1.本发明涉及一种信息处理装置及信息处理方法,尤其涉及一种用来使学习模型机械学习的技术。
背景技术:
2.在教导式机械学习中,使用包含教导样本(标本)与教导标签的教导数据集,以将教导样本与标签的关系反映到学习模型的方式,使学习模型机械学习。通过将利用此种机械学习获得的学习完成模型应用到推理阶段中未附设标签的未知样本,例如获得图像识别、分类等期望的处理结果。
3.如果将使用某教导数据集学习的学习完成模型直接应用到以与所述教导数据集不同域的数据集为对象的任务中,那么会导致推理的精度降低。此处,域意指数据集中的数据的种类、范围、分布等。
4.因此,有一种技术,通过使用与作为对象的数据集同一域的目标域的样本,使学习完成模型进一步机械学习,能将学习完成模型应用到目标域,这被称为转移学习(transfer learning)。
5.所述转移学习的1种具有域适应(domain adaptation)。在所述域适应中,以样本的分布在教导数据集的域、与作为对象的数据集的域中不同为前提,以使应用源也就是教导数据集的域(源域)的分布与应用目标也就是对象数据集的域(目标域)的分布接近的方式,使学习模型学习。
6.专利文献1揭示有一种将相机拍摄的车辆图像分类的任务中的域适应化手法。
7.具体来说,在专利文献1的标签系统中,将表示利用相同相机取得的图像的标签化特征矢量作为对象域训练集,且作为利用其它多个相机分别取得的多个源域训练集使用,以学习域间的差异的方式,训练提升分类器。由此,利用早期导入的相机或设置于其它位置的相机所收集的图像,将车辆图像分类。
8.[现有技术文献]
[0009]
[专利文献]
[0010]
[专利文献1]日本专利特开2016-58079号公报
技术实现要素:
[0011]
[发明所要解决的问题]
[0012]
然而,在域适应中,标签附设于源域所含的教导样本,但标签未必附设于目标域所含的对象数据的样本。标签未附设于目标域的样本时的域适应也称为非教导式域适应。
[0013]
设想在任意情况下,在域适应中,目标域都包含与附设在属于源域的样本的所有标签对应的样本。
[0014]
然而,作为目标域的样本,未必能始终准备与源域的所有标签对应的样本。如此,目标域如果缺少与附设在属于源域的样本的一部分标签对应的样本,那么在专利文献1的
技术中,在使源域对目标域进行域适应时,无法使源域的样本分布与目标域的样本分布充分接近。
[0015]
因此,担心相对于学习完成模型的域适应的精度降低、或使用所述学习完成模型推理的各种处理的精度也降低。
[0016]
本发明为解决所述课题而完成,目的在于提供一种即使目标域的样本与源域的样本未充分对应时,仍能获得高精度处理结果的信息处理装置、信息处理方法及程序。
[0017]
[解决问题的技术手段]
[0018]
为解决所述课题,本发明的信息处理装置的一形态具备:特征抽取部,从源域所含的第1类样本及第2类样本、与目标域所含的所述第1类样本分别抽取特征;疑似样本产生部,基于利用所述特征抽取部抽取的所述特征的特征空间中所述目标域所含的所述第1类样本的分布,产生所述目标域的所述第2类疑似样本;及数据转换部,以使所述特征空间中所述源域所含的所述第1类样本及所述第2类样本的分布,与所述目标域所含的所述第1类样本及所述第2类所述疑似样本的分布接近的方式,通过机械学习进行数据转换。
[0019]
所述疑似样本产生部可推测所述特征空间中所述目标域所含的所述第1类样本的分布的第1可靠度,且基于推测的所述第1可靠度的梯度,产生所述疑似样本。
[0020]
所述疑似样本产生部可在推测的所述第1可靠度较低的所述特征空间的区域,产生所述疑似样本。
[0021]
所述疑似样本产生部可推测所述特征空间中所述源域所含的所述第2类样本的分布的第2可靠度,且基于推测的所述第2可靠度的梯度,产生所述疑似样本。
[0022]
所述疑似样本产生部可将所述第1可靠度与所述第2可靠度结合,且基于结合的可靠度,以使产生的所述疑似样本分布于所述特征空间中所述结合的可靠度更高的区域的方式重取样。
[0023]
所述疑似样本产生部可基于所述特征空间中所述源域所含的所述第1类样本的分布与所述第2类样本的分布之间的距离,产生所述疑似样本。
[0024]
可进而具备:域分类器,将样本分类为所述源域及所述目标域中任一个;且所述疑似样本产生部以所述域分类器对分类到所述目标域的样本,赋予比分类到所述源域的样本更高权重的方式,使所述域分类器学习。
[0025]
可进而具备:类分类器,将样本分类为所述第1类及所述第2类中任一个;且所述疑似样本产生部以所述类分类器对分类到所述第2类的样本,赋予比分类到所述第1类的样本更高权重的方式,使所述类分类器学习。
[0026]
所述数据转换部可以使所述域分类器及所述类分类器中至少1个使用第1损失函数算出的所述特征空间中的交叉熵损失变得更小的方式机械学习。
[0027]
