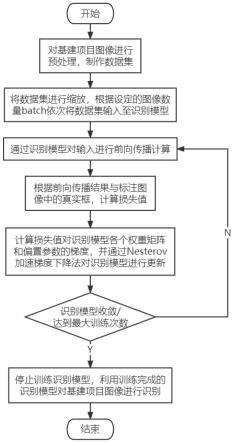
1.本发明涉及计算机自然语言处理技术领域,特别涉及一种融合注意力机制和片段排列的实体关系联合抽取方法。
背景技术:
2.随着科学技术的发展,越来越多重要的信息以文本的形式出现我们的身边,比如论文资料、报纸新闻、社交聊天以及博客等。这些文本信息存在信息量大、内容繁杂、结构不一致等问题,使得人们很难快速从这些文本信息中获取有用的信息。在这样信息爆炸的现代社会,如何快速有效的从这些信息冗余、结构混乱的文档中抽取出有用的信息,并将这些有用信息以固定形式存储,以便后续用户能够精准和快速对这些信息进行利用已经成为亟需解决的挑战。面对这个挑战,人们提出了信息抽取。而实体和关系抽取是信息抽取的关键任务之一,近些年来受到学术界和工业界的广泛关注。它可以为自动问答、信息检索、知识库填充、知识推理等下游任务提供支持。
3.命名实体识别和关系抽取的研究方法主要分为两大类:流水线方法和联合抽取方法。流水线方法通常需要训练两个模型,一个用于命名实体识别,另一个用于关系抽取。联合抽取方法是将命名实体识别和关系抽取这两个任务联合建模,要么将它们投影到结构化预测框架中,要么通过共享表示执行多任务学习。虽然流水线方法易于实现,这两个抽取模型的灵活性高,实体抽取模型和关系抽取模型可以使用独立的数据集,并不需要同时标注实体和关系的数据集。但流水线方法忽略了这两个任务之间的内在联系和依赖关系,实体抽取的错误会影响下一步关系抽取的性能。
技术实现要素:
4.本发明是为解决上述问题而提出的,目的在于提供一种准确的、适应性强的融合注意力机制和片段排列的实体关系联合抽取方法,本发明采用了如下技术方案:
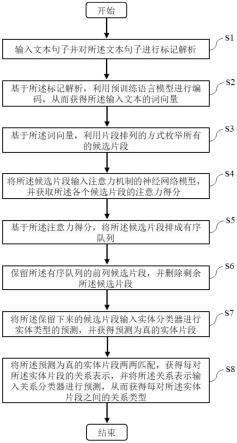
5.本发明提供了一种融合注意力机制和片段排列的实体关系联合抽取方法,其特征在于,包括以下步骤:步骤s1,输入文本句子并对所述文本句子进行标记解析;步骤s2,基于所述标记解析,利用预训练语言模型进行编码,从而获得所述输入文本的词向量;步骤s3,基于所述词向量,利用片段排列的方式枚举所有的候选片段;步骤s4,将所述候选片段输入注意力机制的神经网络模型,并获取所述各个候选片段的注意力得分;步骤s5,基于所述注意力得分,将所述候选片段排成有序队列;步骤s6,保留所述有序队列的前列候选片段,并删除剩余所述候选片段;步骤s7,将所述保留下来的候选片段输入实体分类器进行实体类型的预测,并获得预测为真的实体片段;步骤s8,将所述预测为真的实体片段两两匹配,获得每对所述实体片段的关系表示,并将所述关系表示输入关系分类器进行预测,从而获得每对所述实体片段之间的关系类型。
6.本发明提供的融合注意力机制和片段排列的实体关系联合抽取方法,还可以具有这样的技术特征,其中,步骤s1中的对所述输入文本句子进行标记解析是指将所述文本句
子解析成自然语言处理最基本的单元。
7.本发明提供的融合注意力机制和片段排列的实体关系联合抽取方法,还可以具有这样的技术特征,其中,步骤s5中将所述候选片段排成有序队列是按照所述注意力得分从大到小的顺序进行排列的。
8.本发明提供的融合注意力机制和片段排列的实体关系联合抽取方法,还可以具有这样的技术特征,其中,步骤s6所述保留前列片段的个数计算公式如下:n=λn,式中,n为所述候选片段的总数量,λ为保留因子的阈值。
9.本发明提供的融合注意力机制和片段排列的实体关系联合抽取方法,还可以具有这样的技术特征,其中,步骤s7所述实体分类器和步骤s8所述关系分类器均为深度神经网络。
10.发明作用与效果
11.根据本发明的融合注意力机制和片段排列的实体关系联合抽取方法,将输入的文本转化为词向量,并基于片段排列的方式枚举所有可能的候选片段,通过将所有的候选片段输入到注意力机制的神经网络模型,根据注意力得分进行剪枝,来减少实体负样本的数量,从而进行命名实体识别和关系抽取。本发明基于片段排列的方式,能够枚举所有可能的片段,选择的每一个片段都是独立的,可以直接提取片段级别的特征去解决重叠实体问题。针对实体负样本数量过多的问题,本发明还加入了注意力机制,根据注意力的得分,可以有效地删除部分负样本以提高实体关系联合抽取的性能。
附图说明
12.图1是本发明实施例中融合注意力机制和片段排列的实体关系联合抽取方法的示意流程图;
13.图2是本发明实施例融合注意力机制和片段排列的实体关系联合抽取方法的原理示意图。
具体实施方式
14.为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的融合注意力机制和片段排列的实体关系联合抽取方法作具体阐述。
15.《实施例》
16.图1是本发明实施例中融合注意力机制和片段排列的实体关系联合抽取方法的示意流程图;
17.图2是本发明实施例的示意图。
18.如图1所示,融合注意力机制和片段排列的实体关系联合抽取方法,主要包括如下步骤:
19.步骤s1,输入文本句子并对所述文本句子进行标记解析;
20.本实施例中,以文本句子:joe biden is the president of the united states.为例,将将文本句子解析成自然语言处理最基本的单元,如图2所示;具体地,将文本句子“joe biden is the president of the united states.”分割成
‘
joe’、
‘
