1.本发明涉及自然语言处理技术领域,具体涉及一种基于深度学习的多特征中文实体关系抽取方法。
背景技术:
2.关系抽取是在命名实体识别的基础上将文本中实体之间存在的关系提取出来,构成《实体1,关系,实体2》这种三元组形式。
3.早期关系抽取基于规则模式到后来基于机器学习,基于机器学习的关系抽取又可分为有监督的、半监督的、无监督的、面向开放领域的、远程监督的实体关系抽取。目前深度学习的兴起加上自然语言处理技术和大数据技术的发展,关系抽取迎来显著的改善。目前关系抽取主要应用在知识图谱的构建,自动问答系统和海量文本文献的翻译等领域。
4.然而关系抽取至今面临许多挑战,那就是实际情况中文本的描述远比测试的简单例句复杂的多:比如实体之间关系的多重性,模糊性。同时人工标注的测试语料十分有限,而神经网络模型又需要接近于现实中成千上万的关系实体三元组。最后就是现有的神经网络模型在中文语料的表现不如英文语料,这是中文语法与英文的不同带来的难点。
技术实现要素:
5.为克服上述技术缺点,本发明提供了一种基于深度学习的多特征中文实体关系抽取方法。
6.本发明的技术方案如下:
7.一种基于深度学习的多特征中文实体关系抽取方法,首先使用bert模型学习字符向量,字符向量拼接词性标签和字符信息位置信息作为词嵌入向量。然后词嵌入得到的向量输入本发明的多特征循环卷积网络。最后输入池化层,经由softmax函数输出概率。
8.包容如下步骤:
9.步骤1:多特征中文词嵌入:使用bert模型学习字符向量,字符位置向量和词性标签拼接作为词嵌入向量。
10.步骤1.1:使用bert的tokenizer分词器对文本进行切分操作,每个句子以cls开头,以“sep”为结尾的结构转换为token序列p={cls,c1,c2,
…
,c
n-1
,c
n-1
,sep},将token向量与位置向量,分句向量进行求和输入bert。
11.步骤1.2:定义输入的句子为系列形式:w=[w1,w2,
…
,w
l
]。经过bert编码输出最终序列e=[e0,e1,
…
,en,e
n 1
]∈r
(n 2)
*d
t
。
[0012]
步骤1.3:中文包含丰富的语义特征,为了解决分词歧义,加入postag标签添加实体的词性。
[0013]
步骤1.4:对于一句中文而言,每一个字对应的位置不同,采用独热方式提取边界特征向量。
[0014]
步骤2:上述向量拼接作为bi-gru的输入。
[0015]
步骤2.1:gru有一个当前输入x
t
和上一个节点传递来的隐状h
t-1
,。结合x
t
和h
t-1
,gru得到隐藏节点的输出y
t
和下一个节点的隐藏状态h
t
。这样就可以获得两个门控状态,r为重置门,z为更新门。
[0016]rt
=σ(wr*[h
t-1
,x
t
])
ꢀꢀꢀ
(1)
[0017]zt
=σ(wz*[h
t-1
,x
t
])
ꢀꢀꢀ
(2)
[0018]
得到门控信息,使用重置结果r
t
*h
t-1
与x
t
拼接
[0019][0020]
更新阶段,同时进行遗忘和记忆过程
[0021]ht
=(1-z
t
)*h
t-1
z
t
*h
t
ꢀꢀꢀ
(4)
[0022]
最后将结果进行输出或者传递给下一个细胞
[0023]yt
=σ(wo*h
t
)
ꢀꢀꢀ
(5)
[0024]
步骤2.2:将步骤1得到的向量表示为e
l
。
[0025]
步骤2.3:使用bi-gru来得到每个单词的上下文表示。
[0026]
步骤2.4:本发明定义w
l
的左侧内容为c
l
,右侧为cr。以下为w
l
的左和右上下文表示:
[0027]cl
(w
l
)=f(w
(l)cl
(w
l-1
) w
(sl)
e(w
l-1
)
ꢀꢀꢀ
(6)
[0028]cr
(w
l
)=f(w
(r)cr
(w
l 1
) w
(sr)
e(w
l 1
)
ꢀꢀꢀ
(7)
[0029]w(l)
,w
(r)
将隐藏层(上下文)转换为下一个隐藏层的矩阵.w
(sl)
,w
(sr)
是用于将当前单词的语意与下一个单词的左侧或右侧上下文相结合的矩阵。fi是一个非线性激活函数。
[0030]
步骤2.5:上述公式(6),公式(7)得到的向量做如下公式(8)的处理:
[0031]wl
=[(c
l
)
t
,(e
l
)
t
,(cr)
t
]
t
ꢀꢀꢀ
(8)
[0032]
步骤2.6:循环结构对文本进行前向和后向扫描,得到文本表示后,应用一个线性变换和细活函数y
i(1)
[0033]yi(1)
=tanh(w
(1)wl
b)
ꢀꢀꢀ
(9)
[0034]
步骤3:采用双向循环记忆网络提取上下文的细节。将步骤一结束所得的向量作为bi-lstm的输入,其输出记作y
i(2)
。作为字符级特征。
[0035]
步骤4:步骤2捕获了上下文语义,最后串联左右上下文向量和单词嵌入向量,这样的模型比传统使用固定窗口能更好的消除歧义,作为卷积层输出句子级特征。
[0036]
步骤4.1:计算汉字的所有表示时,本发明应用max-pooling层。输入循环卷积输出和双向记忆网络的向量。
[0037]yi(3)
=max(y
i(1)
y
i(2)
)
ꢀꢀꢀ
(10)
[0038]
步骤4.2:最后将softmax函数应用于y
i(3)
,它可以将输出的数字转换成概率
[0039]
。
[0040]
本发明的有益效果如下:本发明提供了一种基于深度学习的多特征中文实体关系抽取方法,本发明的多特征循环卷积网络包含lstm、gru、cnn层能够提取单词级特征和字符级特征,适用于多种种中文文本的关系抽取,有效解决了现有关系抽取效果不理想的技术问题。
附图说明
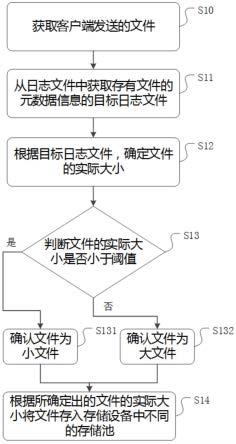
[0041]
图1是本发明的流程示意图;
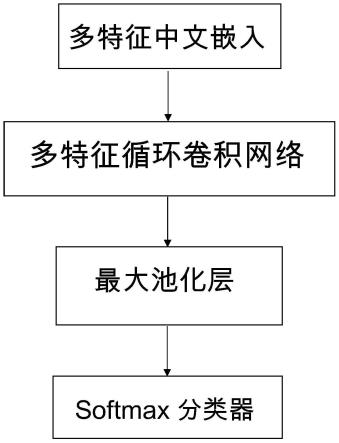
[0042]
图2是本发明的中文嵌入流程图;
[0043]
图3是本发明的多特征循环卷积网络工作流程示意图。
具体实施方式
[0044]
为使本发明实施例的目的、技术方案和优点更加清楚,下面结合附图和具体实施例,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例是本发明一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0045]
一种基于深度学习多特征中文关系抽取的方法,如图1所示,包括多特征中文嵌入,循环卷积网络,最大池化层,softmax分类器。
[0046]
具体步骤如下:
[0047]
步骤1:多特征中文词嵌入:使用bert模型学习字符向量,字符位置向量和词性标签拼接作为词嵌入向量。如图2所示。
[0048]
步骤1-1:使用bert的tokenizer分词器对文本进行切分操作,每个句子以“cls”开头,以“sep”为结尾的结构转换为token序列p={“cls”,c1,c2,
…
,c
n-1
,c
n-1
,“sep”},将token向量与位置向量,分句向量进行求和输入bert。
[0049]
步骤1-2:定义输入的句子为系列形式:w=[w1,w2,
…
,w
l
