1.本发明涉及智能驾驶技术领域,尤其是涉及一种基于图像输入的近场车辆加塞行为预测方法。
背景技术:
2.行为预测属于基于行为识别的进一步发展,而作为计算机视觉领域的基本任务之一,近些年随着深度学习技术的火热发展,行为预测算法也存在制定先验规则的算法以及基于深度神经网络的端到端预测技术。行为识别与预测的方法从最初的基于物理运动特征的方法发展到基于视觉视频输入的slowfast网络、基于双模态输入动作识别网络tsn以及基于膨胀三维卷积(i3d)的3d卷积神经网络,涌现出许多好的算法技术,这些算法在开放的人类行为识别数据集上的检测效果和性能都很出色,但是针对近场车辆加塞行为预测任务,在实际应用中存在以下缺点:
3.其一,现有的公开数据集中,缺少针对近场车辆加塞行为预测的自车辆(ego vehicle)视角数据集,与目标检测数据集相比,在数据的采集、标注中存在很多困难,限制了该技术的进一步发展;
4.其二,双模态输入技术中,光流属于手工制作特征,与rgb输入分别训练,不能实现端到端的训练,系统的准确率也有待提高,同时复杂的算法降低系统运行的实时性;
5.其三,基于lidar的方法硬件成本和使用维护成本较高,同时目前缺少以前向全景图像视频为输入的自车辆(ego vehicle)视角行为预测方法。
6.其四,基于深度学习的端到端的方法,存在训练模型的泛化性不好、具体原理不清晰、以及对于移动端的硬件要求较高等问题,较难在实际场景中快速落地。
技术实现要素:
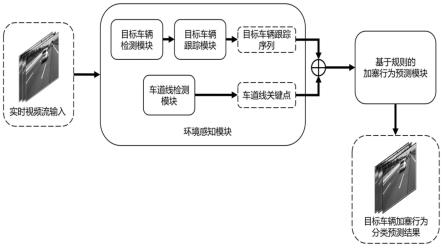
7.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于图像输入的近场车辆加塞行为预测方法,其能够以一段时间内车载高清相机提供的前向全景图像视频数据作为输入,利用基于图像输入的目标检测跟踪算法得到自车辆(ego vehicle)视角下的前向目标车辆感兴趣区域的感知和跟踪,再对感兴趣区域基于制定先验规则的算法进行行为预测,在保证推理速度的前提下,大大降低了实际部署的软硬件成本,最终得到对临近车辆加塞行为较为准确的预测,为智能驾驶系统规避风险提供了充足的时间,提升了智能驾驶系统整体的安全性。
8.本发明的目的可以通过以下技术方案来实现:
9.一种基于图像输入的近场车辆加塞行为预测方法,该方法包括:
10.(1)采集真实的结构化道路场景中基于前向全景图像的图像序列信息,通过人工方法标注图像序列中车辆目标的位置以及行为信息;
11.(2)构建适用于结构化道路中近场车辆检测与跟踪的近场车辆检测与跟踪模型;
12.(3)构建适用于结构化道路中车道线检测的车道线检测网络及相应的损失函数;
13.(4)基于步骤(2)建立的近场车辆检测与跟踪模型获得的车辆id与对应目标的边界框位置数据、以及步骤(3)建立的车道线检测网络获得的车道线,获得目标与车道线的相对位置偏差,根据先验规则的制定,得到近场车辆的加塞行为预测结果。
14.优选地,步骤(1)具体包括:
15.(11)对摄像头的内外参进行标定,其中外参包括旋转矩阵r和平移向量t,内参包括内参矩阵k,以及相机畸变系数;
16.(12)利用装有摄像头的数据采集车在真实道路场景中采集视频数据,并记录采集时图像内车辆目标的类别;
17.(13)利用标注工具对采集到的视频数据进行标注,标注方式包含车辆目标跟踪id标注、车辆目标类别标注、目标物体边界框标注、车辆加塞开始、车辆越过车道线中点以及车辆完成加塞行为的关键帧标注、车辆加塞行为类别标注,标注内容至少需要包含近场车辆的位置、关键帧以及加塞行为类别信息。
18.优选地,步骤(2)具体包括:
19.(21)构建基于改进的yolov5的近场车辆目标检测网络,将输入的视频切片作为图像时间序列输入至近场车辆目标检测网络,经过多层卷积与下采样操作,对输入的图像信息进行特征提取与特征编码,得到将图片划分好的多维特征张量;
20.(22)构建分类网络,采用非极大抑制操作,最终得到各个目标的位置信息与分类置信度信息,包括对象的分类概率和定位概率;
21.(23)构建基于改进的deep-sort的近场车辆目标跟踪网络,将目标检测得到的目标物体边界框信息以及分类信息作为输入,对视频中多个对象同时定位与追踪并记录id和轨迹信息,尤其是在有遮挡的条件下减少对象id的变换,输出目标车辆的跟踪id、目标类别以及目标物体边界框信息。
22.优选地,步骤(3)具体包括:
23.(31)构建基于卷积神经网络的车道线特征提取骨干网络,基于浅层残差连接网络输出特征,通过使用较大的感受野,在保证检测效果的同时提高模型的推理速度;
24.(32)构建车道线语义分割网络,在网络训练时将多尺度特征上采样到同一尺度,并经过转置卷积,计算语义分割损失,增强骨干网络的视觉特征抽取能力,最终得到增强的基于残差连接的车道线检测骨干网络;
25.(33)将骨干网络抽取的特征,根据先验指定的图片纵向候选锚框,在全局范围内通过分类器计算候选点,最终得到自车辆所在车道的车道线位置节点;
26.(34)构建车道线检测网络的损失函数,包括多分类损失、分割损失以及车道结构化损失。
27.优选地,所述的车道线检测网络的损失函数表示为l
total
:
28.l
total
=l
cls
l
seg
ηl
lane
29.l
cls
为多分类损失、l
seg
为分割损失,l
lane
为车道结构化损失,η为超参数。
30.优选地,所述的多分类损失l
cls
表示为:
31.32.其中,l
ce
(
·
)表示交叉熵损失函数,p
i,j,:
表示针对第i个车道线、第j个横向锚框的所有(w 1)个车道线单元预测结果,t
i,j,:
表示针对第i个车道线、第j个横向锚框的所有(w 1)个车道线单元真实分布,c
i,j,:
表示p
i,j,:
与t
i,j,:
的相似度,c与h分别代表车道线类数与车道纵向锚点数,γ与α为超参数。
33.优选地,所述的车道结构化损失l
lane
表示为:
34.l
lane
=l
sim
λ
lshp
[0035][0036][0037]
其中,l
sim
为相似度损失,l
shp
为形状损失,λ为表示损失权重的超参数,p
i,j,k
表示第i类车道线在位置为(j,k)处的预测概率,w为每行的划分单元数量。
[0038]
优选地,步骤(4)训练网络与制定先验规则步骤如下:
[0039]
(41)将采集到的图像序列进行数据预处理,包括:将图像进行随机的水平翻转、裁剪并统一缩放到固定的尺寸,标注数据也进行相应的翻转、裁剪和缩放,在此基础上对得到的图像按通道进行归一化处理;
[0040]
(42)将车道线检测得到的自车辆所在车道的车道线位置节点,采用高鲁棒性回归模型得到自车辆所在车道的车道线拟合模型;
[0041]
(43)根据自车辆所在车道的车道线模型建立加塞行为感兴趣区域,并计算目标车辆边界框信息与加塞行为感兴趣区域的位置偏差,并根据目标车辆跟踪id建立每个目标的加塞行为期望次数与车辆状态符号字典;
[0042]
(44)经过设定加塞行为期望次数阈值结合车辆状态符号判断目标车辆具体的行为,对建立的加塞行为感兴趣区域进行参数更新,迭代后得到理想的网络参数。
[0043]
优选地,自车辆所在车道的车道线拟合模型为线性模型,且左右车道分别根据车道线预测位置节点拟合得到。
[0044]
优选地,建立的每个目标的加塞行为期望次数与车辆状态符号字典中键值为目标跟踪id,值为期望次数与车辆状态符号。