所述数据转换部可以使使用第2损失函数算出的所述特征空间中所述源域与所述目标域之间的wasserstein(瓦瑟斯坦)距离变得更小的方式机械学习。
[0028]
本发明的信息处理方法的一形态为信息处理装置执行的信息处理方法,且包含如下步骤:从源域所含的第1类样本及第2类样本、与目标域所含的所述第1类样本分别抽取特征;基于抽取的所述特征的特征空间中所述目标域所含的所述第1类样本的分布,产生所述目标域的所述第2类疑似样本;及以使所述特征空间中所述源域所含的所述第1类样本及所述第2类样本的分布,与所述目标域所含的所述第1类样本及所述第2类所述疑似样本的分
布接近的方式,通过机械学习进行数据转换。
[0029]
本发明的信息处理程序的一形态为,储存于计算机可读存储介质中,用来使计算机执行信息处理,且所述程序用来使所述计算机执行的处理包含:特征抽取处理,从源域所含的第1类样本及第2类样本、与目标域所含的所述第1类样本分别抽取特征;疑似样本产生处理,基于利用所述特征抽取处理抽取的所述特征的特征空间中所述目标域所含的所述第1类样本的分布,产生所述目标域的所述第2类疑似样本;及数据转换处理,以使所述特征空间中所述源域所含的所述第1类样本及所述第2类样本的分布,与所述目标域所含的所述第1类样本及所述第2类所述疑似样本的分布接近的方式,通过机械学习进行数据转换。
[0030]
[发明的效果]
[0031]
根据本发明,即使在目标域的样本未与源域的样本充分对应的情况下,仍能获得高精度的处理结果。
[0032]
熟知本技术的人通过参照附图及权利要求书的记载,应能从下述用来实施发明的方式中,理解所述本发明的目的、形态及效果以及上文未描述的本发明的目的、形态及效果。
附图说明
[0033]
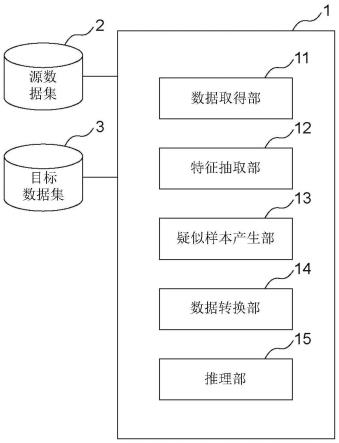
图1是表示本发明的实施方式的学习装置的功能构成的一例的框图。
[0034]
图2(a)、(b)是说明本实施方式的源域与目标域的样本分布的非对称性(域移位)的图。
[0035]
图3(a)、(b)是说明经过本实施方式的学习装置执行的疑似样本产生处理进行域适应后的源域与目标域的图。
[0036]
图4是表示将本实施方式的学习装置安装于机械学习时的学习模型的模组构成及概略处理顺序的一例的概念图。
[0037]
图5是表示本实施方式的学习装置的疑似样本产生部执行的疑似样本产生处理的详细处理顺序的一例的流程图。
[0038]
图6(a)~(c)是说明特征空间上根据目标域及源域的样本产生目标域的疑似样本的顺序的一例的示意图。
[0039]
图7(a)~(c)是说明特征空间上根据目标域及源域的样本产生目标域的疑似样本的顺序的另一例的示意图。
[0040]
图8是表示本实施方式的学习装置的硬件构成的一例的框图。
具体实施方式
[0041]
以下,参照附图详细说明用来实施本发明的实施方式。以下揭示的构成要素中,对具有同一功能的构成要素附注同一符号,省略它的说明。另外,以下揭示的实施方式为本发明的实现办法的一例,应该通过应用本发明的装置的构成或各种条件来适当修正或变更,本发明并非限定于以下实施方式。此外,本实施方式所说明的特征的全部组合未必为本发明的解决办法所必须。
[0042]
本实施方式的学习装置分别抽取源域的样本及目标域的样本的特征,将赋予到源域的样本的多个标签(类)中未充分包含于目标域的标签(类)的样本作为疑似样本,产生于
特征空间中目标域的区域,以产生的疑似样本补充目标域的样本。
[0043]
本实施方式的学习装置又以源域域适应到补充疑似样本的目标域的方式机械学习。
[0044]
以下,说明本实施方式例如应用于识别及分类图像的用途的一例,但本实施方式未限定于此,根据必须应用学习模型的应用,能应用于所有种类的数据或域。
[0045]
《学习装置的功能构成》
[0046]
图1是表示本实施方式的学习装置1的功能构成的一例的框图。
[0047]
图1所示的学习装置1具备数据取得部11、特征抽取部12、疑似样本产生部13、数据转换部14、及推理部15。
[0048]
学习装置1可与由pc(personal computer:个人计算机)等构成的客户端装置(未图示)经由网络能通信地连接。此时,学习出装置1安装于服务器,客户端装置可提供学习装置1与外部执行信息的输入输出时的用户界面,此外,也可具备学习装置1的各组件11~15的一部分或全部。
[0049]
数据取得部11分别从源数据集2取得源域的样本,从目标数据集3取得目标域的样本,且向特征抽取部12供给取得的源域的样本及目标域的样本。
[0050]
源数据集2由hdd(hard disk drive:硬盘驱动器)、ssd(solid state drive:固态驱动器)等非易失性存储装置构成,储存属于域适应源的源域的样本(标本)。将属于源域的样本称为源样本。源样本是用来使学习模型事先学习的教导数据,各源样本附设表示分类上正解的类的标签。
[0051]
