1.本发明涉及一种冲击地压预测模型,具体是一种专家知识与数据融合驱动的冲击地压预测模型构建方法,属于监测预警技术领域。
背景技术:
2.煤炭是我国的基础能源和重要原料,煤炭工业是关系国家经济命脉和能源安全的重要基础产业。冲击地压是严重威胁矿井安全生产的煤岩动力灾害执意。冲击地压以其突然、急剧、猛烈的破坏特征,对煤矿、金属矿井、隧道等正常生产构成严重影响,重则造成巨大的经济损失和人员伤亡。
3.随着矿井开采深度的增加,冲击地压的危险也在逐步增加,原本没有发生过冲击地压的矿井也开始发生;原本发生过冲击地压的矿井,现在冲击强度越来越大,频率也越来越高。然而冲击地压发生的时间、地点、区域和震源等的复杂多样性和冲击地压的突发性,使得其预测工作极为困难复杂,成为亟需解决的世界性难题。
4.传统的预测方法主要有以下两种:
5.1)根据研究人员通过已有的物理模型提出的物理方法来解释和描述矿震,同时通过冲击地压知识来研究矿震前兆提取的显式特征,这在理论体系中具有很强的可解释性,能够真实地描述某一背景下的矿震。然而,这些人工设计的特征可能无法充分利用矿震序列中包含的信息;
6.2)利用深度学习方法提取矿震数据的隐式特征来建立相应的模型进行预测,虽然能够充分利用矿震序列所包含的信息,但从理论体系上看,其解释能力较弱。
7.上述两种方法均无法全面准确地预测冲击地压发生的概率,因此,如何全面准确的预测冲击地压发生的概率成为目前亟需解决的技术问题。
技术实现要素:
8.针对上述现有技术存在的问题,本发明提供一种专家知识与数据融合驱动的冲击地压预测模型构建方法,能够全面准确地预测冲击地压发生的概率。
9.为实现上述目的,本发明提供一种专家知识与数据融合驱动的冲击地压预测模型构建方法,包括
10.1)通过微震传感器采集原始数据,包括矿震时间、矿震能量和震源坐标;
11.2)矿震数据处理:将原始数据转化为用于预测模型输入的前兆模式序列数据,并进行统计分析,计算得到每日最大能量值和平均能量值,生成以日为最小单位的时间序列数据,指定前兆模式序列长度,生成前兆模式序列及其标签,作为海量矿震数据;
12.3)特征提取:包括专家知识驱动的显式特征提取和数据驱动的隐式特征提取
13.根据不同矿区的矿震指标,利用主成分分析法(pca)处理该矿区的矿震指标,得到每个矿震指标所占的权重大小,并根据矿区的实际需要以及矿震指标的权重选择所要使用的矿震指标组合,该矿震指标组合为提取出的隐式特征;
14.数据驱动的隐式特征提取:将步骤2)中的海量矿震数据输入至深度卷积神经网络中进行隐式特征提取;
15.4)构建预测模型:将步骤2)的海量矿震数据作为训练数据集样本生成预测模型,该预测模型包括特征融合模块和分类网络模块,在特征融合模块中利用注意力机制对显式特征提取和隐式特进行深度融合,得到的融合后的特征,并将该特征输入到分类网络模块中,经分类网络模块处理后,得到有无大能量事件的概率,若有大能量矿震事件概率大于无大能量矿震事件概率,则输出1,反之输出0,从而实现冲击地压大能量事件的预测。
16.与现有技术相比,本发明将专家知识即人工选择的矿震指标(显式特征)与海量矿震数据(隐式特征)深度融合在一起,实现了全面准确的预测冲击地压发生的概率。在训练过程中,本发明预测模型可以根据批样本和总体样本的分布情况,动态调整各类别在计算损失的权重。在网络训练中,使用目标函数计算预测模型的损失值,通过不断更新神经网络模型中的参数,使得预测模型在训练数据集上的损失最小化。此外,在冲击地压预测任务中,为了减小大能量对事件的漏报率,本发明在目标函数中添加了各类别的学习权重z0和z1,通过调整大能量事件的学习权重,使得预测模型可以更偏向大能量样本的预测,从而降低了大能量事件的漏报率,有效地改善了数据类别不平衡的问题,有效加快了模型收敛速度,并提高了模型预测准确率。