[0045]
与现有技术相比,本发明具有如下优点:
[0046]
(1)本发明针对目前的神经网络对车辆加塞行为预测不佳的问题提出全新的网络结构,在移动端计算能力有限的前提下大大提升对近场车辆实时行为预测的性能,能方便地部署在现有的智能驾驶系统中,使智能驾驶汽车能对近场车辆加塞行为及时地做出反应,提高行驶过程中的安全性;
[0047]
(2)本发明首先抽取变道行为的视频片段与目标的边界框(bounding boxe s)信息,筛选出符合前文定义的临近车辆加塞行为的数据集合,最终建立起包含标注与视频数据的“临近物体典型加塞行为数据库”数据集;
[0048]
(3)本发明中凭借大的视场、高分辨率获得前向视角图像,包含目标的外观特征以及目标之间的依赖关系,开发了临近车辆检测与跟踪模型和加塞行为预测算法。其中的目标检测模块基于目前最新的one-stage目标检测算法yolov5深度改进,在保持一定的检测准确度的基础上有着较高的检测速度;
[0049]
(4)本发明中在输出目标的边界框和类别信息之后,采用deep-sort多目标跟踪算法,得到与每个目标id对应的感兴趣帧序列,考虑到传统的双模态输入网络对系统的计算资源要求较高,为保证算法的实时性,本文不采用光流作为时域特征的抽取,而是采用目标序列作为时空特征输入;
[0050]
(5)本发明中在加塞行为预测模块,从加塞行为的特征信息出发,基于制定先验规则的算法与上一步得到的目标序列输出,提出一种可解释的车辆行驶场景下实时高鲁棒性的临近物体加塞行为预测方法。
附图说明
[0051]
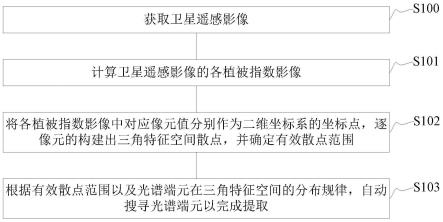
图1为本发明一种基于图像输入的近场车辆加塞行为预测方法的流程示意图;
[0052]
图2为本发明近场车辆目标检测网络的结构示意图;
[0053]
图3为根据先验规则进行加塞行为预测的算法流程第一部分;
[0054]
图4为根据先验规则进行加塞行为预测的算法流程第二部分;
[0055]
图5为根据先验规则进行加塞行为预测的算法流程第三部分。
具体实施方式
[0056]
下面结合附图和具体实施例对本发明进行详细说明。注意,以下的实施方式的说明只是实质上的例示,本发明并不意在对其适用物或其用途进行限定,且本发明并不限定于以下的实施方式。
[0057]
实施例
[0058]
本发明行为预测方法主要步骤包括采集真实的结构化道路场景中基于前向全景图像的图像序列信息,通过人工方法标注图像序列中车辆目标的位置以及行为信息;构建适用于结构化道路中近场车辆检测与跟踪的深度卷积神经网络;构建适用于结构化道路中车道线检测的深度神经网络及相应的损失函数;从所建立的近场车辆检测与跟踪模型获得的车辆id与对应目标的边界框位置数据、以及所建立的车道线检测网络获得的车道线模型,获得目标与车道线的相对位置偏差,根据先验规则的制定,得到近场车辆的加塞行为预测结果。本发明针对目前的神经网络对车辆加塞行为预测不佳的问题提出全新的加塞行为预测算法,在移动端计算能力有限的前提下大大提升对近场车辆实时行为预测的性能,能方便地部署在现有的智能驾驶系统中,使智能驾驶汽车能对近场车辆加塞行为及时地做出反应,提高行驶过程中的安全性。
[0059]
如图1所示,本实施例提供一种基于图像输入的近场车辆加塞行为预测方法,该方法包括:
[0060]
(1)采集真实的结构化道路场景中基于前向全景图像的图像序列信息,通过人工方法标注图像序列中车辆目标的位置以及行为信息;
[0061]
(2)构建适用于结构化道路中近场车辆检测与跟踪的近场车辆检测与跟踪模型;
[0062]
(3)构建适用于结构化道路中车道线检测的车道线检测网络及相应的损失函数;
[0063]
