1.本发明涉及水下缺陷检测领域,具体涉及一种基于迁移学习和声呐图像的输水隧洞缺陷智能检测方法。
背景技术:
2.伴随水资源被大量使用,水资源日益匮乏,越来越多的地方通过建设输水隧洞实现河水的灌溉,并且取得了很好的经济效果。输水隧洞作为水利水电工程的关键建筑物,具有洞径大、洞线长、超埋深、地质环境复杂等特点,长期运行中的高水压环境会导致输水隧洞出现裂缝、脱落、露筋等缺陷,如果不对其进行定期安全检测可能会影响到输水隧洞的正常运行,因此需要对输水隧洞内部的缺陷进行检测,用于后续输水隧洞的维修。
3.现阶段输水隧洞缺陷检测以人工检测为主,检测人员根据输水隧洞结构图纸,进入输水隧洞通过人眼发现缺陷,并用相机进行缺陷信息的记录,用于后续的缺陷分析,这种检测方法存在检测效率低、漏检误检率高、安全风险大等问题。目前随着信息化和自动化技术的发展,基于机器视觉的缺陷检测方法在现代工业中得到的了越来越广泛的应用,在输水隧洞环境下,利用成像声呐对隧洞壁面进行持续扫描获取壁面声呐图像,声呐设备以声学成像的方式将水下隧洞壁面情况呈现,可以克服光学成像受光照、水浑浊程度影响的缺点,但由于隧洞缺陷数据集较少,基于深度学习模型的训练检测效果很差。
4.因此,亟需一种技术解决现有技术声呐图像检测输水隧洞缺陷效果差的问题。
技术实现要素:
5.本发明解决了现有技术声呐图像检测输水隧洞缺陷效果差的问题。
6.本发明提供一种输水隧洞缺陷自动识别模型的构建方法,所述构建方法包括:
7.根据环扫声呐采集输水隧洞壁面图像;
8.根据采集的输水隧洞壁面声呐图像进行去噪处理;
9.基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型;
10.基于标准coco数据集,根据迁移学习的方法训练输水隧洞声呐图像缺陷目标的深度学习模型,获取输水隧洞声呐图像缺陷目标自动识别模型。
11.进一步,所述基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型,具体为:
12.简化yolov3深度学习模型的主干网络,所述简化后的主干网络由5个res1结构块组成;
13.删除yolov3深度学习模型中检测输水隧洞壁面声呐图像中大目标的支干,所述删除后的yolov3模型只保留32
×
32与16
×
16对应的分支。
14.进一步,所述构建方法还包括对去噪处理的输水隧洞壁面图像信息进行数据集的
扩充,所述扩充的数据集包括训练集和测试集。
15.进一步,所述构建方法还包括对扩充的数据集进行人工标注输水隧洞壁面图像缺陷信息,具体为:
16.图像中不含有缺陷的声呐图像为负样本,图像中含有缺陷的声呐图像为正样本;
17.标记缺陷的种类与位置信息,所述位置信息是人工标定的最小外接矩形的顶点坐标,归一化处理训练前的位置信息:
[0018][0019][0020][0021][0022]
其中,x
min
和y
min
为归一化前人工标注框的左上角坐标值,x
max
和y
max
为归一化前人工标注框的右下角坐标值,s
x
为输水隧洞壁面图像的长,sy为输水隧洞壁面图像的宽,x,y为归一化后边界框中心坐标,w为归一化的边界框长,h为归一化的边界框宽。
[0023]
基于同一构思,本发明还提供一种输水隧洞缺陷自动识别模型的检测方法,所述检测方法包括:
[0024]
根据环扫声呐采集输水隧洞壁面图像;
[0025]
根据采集的输水隧洞壁面声呐图像输入至输水隧洞声呐图像缺陷目标自动识别模型,获取检测结果,所述检测结果包括缺陷位置和种类信息;
[0026]
所述输水隧洞声呐图像缺陷目标自动识别模型是基于权利要求1所述的构建方法构建的模型。
[0027]
进一步,所述获取检测结果具体为:
[0028]bx
=σ(t
x
) c
x
,
[0029]by
=σ(ty) cy,
[0030][0031][0032]
c=logistic(t0),
[0033]
其中,c
x
、cy为网格单元左上角坐标,pw、ph为先验框在特征图上的宽高,t
x
、ty为先验框横纵坐标的调整参数,tw为先验框宽度调整参数,th为先验框高度调整参数,t0为置信度调整参数;(b
x
,by)表示预测结果框的中心坐标偏移值;(bw,bh)表示归一化后预测结果框的宽度和高度;c表示置信度。
[0034]
基于同一构思,本发明还提供一种输水隧洞缺陷自动识别模型的构建装置,所述构建装置包括:
