系是否成立的方法。该方法通过将异构中的关系看作实体间的某种平移向量,即对于每个事实关系三元组,首先将实体和关系表示在同一个向量空间中,然后把关系向量看作是头实体向量和尾实体向量之间的平移。
57.应理解,在本说明书实施例中,企业之间存在多种异构关系,例如,合作关系、母公司关系、供应商关系、股份所有者关系、股份担保人关系、共同所有者关系,等等。为便于理解,下面以母公司关系和供应商关系进行举例说明。
58.图1是本说明书实施例企业关系的场景示意图。如图1所示,当前企业a中,存在两种异构的企业关系母公司关系和供应商关系。其中,企业b是企业a的母公司,会为企业a提供资金以供企业a发展;企业a是企业c的供应商,或者说企业a是企业c的上游企业,下游企业c需要向上游企业a提供作为货款的资金。如图1所示,母公司与子公司是一对多的关系,一个母公司可能存在多个子公司,需要为多个子公司提供资金;上下游公司是多对多的关系,一个企业可能存在多个供应商,也可能同时作为多个企业的供应商,即一个企业可能存在多个下游企业,也可能同时存在多个上游企业。
59.在如此复杂的企业异构关系中,不同的企业关系对应的资金流量关系也不同。此外,在不同的企业关系中,邻居节点的资金需求对当前节点的影响因子也不同。
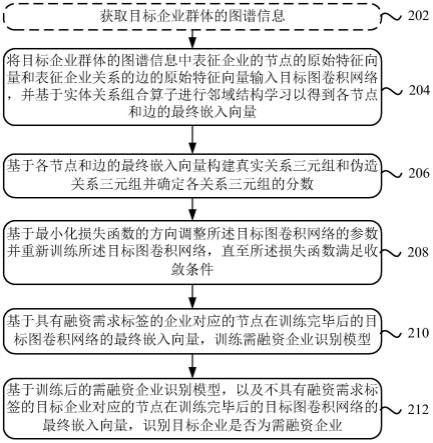
60.为了兼顾各种不同企业关系对企业融资需求的影响,本说明书实施例提出了一种需融资企业识别模型的训练方法。图2是本说明书实施例的一种需融资企业识别方法流程图。如图2所示,该方法可包括:
61.步骤s202,生成目标企业群体的图谱信息。
62.其中,所述图谱信息中的任一个节点对应于所述目标企业群体中的一个企业,所述图谱信息中的任一条边对应于边连接的两个节点对应的两个企业的关系。
63.应理解,生成企业图谱信息的过程属于现有技术,具体实现可参考现有技术的相关内容,本说明书实施例在此不再赘述。本说明书中,以中小型企业(small and medium-sized enterprise,sme)群体为例进行举例说明,此时目标企业群体的图谱信息即为sme图,可表示为g=(v,ε,δ,h,r)。其中,
64.v,表示sme的节点的集合。
65.ε,表示sme之间的异构关系类型的集合(即sne图中的边的集合)。
66.δ,表示关系三元组的集合。对于每个关系三元组(h,r,t)∈δ,h表示边的头节点,r表示边的关系类型,t表示边的尾节点。
67.h,表示所有sme图中所有节点的原始节点特征矩阵。
68.r,表示所有sme图中所有节点之间关系类型的关系特征矩阵。
69.应理解,本说明书实施例中,企业之间可包括多种关系,例如,合作关系、母公司关系、供应商关系、股份所有者关系、股份担保人关系、共同所有者关系,等等。当然,应理解,在本说明书实施例中,主要考虑的是因为各种企业关系导致的不同的资金流动关系。例如,a公司是b公司的母公司,当b公司有资金需求时,会存在a公司向b公司划拨资金的资金流动关系;又例如,b公司是c公司的供应商,当b公司向c公司提供物品时,会存在c公司需向b公司支付货款的资金流动关系。
70.当然,应理解,对本说明书实施例来说,步骤s202是可选地,还可以直接获得图谱信息,例如,可从预存储的数据库直接读取,或者从第三方得到,或者等等,本说明书实施例对此不作限制。
71.步骤s204,将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入(embedding)向量。
72.其中,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量。具体地,所述实体关系组合算子用于汇聚目标节点的邻居节点的嵌入向量以及目标节点与邻居节点的连接边的嵌入向量,以得到邻居节点的嵌入向量传递到目标节点后的嵌入向量。
73.应理解,本说明书实施例中,节点和边的最终嵌入向量,是指目标图卷积网络的最后一个卷积层输出的节点和边的嵌入向量。
74.应理解,本说明书实施例中,通过目标图卷积网络对目标企业群体的图谱信息进行邻域结构学习。应理解,在基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量时,可基于实体关系组合算子逐层汇聚各目标节点的邻居节点和连接边的