目标数据集3与源数据集2同样,由hdd、ssd等非易失性存储装置构成,储存属于域适应目标的目标域的样本。将属于目标域的样本称为目标样本。目标样本是与必须应用学习模型的任务作为处理对象的数据属于同一域的样本,各目标样本可附设类的标签,也可不按类附设标签。
[0052]
另外,域意指根据某1个概率分布产生的数据的所属区域,例如,根据数据种类、范围、分布等属性构成域。
[0053]
数据取得部11通过读取预先储存于源数据集2及目标数据集3的源样本及目标样本,可取得源样本及目标样本,或,也可从存储源样本及目标样本的同一或不同的对向装置经由通信i/f接收。
[0054]
数据取得部11还受理在学习装置1中执行域适应的机械学习处理所需的各种参数的输入。数据取得部11可经由与学习装置1能通信地连接的客户端装置的用户界面,受理各种参数的输入。
[0055]
特征抽取部12从数据取得部11所供给的源样本,抽取各源样本的特征。
[0056]
特征抽取部12又从数据取得部11所供给的目标样本,抽取各目标样本的特征。
[0057]
特征抽取部12向疑似样本产生部13供给抽取的源样本的特征及目标样本的特征。
[0058]
疑似样本产生部13基于从特征抽取部12供给的源样本的特征及目标样本的特征,将目标域的目标样本中未出现或不足的类的目标样本作为疑似样本产生。
[0059]
在本实施方式中,疑似样本产生部13将从特征抽取部12供给的源样本的特征及目标样本的特征映射在特征空间上,推测特征空间上的目标样本的分布的可靠度,且基于推测的可靠度产生疑似样本,由此补充目标域的目标样本。疑似样本产生部13可进一步推测
特征空间上的源样本的分布的可靠度,且基于推测的可靠度产生疑似样本。
[0060]
疑似样本产生部13执行的疑似样本产生处理的细节参照图5予以后述。
[0061]
数据转换部14以使特征抽取部12所供给的源域的源样本的特征的分布与目标域的目标样本的特征的分布一致的方式执行数据转换。也就是说,数据转换部14以源样本的特征及目标样本的特征作为输入,执行将学习模型应该学习的教导数据,从源域的数据转换为目标域的数据的域适应。
[0062]
在本实施方式中,数据转换部14以利用疑似样本产生部13产生的疑似样本补充目标域,且将补充疑似样本的目标域的目标样本的特征作为输入,执行从源域向目标域的域适应。
[0063]
数据转换部14使用转换的教导数据(学习数据),对学习模型中域适应的函数的参数值进行机械学习。
[0064]
推理部15通过利用数据转换部14应用域适应的学习完成的学习模型,相对于输入数据,输出各种处理结果。
[0065]
如此机械学习的学习完成的学习模型因为在目标域中,以作为疑似样本产生的目标样本补充未出现类的目标样本,所以有效防止各种推理处理中的精度降低。
[0066]
《域适应与疑似样本产生》
[0067]
图2是说明本实施方式的源域与目标域的样本分布的非对称性(域移位)的图。
[0068]
图2(a)表示属于源域的域样本的特征值ps(x)的分布、与属于目标域的目标样本的特征值p
t
(x)的分布。如图2(a)所示,目标样本的特征值的分布与源样本的特征值的分布不一致,相对于源样本的特征值的分布,沿正向协变量(covariate)移位(ps(x)≠p
t
(x))。
[0069]
图2(b)表示属于源域的源样本的按照类的分布(ps(y))、与属于目标域的目标样本的按照类的分布(p
t
(y))。在图2(b)中,源域及目标域都具有2个类(-1、 1)。
[0070]
如图2(b)所示,在源域中,附设标签为类(-1)的源样本数与附设标签为类( 1)的源样本数为大致同数。另一方面,在目标域中,附设标签为类(-1)的目标样本数与类(-1)的源样本数大致同数,与此相对,附设标签为类( 1)的目标样本数显著低于类( 1)的源样本数,目标域在类分布中也发生移位(ps(y= 1)≠p
t
(y= 1))。
[0071]
作为非限定的一例,考虑为获得源域是图解图像,目标域是写实图像,将输入图像分类为犬图像与猫图像中任一个类的学习模型,而对学习模型应用域适应的情况。
[0072]
源域的源样本包含描绘犬的犬图解图像(ps(y=-1))、与描绘猫的猫图解图像(ps(y= 1))这两个图像,各源样本附设犬类(-1)与猫类( 1)中任一个的标签。
[0073]
另一方面,目标域的目标样本如图2(b)所示,几乎全为拍摄犬的犬写实图像(p
t
(y=-1)),而完全没有或仅准备少量拍摄猫的猫写实图像(p
t
(y= 1))。
[0074]
在实际使用学习模型的推理阶段,也就是将输入图像分类的任务阶段中,设想除犬的写实图像外,也输入猫的写实图像,所以要求高精度地区分犬的写实图像与猫的写实图像。
[0075]
然而,如图2(b)所示,由于目标域中猫的写实图像(p
t
(y= 1))不足,所以即使对学习模型应用域适应,仍会使区分猫的写实图像与犬的写实图像并分类的精度降低。
[0076]
与此相对,本实施方式在使学习模型域适应时,将目标域中不足的猫的写实图像(p
