1.本发明涉及集成电路技术领域,尤其涉及一种部分积求和模块设计方法及乘法器。
背景技术:
2.乘法器是数字集成芯片中重要的计算单元。在用于数字信号处理、信息加密和科学计算的专用集成芯片中,都要用到乘法器来实现乘法。近年来,深度学习不断发展,例如卷积神经网络在图像分类、目标识别的准确度达到实用程度,使神经网络加速专用集成芯片又成为设计的热点。卷积神经网络中包含大量乘加计算,所以设计高能效的乘法器是设计用于加速神经网络计算的专用集成芯片的重点之一。
3.目前,现有乘法器应用于神经网络计算时存在能耗大的问题。
技术实现要素:
4.本发明提供一种部分积求和模块设计方法及乘法器,用以解决现有技术中乘法器应用于神经网络计算时存在能耗大的缺陷,实现降低乘法器的能耗。
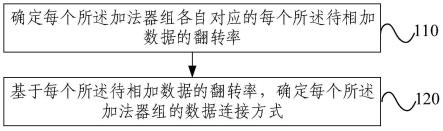
5.第一方面,本发明提供一种部分积求和模块设计方法,所述部分积求和模块包括至少一个加法器组,每个所述加法器组用于基于输入的多个待相加数据获得相加结果,每个所述加法器组包括多级级联的多个逻辑单元;
6.确定每个所述加法器组各自对应的每个所述待相加数据的翻转率;
7.基于每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式。
8.可选地,所述基于每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式,包括:
9.将高翻转率待相加数据输入至所述加法器组中的后级逻辑单元;
10.将低翻转率待相加数据输入至所述加法器组中的前级逻辑单元。
11.可选地,所述基于每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式,包括:
12.基于每个所述待相加数据的翻转率、每个所述待相加数据的保持率和输出翻转率公式,确定每种候选数据连接方式中每个逻辑单元的输出翻转率;
13.基于每个逻辑单元的输出翻转率,确定每个所述加法器组的总输出翻转率;
14.将最小总输出翻转率对应的候选数据连接方式作为优选数据连接方式;
15.所述输出翻转率公式为:
16.α=f(β1,β2,
…
,βn,γ1,
…
,γn);
17.其中,α为输出翻转率,(β1,β2,
…
,βn)为逻辑单元n个输入的由0翻转为1的翻转率,(γ1,
…
,γn)为逻辑单元n个输入的由1保持为1的保持率,f为根据逻辑单元的逻辑表达式确定的函数。
18.可选地,所述方法还包括:
19.在所述逻辑单元的逻辑功能可以由多个候选逻辑门电路实现的情况下,基于每个所述候选逻辑门电路中的基本单元的扇入数确定所述逻辑单元的逻辑门电路。
20.第二方面,本发明还提供一种乘法器,包括:部分积生成模块和部分积求和模块;所述部分积求和模块采用如第一方面所述的部分积求和模块设计方法得到;
21.所述部分积生成模块包括n个部分积生成单元,每个所述部分积生成单元包括串联的编码器和选择器;所述部分积生成模块用于获取被乘数和乘数,基于所述被乘数和所述乘数获得n个部分积,并将所述n个部分积输入至所述部分积求和模块;
22.所述部分积求和模块用于接收所述部分积生成模块输入的所述n个部分积,并基于所述n个部分积获得乘积;
23.其中,n为大于等于1的正整数。
24.可选地,第一选择器至第n-2选择器的电路结构为第一结构,所述第一结构包括第一异或门单元和第一选择器单元;
25.所述第一异或门单元的第一输入端连接被乘数a,所述第一异或门单元的第二输入端连接乘数b;
26.所述第一选择器单元的第一输入端连接所述第一异或门单元的输出端,所述第一选择器单元的第二输入端连接double信号,所述第一选择器单元的第三输入端连接single信号;
27.第n-1选择器和第n选择器的电路结构为第二结构,所述第二结构包括第二选择器单元和第二异或门单元;
28.所述第二选择器单元的第一输入端连接double信号,所述第二选择器单元的第二输入端连接single信号,所述第二选择器单元的第三输入端连接被乘数a;
29.所述第二异或门单元的第一输入端连接所述第二选择器单元的输出端,所述第二异或门单元的第二输入端连接neg信号。
30.可选地,每个所述编码器的输入信号包括乘数b的第2i比特位、第2i 1比特位和第2i 2比特位;每个所述编码器的输出信号包括single信号、double信号和neg信号;
31.所述single信号的逻辑表达式为:
[0032][0033]
所述double信号的逻辑表达式为:
[0034][0035]
所述neg信号的逻辑表达式为:
[0036][0037]
其中,i为大于等于0的自然数,b
2i
表示乘数b的第2i比特位,b
2i 1
表示乘数b的第2i 1比特位,b
2i 2
表示乘数b的第2i 2比特位。
[0038]
可选地,每个所述编码器的输入信号还包括被乘数a的第0比特位,每个所述编码器的输出信号还包括neg_c信号和s信号;
[0039]
所述neg_c信号的逻辑表达式为:
[0040]
[0041]
所述s信号的逻辑表达式为:
[0042]
s=a0·
single;
[0043]
其中,neg表示neg信号,single表示single信号,a0表示被乘数a的第0比特位。
[0044]
可选地,所述编码器的电路包括single信号输出电路、double信号输出电路、neg信号输出电路、和位输出电路和进位输出电路;
[0045]
所述single信号输出电路包括第一异或门电路,所述第一异或门电路的第一输入端连接输入信号b
2i
,所述第一异或门电路的第二输入端连接输入信号b
2i 1
;
[0046]
所述double信号输出电路包括第一反相器、第二反相器、第三反相器、第一与非门电路、第二与非门电路和第三与非门电路;
[0047]
所述第一反相器的输入端连接输入信号b
2i 2
;
[0048]
所述第二反相器的输入端连接输入信号b
2i
;
[0049]
所述第三反相器的输入端连接输入信号b
2i 1
;
[0050]
所述第一与非门电路的第一输入端连接输入信号b
2i
,所述第一与非门电路的第二输入端连接输入信号b
2i 1
,所述第一与非门电路的第三输入端连接所述第一反相器的输出端;