]。经过bert编码输出最终序列e=[e0,e1,
…
,en,e
n 1
]∈r
(n 2)
*d
t
。
[0050]
步骤1-3:中文包含丰富的语义特征,为了解决分词歧义,加入postag标签添加实体的词性。
[0051]
步骤1-4:对于一句中文而言,每一个字对应的位置不同,采用独热方式提取边界特征向量。
[0052]
步骤2:上述向量拼接作为bi-gru的输入。
[0053]
gru的输入输出与传统循环神经网络是一致的,有一个当前输入x
t
和上一个节点传递来的隐状h
t-1
,这个隐藏状态包含了之前节点的相关信息。结合x
t
和h
t-1
,gru得到隐藏节点的输出y
t
和下一个节点的隐藏状态h
t
。这样就可以获得两个门控状态,r为重置门,z为更新门。
[0054]rt
=σ(wr*[h
t-1
,x
t
])
ꢀꢀꢀ
(1)
[0055]zt
=σ(wz*[h
t-1
,x
t
])
ꢀꢀꢀ
(2)
[0056]
得到门控信息,使用重置结果r
t
*h
t-1
与x
t
拼接
[0057][0058]
更新阶段,同时进行遗忘和记忆过程
[0059]ht
=(1-z
t
)*h
t-1
z
t
*h
t
ꢀꢀꢀ
(4)
[0060]
最后将结果进行输出或者传递给下一个细胞
[0061]yt
=σ(wo*h
t
)
ꢀꢀꢀ
(5)
[0062]
步骤2-1:将步骤1得到的向量表示为e
l
。
[0063]
步骤2-2:使用bi-gru来得到每个单词的上下文表示。如图3所示
[0064]
步骤2-3:本发明定义w
l
的左侧内容为c
l
,右侧为cr。以下为w
l
的左和右上下文表示:
[0065]cl
(w
l
)=f(w
(l)cl
(w
l-1
) w
(sl)
e(w
l-1
)
ꢀꢀꢀ
(6)
[0066]cr
(w
l
)=f(w
(r)cr
(w
l 1
) w
(sr)
e(w
l 1
)
ꢀꢀꢀ
(7)
[0067]w(l)
,w
(r)
将隐藏层(上下文)转换为下一个隐藏层的矩阵.w
(sl)
,w
(sr)
是用于将当前单词的语意与下一个单词的左侧或右侧上下文相结合的矩阵。fi是一个非线性激活函数。
[0068]
步骤2-4:上述公式(6),公式(7)得到的向量做如下公式(8)的处理:
[0069]wl
=[(c
l
)
t
,(e
l
)
t
,(cr)
t
]
t
ꢀꢀꢀ
(8)
[0070]
步骤2-5:循环结构对文本进行前向和后向扫描,得到文本表示后,应用一个线性变换和细活函数y
i(1)
[0071]yi(1)
=tanh(w
(1)wl
b)
ꢀꢀꢀ
(9)
[0072]
步骤3:采用双向记忆网络提取能更好的提取上下文的细节,因为其结构更为复杂且拥有记忆门。将步骤一结束所得的向量作为bi-lstm的输入,其输出记作y
i(2)
。作为字符级特征。
[0073]
步骤4:步骤2捕获了上下文语义,最后串联左右上下文向量和单词嵌入向量,这样的模型比传统使用固定窗口能更好的消除歧义,作为卷积层输出句子级特征。
[0074]
步骤4-1:计算汉字的所有表示时,本发明应用max-pooling层。输入循环卷积输出和双向记忆网络的向量之和。
[0075]yi(3)
=max(y
i(1)
y
i(2)
)
ꢀꢀꢀ
(10)
[0076]
步骤4-2:最后将softmax函数应用于y
i(3)
,它可以将输出的数字转换成概率
[0077][0078]
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。