t
(y= 1))作为疑似样本产生,且以产生的疑似样本补充目标域。
[0077]
图3是说明经过本实施方式的学习装置1执行的疑似样本产生处理进行域适应后的源域与目标域的图。
[0078]
图3(a)表示域适应后的属于源域的源样本的特征值(ps(x))的分布、与属于目标域的目标样本的特征值(p
t
(x))的分布。如图3(a)所示,目标样本的特征值的分布与源样本的特征值的分布大致一致(ps(x)≈p
t
(x))。
[0079]
图3(b)表示属于源域的源样本的类( 1)的分布(ps(y))、与属于目标域的目标样本群的类( 1)的分布(p
t
(y))。
[0080]
在域适应时,由于以产生的类( 1)相关的疑似样本补充目标域,所以如图3(b)所示,源域中附设类( 1)标签的源样本数、与目标域中附设类( 1)标签的目标样本数大致同数(ps(y= 1)≈p
t
(y= 1))。
[0081]
如图3(a)及图3(b)所示,根据本实施方式,除能消除在源域与目标域间可能产生的特征值分布的移位外,也能消除类间的移位。
[0082]
《机械学习用学习模型的模组构成》
[0083]
图4是表示将本实施方式的学习装置1安装于机械学习模型时的模组构成及概略处理顺序的一例的概念图。
[0084]
参照图4,学习装置1可由特征抽取模组121、122、编码模组141、疑似样本产生模组13、分类器模组142、及数据转换模组143构成。图4所示的各模组中,编码模组141、疑似样本产生模组13、分类器模组142、及数据转换模组143构成作为特征抽取模组121、122后段的域适应模组14。
[0085]
图4中,说明使将输入图像识别及分类的学习模型学习的例。
[0086]
另外,图4的各特征抽取模组121、122对应学习装置1的特征抽取部12,疑似样本产生模组13对应学习装置1的疑似样本产生部13,包含编码模组141、分类器模组142、及数据转换模组143的域应用模组14对应学习装置1的数据转换部14。
[0087]
特征抽取模组121将源域的源图像作为输入,从各源图像抽取特征,输出源图像的特征。
[0088]
特征抽取模组122将目标域的目标图像作为输入,从各目标图像抽取特征,且输出目标图像的特征。
[0089]
另外,在使学习模型学习时,可并行执行特征抽取模组121、122,也可先执行特征抽取模组121、122的任一个,之后依序执行另一个。
[0090]
抽取源图像及目标图像的图像特征的特征抽取模组121、122可由例如卷积神经网络(convolutional neural network:cnn)构成。
[0091]
特征抽取模组121、122可进一步对源图像及目标图像应用数据扩展(data augmentation)的算法,将图像中的解析对象的目标物(例如人)以适当比例尺定位于图像中央、或去除背景。
[0092]
特征抽取模组121、122也可进一步例如应用attention branch network(abn:注意力分支网络)等注意力机构,根据源图像及目标图像,产生图像中的注视区域的图(attention map)且最优化,并将抽取的图像特征加权。
[0093]
域适应模组14的编码模组141将特征抽取模组输出的源图像的特征及目标图像的特征在共通的特征空间中编码(encoding)。
[0094]
此处,源域包含正(positive)类的特征矢量z
s
、与负(negative)类的特征矢量z
s-两种两种另一方面,目标域仅包含负类的特征矢量也就是说,正类为目标域中未出现(未观测)的类。输入到编码模组141的所述特征矢量为d维特征矢量。
[0095]
编码模组141可学习域不变(domain invariant)的特征空间的参数,例如安装于作为能学习的映射函数g的全结合层(fully connected layer)。
[0096]
编码模组141输出编码的特征矢量^z
s-、^z
s
、^z
t-。所述编码特征矢量设为m维(m<d)的特征矢量
[0097]
疑似样本产生模组13将映射于共通特征空间的编码的特征矢量^z
s-、^z
s
、^z
t-作为输入,产生目标域中未出现的也就是正(positive)类的疑似样本,且将产生的正类的疑似样本看作正类的特征矢量^z
t
,并补充目标域的样本。
[0098]
另外,图4中,疑似样本产生模组13在编码模组141对特征矢量进行编码后执行疑似样本产生处理,但也可在编码模组141对特征矢量进行编码前执行疑似样本产生处理来取而代之。
[0099]
疑似样本产生模组的疑似样本产生处理的细节,参照图5进行后述。
[0100]
s5中,域适应模组的分类器模组142(discriminator)将编码的特征矢量^z分类s5中,域适应模组的分类器模组142(discriminator)将编码的特征矢量^z分类
[0101]