[0035]
图像采集单元,用于根据环扫声呐采集输水隧洞壁面图像;
[0036]
图像去噪单元,用于根据采集的输水隧洞壁面声呐图像进行去噪处理;
[0037]
主干网络简化与预测分支单元,用于基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型;
[0038]
模型获取单元,用于基于标准coco数据集,根据迁移学习的方法训练输水隧洞声呐图像缺陷目标的深度学习模型,获取输水隧洞声呐图像缺陷目标自动识别模型。
[0039]
进一步,所述基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型,具体为:
[0040]
简化yolov3深度学习模型的主干网络,所述简化后的主干网络由5个res1结构块组成;
[0041]
删除yolov3深度学习模型中检测输水隧洞壁面声呐图像中大目标的支干,所述删除后的yolov3模型只保留32
×
32与16
×
16对应的分支。
[0042]
基于同一构思,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质用于储存计算机程序,所述计算机程序执行上述所述的一种输水隧洞缺陷自动识别模型的构建方法。
[0043]
基于同一构思,本发明还提供一种计算机设备,其特征在于:包括存储器和处理器,所述存储器中存储有计算机程序,当所述处理器运行所述存储器存储的计算机程序时,所述处理器执行根据上述所述的一种输水隧洞缺陷自动识别模型的构建方法。
[0044]
本发明的有益之处在于:
[0045]
本发明解决了现有技术声呐图像检测输水隧洞缺陷效果差的问题。
[0046]
(1)本发明通过数据增强的方法对数据集进行扩充,基于缺陷特点进行yolov3单阶段目标检测模型的改进,通过简化主干网络与预测分支,提高检测效率,能够将输水隧洞巡检机器人采集到图像中的缺陷进行自动检测,并通过极大值抑制的方法nms输出图像中置信度最大的目标的种类和位置,为输水隧洞的维修提供技术支持。
[0047]
(2)本发明采用yolov3单阶段目标检测模型作为深度学习模型,对于小目标的检测更加精准,优于现有技术中采用yolov4、yolov5或retinanet等网络结构更复杂的网络模型,通过训练后的模型能进行实时检测且自动更新数据,有效检测效果优于现有深度学习模型。
[0048]
(3)本发明针对输水隧洞缺陷数据集极端缺乏的情况,采用迁移学习的方法进行训练,针对缺陷目标在声呐图像尺寸较小的特点,在yolov3的基础上通过简化特征提取主干网络结构,优化预测层的网络结构,删去特征表达能力差的预测分支,实现对小尺寸的检测识别,并且提高了改进yolov3模型的检测速度。
[0049]
本发明适用于输水隧洞水下检测领域。
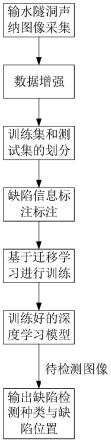
附图说明
[0050]
图1为本实施方式一所述的输水隧洞缺陷训练方法流程图。
[0051]
图2为本实施方式一所述的基于迁移学习训练的流程图。
[0052]
图3为本实施方式二所述的yolov3深度学习模型。
[0053]
图4为本实施方式二所述的res1的结构图。
[0054]
图5为本实施方式二所述的训练后的yolov3深度学习模型。
具体实施方式
[0055]
为使本发明提供的技术方案的优点和有益之处表述得更具体,现结合附图对本发明提供的技术方案进行进一步详细地描述,具体的:
[0056]
实施方式一、参见图1、图2说明本实施方式。本实施方式所述的一种输水隧洞缺陷自动识别模型的构建方法,所述构建方法包括:
[0057]
根据环扫声呐采集输水隧洞壁面图像;
[0058]
根据采集的输水隧洞壁面声呐图像进行去噪处理;
[0059]
基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型;
[0060]
基于标准coco数据集,根据迁移学习的方法训练输水隧洞声呐图像缺陷目标的深度学习模型,获取输水隧洞声呐图像缺陷目标自动识别模型。
[0061]
具体的,所述构建方法中涉及的采集的输水隧洞壁面图像分为含有缺陷的图像和正常状态图像,缺陷类型主要包括为裂缝图片、脱落图片等,声呐图像中缺陷的种类最初由人工标定,用于后续的训练。
[0062]
