1.本技术涉及计算机技术领域,特别涉及一种分类预测模型的训练方法、分类预测方法、装置和设备。
背景技术:
2.随着人工智能技术的快速发展,计算机可以在很多领域代替人工进行决策和判断,这不仅可以降低人员的劳动强度,还可以提高决策和判断的准确性,预测模型便是其中的一个成功案例。基于机器学习对样本数据集合进行训练可以获得预测模型,预测模型能够根据输入数据给出预测分类结果,从而实现自动化的结果预测。
3.在训练用于对多个任务进行结果预测的预测模型时,机器学习模型以序列的形式对多个任务进行学习,此时会出现灾难性遗忘,即机器学习模型在之前任务所学到的知识,会被后续任务的新知识覆盖,导致最终所训练出的预测模型在之前任务上的表现下降,使得预测模型针对之前任务无法给出准确的预测分类结果,因此预测模型的准确性较低。
技术实现要素:
4.本技术实施例提供了一种分类预测模型的训练方法、分类预测方法、装置和设备,能够避免模型训练过程中出现灾难性遗忘,从而提高所训练的分类预测模型的预测结果的准确性。该技术方案如下:
5.一方面,提供了一种分类预测模型的训练方法,包括:
6.获取通过第一样本集进行训练所获得的第一分类预测模型,所述第一分类预测模型包括第一编码子模型和第一分类子模型;
7.通过第二样本集对所述第一编码子模型进行训练,获得第二编码子模型,所述第二样本集与所述第一样本集从多媒体资料中提取得到,且所述第二样本集与所述第一样本集的来源不同,所述多媒体资料包括文本、视频、图片或音频中的至少一种数据;
8.通过所述第二编码子模型对映射样本集进行编码,获得第一向量;
9.通过所述第一向量和第二向量训练第一映射子模型,所述第二向量通过所述第一编码子模型对所述映射样本集进行编码获得,所述第二向量与第三向量的差值小于损失阈值,所述第三向量通过所述第一映射子模型对所述第一向量进行映射获得;
10.通过所述第二编码子模型将所述第二样本集编码为第四向量;
11.通过所述第一映射子模型将所述第四向量映射为第五向量;
12.通过所述第五向量对所述第一分类子模型进行训练,获得第二分类子模型;
13.通过所述第二编码子模型、所述第一映射子模型和所述第二分类子模型构建第二分类预测模型,所述第二分类预测模型用于对待进行结果预测的目标数据进行分类预测。
14.另一方面,提供了一种分类预测方法,包括:
15.获取待进行结果预测的目标数据;
16.获取第二分类预测模型,所述第二分类预测模型包括第二编码子模型、第一映射
子模型和第二分类子模型,所述第二分类预测模型基于第二样本集和第一分类预测模型得到,所述第一分类预测模型通过第一样本集进行训练得到,所述第一分类预测模型包括第一编码子模型和第一分类子模型,所述第一映射子模型对第一向量进行映射获得的第二向量,与所述第一编码子模型对映射样本集进行编码获得的第三向量的差值小于损失阈值,所述第一向量通过所述第二编码子模型对所述映射样本集进行编码获得;所述第二样本集与所述第一样本集从多媒体资料中提取得到,且所述第一样本集与所述第二样本集的来源不同,所述多媒体资料包括文本、视频、图片或音频中的至少一种数据;
17.通过所述第二编码子模型,对所述目标数据进行编码,获得第一目标向量;
18.通过所述第一映射子模型,将所述第一目标向量映射为第二目标向量;
19.将所述第二目标向量输入所述第二分类子模型,获得所述第二分类子模型输出的第二预测分类结果,将所述第二预测分类结果作为所述目标数据的分类结果。
20.另一方面,提供了一种分类预测模型的训练装置,包括:
21.第一获取模块,用于获取通过第一样本集进行训练所获得的第一分类预测模型,所述第一分类预测模型包括第一编码子模型和第一分类子模型;
22.编码训练模块,用于通过第二样本集对所述第一编码子模型进行训练,获得第二编码子模型,所述第二样本集与所述第一样本集从多媒体资料中提取得到,且所述第二样本集与所述第一样本集的来源不同,所述多媒体资料包括文本、视频、图片或音频中的至少一种数据;
23.第一编码模块,用于通过所述第二编码子模型对映射样本集进行编码,获得第一向量;
24.映射训练模块,用于通过所述第一向量和第二向量训练第一映射子模型,所述第二向量通过所述第一编码子模型对所述映射样本集进行编码获得,所述第二向量与第三向量的差值小于损失阈值,所述第三向量通过所述第一映射子模型对所述第一向量进行映射获得;
25.所述第一编码模块,还用于通过所述第二编码子模型将所述第二样本集编码为第四向量;
26.第一映射模块,用于通过所述第一映射子模型,将所述第四向量映射为第五向量;
27.分类训练模块,用于通过所述第五向量对所述第一分类子模型进行训练,获得第二分类子模型;
28.构建模块,用于通过所述第二编码子模型、所述第一映射子模型和所述第二分类子模型构建第二分类预测模型,所述第二分类预测模型用于对待进行结果预测的目标数据进行分类预测。
29.在一种可能的实现方式中,编码训练模块,用于执行如下处理:
30.通过所述第一编码子模型对所述第二样本集进行编码,获得第六向量;
31.获取所述第一分类子模型基于所述第六向量,输出的第一预测分类结果;
32.根据所述第一预测分类结果,对所述第一编码子模型的模型参数进行迭代更新,直至所述第一预测分类结果与所述第二样本集的真实分类结果相匹配,获得所述第二编码子模型。
33.在一种可能的实现方式中,所述映射样本集包括所述第一样本集中的全部或部分
样本,所述映射样本集从第一存储空间读取,且所述映射样本集在训练获得所述第一分类预测模型后被存储到所述第一存储空间。
34.在一种可能的实现方式中,所述第二向量从第二存储空间读取,且所述第二向量在训练获得所述第一分类预测模型后被存储到所述第二存储空间。
35.在一种可能的实现方式中,所述第一样本集包括至少两个子样本集,不同的子样本集的来源不同;所述第一分类预测模型通过所述至少两个子样本集进行顺序训练获得,通过每个子样本集训练所述第一分类预测模型的方法,与通过所述第二样本集训练所述第二分类预测模型的方法相同。
36.在一种可能的实现方式中,所述第一分类预测模型还包括第二映射子模型;
37.所述映射训练模块,用于将所述第一向量作为输入对所述第二映射子模型进行迭代训练,直至所述第二映射子模型输出的第三向量与所述第二向量的差值小于所述损失阈值。
38.在一种可能的实现方式中,所述映射训练模块,用于执行如下处理:
39.将所述第一向量输入所述第二映射子模型,获得所述第二映射子模型输出的所述第三向量;
40.将所述第二向量和所述第三向量输入损失函数;
41.对所述第二映射子模型的模型参数进行迭代更新,使所述损失函数最小化,直至所述损失函数输出最小值时,获得所述第一映射子模型,所述损失函数输出的最小值小于所述损失阈值。
42.在一种可能的实现方式中,所述映射样本集包括至少两个子映射样本集,每个子映射样本集对应一个所述子样本集,不同的所述子映射样本集对应不同的所述子样本集,所述子映射样本集包括相对应所述子样本集中的全部或部分样本。
43.在一种可能的实现方式中,该装置还包括:
44.模型评价模块,用于获取所述第二分类预测模型对每个所述子样本集进行预测的第一准确率;获取所述第二分类预测模型对所述第二样本集进行预测的第二准确率;将各所述第一准确率和所述第二准确率的平均值,确定为所述第二分类预测模型的预测准确率。
45.在一种可能的实现方式中,所述第一编码子模型包括双向长短期记忆网络bilstm模型。
46.另一方面,提供了一种分类预测装置,包括:
47.第二获取模块,用于获取待进行结果预测的目标数据;
48.第三获取模块,用于获取第二分类预测模型,所述第二分类预测模型包括第二编码子模型、第一映射子模型和第二分类子模型,所述第二分类预测模型基于第二样本集和第一分类预测模型得到,所述第一分类预测模型通过第一样本集进行训练得到,所述第一分类预测模型包括第一编码子模型和第一分类子模型,所述第一映射子模型对第一向量进行映射获得的第二向量,与所述第一编码子模型对映射样本集进行编码获得的第三向量的差值小于损失阈值,所述第一向量通过所述第二编码子模型对所述映射样本集进行编码获得;
49.第二编码模块,用于通过所述第二编码子模型,对所述目标数据进行编码,获得第
一目标向量;
50.第二映射模块,用于通过所述第一映射子模型,将所述第一目标向量映射为第二目标向量;
51.分类模块,用于将所述第二目标向量输入所述第二分类子模型,获得所述第二分类子模型输出的第二预测分类结果,将所述第二预测分类结果作为所述目标数据的分类结果。
52.另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述指令由所述处理器加载并执行以实现如上述的分类预测模型的训练方法或分类预测方法所执行的操作。
53.另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述指令由处理器加载并执行以实现如上述的分类预测模型的训练方法或分类预测方法所执行的操作。
54.另一方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括程序代码,该程序代码存储在计算机可读存储介质中,计算机设备的处理器从计算机可读存储介质读取该程序代码,处理器执行该程序代码,使得计算机设备执行如上述的分类预测模型的训练方法或分类预测方法所执行的操作。
55.本技术实施例提供的技术方案带来的有益效果包括:
56.针对来源不同的第一样本集和第二样本集,由于通过第二样本集对第一编码子模型进行训练获得第二编码子模型后,第二编码子模型在第一样本集学到的知识,会被在第二样本集学到的知识覆盖。为此,通过第二编码子模型对映射样本集进行编码获得第一向量,获取第一编码子模型对映射样本集进行编码所获得的第二向量,通过第一向量和第二向量训练第一映射子模型,使得第一映射子模型将第一向量映射成的第三向量与第二向量的差值小于损失阈值,从而对于同一样本,通过第二编码子模型和第一映射子模型所获得的向量,与通过第一编码子模型所获得的向量相同或相近,能够使第二分类预测模型在第一样本集学习到的知识不被覆盖,因此避免了分类预测模型的训练过程中出现灾难性遗忘,从而能够提高所训练的分类预测模型的准确性,进而使得基于该分类预测模型进行分类预测所得到的预测结果的准确性更高。