分类器模组142可具备:域分类器(c_d),将输入的编码特征矢量分类到源域及目标域中任一个域;及类分类器(c_c),将输入的编码特征矢量分类到正类及负类中任一个类。
[0102]
分类器模组142可例如安装于作为能学习的映射函数c的全结合层(fully connected layer),通过将映射为来执行分类。在所述域分类器及类分类器中,c=2。
[0103]
分类器模组142例如通过以使用用来令以下的式1所示的损失最小化的损失函数lc,使域间或类间的二元交叉熵(binary cross entropy)损失变得更小的方式机械学习,能维持分类性能。
[0104]
[数1]
[0105][0106]
此处,
[0107]
[数2]
[0108][0109]
表示第i个源样本的二元标签;
[0110]
[数3]
[0111][0112]
是指标函数。另外,分类器模组也可在所述式1中,算出平方误差等其它损失来替代二元交叉熵损失。
[0113]
域适应模组14的数据转换模组143以源域与目标域之间的数据不一致(discrepancy)最小化的方式,将编码的特征矢量表现转换为实数也就是说,数据转换模组143是评估域适应的模组(domain critic:域判别器)。
[0114]
数据转换模组143可例如安装于作为能学习的转换函数f的全结合层。
[0115]
具体来说,数据转换模组143通过以将编码的源域的特征矢量^z
s-、^z
s
、与编码的目标域的特征矢量^z
t-及疑似样本也就是正类的特征矢量^z
t
作为输入,推测源域的编码特征矢量^z
s-、^z
s
与目标域的编码特征矢量^z
t-、^z
t
之间的共通的特征空间的距离,使所述距离最小化的方式机械学习,来使源域的编码特征矢量域适应到目标域的编码特征矢量。
[0116]
虽然所述距离可为例如作为距离空间上的概率分布间的距离的wasserstein距离,但数据转换模组143也可使用其它距离。
[0117]
数据转换模组143例如通过以使用用来令以下的式2所示的损失最小化的损失函数lw,使源域与目标域之间的样本分布间的距离的损失变得更小的方式执行机械学习,来执行域适应。
[0118]
[数4]
[0119][0120]
此处,ns表示源域中的正类及负类的样本数,n
t
表示目标域中正类及负类的样本数。
[0121]
在本实施方式中,由于利用疑似样本产生模组13产生的疑似正样本的编码特征矢量被追加到目标域,所以数据转换模组143能使用追加到目标域的疑似正样本的编码特征矢量,高精度地执行域适应。
[0122]
另外,在使学习模型机械学习时,可并行执行分类器模组142及数据转换模组143,也可先执行分类器模组142及数据转换模组143的任一个,之后依序执行另一个。分类器模组142的学习及数据转换模组143的学习可作为对抗学习而执行。
[0123]
使学习模型学习的域适应模组14以映射函数g、映射函数c、及转换函数f的各参数最优化,且所述损失函数的合计损失最小化的方式重复进行机械学习。由此,学习域不变的共通的特征空间的参数,且源域的特征空间中的正样本分布及负样本分布向目标域的特征空间中的正样本分布及负样本分布高精度地域适应。
[0124]
另外,图4所示的学习模型的模组构成为一例,本实施方式的学习装置1可使用其它特征抽取或域适应的手法。
[0125]
《疑似样本产生处理的详细处理顺序》
[0126]
图5是表示本实施方式的学习装置1的疑似样本产生部13执行的疑似样本产生处理的详细处理顺序的一例的流程图。
[0127]
另外,图5的各步骤通过cpu(central processing unit:中央处理单元)读取且执行学习装置1的hdd等的存储装置所存储的程序来实现。此外,也可利用硬件来实现图5所示的流程图的至少一部分。利用硬件来实现时,例如,只要通过使用特定的编译程序,根据用
来实现各步骤的程序在fpga(field programmable gate array:现场可编程门阵列)上自动产生专用电路即可。此外,也可与fpga同样形成gate array(门阵列)电路,作为硬件实现。此外,也可利用asic(application specific integrated circuit:专用集成电路)来实现。
[0128]
在s51中,学习装置1的疑似样本产生部13使将样本分类到源域及目标域中任一个域的域分类器事先学习。域分类器以对分类到目标域的样本,赋予比分类到源域的样本更高权重的方式训练。
[0129]
在s51中,疑似样本产生部13也可进一步使将样本分类到正(positive)类及负(negative)类中任一个类的类分类器事先学习。类分类器以对分类到正类的样本,赋予比分类到负类的样本更高权重的方式训练。
[0130]
在s52中,学习装置1的疑似样本产生部13根据特征空间上的目标域的负类样本的分布,推测目标域的负类样本的可靠度。
[0131]