biden’、、
‘
is’、
‘
the’、
‘
president’、
‘
of’、
‘
the’、
‘
united’、
‘
states’、
‘
.’等自然语言处理最基本的单元。
21.步骤s2,基于所述标记解析,利用预训练语言模型进行编码,从而获得所述输入文本的词向量;
22.本实施例中,将标记输入预训练语言模型,获得每个标记的词向量,如图2所示;具体地,将标记解析后的标记:
‘
joe’、
‘
biden’、
‘
is’、
‘
the’、
‘
president’、
‘
of’、
‘
the’、
‘
united’、
‘
states’和
‘
.’输入到预训练语言模型获得每个标记的词向量。
23.步骤s3,基于所述词向量,利用片段排列的方式枚举所有的候选片段;
24.本实施例中,枚举所有候选片段包括以下步骤:设置最长的片段长度l
max
=8;若l=1,枚举所有片段长度等于l的片段;若l《l
max
,则l=l 1,枚举所有片段长度等于l的片段。具体地,如图2所示,片段长度l=1的片段:
‘
joe’、
‘
biden’、
‘
is’、
‘
the’、
‘
president’、
‘
of’、
‘
the’、
‘
united’、
‘
states’和
‘
.’;此外因为l《8,所以l=1 1=2,片段长度l=2的片段:
‘
joe biden’、
‘
biden is’、
‘
is the’、
‘
the president’、
‘
president of’、
‘
ofthe’、
‘
the united’、
‘
united states’和
‘
states.’;因为l《8,所以l=2 1=3,片段长度l=3的片段:
‘
joe biden is’、
‘
biden is the’、
‘
is the president’、
‘
the president of’、
‘
president of the’、
‘
of the united’、
‘
the united states’和
‘
united states.’;
……
;因为l《8,所以l=7 1=8,片段长度l=8的片段:
‘
joe biden is the president of the united’、
‘
biden is the president of the united states’和
‘
is the president of the united states.’。
25.步骤s4,将所述候选片段输入注意力机制的神经网络模型,并获取所述各个候选片段的注意力得分;
26.步骤s5,基于所述注意力得分,将所述候选片段排成有序队列;
27.步骤s6,保留所述有序队列的前列候选片段,并删除剩余所述候选片段;
28.本实施例中,具体步骤如下:首先设置保留因子的阈值λ=0.05,其次将所有的候选片段输入到注意力机制的神经网络模型,获取每个候选片段si的注意力得分αi,其中注意力机制的神经网络模型采用输出为一元的一层线性网络,每个候选片段si的注意力得分αi为线性网络的一元值;接着根据注意力得分α从大到小,将候选片段排成有序队列;最后将候选片段有序队列前n=λn个片段保留下来,有序队列后面的候选片段则删掉,保留下来的候选片段的数量为n=0.05
×
n,其中n为所有剪枝前所有候选片段的总数量。
29.步骤s7,将所述保留下来的候选片段输入实体分类器进行实体类型的预测,并获得预测为真的实体片段;
30.本实施例中,所述实体分类器是一层深度神经网络通过神经网络来预测候选片段的实体类型,如图2所示,具体地,实体表示一共包括三部分:片段的首、尾词向量和片段的长度嵌入,将实体表示输入到实体分类器,得到实体类型的logits得分向量,经过softmax操作后即可得到实体的预测类型;
31.步骤s8,将所述预测为真的实体片段两两匹配,获得每对所述实体片段的关系表示,并将所述关系表示输入关系分类器进行预测,从而获得每对所述实体片段之间的关系类型;
32.本实施例中,将实体分类器预测为真的实体片段进行两两配对,然后将每对实体
片段的特征作为这两个实体之间的关系表示,并将关系表示输入到关系分类器中来预测它们的关系类型;其中,关系分类器是一层深度神经网络,通过神经网络来预测每对实体之间的的关系类型,如图2所示,具体地,首先将所有预测为真的实体进行两两配对,两个实体之间的关系表示包括四个部分:头实体的首、尾词向量和尾实体的首、尾词向量,一共包括四个词向量;接着将关系表示输入到关系分类器,得到关系类型的logits得分向量,最后经过softmax操作后即可得到关系的预测类型。
33.实施例作用与效果
34.根据本发明的融合注意力机制和片段排列的实体关系联合抽取方法,将输入的文本转化为词向量,并基于片段排列的方式枚举所有可能的候选片段,通过将所有的候选片段输入到注意力机制的神经网络模型,根据注意力得分进行剪枝,来减少实体负样本的数量,从而进行命名实体识别和关系抽取。本发明基于片段排列的方式,能够枚举所有可能的片段,选择的每一个片段都是独立的,可以直接提取片段级别的特征去解决重叠实体问题。针对实体负样本数量过多的问题,本发明还加入了注意力机制,根据注意力的得分,可以有效地删除部分负样本以提高实体关系联合抽取的性能。
35.上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。