优选的,所述根据采集的输水隧洞壁面声呐图像进行去噪处理选用的是3
×
3的中值滤波去噪,在更好的保留图像信息的情况下去除椒盐噪声。
[0063]
所述迁移学习训练的流程图如图2所示,将通过yolov3深度学习模型训练的coco数据集的数据参数输入预训练模型,将数据参数冻结在预训练模型,保障预训练模型的训练效果。
[0064]
实施方式二、参见图3、图4和图5说明本实施方式。本实施方式是对实施方式一所述的一种输水隧洞缺陷自动识别模型的构建方法的进一步限定,所述基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型,具体为:
[0065]
简化yolov3深度学习模型的主干网络,所述简化后的主干网络由5个res1结构块组成;
[0066]
删除yolov3深度学习模型中检测输水隧洞壁面声呐图像中大目标的支干,所述删除后的yolov3深度学习模型只保留32
×
32与16
×
16对应的分支。
[0067]
具体的,如图2所示,标准yolov3深度学习模型的主干网络为darknet53,简化后的主干网络由5个res1结构块组成,图片输入尺寸256
×
256
×
3,经过一次3
×
3的卷积层,得到256
×
256
×
32,经过5次res1卷积操作,其中res1包括两次3
×
3卷积操作和一次1
×
1卷积操作,第一次的3
×
3卷积层操作后图片尺寸减半,通道数目翻倍,经过5次res1操作后的尺寸分别为128
×
128
×
64、64
×
64
×
128、32
×
32
×
256、16
×
16
×
512、8
×8×
1024。
[0068]
yolov3深度学习模型为多尺寸检测模型,三个分支对应图像中的小目标、中目标、大目标,分别对应32
×
32的feature map3、16
×
16的feature map2、8
×
8的feature map1,删除yolov3深度学习模型中检测图像中大目标的支干。如图5所示,训练后的yolov3深度学习模型只保留32
×
32与16
×
16对用的分支,用于预测缺陷目标。
[0069]
实施方式三、参见图1说明本实施方式。本实施方式是对实施方式一所述的一种输水隧洞缺陷自动识别模型的构建方法的进一步限定,所述构建方法还包括对去噪处理的输水隧洞壁面图像信息进行数据集的扩充,所述数据集的扩充采用图像扩充方法,所述扩充
的数据集包括训练集和测试集。
[0070]
具体的,所述数据集的扩充采用图像扩充方法,通过对图像做翻转、平移、镜像、明暗度变化以及随机裁剪等操作进行图像变换,将原始图像与数据增强后的图像共同组成数据集,最终达到均衡数据集的目的,并且所有声呐图像的尺寸为256
×
256。
[0071]
所述的训练集、测试集的可划分比例为8:2或9:1。
[0072]
结合实施方式一说明本实施方式,所述训练的yolov3深度学习模型,具体训练方式为:
[0073]
将标准数据集coco载入改进后的深度神经网络模型进行训练,当训练结果收敛时保存训练模型;
[0074]
权重参数冻结多尺度特征融合之前的卷积层,并输入之前实施方式三种扩充好的训练集重新训练,训练结果收敛时保存训练模型。
[0075]
实施方式四、参见图1说明本实施方式。本实施方式是对实施方式三所述的一种输水隧洞缺陷自动识别模型的构建方法的进一步限定,所述构建方法还包括对扩充的数据集进行人工标注输水隧洞壁面图像缺陷信息,具体为:
[0076]
图像中不含有缺陷的声呐图像为负样本,图像中含有缺陷的声呐图像为正样本;
[0077]
标记缺陷的种类与位置信息,所述位置信息是人工标定的最小外接矩形的顶点坐标,归一化处理训练前的位置信息:
[0078][0079][0080][0081][0082]
其中,x
min
和y
min
为归一化前人工标注框的左上角坐标值,x
max
和y
max
为归一化前人工标注框的右下角坐标值,s
x
为输水隧洞壁面图像的长,sy为为输水隧洞壁面图像的长,x,y为归一化后边界框中心坐标,w为归一化的边界框长,h为归一化的边界框宽。
[0083]
在实际应用中,采用的人工标注为人工标定软件labelimg进行缺陷位置的标记。
[0084]
实施方式五、本实施方式所述的一种输水隧洞缺陷自动识别模型的检测方法,所述检测方法包括:
[0085]
根据环扫声呐采集输水隧洞壁面图像;
[0086]