[0051]
所述第二与非门电路的第一输入端连接所述第二反相器的输出端,所述第二与非门电路的第二输入端连接所述第三反相器的输出端,所述第二与非门电路的第三输入端连接输入信号b
2i 2
;
[0052]
所述第三与非门电路的第一输入端连接所述第一与非门电路的输出端,所述第三与非门电路的第二输入端连接所述第二与非门电路的输出端;
[0053]
所述neg信号输出电路包括所述第二反相器、所述第三反相器、第一或门电路和第一与门电路;
[0054]
所述第一或门电路的第一输入端连接所述第二反相器的输出端,所述第一或门电路的第二输入端连接所述第三反相器的输出端;
[0055]
所述第一与门电路的第一输入端连接所述第一或门电路的输出端,所述第一与门电路的第二输入端连接输入信号b
2i 2
;
[0056]
所述和位输出电路包括第二与门电路,所述第二与门电路的第一输入端连接所述第一异或门电路的输出端,所述第二与门电路的第二输入端连接输入信号a0;
[0057]
所述进位输出电路包括第四取反器和第一或非门电路,所述第四取反器的输入端连接neg信号,所述第一或非门电路的第一输入端连接所述第四取反器的输出端,所述第一或非门电路的第二输入端连接所述第二与门电路的输出端。
[0058]
可选地,所述部分积求和模块用于将第n个neg_c信号与第1个部分积生成单元出的部分积的第2n比特位相加;
[0059]
其中,n为部分积生成单元的总数。
[0060]
本发明提供的部分积求和模块设计方法及乘法器,通过每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式,降低了部分积求和模块的翻转功耗,从而降低了部分积求和模块的动态功耗,在部分积求和模块应用于乘法器时,能够实现降低乘法器的动态功耗。
附图说明
[0061]
为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0062]
图1是本发明实施例提供的部分积求和模块设计方法的流程示意图;
[0063]
图2是本发明提供的全加器的晶体管级原理图;
[0064]
图3是本发明实施例提供的alexnet神经网络各层特征图相关性统计图;
[0065]
图4是本发明实施例提供的resnet50神经网络各层特征图相关性统计图;
[0066]
图5是本发明实施例提供的googlenet神经网络各层特征图相关性统计图;
[0067]
图6是本发明实施例提供的6比特数据求和的候选连接方式图;
[0068]
图7是本发明实施例提供的6比特求和最优连接方式及端口分配图;
[0069]
图8是本发明实施例提供的乘法器的结构示意图;
[0070]
图9是本发明提供的传统基4booth编码乘法器中部分积生成单元的结构示意图;
[0071]
图10是本发明实施例提供的先移位后取反的booth选择器模块电路图;
[0072]
图11是本发明实施例提供的先取反后移位的booth选择器模块电路图;
[0073]
图12是本发明实施例提供的基4booth编码乘法器中部分积生成模块的结构示意图;
[0074]
图13是本发明实施例提供的基4booth编码乘法器中部分积生成模块booth编码器模块电路图;
[0075]
图14是本发明实施例提供的基4booth编码乘法器部分积生成模块生成的部分积阵列图;
[0076]
图15是本发明提供的传统基4booth编码乘法器部分积生成模块生成的部分积阵列图;
[0077]
图16是本发明实施例提供的应用wallace树形压缩方法实现的部分积求和模块的结构示意图;
[0078]
图17是本发明实施例提供的基4booth编码8比特乘法器的结构示意图;
[0079]
图18是本发明实施例提供的基4booth编码16比特乘法器的结构示意图;
[0080]
图19是本发明实施例提供的基4booth编码16比特乘法器的部分积生成模块的结构示意图;
[0081]
图20是本发明实施例提供的基4booth编码16比特乘法器的部分积求和模块的结构示意图;
[0082]
图21是本发明提供的常见神经网络三层权重统计分布图;
[0083]
图22是本发明提供的常见神经网络三层特征图统计分布图。
具体实施方式
[0084]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳
动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0085]
下面结合本发明的设计思路对本发明进行介绍。
[0086]
数字乘法器实现的是两个二进制数分别作为被乘数和乘数相乘,得到同样为二进制表示的乘积结果。数字乘法器可以分为两大类:串行乘法器和并行乘法器。串行乘法器主要用于功耗和面积受限的专用集成芯片,例如银行卡上的芯片等。虽然串行乘法器功耗低,面积小,但是串行乘法器完成一次乘法运算需要多个时钟。对于追求高能效的芯片,例如加速神经网络计算的专用集成芯片等,综合考虑时钟树能耗和控制电路能耗,串行乘法器的能效较低,不适合追求高能效的应用。并行乘法器的实现分为三个模块:部分积生成模块、部分积压缩模块和最终相加模块。其中后两个模块由于实现的都是部分积的相加,所以也可以统称为部分积求和模块,则并行乘法器可划分为两个模块,本文即采用这种划分方法。部分积生成模块和部分积求和模块各有若干种实现方法,并行乘法器就按两个模块的实现方式进行分类,例如基-4booth编码树形乘法器等。
[0087]