具体来说,疑似样本产生部13推测特征空间上的目标域的负类样本的分布的平均矢量(mean vector)及协方差矩阵(covariance matrix),且将目标域的负类样本的分布所对的负类样本概率值(probability value)推测为目标域的负类样本的可靠度(confidence score)。此处,负类样本的分布可看作高斯(gaussian)分布(正态分布)。
[0132]
在s53中,学习装置1的疑似样本产生部13在特征空间上的目标域的区域产生疑似正类样本。
[0133]
如果s52中推测的特征空间上的目标域的负类样本的可靠度得分为p(d
t-|x
),那么特征空间上的目标域的疑似正类样本的可靠度可推测为以下的式3。
[0134]
p(d
t
|x
)=1-p(d
t-|x
)
ꢀꢀꢀꢀꢀꢀꢀ
(式3)
[0135]
具体来说,疑似样本产生部13基于目标域的负类样本的可靠度的特征空间上的梯度,在目标域的负类样本的可靠度较低的区域周围均一地产生目标域的疑似正类样本。
[0136]
疑似样本产生部13可在基于源域中正类样本及负类样本的类间距离的平均及标准偏差决定的目标域的区域,产生疑似正类样本。
[0137]
也就是说,源域中正类样本及负类样本的类间距离可看作与目标域中正类样本及负类样本的类间距离相等。因此,疑似样本产生部13可在从目标域的负类样本分布的区域隔开所述类间距离的量的区域,产生目标域的疑似正类样本。
[0138]
疑似样本产生部13又可将与源域的正类样本数同数的疑似正类样本产生到目标域的区域(n
t
=n
s
)。域分类器(c_d)将产生的疑似正类样本分类到目标域。
[0139]
在s54中,学习装置1的疑似样本产生部13推测特征空间上的源域的正类样本的分布的平均矢量及协方差矩阵,将源域的正类样本的分布所对的正类样本概率值推测为源域的正类样本的可靠度。此处,正类样本的分布也可看作高斯分布(正态分布)。疑似样本产生部13可与s53同样,基于源域的正类样本的可靠度的特征空间上的梯度,在源域的正类样本的可靠度较低的区域周围均一地产生目标域的疑似正类样本。
[0140]
类(内容)分类器(c_c)可使用源域的正类样本的可靠度p(d
s
|x
),更新疑似正类样本的可靠度。
[0141]
s55中,学习装置1的疑似样本产生部13使用在s51中学习的域分类器及类分类器,将目标域的负类样本的可靠度及源域的正类样本的可靠度结合,更新样本的权重。目标域
的负类样本的可靠度如式3所示,转换为目标域的正类样本的可靠度。
[0142]
此处,分类为正类(y= 1)的样本具有更高的权重。此外,如以下式4所示,推测源域的正样本的分布(d
s
)与目标域的正样本的分布(d
t
)附条件独立。
[0143]
p(d
s
,d
t
|x
)=p(d
s
|x
)p(d
t
|x
)
ꢀꢀꢀꢀ
(式4)
[0144]
s56中,学习装置1的疑似样本产生部13算出s55中被赋予更高权重的样本的参数分布,在特征空间上将目标域的疑似正类样本重取样。
[0145]
具体来说,疑似样本产生部13将可靠度作为权重,增大具有更高可靠度的疑似正类样本的区域中的样本数(up-sample),使具有更低可靠度的疑似正类样本的区域中的样本数减少(down-sample)。
[0146]
s57中,学习装置1的疑似样本产生部13重复s51~s56的处理直到达到特定收敛条件。
[0147]
作为收敛条件,可例如在绕过s54~s55的处理不使用源域的正类样本的信息时,通过重复特定次数图5所示的处理来看作收敛。
[0148]
或,也可在使用源域的正类样本的信息时,以重复次数设定收敛条件,但也可例如设定距离的阈值,将源域的正类样本与负类样本的分布之间的距离、与目标域的正类样本与负类样本的分布之间的距离收敛于特定阈值内的情况,设定为收敛条件。此外,也可使用样本可靠度之间的距离来取代样本分布之间的距离。此处,作为距离,例如可使用jensen-shannon(詹森-香农)散度。
[0149]
图6是说明特征空间上根据目标域及源域的样本产生目标域的疑似正类样本的顺序的一例的示意图。
[0150]
参照图6(a),在特征空间上,左侧表示源域的区域,右侧表示目标域的区域。垂直线61表示利用域分类器划定的特征空间上的源域与目标域的边界。
[0151]
源域的区域包含(-)所表示的负类样本的分布、与负类样本的分布上方( )所表示的正类样本的分布。另一方面,目标域的区域包含(-)所表示的负类样本的分布,但未出现正类样本的分布。
[0152]
参照图6(b),学习装置1的疑似样本产生部13在特征空间上的目标域的区域产生疑似正类样本。在边界61的右侧的目标域的区域中,(-)所表示的负类样本的分布表示目标域的负类样本的可靠度较高的区域。
[0153]
疑似样本产生部13判断越远离所述目标域的(-)所表示的负类样本的分布,是目标域的负类样本的可靠度越低的区域,因此,判断是目标域的疑似正类样本的可靠度越高的区域,在目标域的(-)所表示的负类样本的分布的周围均一地产生多个疑似正类样本的区域63~67(图5的s53)。