根据采集的输水隧洞壁面图像输入至输水隧洞声呐图像缺陷目标自动识别模型,获取检测结果,所述检测结果包括缺陷位置和种类信息;
[0087]
所述输水隧洞声呐图像缺陷目标自动识别模型是基于权利要求1所述的构建方法构建的模型。
[0088]
实施方式六、本实施方式是对实施方式五所述的一种输水隧缺陷自动识别模型的构建方法的进一步限定,所述获取检测结果具体为:
[0089]bx
=σ(t
x
) c
x
,
[0090]by
=σ(ty) cy,
[0091][0092][0093]
c=logistic(t0),
[0094]
其中,c
x
、cy为网格单元左上角坐标,pw、ph为先验框在特征图上的宽、高,以16
×
16的输出层为例,深度学习模型的输出为16
×
16
×
(4 1 缺陷种类数),t
x
、ty为先验框横纵坐标的调整参数,tw为先验框宽度调整参数,th为先验框高度调整参数,t0为置信度调整参数;(b
x
,by)表示预测结果框的中心坐标偏移值;(bw,bh)表示归一化后预测结果框的宽度和高度;c表示置信度。
[0095]
具体的,利用k-means聚类方法对声呐图像中标注框进行聚类处理,因为改进后的yolov3神经网络的输出层为2层,每个层的单元格对应三个锚边框,因此对应的聚类的种类设置为6,得到六种大小尺度不同的先验框;
[0096]
将聚类得到的六种尺度中较大的三种先验框分给16
×
16的分支,六种尺度中较小的三种先验框分给32
×
32的分支;
[0097]
将尺寸为32
×
32的预测层特征图划分成32
×
32个网格单元,根据目标所在边界框中心坐标,将每个目标分配到对应位置的网格单元,该对应位置的网格单元给特征图尺寸为32
×
32的预测层分配的先验框预测目标的位置坐标和置信度;将尺寸为16
×
16的预测层特征图划分成16
×
16个网格单元,根据目标所在边界框中心坐标,将每个目标分配到对应位置的网格单元,该对应位置的网格单元使用给特征图尺寸为16
×
16的预测层分配的先验框预测目标的位置坐标和置信度;所述预测目标的位置坐标和置信度即为获取检测结果。
[0098]
使用非极大值抑制方法获得置信度最大的目标位置和种类。
[0099]
实施方式七、本实施方式所述的一种输水隧洞缺陷自动识别模型的构建装置,所述构建装置包括:
[0100]
图像采集单元,用于根据环扫声呐采集输水隧洞壁面图像;
[0101]
图像去噪单元,用于根据采集的输水隧洞壁面图像进行去噪处理;
[0102]
主干网络简化与预测分支单元,用于基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型;
[0103]
模型获取单元,用于基于标准coco数据集,根据迁移学习的方法训练输水隧洞声呐图像缺陷目标的深度学习模型,获取输水隧洞声呐图像缺陷目标自动识别模型。
[0104]
实施方式八、本实施方式是对实施方式七所述的一种输水隧洞缺陷自动识别模型的构建装置的进一步限定,所述基于简化主干网络与预测分支的yolov3深度学习模型构建输水隧洞声呐图像缺陷目标的深度学习模型,具体为:
[0105]
简化yolov3深度学习模型的主干网络,所述简化后的主干网络由5个res1结构块组成;
[0106]
删除yolov3深度学习模型中检测输水隧洞壁面图像中目标与大目标的支干,所述删除后的yolov3模型只保留32
×
32与16
×
16对应的分支。
[0107]
实施方式九、本实施方式所述的一种计算机可读存储介质,所述计算机可读储存
介质用于存储计算机程序,所述计算机程序执行实施方式一至实施方式四所述的种输水隧洞缺陷自动识别模型的构建方法。
[0108]
实施方式十、本实施方式所述的一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,当所述处理器运行所述存储器存储的计算机程序时,所述处理器执行根据实施方式一至实施方式四所述的一种输水隧洞缺陷自动识别模型的构建方法。
[0109]
以上结合附图对本发明提供的技术方案进行进一步详细地描述,是为了突出优点和有益之处,并不用于作为对本发明的限制,任何基于本发明的精神原则范围内的,对本发明的修改、实施方式的组合、改进和等同替换等,均应当包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。