部分积生成模块的实现有“按位与”、“booth编码”、“verdi”三种方法,其中booth编码又分为基2booth编码、基4booth编码、基8booth编码等。从部分积数量来看,按位与方法、verdi算法、基2booth编码算法这三种方法生成的部分积行数等于乘数的位数,而基4booth编码算法生成的部分积行数等于乘数的位数的一半,这意味着部分积求和模块能够使用更少压缩器实现。而基8booth编码及更高基数的booth编码算法虽然生成的部分积行数比基4booth编码算法生成的部分积行数还要少,但是会出现需要算出3x被乘数这类非2的整数倍的情况,实现电路较为复杂,所以基4booth编码是并行乘法器中部分积生成模块的常用方法。从部分积生成方式来看,基4booth编码需要根据乘数的每3比特进行分组,根据每组的3比特分别对被乘数进行处理,生成相应的一行部分积。以a表示被乘数,生成的部分积有六种情况-0,0,a,-a,2a,-2a,这样的部分积生成方式与“按位与”等方式相比需要额外的编码电路,但考虑到卷积神经网络计算中存在一个操作数固定的特点,若将固定的操作数用于booth编码,就能将这部分额外电路带来的动态能耗省去。此外,现有的基于基4booth编码的部分积生成模块因部分积阵列形状不规则而在求和时产生一定程度的冗余,且都没有考虑到卷积神经网络计算中存在一个操作数固定,另一个操作数前后相关的特点。
[0088]
部分积求和模块有阵列相加,树形相加两种方法,树形相加又分为wallace树形相加、dadda树形相加等。这些方法的本质区别是部分积求和模块中的压缩器连接方式的不同。同样的,现有的部分积求和模块同样没有考虑到卷积神经网络计算中存在一个操作数固定,另一个操作数前后相关的特点。
[0089]
下面结合图1-图7描述本发明实施例提供的部分积求和模块设计方法。
[0090]
图1是本发明实施例提供的部分积求和模块设计方法的流程示意图,如图1所示,本发明实施例提供的部分积求和模块包括至少一个加法器组,每个所述加法器组用于基于输入的多个待相加数据获得相加结果,每个所述加法器组包括多级级联的多个逻辑单元。
[0091]
示例性地,表1是二进制乘法阵列示例表,以101010
×
101为例,得到乘法阵列如表1所示:
[0092]
表1.二进制乘法阵列示例表
[0093][0094][0095]
应理解,每一列为一组待相加数据,每一列对应一组加法器组,加法器组将对应待相加数据相加,得到相加结果。如第一列对应待相加数据“0”、“1”和“0”,第一列对应的加法器组实现“0 1 0”,得到和位输出1,进位输出0,将进位输出“0”输入至第二列对应的加法器组中。
[0096]
本发明实施例提供的部分积求和模块设计方法包括:
[0097]
步骤110,确定每个所述加法器组各自对应的每个所述待相加数据的翻转率;
[0098]
可选地,每个所述加法器组各自对应的每个所述待相加数据的翻转率可以通过synopsys vcs软件获得,如神经网络计算场景中,将目标神经网络输入至synopsys vcs,获得synopsys vcs输出的目标神经网络的数据的翻转率结果,目标神经网络的数据与部分积求和模块的待相加数据是同一的。
[0099]
步骤120,基于每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式。
[0100]
应理解,在基于待相加数据的翻转率确定加法器组的数据连接方式的情况下,逻辑单元为加法器,加法器可以包括全加器或半加器。
[0101]
具体地,使用cmos数字逻辑电路的神经网络加速器芯片中的乘法器动态能耗占95%以上,而静态能耗只占不到5%。cmos逻辑电路的动态功耗分为两部分,一部分是对逻辑单元对负载电容充放电导致的翻转功耗和逻辑单元内部p管n管同时导通导致的短路功耗,则任意逻辑单元的动态功耗计算公式为:
[0102]
p
dynamic
=p
switch
p
short
;
[0103]
p
switch
=αfcv2;
[0104]
p
short
=2αt
sc
vi
peak
f;
[0105]
其中,p
dynamic
为动态功耗,p
switch
为翻转功耗,p
short
为短路功耗,α为逻辑单元的一个输出的0
→
1的翻转概率,简称为翻转率;c为逻辑单元的输出的负载电容,包括逻辑单元本身的负载和外部负载;v为逻辑单元的工作电压;t
sc
为短路电流脉冲等效脉冲宽度;i
peak
为短路脉冲电流脉冲高度;f为时钟频率。可见逻辑单元的动态功耗与逻辑单元的一个输出的0
→
1的翻转概率α密切相关,而输出翻转率α又是根据输入翻转率β以及逻辑单元的逻辑关系算出:
[0106]
α=f(β1,β2,
…
,βn);
[0107]
其中,β1,
…
βn为逻辑单元n个输入的0
→
1翻转率,f为与逻辑单元逻辑表达式有关
的函数。
[0108]
示例性地,在已有多种候选连接方式的情况下,如方式1:将数据a输入至加法器a,将数据b输入至加法器b;方式2:将数据b输入至加法器a,将数据a输入至加法器b,在获得每个所述待相加数据的翻转率后,通过翻转率确定每种数据连接方式的翻转功耗,从而确定每种数据连接方式的动态功耗,选择动态功耗最小的加法器组的数据连接方式。
[0109]
本发明实施例提供的部分积求和模块设计方法,通过每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式,降低了部分积求和模块的翻转功耗,从而降低了部分积求和模块的动态功耗,在部分积求和模块应用于乘法器时,能够实现降低乘法器的动态功耗。
[0110]
下面,对上述步骤在具体实施例中的可能的实现方式做进一步说明。
[0111]
可选地,所述基于每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式,包括:
[0112]
步骤121,将高翻转率待相加数据输入至所述加法器组中的后级逻辑单元;
[0113]
步骤122,将低翻转率待相加数据输入至所述加法器组中的前级逻辑单元。
[0114]
具体地,高翻转率和低翻转率是指待相加数据在加法器组对应的多个待相加数据中的数值大小相对高低,示例性地,待相加数据包括a和b,a的翻转率为0.1,b的翻转率为0.01,则a相对于b是高翻转率待相加数据。后级逻辑单元用于处理前级发送的数据,即后级逻辑单元的输入中至少有一个输入为前级逻辑单元的输出。示例性地,以加法器为例,加法器组中的加法器级联级数大于等于三的情况下,可以对加法器进行两两比较,如第一加法器的输出端连接第二加法器的输入端,第二加法器的输出端连接第三加法器的输入端,则第二加法器相对于第三加法器为前级加法器,第二加法器相对于第一加法器为后级加法器。
[0115]
一般假设:逻辑单元的各个输入信号相互独立,且前一次输入与后一次输入也相互独立,α可通过输入的翻转率以及逻辑单元的逻辑关系算出。