附图说明
57.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
58.图1是本技术实施例提供的一种实施环境的示意图;
59.图2是本技术实施例提供的一种分类预测模型的训练方法的流程图;
60.图3是本技术实施例提供的另一种分类预测模型的训练方法的流程图;
61.图4是本技术实施例提供的一种分类预测模型的训练过程的示意图;
62.图5是本技术实施例提供的一种主诉文本的示意图;
63.图6是本技术实施例提供的一种不同分类预测模型预测结果对比的示意图;
64.图7是本技术实施例提供的一种分类预测方法的流程图;
65.图8是本技术实施例提供的一种分类预测模型的训练装置的示意图;
66.图9是本技术实施例提供的另一种分类预测模型的训练装置的示意图;
67.图10是本技术实施例提供的一种分类预测装置的示意图;
68.图11是本技术实施例提供的一种终端的结构示意图;
69.图12是本技术实施例提供的一种服务器的结构示意图。
具体实施方式
70.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清除、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
71.本技术中术语“第一”、“第二”等字样用于对作用和功能基本相同的相同项或相似项进行区分,应理解,“第一”、“第二”、“第n”之间不具有逻辑或时序上的依赖关系,也不对数量和执行顺序进行限定。
72.人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
73.人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
74.机器学习(machine learning,ml)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、示教学习等技术。
75.自然语言处理(nature language processing,nlp)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。
76.随着人工智能技术研究和进步,人工智能技术在多个领域展开研究和应用,例如常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗、智能客服等,相信随着技术的发展,人工智能技术将在更多的领域得
到应用,并发挥越来越重要的价值。
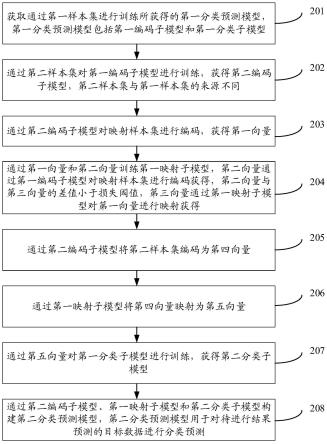
77.本技术实施例提供的方案涉及人工智能服务的结果预测,例如,基于机器学习的模型训练和结果预测,具体通过如下实施例进行说明。
78.图1是本技术实施例提供的一种分类预测模型的训练方法的实施环境示意图,参见图1,该实施环境包括:终端101和服务器102;
79.终端101通过无线网络或有线网络与服务器102相连。终端101可以是智能手机、平板电脑、便携计算机、医疗用计算机、材料检测计算机等设备。本领域技术人员可以知晓,上述终端101的数量可以更多或更少,比如上述终端101可以仅为一个,或者上述终端101为几十个或几百个,或者更多数量,本技术实施例对终端101的数量和设备类型不加以限定。
80.服务器102可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务器、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(content delivery network,cdn)、以及大数据和人工智能平台等基础云计算服务的云服务器。本领域技术人员可以知晓,上述服务器102的数量可以更多或更少,本技术对此不加以限定。当然,服务器102还可以包括其他功能的服务器,以便提供更全面且多样化的服务。
81.本技术实施例中,可以由终端101或服务器102作为执行主体来实施本技术实施例提供的技术方案,也可以通过终端101与服务器102之间的交互来实施本技术实施例提供的技术方案,本技术实施例对此不作限定。下面将以执行主体为服务器102为例进行说明:
82.在本技术实施例中,终端101上设置有用于存储训练样本的存储空间,该存储空间中存储的训练样本用于训练分类预测模型。终端101可以接收外部输入的训练样本,将所接收到的训练样本存储到存储空间中。终端101还可以从文本、视频、图片或音频等多媒体资料中提取训练样本,将提取到的训练样本存储到存储空间中。服务器102从终端101获取训练样本后,服务器102基于所获取到的训练样本训练分类预测模型,进而通过分类预测模型进行分类预测。
83.图2是本技术实施例提供的一种分类预测模型的训练方法的流程图,参见图2,该方法包括如下步骤:
84.201、获取通过第一样本集进行训练所获得的第一分类预测模型,第一分类预测模型包括第一编码子模型和第一分类子模型。
85.示例性地,第二样本集与第一样本集从多媒体资料中提取得到,且第一样本集与第二样本集的来源不同,多媒体资料包括文本、视频、图片或音频中的至少一种数据。第一样本集包括至少一个样本,第一样本集所包括的样本为文本、图像或音频等数据形式。
86.第一分类预测模型通过第一样本集训练获得,第一分类预测模型能够根据输入的目标数据,输出相应的预测分类结果。第一分类预测模型包括第一编码子模型和第一分类子模型,第一编码子模型用于将输入数据编码为相应的向量,第一分类子模型用于基于第一编码子模型编码出的向量输出预测分类结果。
87.在一种可能的实现方式中,对第一编码子模型和第一分类子模型进行初始化,通过第一编码子模型对第一样本集中的样本进行编码,获得向量,将所获得的向量输入第一分类子模型,获得第一分类子模型输出的预测分类结果,根据所获得预测分类结果与第一样本集中样本所对应的真实分类结果的差距,对第一编码子模型和第一分类子模型的模型
参数进行迭代更新,直至第一分类子模型输出的预测分类结果与样本对应的真实分类结果相同或差距满足要求,停止对第一编码子模型和第一分类子模型的模型参数进行迭代更新,从而获得包括第一编码子模型和第一分类子模型的第一分类预测模型。
88.在另一种可能的实现方式中,由于分类预测模型的训练可以是持续进行的,因此可以按照训练第二分类预测模型的方法来训练获得第一分类预测模型,比如,按照本实施例所提供的分类预测模型的训练方法,基于第三预测模型训练获得第一分类预测模型。
89.需要说明的是,第一分类预测模型还可以通过其他方式获取,本技术对此不加以限定。
90.202、通过第二样本集对第一编码子模型进行训练,获得第二编码子模型,第二样本集与第一样本集的来源不同。
91.第二样本集包括至少一个样本,第二样本集所包括的样本为文本、图像或音频等数据形式,第二样本集和第一样本集中样本的数据形式相同或不同。第二样本集与第一样本集的来源不同,比如第一样本集和第二样本集中的样本为病历中的主诉文本时,第二样本集和第一样本集来自不同的医院,或者第二样本集和第一样本集来自同一医院的不同科室。
92.通过第二样本集对第一编码子模型进行训练,获得第二编码子模型,第二编码子模型用于将输入数据编码为相应的向量。
93.203、通过第二编码子模型对映射样本集进行编码,获得第一向量。
94.映射样本集包括至少一个样本,映射样本集所包括的样本为文本、图像、或音频等数据形式,第一编码子模型和第二编码子模型均能够将映射样本集编码为相应的向量。
95.映射样本集中的样本可以从第一样本集和第二样本集之外随机选取获得,或者选取第一样本集中的部分或全部样本作为映射样本集,或者选取第二样本集中的部分或全部样本作为映射样本集,再或者从第一样本集和第二样本集中分别选取部分样本作为映射样本集。
96.将映射样本集输入第二编码子模型后,第二编码子模型对映射样本集进行编码,获得第一向量。
97.204、通过第一向量和第二向量训练第一映射子模型,第二向量通过第一编码子模型对映射样本集进行编码获得,第二向量与第三向量的差值小于损失阈值,第三向量通过第一映射子模型对第一向量进行映射获得。
98.第二向量通过第一编码子模型对映射样本集进行编码获得,通过第一向量和第二向量训练第一映射子模型,所训练出的第一映射子模型能够将第一向量映射为第三向量,且所映射出的第三向量与第二向量的差值小于损失阈值。
99.例如,在训练获得第一映射子模型后,对于映射样本集中的一个样本,第一编码子模型将该样本编码为向量1,第二编码子模型将该样本编码为向量2,第一映射子模型将向量2映射为向量3,则向量1与向量3的差值小于损失阈值,即向量1与向量3相同或相近似。
100.损失阈值作为训练第一映射子模型的目标,用于衡量第三向量与第二向量的差值大小,当第三向量与第二向量的差值小于损失阈值后,对第一映射子模型的训练结束。可选地,损失阈值为预先设定的值。
101.205、通过第二编码子模型将第二样本集编码为第四向量。
102.第一分类预测模型中的第一分类子模型,用于根据输入的向量输出预测分类结果,在通过第二样本集训练获得第二编码子模型后,为了通过第二样本集对第一分类子模型进行训练以获得第二分类子模型,需要通过第二编码子模型将第二样本集中的样本编码为第四向量,进而可以基于第四向量对第一分类子模型进行训练,以获得第二分类子模型。