附图说明
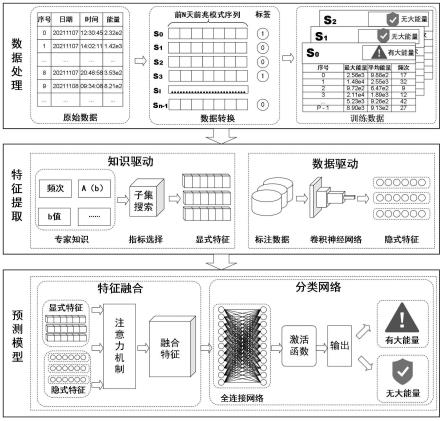
17.图1是本发明模型结构示意图;
18.图2是本发明矿震数据处理过程;
19.图3是本发明深度学习卷积神经网络提取隐式特征示意图;
20.图4是本发明预测模型中显示特征和隐式特征融合示意图。
具体实施方式
21.下面结合附图对本发明作进一步说明。
22.本实施例通过微震传感器采集待监测区域的数据信息,微震传感器安装在采煤工作面四周,然后将采集到的数据传送值地面控制室的上位机,上位机采用本实施例预测模型对待检测区域的冲击地压进行监测。
23.参见图1,本发明一种专家知识与数据融合驱动的冲击地压预测模型构建方法,包括
24.1)通过微震传感器采集原始数据,包括矿震时间、矿震能量和震源坐标;
25.2)矿震数据处理,参见图2和图3:
26.将原始数据转化为用于预测模型输入的前兆模式序列数据,并进行统计分析,计算得到每日最大能量值和平均能量值,生成以日为最小单位的时间序列数据,指定前兆模式序列长度,生成前兆模式序列及其标签,作为海量矿震数据,具体方法如下:
27.2.1)以固定时间窗口统计原始数据,构建时间序列数据集合,假设第i个时间窗口计算得到的数据记录为mi,其表达式为:
28.mi=<id,e
max
,e
mean
,f>
ꢀꢀꢀ
(1)
29.其中,id为时间窗口编号,e
max
为时间窗口内最大能量,e
mean
为时间窗口内的平均
能量,f为时间窗口内矿震频次,因此,当数据被划分为n个时间窗口,基于公式(1)遍历时间窗口,得到时间序列数据集合m=<m0,m1,m2,.....,m
n-1
>;
30.2.2)基于步骤2.1)的时间序列数据集合m构建前兆模式序列,假设第i个前兆模式序列为si,其表达式为:
31.si=<mi×j,mi×
j 1
,mi×
j 2
,,.....,mi×
j p-1
,>
ꢀꢀꢀ
(2)
32.其中,p为前兆模式序列长度,j为采样步长,m
i*jmi*j
为第i个时间窗口采样步长为j的数据,因此,在n个时间窗口且n》》p的前提下,基于公式(2)生成前兆模式序列集合s,其表达式为:
33.s=<s0,s1,s2,,.....,s
d-1
>
ꢀꢀꢀ
(3)
34.其中,d为前兆模式序列样本在预测时间范围为n小时情况下的前兆模式序列数量;
35.2.3)为了后续预测模型训练,需要建立前兆模式序列集合s对应的标签集合t,其表达式为:
36.t=<t0,t1,t2,,.....,t
d-1
>
ꢀꢀꢀ
(4)
37.其中,ti为前兆模式序列si的标签,若即将发生大能量事件ti=1,否则ti=0,其计算方法如下:
[0038][0039]
其中,ei为前兆模式序列si未来n小时内最大能量值,e为大能量事件的能量阈值,e的值可根据实际需求设置,如e=5
×
104j或e=1
×
105j。
[0040]
3)特征提取:包括专家知识驱动的显式特征提取和数据驱动的隐式特征提取
[0041]
3.1)专家知识显式特征提取:
[0042]