[0116]
以全加器为例,记全加器三个输入为a、b、c,进位输出co,和位输出s;又记全加器三个输入为1的概率分别为p(a=1)=a,p(b=1)=b,p(c=1)=c。表2是本发明提供的全加器真值表,如表2所示:
[0117]
表2.全加器真值表
[0118][0119][0120]
则由独立事件概率公式可得输出s、co为1的概率分别为
[0121]
s=p(s=1)=a(1-b)(1-c) b(1-a)(1-c) c(a-1)(b-1) abc;
[0122]
co=p(co=1)=ab(c-1) ac(b-1) bc(a-1) abc;
[0123]
同样由独立事件概率公式可得输出s、co的翻转率α(s)、α(co)分别为:
[0124]
α(s)=s(1-s);
[0125]
α(co)=co(1-co);
[0126]
本发明实施例中的全加器选用镜像全加器,图2是本发明提供的全加器的晶体管级原理图,如图2所示,co与s两个输出端接到下一个全加器的输入端,分别有10个与8个栅极电容作为负载,负载电容远远高于电路中的其他节点,故全加器的翻转功耗高低可以由co、s两个输出端的翻转率来近似度量。
[0127]
图3是本发明实施例提供的alexnet神经网络各层特征图相关性统计图,图4是本发明实施例提供的resnet50神经网络各层特征图相关性统计图,图5是本发明实施例提供的googlenet神经网络各层特征图相关性统计图,常见神经网络各层的相关性如图3、图4和图5所示。在进行神经网络计算时,往往会利用神经网络的卷积特性,将一个操作数固定,而改变另一个操作数,以达到减少访问存储器的目的,从而减少能耗。因此,在乘法器计算时,存在一个操作数固定,另一个操作数前后两次输入之间存在相关性的特点。
[0128]
由于实际输入前后两次有较强相关性,传统的翻转率α的计算方法得到的结果与实际情况差距较大。所以本发明提出输入数据前后有相关性情况下的翻转率的计算方法。
[0129]
输出翻转率公式:
[0130]
α=f(β1,β2,
…
,βn,γ1,
…
,γn);
[0131]
其中,α为输出翻转率,(β1,β2,
…
,βn)为逻辑单元n个输入的由0翻转为1的翻转率,(γ1,...,γn)为逻辑单元n个输入的由1保持为1的保持率,f为根据逻辑单元的逻辑表达式确定的函数。
[0132]
应理解,f是根据逻辑单元的输入输出确定的,计算逻辑单元输出翻转的情况下,对应的所有的输入情况的概率。因此,根据逻辑单元的不同,f也不同;但是对于一个确定的
逻辑单元,f是确定的。以与门和加法器进行举例,应理解,以下是为便于理解本发明进行的示例,不应对本发明构成任何限定,本发明未进行举例的逻辑单元对应的函数也在本发明保护范围内。
[0133]
以与门举例,a、b为与门的输入,c为与门的输出,表3是本发明提供的与门真值表,如表3所示:
[0134]
表3.与门真值表
[0135]
abc000010100111
[0136]
由与门真值表及全概率公式,可以得到与门的输出翻转率计算公式:
[0137]
α(c)=p0→1(c)=
[0138]
p0→1(a)p0→1(b) p0→1(a)p1→1(b) p1→1(a)p0→1(b)。
[0139]
以全加器为例,参照上述全加器真值表及翻转率计算公式,可以得到全加器的输出翻转率公式如下:
[0140]
α(s)=p0→0(a)p0→0(b)p0→1(c) p0→0(a)p0→1(b)p0→0(c)
[0141]
p0→1(a)p0→0(b)p0→0(c)
[0142]
p0→1(a)p0→1(b)p0→1(c) p0→0(a)p1→0(b)p1→1(c)
[0143]
p0→0(a)p1→1(b)p1→0(c)
[0144]
p0→1(a)p1→0(b)p1→0(c) p0→1(a)p1→1(b)p1→1(c)
[0145]
p1→0(a)p0→0(b)p1→1(c)
[0146]
p1→0(a)p0→1(b)p1→0(c) p1→1(a)p0→0(b)p1→0(c)
[0147]
p1→1(a)p0→1(b)p1→1(c)
[0148]
p1→0(a)p0→0(b)p1→1(c) p1→0(a)p0→1(b)p1→0(c)
[0149]
p1→1(a)p0→0(b)p1→0(c)
[0150]
p1→1(a)p0→1(b)p1→1(c);
[0151]
α(co)=p0→0(a)p0→1(b)p0→1(c) p0→1(a)p0→1(b)p0→0(c)
[0152]
p0→1(a)p0→0(b)p0→1(c)
[0153]
p0→1(a)p0→1(b)p0→1(c) p0→0(a)p0→1(b)p1→1(c)
[0154]
p0→1(a)p0→1(b)p1→0(c)
[0155]
p0→1(a)p0→0(b)p1→1(c) p0→1(a)p0→1(b)p1→1(c)
[0156]
p0→0(a)p1→1(b)p0→1(c)
[0157]
p0→1(a)p1→1(b)p0→0(c) p0→1(a)p1→0(b)p0→1(c)
[0158]
p0→1(a)p1→1(b)p0→1(c)
[0159]
p1→0(a)p0→1(b)p0→1(c) p1→1(a)p0→1(b)p0→0(c)
[0160]
p1→1(a)p0→0(b)p0→1(c)
[0161]
p1→1(a)p0→1(b)p0→1(c)。
[0162]
对于两个全加器级联的情况,设第一级全加器为fa1,输入端为a1、b1、c1,输出端
s1、co1;第二级全加器为fa2,输入端s1、b2、c2,输出端co2,s2。由上所述,当全加器s与co端负载相差不大时可以用α(s1) α(co1) α(s2) α(co2)代表两个全加器的能耗。将翻转率从低到高排序的p1~p5五个端口分配至a1、b1、c1、b2、c2五个端口,对于不同的分配方法,相加结果s2相同,其翻转率不变,所以需比较α(s1) α(co1) α(co2)的值来对比不同分配方法的能耗。
[0163]
下面证明两个全加器级联时高翻转率端口分配到后级的情况下能耗更低:因统计输入数据得出输入端p0→0、p1→1改变相对p0→1很小,所以有:
[0164]