(4)基于步骤(2)建立的近场车辆检测与跟踪模型获得的车辆id与对应目标的边界框位置数据、以及步骤(3)建立的车道线检测网络获得的车道线,获得目标与车道线的相对位置偏差,根据先验规则的制定,得到近场车辆的加塞行为预测结果。
[0064]
具体地,步骤(1)具体包括:
[0065]
(11)对摄像头的内外参进行标定,其中外参包括旋转矩阵r和平移向量t,内参包括内参矩阵k,以及相机畸变系数;
[0066]
(12)利用装有摄像头的数据采集车在真实道路场景中采集视频数据,并记录采集时图像内车辆目标的类别;
[0067]
(13)利用标注工具对采集到的视频数据进行标注,标注方式包含车辆目标跟踪id标注、车辆目标类别标注、目标物体边界框标注、车辆加塞开始、车辆越过车道线中点以及车辆完成加塞行为的关键帧标注、车辆加塞行为类别标注,标注内容至少需要包含近场车辆的位置、关键帧以及加塞行为类别信息,此过程中所要求记录的车辆目标id是唯一的。
[0068]
步骤(2)具体包括:
[0069]
(21)构建基于改进的yolov5的近场车辆目标检测网络,将输入的视频切片作为图像时间序列输入至近场车辆目标检测网络,经过多层卷积与下采样操作,对输入的图像信息进行特征提取与特征编码,得到将图片划分好的多维特征张量,此部分的近场车辆目标检测网络的网络结构如图2所示,由backbone、fpn、pan等结构组成;
[0070]
(22)构建分类网络,采用非极大抑制操作,最终得到各个目标的位置信息与分类置信度信息,包括对象的分类概率和定位概率;
[0071]
(23)构建基于改进的deep-sort的近场车辆目标跟踪网络,将目标检测得到的目标物体边界框信息以及分类信息作为输入,对视频中多个对象同时定位与追踪并记录id和轨迹信息,尤其是在有遮挡的条件下减少对象id的变换,输出目标车辆的跟踪id、目标类别以及目标物体边界框信息,deep-sort网络中的reid模块经过了经过重新分类处理的新的车辆重识别数据集compcars训练。
[0072]
步骤(3)具体包括:
[0073]
(31)构建基于卷积神经网络的车道线特征提取骨干网络,基于浅层残差连接网络输出特征,通过使用较大的感受野,在保证检测效果的同时提高模型的推理速度,浅层残差连接卷积神经网络输出有四种尺度,分别为112
×
112
×
3、56
×
56
×
64、28
×
28
×
128、14
×
14
×
256:
[0074]
(32)构建车道线语义分割网络,在网络训练时将多尺度特征上采样到同一尺度,并经过转置卷积,计算语义分割损失,增强骨干网络的视觉特征抽取能力,最终得到增强的基于残差连接的车道线检测骨干网络,车道线语义分割网络,在网络训练时将多尺度特征上采样到同一尺度,在实际推断过程中不使用;
[0075]
(33)将骨干网络抽取的特征,根据先验指定的图片纵向候选锚框,在全局范围内通过分类器计算候选点,最终得到自车辆所在车道的车道线位置节点,本实施例中车道线类数c的值为4,纵向候选锚框个数h的值为18;
[0076]
(34)构建车道线检测网络的损失函数,包括多分类损失、分割损失以及车道结构化损失,车道线检测网络的损失函数表示为l
total
:
[0077]
l
total
=l
cls
l
seg
ηl
lane
[0078]
l
cls
为多分类损失、l
seg
为分割损失,l
lane
为车道结构化损失,η为超参数。
[0079]
其中,多分类损失l
cls
和分割损失l
seg
均采用了交叉熵损失函数,分割损失l
seg
采用了分类数为2的多分类损失。
[0080]
具体地,多分类损失l
cls
表示为:
[0081][0082]
其中,l
ce
(
·