嵌入向量以得到邻居节点的嵌入向量传递到目标节点后的嵌入向量,并逐层转换边的嵌入向量到下一层卷积层。也即:基于实体关系组合算子逐层汇聚各节点的邻居节点和边的嵌入向量,以得到各节点和边在所述目标图卷积网络中各卷积层输出的嵌入向量。。在本说明书实施例中,目标图卷积网络的卷积层数量l是一个超参数,是可配置的。本说明书实施例可根据需要选择不同的l值,以得到最优的需融资企业识别模型。例如,l值可取值为2、3、5、8、10、20等等,每个l值可分别得到一个最优的需融资企业识别模型。但是,不同的l值训练得到模型的代价和训练后的模型的预测准确率是不一样的,在配置l值时,需要考虑训练代价和预测准确率的平衡。
75.应理解,在图卷积网络中,每个卷积层都有对应的嵌入向量输入和嵌入向量输出。在本说明书实施例中,目标图卷积网络的第l层卷积层中,其输入是一组节点的嵌入向量h和一组边(关系)的嵌入向量r。具体可用如下向量表示:
76.第l层卷积层输入的节点的嵌入向量其中,|v|表示节点集合v的节点数量。表示节点i在图卷积网络中的第l层卷积层的输入特征向量。第l 1层卷积层输入的节点嵌入向量,也即第l层卷积层输出的节点嵌入向量。
77.第l层卷积层输入的节点嵌入向量其中,|ε|表示关系集合ε的关系数量。表示边(关系)i在图卷积网络中的第l层卷积层的输入特征向量。第l 1层卷积层输入的边的嵌入向量,也即第l层卷积层输出的边的嵌入向量。
78.特别地,在第1层卷积层中,其输入即节点的原始特征向量和边的原始特征向量。
79.本说明书实施例中,为了区别不同关系类型的邻居节点的重要性,引入一个可设计了一个实体-关系组合算子,通过对邻居节点和边的嵌入向量进行合成运算以聚合来自邻居节点和边的嵌入向量。对于每个节点u,首先聚合来自一跳邻居的嵌入向量输入来计算每个节点的嵌入向量输出。根据该实体关系组合算子,可确定该节点u的每个邻居节点v的嵌入向量,以及节点u和邻居节点v对应的边的嵌入向量传递到该节点后的嵌入向量。每个邻居节点u的嵌入向量和边的嵌入向量可确定一个传递后的嵌入向量之后可通过一个变换矩阵对节点u的各邻居节点传递到节点u的嵌入向量进行线性变换后,然后再通过预设函数f()进行非线性变换处理,以得到节点u对应的嵌入向量输出。应理解,该预设函数f()可选择多种激活函数,本说明书实施例对此不作限制。
80.可选地,该邻域结构学习过程可包括:
81.根据实体关系组合算子、目标节点的目标邻居节点在目标卷积层的嵌入向量输入,以及目标节点与目标邻居节点的连接边在目标卷积层的嵌入向量输入,确定目标卷积层中目标邻居节点的嵌入向量传递到目标节点后的嵌入向量;
82.根据目标卷积层对应的第一线性变换矩阵,以及目标卷积层中目标节点的各邻居节点的嵌入向量传递到目标节点后的嵌入向量,确定目标节点在目标卷积层对应的嵌入向量输出;其中,目标卷积层对应的第一线性变换矩阵用于对目标卷积层输入的节点嵌入向量进行线性变换处理;
83.确定所述目标图卷积网络的最后一个卷积层输出的各节点和边的嵌入向量为所述各节点和边的最终嵌入向量。
84.可选地,根据目标卷积层对应的第一线性变换矩阵,以及目标卷积层中目标节点的各邻居节点的嵌入向量传递到目标节点后的嵌入向量,确定目标节点在目标卷积层对应的嵌入向量输出,可包括:
85.根据目标卷积层对应的第一线性变换矩阵,对目标卷积层中目标节点的各邻居节点的嵌入向量传递到目标节点后的嵌入向量进行线性变换,得到目标邻居节点对应的第一变换参数;
86.对目标节点的各邻居节点对应的第一变换参数进行累加后进行预设的非线性变换处理,以得到目标节点在目标卷积层对应的嵌入向量输出。
87.可选地,第l层中节点u的嵌入向量输出(也即第l 1层中节点u的嵌入向量输入)表示如公式(1)所示:
[0088][0089]
其中,n(u)表示节点u的一跳邻居集合,t(u,v)表示节点u的邻居节点v和节点u的关系类型,表示第l层卷积层中节点u的邻居节点v和节点u的关系的嵌入向量输入,表示第l层卷积层中节点u的邻居节点v的嵌入向量输入,根据实体-关系合成算子、邻居节点v的嵌入向量和关系t(u,v)的嵌入向量将邻居节点v的嵌入向量传递到节点u后的嵌入向量,表示表示在图卷积网络中的第l层卷积层中的节点嵌入向量变换矩阵,用于对第l层卷积层输入的节点嵌入向量进行线性变换处理;函数f()为激活函数,用于对该函数内的参数进行预设的非线性变换处理。