103.需要说明的是,步骤204和步骤205可以是同步执行或者按照当前顺序执行,又或者是先执行步骤205再执行步骤204。
104.206、通过第一映射子模型将第四向量映射为第五向量。
105.通过第二样本集对第一编码子模型进行训练,获得第二编码子模型后,第二编码子模型在第二样本集学习到的新知识,会将在第一样本集学习到的知识覆盖,而通过第一映射子模型将第二编码子模型编码出的向量映射为另一个向量,从而基于在第一样本集和第二样本集所学到的知识将样本转换为向量,避免模型训练过程中发生灾难性遗忘。通过第一映射子模型将第四向量映射为第五向量,使得第五向量是基于在第一样本集和第二样本集所学到的知识而获得的向量,保证后续基于第五向量训练第二分类子模型时,第二分类子模型不会发生灾难性遗忘,从而进一步保证所训练分类预测模型的准确性。
106.207、通过第五向量对第一分类子模型进行训练,获得第二分类子模型。
107.第二样本集中的每个样本均具有相对应的标签,一个样本对应的标签即为该样本的真实分类结果,比如样本为描述一个事物的文本数据,则该样本的标签为该样本所描述事物所属的类别。
108.由于第二编码子模型将第二样本集编码为第四向量,第一映射子模型将第四向量映射为第五向量,示例性地,通过第五向量对第一分类子模型进行训练时,可基于第五向量和第二样本集中各样本对应的标签,对第一分类子模型进行训练,获得第二分类子模型,使得将第五向量输入第二分类子模型后,第二分类子模型能够输出相应的标签。
109.208、通过第二编码子模型、第一映射子模型和第二分类子模型构建第二分类预测模型,第二分类预测模型用于对待进行结果预测的目标数据进行分类预测。
110.第二分类预测模型包括第二编码子模型、第一映射子模型和第二分类子模型,第二编码子模型用于将输入数据编码为相应的向量,第一映射子模型用于将第二编码子模型编码出的向量映射为另一个向量,第二分类子模型用于根据第一映射子模型映射出的向量输出预测分类结果。
111.本技术实施例提供的方案,通过第二样本集对第一编码子模型进行训练获得第二编码子模型后,第二编码子模型在第一样本集学到的知识,会被在第二样本集学到的知识覆盖。为此,通过第二编码子模型对映射样本集进行编码获得第一向量,获取第一编码子模型对映射样本集进行编码所获得的第二向量,通过第一向量和第二向量训练第一映射子模型,使得第一映射子模型将第一向量映射成的第三向量与第二向量的差值小于损失阈值,从而对于同一样本,通过第二编码子模型和第一映射子模型所获得的向量,与通过第一编码子模型所获得的向量相同或相近。基于第二编码子模型、第一映射子模型和第二样本集对第一分类子模型进行训练,获得第二分类子模型,进而获得包括有第二编码子模型、第一映射子模型和第二分类子模型的第二分类预测模型。由于通过第二编码子模型和第一映射子模型将样本转换为向量,因此避免了分类预测模型的训练过程中出现灾难性遗忘,从而能够提高所训练的分类预测模型的准确性,进而使得基于该分类预测模型进行分类预测所
得到的预测结果的准确性更高。
112.图3是本技术实施例提供的一种分类预测模型的训练方法的流程图,参见图3,该分类预测模型的训练方法包括:
113.301、获取通过第一样本集进行训练所获得的第一分类预测模型。
114.第一分类预测模型是通过第一样本集训练获得的,根据第一样本集中样本来源的数量不同,第一分类预测模型通过一次或多次训练获得。
115.在第一种可能的实现方式中,第一样本集中各样本具有相同的来源,此时通过第一样本集进行一次训练获得第一分类预测模型,所获得的第一分类预测模型包括第一编码子模型和第一分类子模型。比如,第一样本集中的样本为描述个体属性的文本数据,且第一样本集中各样本来自同一单位的同一科室,因此第一样本集中各样本具有相同的数据格式,通过第一样本集训练出的第一分类预测模型用于根据个体属性确定个体所属的类别。
116.第一样本集不仅包括有多个样本,还包括有每个样本对应的标签,标签为相应样本对应的真实分类结果。比如,第一样本集中的样本为描述个体属性的文本数据时,样本对应的标签为相应个体所属的类别。
117.实现时,第一编码子模型将第一样本集编码为向量,第一分类子模型根据第一编码子模型编码出的向量输出预测分类结果,根据预测分类结果与第一样本集中样本所对应真实分类结果之间的差距,对第一编码子模型和第一分类子模型进行迭代训练,直至第一分类子模型输出的预测分类结果与样本的真实分类结果相同或者差距满足要求,进而获得包括第一编码子模型和第一分类子模型的第一分类预测模型。
118.在第二种可能的实现方式中,第一样本集包括至少两个子样本集,每个子样本集包括至少一个样本,不同的子样本集的来源不同,此时通过各子样本集进行顺序训练获得第一分类预测模型,所获得的第一分类预测模型包括第一编码子模型、第二映射子模型和第一分类子模型。比如,第一样本集包括k个子样本集,每个子样本集中的样本均为描述个体属性的文本数据,同一子样本集中的样本来自同一单位或同一科室,不同子样本集中的样本来自不同单位或不同科室,同一子样本集中各样本具有相同的数据格式。