)表示交叉熵损失函数,p
i,j,:
表示针对第i个车道线、第j个横向锚框的所有(w 1)个车道线单元预测结果,t
i,j,:
表示针对第i个车道线、第j个横向锚框的所有(w 1)个车道线单元真实分布,c
i,j,:
表示p
i,j,:
与t
i,j,:
的相似度,c与h分别代表车道线类数与车道纵向锚点数,γ与α为超参数。
[0083]
车道结构化损失l
lane
表示为:
[0084]
l
lane
=l
sim
λl
shp
[0085][0086][0087]
其中,l
sim
为相似度损失,l
shp
为形状损失,λ为表示损失权重的超参数,p
i,j,k
表示第i类车道线在位置为(j,k)处的预测概率,w为每行中的车道线单元数量。
[0088]
在被实施例中,η的值为1,γ的值为2,α的值为0.25,λ的值为1.25。
[0089]
步骤(4)训练网络与制定先验规则步骤如下:
[0090]
(41)将采集到的图像序列进行数据预处理,包括:将图像进行随机的水平翻转、裁剪并统一缩放到固定的尺寸,标注数据也进行相应的翻转、裁剪和缩放,在此基础上对得到的图像按通道进行归一化处理;
[0091]
(42)将车道线检测得到的自车辆所在车道的车道线位置节点,采用高鲁棒性回归模型得到自车辆所在车道的车道线拟合模型,自车辆所在车道的车道线拟合模型为线性模型,且左右车道分别根据车道线预测位置节点拟合得到;
[0092]
(43)根据自车辆所在车道的车道线模型建立加塞行为感兴趣区域,并计算目标车辆边界框信息与加塞行为感兴趣区域的位置偏差,并根据目标车辆跟踪id建立每个目标的加塞行为期望次数与车辆状态符号字典,建立的每个目标的加塞行为期望次数与车辆状态符号字典中键值为目标跟踪id,值为期望次数与车辆状态符号;
[0093]
(44)经过设定加塞行为期望次数阈值结合车辆状态符号判断目标车辆具体的行为,对建立的加塞行为感兴趣区域进行参数更新,迭代后得到理想的网络参数。
[0094]
根据先验规则的制定,得到近场车辆的加塞行为预测结果的算法具体流程如图3、图4、图5所示。首先在每一个临近车辆在完成检测与跟踪之后,构建以目标跟踪id为键、初
始状态[0,
′
keep
′
]为值的目标状态描述符,其中0是计数值,
′
keep
′
是历史状态描述子。根据临近车辆检测边界框(bounding box)所在区域的不同,判断临近车辆初始车道为左侧车道或者右侧车道;同时,根据车道线检测模块获得的车道线模型适当增加车道线两侧的宽度,设置车辆加塞预测感兴趣区域(cut-in roi)。根据临近车辆目标与车辆加塞预测感兴趣区域(cut-inroi)相对位置关系,可分为两种位置状态:
①
临近车辆目标处于横跨该区域边缘时;
②
临近车辆目标处于该区域内时。后者较为简单,在此时设置目标状态描述符为[2,
′
follow
′
]。前者的状态多出现于临近车辆切入与切出两种时刻,在这种条件下可以根据历史状态描述子{
′
keep
′
,
′
cut_in
′
,
′
follow
′
}加以区分。
[0095]
如果目标状态描述符为[count<threshold,
′
keep
′
]时,认为前一时刻目标临近车辆处于车道保持状态并有从车道保持向加塞行为发展的潜在趋势,同时为了降低临近车辆加塞行为预警逻辑的误检率,可以适当延迟加塞预警预测时间,只考虑被跟踪足够长时间加塞的目标。具体而言,只有临近车辆检测边界框(bounding box)距离加塞预测感兴趣区域(cut-in roi)较远的点位于该区域外,同时在加塞预测感兴趣区域(cut-in roi)内的边界框关键点(距离另一端点的距离占宽度一定比例α)被检测到的次数超过阈值时,目标状态描述符为[count=count 1,