[0090]
另外,由于节点u在公式1中的嵌入向量的更新会变换原始向量空间,第l 1层输入的关系向量也要做相应的变换。各边在各个卷积层的嵌入向量输出过程可包括:
[0091]
根据目标卷积层对应的第二线性变换矩阵,对目标边在目标卷积层对应的嵌入向量输入进行线性变换处理,再对线性变换处理后的参数进行所述预设的非线性变换,得到目标边在目标卷积层对应的嵌入向量输出,其中,目标卷积层对应的第二线性变换矩阵用于对目标卷积层输入的边的嵌入向量进行线性变换处理。
[0092]
可选地,目标图卷积网络中的第l层卷积层中第i个关系嵌入向量输出和对应的第i个关系嵌入向量输入的关系,可如公式(2)所示:
[0093][0094]
其中,表示在目标图卷积网络中的第l层卷积层中的关系变换矩阵。根据目标图卷积网络中的第l层卷积层中第i个关系嵌入向量输入结合关系变换矩阵和激活
函数f(),即可得到目标图卷积网络中的第l层卷积层中关系嵌入向量输出应理解,用于计算节点嵌入向量的公式(1)的激活函数f(),和用于计算边嵌入向量的公式(2)的激活函数f(),可以相同也可以不同,但一般选择使用相同的激活函数。
[0095]
通过上述公式(1)和公式(2),目标图卷积网络可对目标企业群体的图谱中的边(关系)的多类型异构性建模,同时保持关系类型建模的空间复杂度为(o(|ε|d
l
)),即在特征维数上是线性的,其中,|ε|表示目标企业群体的图谱中的节点数,d
l
表示第l层的嵌入向量的特征维数。
[0096]
当然,应理解,如果仅依靠实体-关系合成算子对邻居节点的嵌入向量和边的嵌入向量进行聚合,可能存在一定的缺陷,例如不能将可变大小的邻居作为输入来处理,而是集中在最相关的邻居上进行聚合。
[0097]
优选地,为了解决上述问题,可引入了一种自注意力机制,通过关注邻居节点来计算图中每个节点的嵌入向量。为了稳定自注意力机制的学习过程,本说明书实施例扩展了该机制,采用多头自注意力机制。此时,可基于实体关系组合算子和多头自注意力机制进行邻域结构学习以得到各节点和边的最终嵌入向量。应理解,在基于实体关系组合算子和多头自注意力机制进行邻域结构学习时,可逐层汇聚各节点的邻居节点的嵌入向量和各边的嵌入向量,以得到各节点和边在所述目标图卷积网络中各卷积层输出的嵌入向量,从而得到最后一层卷积层输出的各节点和边的最终嵌入向量。
[0098]
具体地,引入多头自注意力机制的节点的嵌入向量汇聚过程可包括:
[0099]
根据实体关系组合算子、目标节点的目标邻居节点在目标卷积层的嵌入向量输入,以及目标节点与目标邻居节点的连接边在目标卷积层的嵌入向量输入,确定目标卷积层中目标邻居节点的嵌入向量传递到目标节点后的嵌入向量;
[0100]
根据目标卷积层对应的第三线性变换矩阵,目标节点在目标卷积层的嵌入向量输入中的目标分维向量,以及目标卷积层中目标节点的目标邻居节点的嵌入向量传递到目标节点后的嵌入向量,确定目标节点的目标邻居节点在目标分维向量和目标卷积层对应的自注意力系数并进行归一化处理得到归一化自注意力系数,其中,目标卷积层对应的第三线性变换矩阵用于对目标卷积层输入的节点嵌入向量进行线性变换处理;
[0101]
根据目标节点的各邻居节点在目标分维向量和目标卷积层对应的归一化自注意力系数、目标卷积层对应的第三线性变换矩阵、目标卷积层中目标节点的各邻居节点的嵌入向量传递到目标节点后的嵌入向量,确定目标节点在目标卷积层和目标分维向量对应的聚合特征;
[0102]
对目标卷积层中目标节点的各目标分维向量对应的聚合特征进行合并操作以得到目标节点在目标卷积层的嵌入向量输出;
[0103]
确定所述目标图卷积网络的最后一个卷积层输出的各节点和边的嵌入向量为所述各节点和边的最终嵌入向量。
[0104]
图3是本说明书实施例基于实体关系组合算子和多头自注意力机制的节点的嵌入向量汇聚过程示意图。下面结合图3,对本说明书实施例的节点的嵌入向量汇聚过程进行描述。
[0105]
在图3中,h1、h2、h3、h4、h5、h6和h7分别表示节点1-7的原始特征向量;r1是节点2与节
点4的关系,表示资金从节点4资金向节点2流入;r2是节点2与节点5的关系,表示资金从节点5资金向节点2流入;r3是节点2与节点6的关系,表示资金从节点2流出到节点6;r4是节点2与节点7的关系,表示资金从节点2流出到节点7;α
