1.本发明属于计算机技术领域,具体属于计算机学科中的数据挖掘的技术领域;具体涉及一种异构资源的挖掘与整合方法。
背景技术:
2.当前互联网中各类媒体资源混杂地分布在不同的数据源中,为信息的查找与获取带来了很大困难。对这些分散的异构数据源中的媒体资源进行挖掘和整理,对于解决信息查找与获取的难题具有重要意义。
技术实现要素:
3.本发明提供一种异构资源的整合方法,以解决现有技术中异构资源查找与获取难的问题。
4.为实现上述发明目的,本发明提供一种异构资源的整合方法,使用网络爬虫技术,对网站、网页数据,文档数据,微博信息,微信公众号信息以及用户行为数据进行抓取,并按照统一格式整合为结构化数据,最后设计数据分类处理模块,对处理后的数据按类别进行存储。
5.本发明提供的异构资源的整合方法包括以下工作步骤:步骤1:获取各类信息统一资源定位符;步骤2:增加相关性判断模块,过滤出主题相关性较高的媒体资源页面;步骤3:对过滤出的非结构化数据按照统一的格式进行整合,得到结构化数据,以文本的形式表示;步骤4:识别文本中的词条,进行细分处理;步骤5:去除文本中不存在实际意义的词,提高文本分析处理的效率;步骤6:通过特征提取技术将文本转化为向量表示,从而进一步利用分类算法来进行处理;步骤7:设计文本数据分类处理模块,对处理后的数据按类别进行存储。
6.所述异构资源整合方法,其特征在于,步骤2中所述的相关性判断模块通过统一资源定位符拆分来获取描述词,根据描述词中主题相关词所占的比例来判断统一资源定位符的相关性;对于网页内容的相关性判断,通过向量空间模型来对文档内容进行向量表示和主题相关性计算。
7.所述异构资源整合方法,其特征在于,步骤4中的细分处理,通过文本预处理,提取初步特征,特征降维,计算特征向量,文本分类实现。
8.本发明有益效果如下:本发明针对异构资源智能生成中所面临的关键问题,研究和设计相应的解决方案,面向异构资源主题的信息进行采集、整理和分类。进而真正实现对异构资源的统一管理,对结构化以及非结构化数据信息的统一搜索。
附图说明
9.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
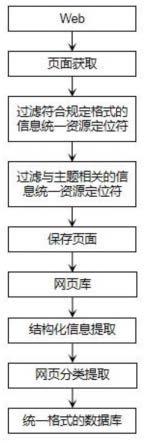
10.图1为本发明的方法流程图。
具体实施方式
11.为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
12.请见图1,本发明提供的一种异构资源的整合方法,包括以下步骤:步骤1:获取各类信息统一资源定位符;步骤2:增加相关性判断模块,过滤出主题相关性较高的媒体资源页面;步骤3:对过滤出的非结构化数据按照统一的格式进行整合,得到结构化数据,以文本的形式表示;步骤4:识别文本中的词条,进行细分处理;步骤5:去除文本中不存在实际意义的词,提高文本分析处理的效率;步骤6:通过特征提取技术将文本转化为向量表示,从而进一步利用分类算法来进行处理;步骤7:设计文本数据分类处理模块,对处理后的数据按类别进行存储。
13.本实施例的相关性判断模块,构建方法为:通过统一资源定位符拆分来获取描述词,根据描述词中主题相关词所占的比例来判断统一资源定位符的相关性;对于网页内容的相关性判断,通过向量空间模型来对文档内容进行向量表示和主题相关性计算。
14.本实施例中,细分处理方法通过文本预处理,提取初步特征,特征降维,计算特征向量,文本分类实现。
15.综上所述,本发明的异构资源的整合方法可以提取异构媒体数据源,整合相关领域信息,实现对采集的数据的结构化信息提取和分类处理,将异构资源转换为便于存储和管理的数据形式,实现异构资源的智能生成。
16.应当理解的是,本说明书未详细阐述的部分均属于现有技术。
17.应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
技术特征:
1.一种异构资源整合方法,其特征在于,所述异构资源使用网络爬虫技术,对网站、网页数据,文档数据,微博信息,微信公众号信息以及用户行为数据进行抓取,并按照统一格式整合为结构化数据,最后设计数据分类处理模块,对处理后的数据按类别进行存储。2.根据权利要求1所述异构资源整合方法,其特征在于,包括以下工作步骤:步骤1:获取各类信息统一资源定位符;步骤2:增加相关性判断模块,过滤出主题相关性较高的媒体资源页面;步骤3:对过滤出的非结构化数据按照统一的格式进行整合,得到结构化数据,以文本的形式表示;步骤4:识别文本中的词条,进行细分处理;步骤5:去除文本中不存在实际意义的词,提高文本分析处理的效率;步骤6:通过特征提取技术将文本转化为向量表示,从而进一步利用分类算法来进行处理;步骤7:设计文本数据分类处理模块,对处理后的数据按类别进行存储。3.根据权利要求2所述异构资源整合方法,其特征在于,步骤2中所述相关性判断模块通过统一资源定位符拆分来获取描述词,根据描述词中主题相关词所占的比例来判断统一资源定位符的相关性;对于网页内容的相关性判断,通过向量空间模型来对文档内容进行向量表示和主题相关性计算。4.根据权利要求2所述异构资源整合方法,其特征在于,步骤4中细分处理,通过文本预处理,提取初步特征,特征降维,计算特征向量,文本分类实现。
技术总结
本发明公开了一种异构资源的整合方法,本发明的方法使用网络爬虫技术,对网站、网页数据,文档数据,微博信息,微信公众号信息以及用户行为数据进行抓取,并按照统一格式整合为结构化数据,最后设计数据分类处理模块,对处理后的数据按类别进行存储,进而真正实现对异构资源的统一管理,对结构化以及非结构化数据信息的统一搜索,以解决现有技术中异构资源查找与获取难的问题。与获取难的问题。与获取难的问题。
技术研发人员:王林林
受保护的技术使用者:镇江睿泰教育科技有限公司
技术研发日:2021.01.12
技术公布日:2022/7/14
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。