119.实现时,在通过第一样本集中的各子样本集训练第一分类预测模型时,按照对第一分类预测模型进行训练的顺序不同,通过第一样本集中样本中各子样本集对第一分类预测模型进行训练具有三种方式,对于第一个子样本集(第一样本集中样本中第一个用于对第一分类预测模型进行训练的子样本集),采用第一种方式对第一分类预测模型进行训练,对于第二个子样本集(第一样本集中样本中第二个用于对第一分类预测模型进行训练的子样本集),采用第二种方式对第一分类预测模型进行训练,对于第一样本集中除第一个子样本集和第二个子样本集之外的子样本集,采用第三种方式对第一分类预测模型进行训练。下面对上述三种通过子样本集对第一分类预测模型的训练方法进行分别说明。为了方便描述,将第一样本集中第一个用于对第一分类预测模型进行训练的子样本集定义为子样本集s1,将第一样本集中第二个用于对第一分类预测模型进行训练的子样本集定义为子样本集s2,将第一样本集中第二个之后用于对第一分类预测模型进行训练的子样本集定义为子样本集sk。
120.对于通过子样本集s1训练第一分类预测模型:第一编码子模型将子样本集s1编码为向量,第一分类子模型根据第一编码子模型编码出的向量输出预测分类结果,根据该预
测分类结果与子样本集s1中样本所对应真实分类结果之间的差距,对第一编码子模型和第一分类子模型进行迭代训练,直至第一分类子模型输出的预测分类结果与子样本集s1中样本的真实分类结果相同,进而获得包括第一编码子模型b1和第一分类子模型f1的第一分类预测模型m1。
121.在通过第一分类预测模型m1进行分类预测时,首先通过第一编码子模型b1将输入数据编码为向量,之后将第一编码子模型b1编码出的向量输入第一分类子模型f1,获得第一分类子模型f1输出的预测分类结果。
122.对于通过子样本集s2训练第一分类预测模型:通过子样本集s2训练第一编码子模型b1,获得第一编码子模型b2。通过第一编码子模型b1对包括至少一个样本的映射样本集进行编码,获得向量1,通过第一编码子模型b2对上述映射样本集进行编码,获得向量2,根据向量1和向量2训练第二映射子模型y2,其中第二映射子模型y2能够将向量2映射为限量3,且向量1与向量3的差值小于损失阈值。通过第一编码子模型b2将子样本集s2编码为向量4,通过第二映射子模型y2将向量4映射为向量5,通过向量5对第一分类子模型f1进行训练,获得第一分类子模型f2,进而获得包括第一编码子模型b2、第二映射子模型y2和第一分类子模型f2的第一分类预测模型m2。
123.在通过第一分类预测模型m2进行分类预测时,首先通过第一编码子模型b2将输入数据编码为向量,之后通过第二映射子模型y2将第一编码子模型b2编码出的向量映射为另一个向量,之后将第二映射子模型y2映射出的向量输入第一分类子模型f2,获得第一分类子模型f2输出的预测分类结果。
124.对于通过子样本集sk训练第一分类预测模型:获取通过子样本集s
k-1
训练获得的第一分类预测模型m
k-1
,子样本集s
k-1
为子样本集sk的上一个子样本集,第一分类预测模型m
k-1
包括第一编码子模型b
k-1
、第二映射子模型y
k-1
和第一分类子模型f
k-1
。通过子样本集sk训练第一编码子模型b
k-1
,获得第一编码子模型bk。通过第一编码子模型b
k-1
对包括至少一个样本的映射样本集进行编码,获得向量6,通过第一编码子模型bk对上述映射样本集进行编码,获得向量7,根据向量6和向量7对第二映射子模型y
k-1
进行训练,获得第二映射子模型yk,其中第二映射子模型yk能够将向量7映射为向量8,且向量6与向量8的差值小于损失阈值。通过第一编码子模型bk将子样本集sk编码为向量9,通过第二映射子模型yk将向量9映射为向量10,通过向量10对第一分类子模型f
k-1
进行训练,获得第一分类子模型fk,进而获得包括第一编码子模型bk、第二映射子模型yk和第一分类子模型fk的第一分类预测模型mk。
125.在通过第一分类预测模型mk进行分类预测时,首先通过第一编码子模型bk将输入数据编码为向量,之后通过第二映射子模型yk将第一编码子模型bk编码出的向量映射为另一个向量,之后将第二映射子模型yk映射出的向量输入第一分类子模型fk,获得第一分类子模型fk输出的预测分类结果。
126.需要说明的是,通过子样本集训练第一编码子模型的具体方法,参见后续实施例中通过第二样本集对第一编码子模型进行训练的描述。训练第二映射子模型的具体方法,参见后续实施例中训练第一映射子模型的描述。
127.302、获取第二样本集。
128.第二样本集包括有至少一个样本,第二样本集与第一样本集从多媒体资料中提取得到,且第一样本集与第二样本集的来源不同,多媒体资料包括文本、视频、图片或音频中
的至少一种数据;第二样本集和第一样本集中样本具有相同的数据类型,比如第一样本集和第二样本集中的样本均是用于描述个体属性的文本数据。