α(s1)=fs(α(a1),α(b1),α(c1));
[0165]
α(co1)=f
co
(α(a1),α(b1),α(c1));
[0166]
α(co2)=f
co
(fs(α(a1),α(b1),α(c1)),α(b2),α(c2))。
[0167]
高翻转端口p4、p5中有端口被分配至第一级的情况,相对p4、p5都被分配至第二级的情况,前一种情况由公式易知α(s1)与α(co1)比第二种情况更高,α(co2)可能相反地在第二种情况下更高。但如果fs(α(a1),α(b1),α(c1)),α(b2),α(c2)三项中存在第二种情况下更高的项,fs(α(a1),α(b1),α(c1))一定更低,所以α(co1)、α(co2)的和依然在第一种情况下更高,所以两个全加器级联时高翻转率端口分配到后级的情况下能耗更低。
[0168]
因此,对于多级级联的若干逻辑单元,将翻转率高的输入数据接到后级逻辑单元,而将翻转率低的输入数据接到前级逻辑单元。
[0169]
示例性地,部分积求和模块使用若干全加器(full-adder,fa)和半加器(half-adder,ha)连接组成。连接方式通过本实施例中改进的翻转率计算公式计算翻转率,得出最优化的连接方式。以图14中第五列求和为例,第五列求和一共有6比特输入,包括3比特部分积和3比特第四列求和产生的进位,用已有神经网络的数据进行仿真可得到这六个输入的翻转率,按翻转率从低到高重新命名为p1~p6。为尽可能少地在本列中产生进位,求和电路应尽量少使用半加器,所以本列使用两个全加器和一个半加器,一共有五种连接方式,图6是本发明实施例提供的6比特数据求和的候选连接方式图,每种连接方式还存在多种将p1~p6与输入端口的分配方式。经计算,可以得出第4种连接方式最优,拥有最低的翻转率。图7是本发明实施例提供的6比特求和最优连接方式及端口分配图,最终连接方式如图7所示。
[0170]
第六列的求和有7比特输入,包括4比特部分积和3比特第五列求和产生的进位。确定了第五列连接方式后进行仿真可得到第六列输入的翻转率信息,进而通过与第五列相同的步骤确定第六列求和的压缩器连接方式和输入端口分配方式。如此可以得到部分积所有列的连接方式。最终得到的部分积求和模块如图17虚线框内和图20所示。
[0171]
本发明实施例提供的部分积求和模块设计方法,基于神经网络前后两次输入的相关性特点,通过获得部分积求和模块内部各节点的翻转率大小关系,依据该大小关系优化加法器的数据连接方式,降低了部分积求和模块的翻转能耗,从而降低了部分积求和模块的翻转能耗。
[0172]
可选地,基于每个所述待相加数据的翻转率,确定每个所述加法器组的数据连接方式,包括:
[0173]
基于每个所述待相加数据的翻转率、每个所述待相加数据的保持率和输出翻转率公式,确定每种候选数据连接方式中每个逻辑单元的输出翻转率;
[0174]
基于每个逻辑单元的输出翻转率,确定每个所述加法器组的总输出翻转率;
[0175]
将最小总输出翻转率对应的候选数据连接方式作为优选数据连接方式;
[0176]
所述输出翻转率公式为:
[0177]
α=f(β1,β2,
…
,βn,γ1,
…
,γn);
[0178]
其中,α为输出翻转率,(β1,β2,
…
,βn)为逻辑单元n个输入的由0翻转为1的翻转率(即待相加数据的翻转率),(γ1,
…
,γn)为逻辑单元n个输入的由1保持为1的保持率(待相加数据的保持率),f为根据逻辑单元的逻辑表达式确定的函数。
[0179]
本发明实施例提供的部分积求和模块设计方法,根据待相加数据的翻转率和保持率计算逻辑单元的输出翻转率,从而获得加法器组的总输出翻转率,选择最小输出翻转率,优化了加法器的数据连接方式,降低了部分积求和模块的翻转能耗,从而降低了部分积求和模块的翻转能耗。可选地,每个所述加法器包括一个或多个逻辑单元;
[0180]
在所述逻辑单元的逻辑功能可以由多个候选逻辑门电路实现的情况下,基于每个所述候选逻辑门电路中的基本单元的扇入数确定所述逻辑单元的逻辑门电路。
[0181]
应理解,在确定逻辑门电路的情况下,逻辑单元是指实现逻辑功能的单元模块,可以是基础门电路及其组合。
[0182]
对于同样的逻辑功能,可以使用方式1:一个大扇入逻辑门或方式2:若干个小扇入逻辑门两种方法实现,则这两种电路的短路功耗分别为:
[0183]
方式1的短路功耗:p
short
=2αt
sc
vi
peak
f;
[0184]
方式2的短路功耗:
[0185]
其中,短路电流脉冲等效脉冲宽度t
sc
由输入的上升沿、下降沿宽度决定,因为方式1和方式2完成的逻辑功能相同,所以输入相同,输入的上升沿、下降沿宽度相同,t
sc
也相同;工作电压v定为相同;时钟频率f定为相同;i
peak
由工作电压以及短路通路上的电阻决定,由于大扇入逻辑门堆叠的晶体管比小扇入逻辑门多,所以大扇入逻辑门短路通路上的电阻更大,i
peak
更小。
[0186]
示例性地,以使用一个四输入与门和使用三个二输入与门完成y=a&b&c&d为例:假设输入a,b,c,d翻转率均为50%,无相关性,则使用一个四输入与门:
[0187][0188][0189]
使用三个二输入与门,记y1=a&b,y2=c&d,y=y1&y2,则:
[0190][0191][0192][0193][0194]
[0195][0196][0197]
可见使用三个二输入与门的短路功耗比使用一个四输入与门的功耗高。
[0198]
因此,尽量使用标准单元库内提供的大扇入逻辑门而少用小扇入的逻辑门。应理解,此处的扇入大或小是指相对于另一候选逻辑门电路的数值比较。
[0199]
本发明实施例提供的部分积求和模块设计方法,基于每个所述候选逻辑门电路中的基本单元的扇入数确定所述逻辑单元的逻辑门电路,降低了部分积求和模块的短路能耗,从而降低了部分积求和模块的动态能耗。
[0200]
下面结合图8-图22描述本发明实施例提供的乘法器。
[0201]
图8是本发明实施例提供的乘法器的结构示意图,如图8所示,本发明实施例提供的乘法器,包括:部分积生成模块和部分积求和模块;所述部分积求和模块采用上文实施例中所述的部分积求和模块设计方法得到;
[0202]