′
keep
′
]保持更新,直到count=threshold,目标状态描述符更新为[count=threshold,
′
cut_in
′
]。在本项目中设置α=0.4,检测到的加塞次数阈值threshold=3。此时,当前帧临近车辆的加塞行为从action=
′
keep
′
变为action=
′
cut_in
′
,临近车辆检测边界框(bounding box)与加塞预测感兴趣区域(cut-in roi)变为红色预警。
[0096]
如果当前帧目标状态描述符为[count=threshold,
′
cut_in
′
],可以认为该目标正在延续上一帧的加塞行为,故保持目标状态描述符为[count=threshold,
′
cut_in
′
]不变,当前帧临近车辆的加塞行为从action=
′
cut_in
′
,临近车辆检测边界框(bounding box)与加塞预测感兴趣区域(cut-in roi)继续保持红色,提示临近车辆加塞行为正在发生。
[0097]
如果当前帧目标状态描述符为[count=threshold,
′
cut_in
′
],但是此时临近车辆检测边界框(bounding box)完全进入加塞预测感兴趣区域(cut-in roi)内,可以认为该目标已经完成加塞行为,故目标状态描述符更新为[count=threshold,
′
follow
′
],当前帧临近车辆的加塞行为从action
′
keep
′
,临近车辆检测边界框(bounding box)与加塞预测感兴趣区域(cut-in roi)变为绿色,提示临近车辆加塞行为已经完成,当前帧处于安全状态。
[0098]
如果当前帧目标状态描述符为pcount=threshold,
′
folow
′
],同时临近车辆检测边界框(bounding box)处于横跨加塞预测感兴趣区域(cut-in roi)边缘时,可以认为该目标已经完成加塞行为并在离开当前车道,故目标状态描述符更新为[count=threshold,
′
keep
′
],当前帧临近车辆的加塞行为从action=
′
keep
′
,临近车辆检测边界框(bounding box)与加塞预测感兴趣区域(cut-in roi)继续保持绿色,当前帧处于安全状态。
[0099]
在任何情况下,如果临近车辆检测边界框(bounding box)完全离开加塞预测感兴趣区域(cut-in roi)范围,则立刻更新目标状态描述符为[count=0,
′
keep
′
],并在下一帧继续重复以上步骤。使用以上算法流程,针对加塞情况有额外的3帧延迟,由于输入流的fps=30,这个延迟相当于0.1s;真实条件下人类司机在遇到未预见加塞切入情况时,通常至少需要0.7s才能刹车。因此,即使有一个从检测到发送加塞预警的时间延迟,预计也不会造成
严重的问题,符合实际的技术要求。
[0100]
经过测试可知,本发明提出的网络分别成功的预测出的临近车辆加塞的行为并预警,同时能够实现加塞完成之后的预警解除,在上述类似的两种场景下均能成功辨别。
[0101]
总之,本发明提出了一种基于图像输入的的近场车辆加塞行为预测方法,在移动端计算能力有限的前提下大大提升对近场车辆实时行为预测的性能,能方便地部署在现有的智能驾驶系统中,使智能驾驶汽车能对近场车辆加塞行为及时地做出反应,提高行驶过程中的安全性。
[0102]
上述实施方式仅为例举,不表示对本发明范围的限定。这些实施方式还能以其它各种方式来实施,且能在不脱离本发明技术思想的范围内作各种省略、置换、变更。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。