129.在一种可能的实现方式中,第一样本集和第二样本集来自于不同的单位,或者来自于相同单位的不同部门。比如,第一样本集中的样本来自于汽车厂a,第二样本集中的样本来自于汽车厂b,第一样本集和第二样本集中的样本均为描述汽车所出现缺陷的文本数据,预测模型用于根据汽车所出现缺陷的文本数据,预测汽车生产线的故障位置。再比如,第一样本集中的样本来自于汽车厂a的涂装车间,第二样本集中的样本来自于汽车厂a的总装车间,第一样本集和第二样本集中的样本均为描述汽车所出现缺陷的文本数据,预测模型用于根据汽车所出现缺陷的文本数据,预测汽车生产线的故障位置。
130.在另一种可能的实现方式中,预测模型用于根据描述个体属性的文本数据,预测相应个体所属的类别,第一样本集和第二样本集中的样本为用于描述个性属性的文本数据,此时第一样本集和第二样本集中的样本用于描述不同类别个体的属性。比如,第一样本集中的样本用于描述属于a类别、b类别或c类别的个体的属性,第二样本集中的样本用于属于描述d类别或e类别的个体的属性。
131.303、通过第二样本集对第一编码子模型进行训练,获得第二编码子模型。
132.通过第一分类预测模型中的第一编码子模型,对第二样本集进行编码,获得第六向量,通过第一分类预测模型中的第二映射子模型,将第六向量映射为第七向量,将第七向量输入第一分类预测模型包括的第一分类子模型,获得第一分类子模型输出的第一预测分类结果。根据第一分类子模型输出的第一预测分类结果,对第一编码子模型的模型参数进行迭代更新,直至第一分类子模型输出的第一预测分类结果与第二样本集的真实分类结果相匹配,获得第二编码子模型。
133.由于对第一编码子模型的模型参数进行迭代更新,在每次对第一编码子模型的模型参数进行更新之后,通过更新模型参数之后的第一编码子模型对第二样本集进行编码,获得第六向量。之后,通过第二映射子模型将第六向量映射为第七向量,将第七向量输入第一分类子模型获得第一预测分类结果。如果第一预测分类结果与第二样本集的真实分类结果相匹配,则停止对第一编码子模型的模型参数进行迭代更新,将此时的第一编码子模型作为第二编码子模型。如果第一预测分类结果与第二样本集的真实分类结果不匹配,则在对第一编码子模型的模型参数进行更新后重复上述处理过程,直至第一分类子模型输出的第一预测分类结果与第二样本集的真实分类结果相匹配。
134.304、获取映射样本集。
135.映射样本集包括有至少一个样本,而且映射样本集中的样本与第一样本集和第二样本集中的样本具有相同的数据类型,以保证第一编码子模型和第二编码子模型能够将映射样本集编码成相应的向量。比如,第一样本集和第二样本集中的样本为用于描述个体属性的文本数据,则映射样本集中的样本也为用于描述个体属性的文本数据。
136.在一种可能的实现方式中,映射样本集中的样本是随机获取的,比如根据第一样本集和第二样本集中样本的数据类型,随机获取1万个样本作为映射样本集。
137.在另一种可能的实现方式中,映射样本集是第一样本集的子集,即映射样本集中的样本是从第一样本集中获取的,根据第一样本集所包括子样本集的数量,映射样本集具有不同的组成形式,下面参照上述步骤301,对映射样本集的组成形式进行说明。
138.当第一样本集中的样本具有相同来源时,即通过第一样本集进行一次训练获得第一分类预测模型时,映射样本集包括第一样本集中的全部或部分样本。可选地,在通过第一样本集训练获得第一分类预测模型后,从第一样本集中随机选取一定数量的样本,将所选取出的各样本作为映射样本集。比如,在通过第一样本集训练获得第一分类预测模型后,从第一样本集中随机选取1万个样本,将所选取的1万个样本作为映射样本集。
139.当第一样本集包括至少两个子样本集,即通过第一样本集所包括的各子样本集进行顺序训练获得第一分类预测模型时,此时映射样本集包括至少两个子映射样本集,每个子映射样本集对应第一样本集包括的一个子样本集,不同的子映射样本集对应不同的子样本集,每个子映射样本集包括相对应子样本中的全部或部分样本。可选地,在通过一个子样本集对第一分类预测模型进行训练后,从该子样本集中随机选取一定数量的样本,作为与该子样本集对应的子映射样本集,进而将该子样本集对应的子映射样本集,和与该子样本集之前的子样本集对应的子映射样本集作为映射样本集。
140.比如,第一样本集包括k个子样本集,在通过第一样本集中的第k个子样本集对第一分类预测模型进行训练时,从第k个子样本集中随机选取部分样本,作为与第k个子样本集对应的子映射样本集rk,同理可以获取与第一样本集中前k-1个子样本集对应的子映射样本集r1~r
k-1
,从而所获得的映射样本集为{r1、r2,r3,
…
,rk}。