所述部分积生成模块包括n个部分积生成单元,每个所述部分积生成单元包括串联的编码器和选择器;所述部分积生成模块用于获取被乘数和乘数,基于所述被乘数和所述乘数获得n个部分积,并将所述n个部分积输入至所述部分积求和模块;
[0203]
所述部分积求和模块用于接收所述部分积生成模块输入的所述n个部分积,并基于所述n个部分积获得乘积;
[0204]
其中,n为大于等于1的正整数。
[0205]
可选地,本发明实施例提供的乘法器可以是基4booth乘法器,部分积生成模块用于对两个任意比特长度的操作数a和b(也称为被乘数a和乘数b)根据基4booth编码算法求得部分积。过程如下:对乘数b进行三三分组,前一组的最高位与后一组的最低位交叠一比特位(最后一组不足3比特的,在最高位补0),表4.为传统基4booth编码算法求得的部分积,基4booth编码器生成的每组相应的部分积如表4所示:
[0206]
表4.传统基4booth编码算法求得的部分积
[0207]b2i 1b2ib2i-1
部分积0000001a010a0112a100-2a101-a110-a111-0
[0208]
该算法可以用如下数学式表示:
[0209][0210]
部分积生成模块可以分为编码器模块和选择器模块。图9是本发明提供的传统基4booth编码乘法器中部分积生成单元的结构示意图,如图9所示,编码器根据乘数的一组三
比特编码出single,double和neg信号,neg信号同时也是部分积的一比特,需要在部分积相加模块中进行求和。应理解,一个或多个部分积生成单元相连接可以组成部分积生成模块。表5是传统的编码器的编码逻辑,如表5所示:
[0211]
表5.传统的编码器的编码逻辑
[0212]b2ib2i-1b2i-2
singledoubleneg000000001100010100011010100011101101110101111001
[0213]
其逻辑表达式如下:
[0214][0215][0216]
neg=b2;
[0217]
booth选择器根据编码器产生的single、double、neg比特对被乘数a进行移位与否,取非与否的处理。single为1且double为0时不移位,根据neg为0或1生成部分积p=a或p=-a;single为0且double为1时左移一位,根据neg为0或1生成部分积p=2a或p=-2a;single为0且double为0时生成部分积p=0。
[0218]
本发明实施例提供的乘法器中的部分积求和模块采用上文实施例中所述的部分积求和模块设计方法得到,因此能够实现降低翻转功耗和/或短路功耗,从而降低乘法器的动态功耗。
[0219]
可选地,第一选择器至第n-2选择器的电路结构为第一结构,所述第一结构包括第一异或门单元和第一选择器单元;
[0220]
所述第一异或门单元的第一输入端连接被乘数a,所述第一异或门单元的第二输入端连接neg信号;
[0221]
所述第一选择器单元的第一输入端连接所述第一异或门单元的输出端,所述第一选择器单元的第二输入端连接double信号,所述第一选择器单元的第三输入端连接single信号;
[0222]
第n-1选择器和第n选择器的电路结构为第二结构,所述第二结构包括第二选择器单元和第二异或门单元;
[0223]
所述第二选择器单元的第一输入端连接double信号,所述第二选择器单元的第二输入端连接single信号,所述第二选择器单元的第三输入端连接被乘数a;
[0224]
所述第二异或门单元的第一输入端连接所述第二选择器单元的输出端,所述第二异或门单元的第二输入端连接neg信号。
[0225]
具体地,如上文所述,部分积有多种取值情况,其生成需要两部分电路来实现,一
是从0、a、2a中做选择的选择器(mux),二是实现取反的异或门(xor)。应理解,8比特乘法器中包含4个选择器,16比特乘法器中包含8个选择器,以此类推,因此,n通常大于等于4。
[0226]
具体实现方式可以包括:
[0227]
方式1:让被乘数a先通过mux后通过xor,即第二结构。
[0228]
方式2:让被乘数a先通过xor后通过mux,即第一结构。
[0229]
示例性地,以8比特输入为例,图10是本发明实施例提供的先移位后取反的booth选择器模块电路图,图11是本发明实施例提供的先取反后移位的booth选择器模块电路图,图10对应于方式1,采用第二结构,图11对应于方式2,采用第一结构。以图11为例,如图11所示,每个输出对应一个选择器,即p[1]至p[8]分别对应一个选择器。
[0230]
8比特乘法需要4行部分积,即4个选择器。常见深度学习网络的权重值的绝对值通常较小,输入到乘数b时,b[7:5]与b[5:3]处于全0或全1的情况较普遍,如表4所示,全0或全1的情况下,部分积为0,因此后2行部分积保持0的概率大,本发明实施例中后2个选择器选用第二结构,其他选择器用第一结构。应理解,最高比特位对应的选择器为最后一个选择器(p[8]对应的选择器),依次类推。
[0231]
第一结构中xor的输出会随a的改变而改变,产生动态能耗,第二结构的选择器会因逻辑门输入延时不匹配而产生毛刺,但在部分积始终保持0的情况时,mux与xor的输出均保持0,本发明实施例提供的乘法器,将选择器的第一结构和第二结构结合,第1选择器至第n-2选择器采用第一结构,避免输入延时产生毛刺,后两个选择器采用第二结构,在部分积始终保持0的情况时,mux与xor的输出均保持0,降低动态能耗,本发明实施例提供的乘法器实现了动态能耗的降低。
[0232]
可选地,每个所述编码器的输入信号包括乘数b的第2i比特位、第2i 1比特位和第2i 2比特位;每个所述编码器的输出信号包括single信号、double信号和neg信号;
[0233]
所述single信号的逻辑表达式为:
[0234][0235]
所述double信号的逻辑表达式为:
[0236][0237]
所述neg信号的逻辑表达式为:
[0238][0239]
其中,i为大于等于0的自然数,b
2i
表示乘数b的第2i比特位,b
2i 1
表示乘数b的第2i 1比特位,b
2i 2
表示乘数b的第2i 2比特位。
[0240]
具体地,根据表4可知,传统部分积有六种情况:
±
0、