12
表示表示节点2对节点1的注意力,α
13
分别表示节点3对节点1的注意力,r5表示节点2和节点1的关系,r6表示节点3和节点1的关系。为了表示多头注意力机制中不同的分维向量对应的注意力,可进一步加上分维向量对应的多头标记进行区分。。concat/avg表示对聚合得到的向量h1进行向量合并操作或求平均操作,以得到相应的嵌入向量输出h1’
。图3表示某一层神经网络下,节点1的向量嵌入更新机制。α表示注意力,h表示嵌入向量。注意力上有三条线(一实两虚线),表示三头注意力。当然,图3的示意图仅供参考,不对本说明书实施例的汇聚过程构成任何限制。
[0106]
应理解,本说明书实施例中其中,多头自注意力机制中的多头参数值k也是一个超参数,是可配置的。本说明书实施例中也可分别选择多种k值,以得到最优的需融资企业识别模型。对于每个节点u,在第k个头中,可用共享的注意力单层前馈神经网络a:计算节点u的邻居节点v的自注意力系数,具体可如公式(3)所示:
[0107][0108]
其中,表示在第l层卷积层的注意头k中的所有节点的共享的线性变换矩阵。
[0109]
此外,本说明书实施例可选择由权重向量参数化的单层前馈神经网络a,并应用leakyrelu函数进行非线性化处理。其中,d
l
表示第l层卷积层的嵌入向量的维度数。此时,公式(3)可表示为:
[0110][0111]
其中,||表示向量合并操作,以将各分维度向量组合为一个多维向量。
[0112]
公式(3)、(4)中计算的自注意力系数揭示了节点u的邻居节点v的嵌入向量对节点u的嵌入向量的重要性。为了使得不同邻居之间的自注意力系数易于比较,可使用例如softmax函数之类的函数对节点u在其所有邻居节点的的自注意力系数进行归一化处理。具体可如公式(5)所示:
[0113][0114]
在得到归一化的注意力系数后,可计算每个节点u的第k头的自注意力系数,然后连接k个独立的自注意力系数以获得每个节点u的嵌入向量输出。具体地,根据目标节点的各邻居节点在目标分维向量和目标卷积层对应的自注意力系数、目标卷积层对应的第三线性变换矩阵、目标卷积层中目标节点的各邻居节点的嵌入向量传递到目标节点后的嵌入向量,确定目标节点在目标卷积层和目标分维向量对应的聚合特征,可包括:
[0115]
根据目标节点的目标邻居节点在目标分维向量和目标卷积层对应的自注意力系
数、目标卷积层对应的第三线性变换矩阵、目标卷积层中目标邻居节点的嵌入向量传递到目标节点后的嵌入向量,进行乘法运算后以得到目标节点的目标邻居节点对应的聚合特征值;
[0116]
对目标节点的各邻居节点对应的聚合特征值进行累加再进行预设的非线性变换处理,以得到目标节点在目标卷积层和目标分维向量对应的聚合特征。
[0117]
其中,节点u在卷积层l和分维向量k对应的聚合特征对应的具体实现公式可如公式(6)所示:
[0118][0119]
当然,应理解,在本说明书实施例中,该合并操作可能存在多种操作方式。
[0120]
可选地,作为一个实施例,对目标卷积层中目标节点的各目标分维向量对应的聚合特征进行合并操作以得到目标节点在目标卷积层的嵌入向量输出,可包括:
[0121]
对目标卷积层中目标节点的各目标分维向量对应的聚合特征进行向量合并操作以得到目标节点在目标卷积层的嵌入向量输出。
[0122]
此时,公式(1)的表述可更改为如公式(7)所示:
[0123][0124]
其中,||表示k个自注意力系数的向量合并操作,以形成一个k维的特征向量。
[0125]
可选地,作为一个实施例,对目标卷积层中目标节点的各目标分维向量对应的聚合特征进行合并操作以得到目标节点在目标卷积层的嵌入向量输出,可包括:
[0126]
当所述目标卷积层不是目标图卷积网络的最后一层卷积层时,对目标卷积层中目标节点的各目标分维向量对应的聚合特征进行向量合并操作以得到目标节点在目标卷积层的嵌入向量输出;
[0127]
当所述目标卷积层是目标图卷积网络的最后一层卷积层时,对目标卷积层中目标节点的各目标分维向量对应的聚合特征进行平均操作或加权平均操作以得到目标节点在目标卷积层的嵌入向量输出。
[0128]
也就是说,在最后一层卷积层输出节点的嵌入向量的过程中,可采用多种其他处理方式替代向量合并操作。例如,可将向量合并操作替换为取平均值的操作,具体如公式(7)所示:
[0129][0130]