根据不同矿区的矿震指标,利用主成分分析法(pca)处理该矿区的矿震指标,得到每个矿震指标所占的权重大小,并根据矿区的实际需要以及矿震指标的权重选择所要使用的矿震指标组合。如某矿区的矿震指标为a1,a2,a3,a4,利用主成分分析法对上述四个指标进行处理,得出矿震指标所占权重为:a1=1.4%,a2=2.5%,a3=50%,a4=46.1%,从数据上看,a1和a2的所占权重较小,即对该矿区预测冲击地压影响较小,为提高数据运算,可放弃a1和a2的使用,选择a3和a4的组合作为该矿区的显式特征用于构建预测模型;
[0043]
所述矿震指标是研究人员通过现有的冲击地压知识对冲击地压长期研究而得,所述矿震指标包括某一时段内微震活动水平a、微震活动强度b、某一时段微震时间的频次、能量以及活动性等因素的综合评价a(b),以及缺震b,上述指标的表达式如下:
[0044][0045][0046]
式中,m为能级分档总数,lgei为第i档表示的能级,ni为第i档能级的微震总数,a值
代表某一时段内微震活动水平的高低,a值越大说明微震发生的频次越高;b值代表微震活动强度的强弱,b值越小发生大能量事件的可能性越大;
[0047][0048]
式中,mi为微震事件能级,a(b)值综合考虑了某时段内微震事件的频次、能量以及活动性等因素,可直观定量的对微震活动性进行评价;
[0049][0050]
式中,b为缺震,为统计时段内的平均能级,m0为初始能级,n为统计时段内的微震事件总数。缺震意味着某时段内平均能级m比长时间段内平均能级m偏小,则该区域极有可能发生大能量事件来补充缺少的这部分能级。
[0051]
上述四个指标a、b、a(b)和b是从矿震指标专家知识库中选取的,之所以选择这四个指标是因为:利用pca法对多个矿区的矿震指标进行处理,发现每个矿区都会包含上述四个指标,且上述四个指标在每个矿区的指标中所占权重均比较大,有利于提高后期预测冲击地压的准确性。当然也可根据实际需要选取某个矿区所有矿震指标进行pca法处理,得到每个矿震指标所占权重,然后根据所需总权重选取需要的矿震指标组成为一个矿震指标集,作为显式特征。
[0052]
隐式特征的提取:利用深度学习中的卷积神经网络提取隐式特征
[0053]
卷积神经网络具有表征学习能力,它的人工神经元可以响应一部分覆盖范围内的周围单元,由一个或多个卷积层和顶端的全连接层组成,同时也包括关联权重和池化层。这一结构使得卷积神经网络能够利用输入数据的二维结构。其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量实现隐式特征提取。因此,本实施例利用深度卷积神经网络提取海量矿震数据的隐藏特征,将步骤2)中的海量矿震数据(前兆序列模式及其标签)输入至深度卷积神经网络中进行隐式特征提取;本实施例深度卷积神经网络为3层卷积,包括88个卷积核,输出1000维度的隐式特征向量,该向量即为本实施例所要提取的隐式特征。
[0054]
4)构建预测模型:将步骤2)的海量矿震数据(前兆序列模式及其标签)为训练数据集样本生成预测模型,该预测模型包括特征融合模块和分类网络模块,在特征融合模块中利用注意力机制对显式特征提取和隐式特进行深度融合,在分类网络模块中,通过全连接网络拟合实现分类,从而构建冲击地压大能量事件预测模型,参见图4,具体方法如下:
[0055]
4.1)根据步骤2)的海量矿震数据作为训练数据集建立目标函数:
[0056][0057][0058]
其中,li为第i个前兆模式序列的损失值,n为前兆模式序列数量,z0和z1分别为两个类别的学习权重,w0和w1分别为类别0和1的样本分布权重,若第i个前兆模式序列的标签为小能量事件,则y
io
=1,y
i1
=0,否则y
io
=0,y
i1
=1;p
i0
为观测样本i为类别0的预测概率,
p
i1