±
a和
±
2a,其中带负号的情况即求补码,传统方式为按位取反后最低位加1,例如-0的情况即对0求补码,部分积p=111
…
1 1。加1通过在部分积阵列中加入neg比特来实现。当乘数的绝对值较小,在0上下浮动时,会有多行部分积为0或-0,上述将0与-0区分开的传统方式会使部分积在000
…
0与111
…
1间反复翻转,产生不必要的动态能耗。
[0241]
图12是本发明实施例提供的基4booth编码乘法器中部分积生成模块的结构示意图,如图12所示,本发明实施例中,将neg比特采用下述逻辑表达式:
[0242][0243]
表6.本发明实施例提供的逻辑编码之一
[0244]
b[3:1]singledoubleneg000000001100010100011010100011101101110101111000
[0245]
表6是本发明实施例提供的逻辑编码之一,如表6所示,本发明实施例提供的乘法器,能够统一部分积为0与-0两种情况,避免了0与-0的动态翻转,降低了乘法器的动态能耗。
[0246]
可选地,每个所述编码器的输入信号还包括被乘数a的第0比特位,每个所述编码器的输出信号还包括neg_c信号和s信号;
[0247]
所述neg_c信号的逻辑表达式为:
[0248][0249]
所述s信号的逻辑表达式为:
[0250]
s=a0·
single;
[0251]
其中,neg表示neg信号,single表示single信号,a0表示被乘数a的第0比特位。
[0252]
应理解,本发明实施例中对比特位的排序采用第0、1、2
……
的方式进行排序,对其他的结构、单元或行列采用第1、2、3
……
的方式进行排序,排序方式是为了便于理解本发明实施例,不应对本发明构成任何限定。
[0253]
表6.本发明实施例提供的逻辑编码之二
[0254]
negsinglea[0]sneg_c0000000100010000111010001101011100111110
[0255]
可选地,图13是本发明实施例提供的基4booth编码乘法器中部分积生成模块booth编码器模块电路图,如图13所示,所述编码器的电路包括single信号输出电路、double信号输出电路、neg信号输出电路、和位(s)输出电路和进位(n)输出电路;
[0256]
所述single信号输出电路包括第一异或门电路,所述第一异或门电路的第一输入端连接输入信号b
2i
,所述第一异或门电路的第二输入端连接输入信号b
2i 1
;所述第一异或门电路的输出端为single信号;
[0257]
所述double信号输出电路包括第一反相器、第二反相器、第三反相器、第一与非门电路、第二与非门电路和第三与非门电路;
[0258]
所述第一反相器的输入端连接输入信号b
2i 2
;
[0259]
所述第二反相器的输入端连接输入信号b
2i
;
[0260]
所述第三反相器的输入端连接输入信号b
2i 1
;
[0261]
所述第一与非门电路的第一输入端连接输入信号b
2i
,所述第一与非门电路的第二输入端连接输入信号b
2i 1
,所述第一与非门电路的第三输入端连接所述第一反相器的输出端;
[0262]
所述第二与非门电路的第一输入端连接所述第二反相器的输出端,所述第二与非门电路的第二输入端连接所述第三反相器的输出端,所述第二与非门电路的第三输入端连接输入信号b
2i 2
;
[0263]
所述第三与非门电路的第一输入端连接所述第一与非门电路的输出端,所述第三与非门电路的第二输入端连接所述第二与非门电路的输出端;所述第三与非门电路的输出端为double信号;
[0264]
所述neg信号输出电路包括所述第二反相器、所述第三反相器、第一或门电路和第一与门电路;
[0265]
所述第一或门电路的第一输入端连接所述第二反相器的输出端,所述第一或门电路的第二输入端连接所述第三反相器的输出端;
[0266]
所述第一与门电路的第一输入端连接所述第一或门电路的输出端,所述第一与门电路的第二输入端连接输入信号b
2i 2
;所述第一与门电路的输出端为neg信号;
[0267]
所述和位输出电路包括第二与门电路,所述第二与门电路的第一输入端连接所述第一异或门电路的输出端,所述第二与门电路的第二输入端连接输入信号a0;所述第二与门电路的输出端为和位(图13中为s);
[0268]
所述进位输出电路包括第四取反器和第一或非门电路,所述第四取反器的输入端连接neg信号,所述第一或非门电路的第一输入端连接所述第四取反器的输出端,所述第一或非门电路的第二输入端连接所述第二与门电路的输出端;所述第一或非门电路的输出为进位(图13中为n)。应理解,图13中的nor2b门相当于第四取反器和第二或非门的组合。
[0269]
应理解,图13中的b[1]对应于输入信号b
2i
,b[2]对应于输入信号b
2i 1
,b[3]对应于输入信号b
2i 2
。
[0270]
可选地,所述部分积求和模块用于将第n个neg_c信号与第1个部分积生成单元出的部分积的第2n比特位相加;
[0271]
其中,n为部分积生成单元的总数。
[0272]
具体地,图14是本发明实施例提供的基4booth编码乘法器部分积生成模块生成的部分积阵列图,图15是本发明提供的传统基4booth编码乘法器部分积生成模块生成的部分积阵列图。传统方式生成的booth部分积阵列中,每行部分积的neg信号都会加到本行的最低比特上。8比特传统booth乘法器部分积阵列如图15所示,传统booth乘法器部分积阵列最
后一行存在一个孤立的neg比特。这使阵列中最长列的长度为5,需要增加压缩器。应理解,部分积阵列图可以表示待相加数据的类型和位置,乘法器会对阵列图中的每一列数据进行相加操作。
[0273]
具体地,第n个neg_c信号即第n个部分积生成单元对应的neg_c信号,即部分积阵列表中的末行部分积的neg_c比特,第1个部分积生成单元出的部分积即部分积阵列表中的首行部分积。如图14所示,本发明实施例中,将每行部分积会将neg_c比特(即neg_c信号)加到第2低比特上,将末行部分积的neg_c比特加到了首行部分积上,省去了传统booth乘法器部分积阵列最后一行存在一个孤立的neg比特,将阵列的最长列长度减至4。