当然,还可以将上述取平均值的操作替换为其他操作,例如,进行加权平均,求平方和,等等。本说明书实施例对此不作限制。
[0131]
应理解,本说明书实施例的多头自注意力机制的效率较高,因为该机制可以对节
点的邻居们进行并行化处理。此外,该多头自注意力机制适用于可归纳学习的问题,可推广到不可预见节点数量的场景中。
[0132]
通过上述的实体关系算子和多头自注意力机制,即可得到最后一层卷积层输出的各节点和边的嵌入向量。
[0133]
步骤s206,基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组并确定各关系三元组的分数。
[0134]
其中,关系三元组可包括头节点的嵌入向量,尾节点的嵌入向量和头尾节点的连接边的嵌入向量。
[0135]
应理解,经过前述步骤s204的邻域结构学习过程后,可从目标图卷积网络中获取各节点和各边最终的嵌入向量输出。根据每个边的头节点和尾节点最终输出的嵌入向量和每个边最终输出的嵌入向量,可得到真实关系三元组δ。对于每个关系三元组(h,r,t)∈δ,h表示边的头节点,r表示边的关系类型,t表示边的尾节点。
[0136]
此外,本说明书实施例中,还可生成伪造的关系三元组。伪造关系三元组中的头节点的嵌入向量,尾节点的嵌入向量和头尾节点的连接边的嵌入向量中至少一种是伪造的。本说明书实施例引入关系三元组的分数这一指标,以区分真实关系三元组和伪造关系三元组。
[0137]
确定关系三元组的分数可包括:
[0138]
根据所述关系三元组中的头节点的嵌入向量,尾节点的嵌入向量、头节点和尾节点的连接边的嵌入向量,确定所述关系三元组的聚合向量;
[0139]
基于所述关系三元组的聚合向量,确定所述关系三元组的分数。
[0140]
应理解,在通过邻域结构学习对目标企业群体的图谱的读出过程中,由于忽略了图中的关系的多结构异构性,例如一对一、一对多、多对一和多对多等,获得的节点的嵌入向量和关系三元组的准确度会存在一定偏差。例如,如果r是多对一的结构映射,即(h,r,t)∈δ,那么我们将获得所有h的相同的最终输出表示,即h0=h1=
……
=hm,这在真实场景中是不合理的。类似地,如果r是一对多的结构映射,即那么我们将得到t0=t1=
……
=tm,这也不合理。
[0141]
为了解决多结构异构性带来的问题,可在关系超平面上引入了一种转换机制,以对节点的嵌入向量进行区分。此时,将关系三元组的头节点嵌入向量和尾节点嵌入向量投影到连接边嵌入向量的超平面以确定关系三元组的分数。
[0142]
可选地,作为一个实施例,根据所述关系三元组中的头节点的嵌入向量,尾节点的嵌入向量、头节点和尾节点的连接边的嵌入向量,确定所述关系三元组的聚合向量,包括:
[0143]
获取目标关系三元组的头节点嵌入向量投影到目标关系三元组的连接边嵌入向量的超平面的第一投影向量,以及目标关系三元组的尾节点嵌入向量投影到目标关系三元组的连接边嵌入向量的超平面的第二投影向量;
[0144]
对所述第一投影向量、所述目标关系三元组的连接边嵌入向量和所述第二投影向量按序求矢量和;
[0145]
将所述矢量和作为根据所述关系三元组的聚合向量。
[0146]
当然,应理解,本说明书实施例还可通过其他方式确定关系三元组的聚合向量,例
如,对所述关系三元组中的头节点的嵌入向量,尾节点的嵌入向量、头节点和尾节点的连接边的嵌入向量按序求和,以得到所述关系三元组的聚合向量。本说明书实施例对此不作限制。
[0147]
在得到关系三元组的聚合向量后,即可基于关系三元组的聚合向量确定关系三元组的分数。类似地,本说明书实施例可通过多种方式确定关系三元组的分数。可选地,可获取关系三元组的聚合向量的向量二范数作为所述目标关系三元组的分数。或者,按照聚合向量的各维度对应的加权值对聚合向量进行变换处理得到关系三元组的分数,等等。
[0148]
图4是本说明书实施例节点的嵌入向量投影到关系超平面的示意图。如图4所示,节点2的嵌入向量2可通过投影到不同的关系超平面r1和r2进行区分。在每个关系类型r下,可利用向量wr将每个节点的嵌入向量hs投影到超平面中以获得节点的嵌入向量投影此时,每个关系三元组(s,r,o)=(s,t(s,o),o)的分数可以如下公式(9)所示:
[0149][0150]
其中,wr表示关系r对应的超平面的范数向量。
[0151]