[0154]
参照图6(c),学习装置1的疑似样本产生部13在特征空间上的目标域的区域中,重取样疑似正类样本。水平线62表示利用类分类器划定的正类与负类的边界。
[0155]
疑似样本产生部13将图6(b)中产生于目标域的多个疑似正类样本的区域63~67中,相对于源域的( )所表示的正类样本的分布距离更近的区域63,判断为疑似正类样本的可靠度较高的区域,且赋予更高权重。
[0156]
另一方面,多个疑似正类样本的区域63~67中,相对于源域的( )所表示的正类样本的分布距离更远的区域64~67判断为疑似正类样本的可靠度较低的区域,赋予更低的权
重。此外,水平线62下的疑似正类样本的区域65~67由于利用类分类器判断为负类区域,因而可赋予比水平线62上的疑似正类样本的区域更低的权重,也可删除疑似正类样本。
[0157]
疑似样本产生部13只要最终在算出更高可靠度的疑似正类样本的区域63产生疑似正类样本即可。
[0158]
图7是说明特征空间上根据目标域及源域的样本产生目标域的疑似正类样本的顺序的另一例的示意图。
[0159]
参照图7(a),在特征空间上,左侧表示源域的区域,右侧表示目标域的区域。垂直线71表示利用域分类器划定的特征空间上的源域与目标域的边界。
[0160]
源域的区域包含(-)所表示的负类样本的分布、与负类样本的分布上方( )所表示的正类样本的分布。另一方面,目标域的区域包含(-)所表示的负类样本的分布,但未出现正类样本的分布。其中,与图6(a)不同,目标域的(-)所表示的负类样本的分布隔着边界71,与源域的(-)所表示的负类样本的分布相比,更邻近( )所表示的正类样本的分布。
[0161]
参照图7(b),学习装置1的疑似样本产生部13在特征空间上的目标域的区域产生疑似正类样本。在边界71的右侧的目标域的区域中,(-)所表示的负类样本的分布表示目标域的负类样本的可靠度较高的区域。
[0162]
疑似样本产生部13判断越远离所述目标域的(-)所表示的负类样本的分布,是目标域的负类样本的可靠度越低的区域,因此,判断是目标域的疑似正类样本的可靠度越高的区域,在目标域的(-)所表示的负类样本的分布的周围均一地产生多个疑似正类样本的区域73~77(图5的s53)。
[0163]
参照图7(c),学习装置1的疑似样本产生部13在特征空间上的目标域的区域中,重取样疑似正类样本。斜线72表示利用类分类器划定的正类与负类的边界。
[0164]
疑似样本产生部13将图7(b)中产生于目标域的多个疑似正类样本的区域73~77中,相对于源域的( )所表示的正类样本的分布距离更近的区域73,判断为疑似正类样本的可靠度较高的区域,且赋予更高权重。
[0165]
另一方面,多个疑似正类样本的区域73~77中,相对于源域的( )所表示的正类样本的分布距离更远的区域74~77判断为疑似正类样本的可靠度较低的区域,赋予更低的权重。此外,斜线72下的疑似正类样本的区域75~77由于利用类分类器判断为负类区域,因而可赋予比斜线72上的疑似正类样本的区域更低的权重,也可删除疑似正类样本。
[0166]
疑似样本产生部13只要最终在算出更高可靠度的疑似正类样本的区域73产生疑似正类样本即可。
[0167]
《学习装置的硬件构成》
[0168]
图8是表示本实施方式的学习装置1的硬件构成的非限定的一例的图。
[0169]
本实施方式的学习装置1也可安装于单一或多个所有计算机、移动设备、或其它任何处理平台上。
[0170]
参照图8,表示有学习装置1安装于单一计算机的例,但本实施方式的学习装置1可安装于包含多个计算机的计算机系统。多个计算机可通过有线或无线的网络能够相互通信地连接。
[0171]
如图8所示,学习装置1可具备cpu81、rom82、ram83、hdd84、输入部85、显示部86、通信i/f87、及系统总线88。学习装置1又可具备外部存储器。
[0172]
cpu(central processing unit)81统一控制学习装置1的动作,经由数据传送线路也就是系统总线88,控制各构成部(82~87)。
[0173]
学习装置1又可具备gpu(graphics processing unit:图形处理单元)。gpu具有比cpu81更高的计算功能,通过使多个或多数gpu并列动作,尤其对使用本实施方式这样的机械学习的图像处理等应用提供更高的处理性能。gpu通常包含处理器与共用存储器。各个处理器从高速的共用存储器取得数据,执行共通程序,由此大量且高速地执行同种计算处理。
[0174]
rom(read-only memory:只读存储器)82是存储cpu81执行处理所需的控制程序等的非易失性存储器。另外,所述程序也可存储于hdd(hard disk drive)84、ssd(solid state drive)等非易失性存储器或能装卸的存储介质(未图示)等外部存储器。