[0274]
本发明实施例通过将末行部分积的neg_c比特加到了首行部分积上,实现了缩短阵列长度,使部分积阵列形状更为规则,易于后面的部分积求和模块以更少的压缩器单元对部分积进行求和。本发明实施例提供的乘法器,对乘法器中的部分积生成模块进行了改进,通过将部分积阵列行数减少一行,使求和电路减少,从而提高乘法器能效。利用卷积神经网络计算中存在一个操作数固定,另一个操作数前后相关的特点,改进了乘法器部分积生成模块并根据部分积翻转率大小关系制定了部分积求和模块中的压缩器连接方式,进一步提高乘法器在卷积神经网络计算中的能效。
[0275]
一个实施例中,图16是本发明实施例提供的应用wallace树形压缩方法实现的部分积求和模块的结构示意图,本发明实施例提供的部分积求和模块采用传统wallace树形结构进行求和,结构如图16所示。
[0276]
一个实施例中,图17是本发明实施例提供的基4booth编码8比特乘法器的结构示意图;如图17所示,乘数为8比特,所以部分积生成模块有四个部分积生成子模块。根据本发明实施例1中描述的方法,可以计算得出翻转率最低的部分积生成模块结构,即生成前两行部分积的部分积子模块中的选择器使用第一结构,而生成后两行部分积的部分积子模块中的选择器使用第二结构。固定的操作数作为乘数y,另一个操作数作为被乘数x输进部分积生成模块,得到如图14所示的部分积阵列,并将该部分积阵列输进部分积求和模块。根据本发明实施例2中描述的设计方法,可以求得翻转率最低的压缩器(部分积求和模块)连接方式,如图17虚线框内所示,其中fa表示全加器,ha表示半加器。部分积阵列经部分积求和模块求和得到最终乘积结果f[15:0]。
[0277]
图18是本发明实施例提供的基4booth编码16比特乘法器结构的示意图,图19是本发明实施例提供的基4booth编码16比特乘法器的部分积生成模块的结构示意图,图20是本发明实施例提供的基4booth编码16比特乘法器的部分积求和模块的结构示意图,如图18、图19和图20所示,本发明实施例提供的16比特基4booth编码乘法器包括部分积生成模块和部分积求和模块。
[0278]
部分积生成模块:参照本发明实施例上文所描述的部分积生成模块。由于乘数为16比特,所以部分积生成模块有八个部分积生成子模块,可以计算得出翻转率最低的部分积生成模块结构,即生成后两行部分积的部分积子模块中的选择器使用如图10所示的选择器,而生成前六行部分积的部分积子模块中的选择器使用如图11所示的选择器。固定的操作数作为乘数y,另一个操作数作为被乘数x输进部分积生成模块,得到如图14所示的部分积阵列,并将该部分积阵列输进部分积求和模块。
[0279]
部分积求和模块:根据本发明实施例提供的设计方法,可以求得翻转率最低的压
缩器连接方式,如虚线框内所示,其中fa表示全加器,ha表示半加器。部分积阵列经部分积求和模块求和得到最终乘积结果f[31:0]。
[0280]
表8.对比结果
[0281]
[0282][0283]
表8是本发明实施例提供的对比结果表,如表8所示,将发明实施例提供的乘法器与三种现有乘法器进行比较。对比对象一是2009年shiann-rong kuang等人发表于ieee transactions on circuits and systems—ii的乘法器,对比对象二是2016年panagiotis sakellariou等人发表于ieee transcation on computer的乘法器,对比对象三是2018年h.xue等人发表于electronics letters的乘法器。对于8bit乘法器,本发明相比于三种乘法器中相应指标最好的乘法器,延时小6.78%,面积小0.86%,输入数据为随机数的情况下能耗小12.10%,进行alexnet推理计算时能耗小27.65%,进行vgg16推理计算时能耗小28.74%,进行resnet18推理计算时能耗小30.93%;对于16bit乘法器,本发明相比于三种乘法器中相应指标最好的乘法器,延时小1.66%,面积小6.01%,输入数据为随机数的情况下能耗小4.18%,进行alexnet推理计算时能耗小41.27%,进行vgg16推理计算时能耗小44.88%,进行resnet18推理计算时能耗小40.35%;性能对比如表8所示。能耗、面积、延时仿真结果是基于smic 40nm逻辑工艺,使用verilog硬件描述语言进行设计、synopsys design compiler、synopsys ic compiler、synopsys primetime等软件进行的综合、布局布线以及仿真所得到的结果。
[0284]
本发明实施例中基于进行神经网络计算时存在一个操作数固定,而只改变另一个操作数的特点,通过相关性和翻转率的低能耗设计方法,booth乘法器中部分积生成模块的编码部分在输入固定时没有动态能耗,所以将固定的操作数作为乘数输入到乘法器,而另一个操作数作为被乘数输入到乘法器。图21是本发明提供的常见神经网络三层权重统计分布图,如图21所示,通过对神经网络进行分析,可以得到神经网络的权重数据呈现正态分布的统计特点;图22是本发明实施例提供的常见神经网络三层特征图统计分布图,如图22所示,特征图数据呈现半边正态分布的统计特点;图像数据和特征图数据相邻点之间相关性较强的特点。这意味着定点数表示下的权重和特征图数据的低位翻转率较高,高位翻转率较低,且高位为全0和全1的概率较高。则对于乘法器来说,由于固定的操作数作为乘数输进
编码器,会使得部分积行与行之间的翻转率有着首行到末行翻转率逐渐降低的特点。又由于不固定的操作数前后输入有较强的相关性,所以每行部分积各比特之间有着低比特到高比特翻转率逐渐降低的特点。
[0285]
在此需要说明的是,本发明实施例提供的上述装置,能够实现上述方法实施例所实现的所有方法步骤,且能够达到相同的技术效果,在此不再对本实施例中与方法实施例相同的部分及有益效果进行具体赘述。
[0286]
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
[0287]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。