也就是说,当计算关系三元组时,关系超平面上的转换机制使得每个节点在不同的关系类型下具有可区分的嵌入向量,这避免了将节点的嵌入向量折叠为相同的情况。利用该评分函数分别处理资金转入关系三元组和资金转出关系三元组,邻域结构学习过程中的第l层卷积层的实体关系组合算子φ可以被实例化如下:
[0152][0153]
其中,δ
in
(o)和δ
out
(o)分别表示资金转入关系三元组和资金转出关系三元组。其中,表示超平面在图卷积网络中的第l层卷积层中的关系类型r的投影向量。
[0154]
此外,在每个l层的邻域结构学习过程中,每个关系超平面投影向量将进行矩阵变换。具体如公式(11)所示
[0155][0156]
其中,表示在图卷积网络中的第l层卷积层中的关系超平面变换矩阵。
[0157]
步骤s208,基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件。
[0158]
其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关。
[0159]
应理解,在通过邻域结构学习过程中的k个卷积层获得节点和边的嵌入向量后,本说明书实施例可进行连接结构学习。由于真实关系三元组的分数预计较高,而伪造关系三元组的分数较低,为了最大化真实关系三元组和伪造关系三元组之间的区别,可使用以下基于差值的损失函数:
[0160][0161]
其中δ和δ
′
分别表示真实关系三元组和伪造关系三元组,zi表示来自目标图卷积网络的节点i最终的嵌入向量输出,γ是分隔正关系三元组和负关系三元组的余量。
[0162]
当期望最小化损失函数时,为了保证来自目标图卷积网络的每个关系类型r的嵌入向量r
rl 1
被调整到关系超平面中,可考虑以下约束:
[0163][0164]
其中∈是确保正交性的误差向量。有了这些约束,公式(12)可以重写为:
[0165][0166]
本说明实施例中,可基于上述公式(14),采用多种方式来最小化上述损失函数,例如采用随机梯度下降(sgd),或者其他梯度下降算法,等等。
[0167]
基于最小化上述损失函数的思路,我们可对目标图卷积网络中任意的第l层卷积层的线性变换矩阵w
ln,k
,w
lr
和w
lw
,以及每个关系r的权重向量a、超平面的范数向量wr等进行调整,然后重新训练目标图卷积神经网络,直至损失函数满足收敛条件。
[0168]
步骤s210,基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型。
[0169]
在得到最后一次训练后的目标图卷积网络后,可得到各企业对应的节点在最后一次训练的目标图卷积网络的最后一个卷积层输出的嵌入向量,以基于各节点的最终嵌入向量和融资需求标签训练需融资企业识别模型,具体训练过程可参考现有技术,下面做一下简单介绍。
[0170]
此时,可将取出具有融资需求标签(可包括需要融资和不需要融资两种标签)的企业集合,划分为训练集和预测集,然后根据训练集和对应的融资需求标签,训练需融资企业识别模型,根据预测集和对应的融资需求标签确定需融资企业识别模型的预测准确性,以便决定是否进行下一轮的训练。
[0171]
当然,应理解,本说明书实施例中,可采用多种人工智能算法对融资企业识别模型进行训练,例如xgboost(extremegradientboosting)算法、梯度提升树(gradient boosting decision tree,gbdt)算法,等等,本说明书实施例对此不作限制。
[0172]
步骤s212,基于训练后的需融资企业识别模型,以及不具有融资需求标签的目标企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,识别目标企业是否为需
融资企业。
[0173]
在完成需融资企业识别模型的训练后,即可基于需融资企业识别模型,对还没有融资需求标签的企业进行识别,以筛选出需要融资的企业。
[0174]
本说明书实施例中,通过根据目标企业群体的图谱信息进行邻域结构学习和邻域连接学习,再根据学习完毕后得到的企业节点的嵌入向量和企业节点的融资需求标签训练需融资企业识别模型,以便根据训练好的需融资企业识别模型和目标企业节点的嵌入向量预测目标企业是否为需融资企业,从而能够大大提高需融资企业的定位准确度,以便融资产品投放机构能够将融资产品高效地投放到需要融资的企业中。