[0175]
ram(random access memory:随机存取存储器)83是易失性存储器,作为cpu81的主存储器、工作区等发挥功能。也就是说,cpu81通过在执行处理时从rom82将所需程序等载入ram83且执行所述程序等,来实现各种功能动作。
[0176]
hdd84例如存储cpu81进行使用程序的处理时所需的各种数据或各种信息等。此外,在hdd84中例如存储通过cpu81进行使用程序等的处理来获得的各种数据或各种信息等。
[0177]
输入部85由键盘或鼠标等指向设备构成。
[0178]
显示部86由液晶显示器(lcd:liquid crystal display)等监视器构成。显示部86可提供用来向参数调整装置1指示输入机械学习处理所使用的各种参数、或与其它装置通信所使用的通信参数等的用户界面也就是gui(graphical user interface:图形用户界面)。
[0179]
通信i/f87是控制学习装置1与外部装置的通信的界面。
[0180]
通信i/f87提供与网络的界面,经由网络,执行与外部装置的通信。经由通信i/f87,在与外部装置之间收发各种数据或各种参数等。在本实施方式中,通信i/f87可执行经由依据以太网(注册商标)等通信规格的有线lan(local area network:局域网)或专用线的通信。其中,本实施方式中能利用的网络不限定于此,也可由无线网络构成。所述无线网络包含bluetooth(蓝牙)(注册商标)、zigbee(紫蜂)(注册商标)、uwb(ultra wide band:超宽带)等无线pan(personal area network:个域网)。此外,包含wifi(wireless fidelity:无线保真)(注册商标)等无线lan(local area network)、或wimax(world interoperability for microwave access:全球微波接入互操作性)(注册商标)等无线man(metropolitan area network:城域网)。再者,包含lte(long term evolution:长期演进)/3g(3th generation mobile communication technology:第3代移动通信技术)、4g、5g等无线wan(wide area network:广域网)。另外,网络只要使各机器能够相互通信地连接且能够通信即可,通信的规格、规模、构成未限定于所述。
[0181]
图1所示的学习装置1的各要素中至少一部分的功能能通过cpu81执行程序来实现。其中,也可使图1所示的学习装置1的各要素中至少一部分的功能作为专用硬件来动作。此时,专用硬件基于cpu81的控制来动作。
[0182]
如以上说明,根据本实施方式,学习装置分别抽取源域的样本及目标域的样本的特征,将对源域的样本附设标签的多个类中未充分包含于目标域的类的样本,作为疑似样本,产生于特征空间中目标域的区域,以产生的疑似样本补充目标域的样本。
[0183]
本实施方式的学习装置又以源域域适应到补充疑似样本的目标域的方式机械学习。
[0184]
因此,即使源域的样本未与目标域的样本充分对应时,也能获得高精度的处理结果。
[0185]
例如,即使在检测影像中只以极低频率出现的异常场景(anomaly scene)的任务中,也通过在目标域产生应该过滤的异常场景的疑似样本,且以产生的疑似样本补充目标域,来消除源域及目标域的类间的非对称性。
[0186]
由此,高精度地实现域适应,有助于提高机械学习模型的可用性。
[0187]
另外,上文虽然说明了特定实施方式,但所述实施方式仅为例示,并无限定本发明的范围的意图。本说明书所记载的装置及方法可在所述以外的方式中具体化。此外,在不脱离本发明的范围的情况下,也可对所述实施方式适当进行省略、置换及变更。进行所述省略、置换及变更的方式包含在权利要求书所记载的发明及它的均等物的范围内,且属于本发明的技术范围。
[0188]
[符号的说明]
[0189]
1:学习装置
[0190]
2:源数据集
[0191]
3:目标数据集
[0192]
11:数据取得部
[0193]
12:特征抽取部
[0194]
13:疑似样本产生部
[0195]
14:数据转换部
[0196]
15:推理部
[0197]
81:cpu
[0198]
82:rom
[0199]
83:ram
[0200]
84:hdd
[0201]
85:输入部
[0202]
86:显示部
[0203]
87:通信i/f
[0204]
88:总线
[0205]
121:源特征抽取模组
[0206]
122:目标特征抽取模组
[0207]
141:编码器(编码模组)
[0208]
142:分类器
[0209]
143:数据转换模组。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