为观测样本i为类别1的预测概率;
[0059]
4.2)利用反向传播算法进行网络权重w0、w1的更新,使得目标函数损失最小化,从而
[0060]
生成预测模型,该预测模型包括特征融合模块和分类网络模块;
[0061]
上述方法有效地改善了数据类别不平衡的问题,加快了预测模型的收敛速度,提高了预测模型预测准确率。
[0062]
4.3)在特征融合模块中利用注意力机制法对显式特征和隐式特征进行深度融合
[0063]
由于显式特征和隐式特征的复杂性和异构性,导致简单的加权特征融合方法并不适用,因此,本实施例利用深度学习中的注意力机制法实现显式特征和隐式特征的融合,并实现显式特征和隐式特征内每个维度的加权,具体方法如下:
[0064]
4.3.1)将显式特征fe和隐式特征fi进行合并,从而得到初始特征向量fs[0065]fs
=[fe,fi]
ꢀꢀꢀ
(6)
[0066]
其中,显示特征向量和隐式特征向量的维度分别为d1和d2,融合特征向量的维度为d1 d2;在注意力机制中,隐式特征和显示特征的权重向量分别记为其计算方法如下:
[0067][0068]
其中,为两个可学习参数矩阵,h(x)为激活函数权重向量ve和vi的每一个维度对应fe和fi每一个特征维度的权重;
[0069]
4.3.2)计算最终的融合特征向量ff表示为:
[0070]ff
=[fe⊙ve
,fi⊙vi
]
ꢀꢀꢀ
(8)
[0071]
其中,
⊙
为哈达玛积;
[0072]
4.4)将步骤4.3.2得到的融合特征向量ff输入到分类网络模块,经分类网络模块处理后,得到有无大能量事件的概率,若有大能量矿震事件概率大于无大能量矿震事件概率,则输出1,反之输出0;
[0073]
在一些实施例中,所述分类网络模块包括一个全连接层和一个激活函数,在深度学习中,全连接层起到分类器的作用,其可以将学到的分布式特征表示映射到样本标记空间中,本预测模型中全连接层主要由2000个神经元组成和一个激活函数组成,分类网络模块通过以下方法对融合特征向量ff进行处理:
[0074]
将融合特征向量ff输入到全连接层,全连接层将学到的分布式特征表示映射到样本标记空间中,然后,利用激活函数进行归一化处理,得到有无大能量事件的概率,若有大能量矿震事件概率大于无大能量矿震事件概率,则输出1,反之输出0。如:有大能量矿震事件的概率为60%,无大能量矿震事件概率为40%,此时,有大能量矿震事件大于无大能量矿震事件概率,最终输出1,说明将有大能量矿震事件概率发生,工作人员可根据预测结果采取相应的措施。
[0075]
本发明考虑到大能量矿震事件发生的次数较少,导致训练数据集样本不平衡,标签为小能量事件的数据远多于大能量事件的数据。若使用传统的深度学习模型训练方法,
则会导致预测模型在分类时偏向学习样本较多的一类的问题。为了解决这个问题,本实施例借鉴了“再放缩”的思想,在训练过程中,预测模型可以根据批样本和总体样本的分布情况,动态调整各类别在计算损失的权重。在网络训练中,使用目标函数计算预测模型的损失值,通过不断更新神经网络模型中的参数,使得预测模型在训练数据集上的损失最小化。此外,在冲击地压预测任务中,为了减小大能量对事件的漏报率,本实施例在目标函数中添加了各类别的学习权重z0和z1,通过调整大能量事件的学习权重,使得该预测模型可以更偏向大能量样本的预测,从而降低了大能量事件的漏报率,有效地改善了数据类别不平衡的问题,有效加快了模型收敛速度,并提高了模型预测准确率。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