[0175]
本说明书实施例还提供了一种需融资企业识别模型的训练方法,可包括上述实施例中步骤s202-步骤s210所示的步骤,本说明书实施例在此不再赘述。
[0176]
图5为本说明书一实施例提供的需融资企业识别装置的结构示意图,参见图5,所述装置具体可以包括:
[0177]
邻域结构学习模块510,将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量;
[0178]
关系三元组生成模块520,基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组;
[0179]
关系三元组分数确定模块530,确定各关系三元组的分数;
[0180]
图卷积网络参数调整模块540,基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件,其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关;;
[0181]
识别模型训练模块550,基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型;
[0182]
预测模块560,基于训练后的需融资企业识别模型,以及不具有融资需求标签的目标企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,识别目标企业是否为需融资企业。
[0183]
本说明书实施例的需融资企业识别装置还可执行图2所示实施例的方法,并实现对应模块在图2对应步骤的功能,具体实现可参考图2所示实施例,不再赘述。
[0184]
另外,应当注意的是,在本说明书的装置的各个部件中,根据其要实现的功能而对其中的部件进行了逻辑划分,但是,本说明书不受限于此,可以根据需要对各个部件进行重新划分或者组合。
[0185]
图6为本说明书一实施例提供的一种电子设备的结构示意图,参见图6,该电子设备包括处理器、内部总线、网络接口、内存以及非易失性存储器,当然还可能包括其他业务所需要的硬件。处理器从非易失性存储器中读取对应的计算机程序到内存中然后运行,在逻辑层面上形成需融资企业识别装置。当然,除了软件实现方式之外,本说明书并不排除其他实现方式,比如逻辑器件抑或软硬件结合的方式等等,也就是说以下处理流程的执行主体并不限定于各个逻辑单元,也可以是硬件或逻辑器件。
[0186]
网络接口、处理器和存储器可以通过总线系统相互连接。总线可以是isa
(industry standard architecture,工业标准体系结构)总线、pci(peripheral component interconnect,外设部件互连标准)总线或eisa(extended industry standard architecture,扩展工业标准结构)总线等。所述总线可以分为地址总线、数据总线、控制总线等。为便于表示,图6中仅用一个双向箭头表示,但并不表示仅有一根总线或一种类型的总线。
[0187]
存储器用于存放程序。具体地,程序可以包括程序代码,所述程序代码包括计算机操作指令。存储器可以包括只读存储器和随机存取存储器,并向处理器提供指令和数据。存储器可能包含高速随机存取存储器(random-access memory,ram),也可能还包括非易失性存储器(non-volatile memory),例如至少1个磁盘存储器。
[0188]
处理器,用于执行所述存储器存放的程序,并具体执行:
[0189]
将目标企业群体的图谱信息中表征企业的节点的原始特征向量和表征企业关系的边的原始特征向量输入目标图卷积网络,并基于实体关系组合算子进行邻域结构学习以得到各节点和边的最终嵌入向量,所述实体关系组合算子用于汇聚目标节点的邻居节点和对应的连接边的嵌入向量;
[0190]
基于各节点和边的最终嵌入向量构建真实关系三元组和伪造关系三元组并确定各关系三元组的分数;
[0191]
基于最小化损失函数的方向调整所述目标图卷积网络的参数并重新训练所述目标图卷积网络,直至所述损失函数满足收敛条件,其中,所述损失函数与真实关系三元组和伪造关系三元组的分数差值相关;
[0192]
基于具有融资需求标签的企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,训练需融资企业识别模型;
[0193]
基于训练后的需融资企业识别模型,以及不具有融资需求标签的目标企业对应的节点在训练完毕后的目标图卷积网络的最终嵌入向量,识别目标企业是否为需融资企业。
[0194]
上述如本说明书图2所示实施例揭示的需融资企业识别装置执行的方法可以应用于处理器中,或者由处理器实现。处理器可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器可以是通用处理器,包括中央处理器(central processing unit,cpu)、网络处理器(network processor,np)等;还可以是数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field-programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本说明书实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本说明书实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。
[0195]
基于相同的发明创造,本说明书实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储一个或多个程序,所述一个或多个程序当被包括多个应用程序的
电子设备执行时,使得所述电子设备执行图2对应的实施例提供的需融资企业识别方法或需融资企业识别模型的训练方法。
[0196]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0197]
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0198]
本领域内的技术人员应明白,本说明书的实施例可提供为方法、系统、或计算机程序产品。因此,本说明书可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本说明书可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0199]
本说明书是参照根据本说明书实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0200]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0201]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0202]
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
[0203]
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
[0204]
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动
态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
[0205]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
[0206]
本领域技术人员应明白,本说明书的实施例可提供为方法、系统或计算机程序产品。因此,本说明书可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本说明书可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0207]
以上所述仅为本说明书的实施例而已,并不用于限制本说明书。对于本领域技术人员来说,本说明书可以有各种更改和变化。凡在本说明书的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本说明书的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。