141.需要说明的是,当映射样本集包括多个子映射样本集时,不同子映射样本集所包括样本的数量相同或者不同。在一种可能的实现方式中,从每个子样本集中随机选取固定数量的样本,作为与该样本集对应的子映射样本集,此时各子映射样本集包括有相同数量的样本,比如从每个子样本集中随机选取1万个样本作为子映射样本集。在另一种可能的实现方式中,对于每个子样本集,根据该子样本集中样本的数量,从该子样本集中随机选取样本,使得所选取样本的数量与该子样本集中样本的数量之比等于预设的百分比,进而将所选取出的样本作为与该子样本集对应的子映射样本集,比如,对于每个子样本集,从该子样本集中随机选取数量等于该子样本集中样本数量1%的样本,作为与该子样本集对应的子映射样本集。
142.当映射样本集包括第一样本集中的全部或部分样本时,在通过第一样本集训练获得第一分类预测模型后,从第一样本集中选取出的映射样本集被存储的第一存储空间,进而在获取映射样本集时,从第一存储空间读取映射样本集。可选地,一个设备上的第一存储空间,不仅用于存储映射样本集,还用于存储第一分类预测模型的模型文件,当需要在其他设备上部署预测模型时,将第一存储空间中的映射样本集和第一分类预测模型的模型文件,一起拷贝到需要部署预测模型的设备上。
143.在一些应用场景下,出于对数据安全性和隐私性的考虑,第一样本集中的样本不能被全部拷贝,比如,用于训练a单位所使用分类预测模型的样本,不能被全部拷贝到b单位,以作为映射数据集对b单位所使用的分类预测模型进行训练。为此,映射数据集仅包括第一样本集中的部分样本,从而能够满足用户对于数据安全性和隐私性的要求。
144.305、通过第二编码子模型对映射样本集进行编码,获得第一向量。
145.在获取到映射样本集后,通过第二编码子模型对映射样本集进行编码,获得第一向量。本领域技术人员可以知晓,由于映射样本集包括有多个样本,第二编码子模型对映射样本集进行编码,是指分别对映射样本集包括的每个样本进行编码,获得映射样本集中每
个样本对应的向量,因此第一向量并非指某一个向量,而是指包括有映射样本集中每个样本经第二编码子模型编码所获得向量的向量集合。
146.由于映射样本集、第一样本集和第二样本集中样本的数据类型相同,而第二编码子模型是基于第一样本集和第二样本集训练获得的,因此第二编码子模型可以将映射样本集编码为第一向量。比如,当映射样本集、第一样本集和第二样本集中的样本均为文本数据时,第一编码子模型为bilstm模型,相应的第二编码子模型也为bilstm模型,通过第二编码子模型对映射样本集进行编码时,对于映射样本集中的每个样本,首先对该样本进行分词处理,之后将获得的分词输入第二编码子模型,第二编码子模型对该样本进行两个方向的编码,并将两个方向上的编码拼接起来作为该样本对应的向量。
147.例如,参见上述步骤304,映射样本集为{r1、r2,r3,
…
,rk},通过第二编码子模型对映射样本集进行编码,获得的第一向量为{e1、e2,e3,
…
,ek}。
148.306、获取通过第一编码子模型对映射样本集进行编码所获得的第二向量。
149.在一种可能的实现方式中,在获取到映射样本集后,通过第一编码子模型对映射样本集进行编码,获得第二向量。需要说明的是,第一编码子模型对映射样本集进行编码的方法,参见上述步骤305第二编码子模型对映射样本集进行编码方法。
150.在另一种可能的实现方式中,当第一样本集包括有至少两个子样本集时,即通过第一样本集包括的各子样本集进行顺序训练获得第一分类预测模型时,在通过第一样本集中最后一个子样本集训练第一分类预测模型的过程中,第一编码子模型会对映射样本集进行编码而获得第二向量,而所获得的第二向量会被存储到第二存储空间。进而在获取通过第一编码子模型对映射样本集进行编码所获得的第二向量时,从第二存储空间读取第二向量。
151.可选地,一个设备上的第二存储空间和第一存储空间相同,即第一存储空间/第二存储空间用于存储映射样本集、第一分类预测模型的模型文件和第二向量。当需要在其他设备上部署分类预测模型时,将第一存储空间/第二存储空间中的映射样本集、第一分类预测模型的模型文件和第二向量,一起拷贝到需要部署分类预测模型的设备上。
152.在通过第一样本集训练第一分类预测模型的过程中,会通过第一编码子模型对映射样本集进行编码而获得第二向量,将所获得的第二向量存储到第二存储空间,在通过第二样本集训练第一分类预测模型获得第二分类预测模型的过程中,直接从第二存储空间读取第二向量,无需再次通过第一编码子模型对映射样本集进行编码以获得第二向量,可以提升分类预测模型训练的效率。
153.例如,参见上述步骤304,映射样本集为{r1、r2,r3,
…
,rk},通过第一编码子模型对映射样本集进行编码所获得的第二向量为{e
′1、e
′2,e
′3,
…
,e
′k}。
154.307、通过第一向量和第二向量,训练第一映射子模型。
155.在获取到第一向量和第二向量之后,通过第一向量和第二向量训练第一映射子模型,训练所获得的第一映射子模型将第一向量映射为第三向量后,第三向量与第二向量的差值小于损失阈值。
156.通过第二样本集对第一编码子模型进行训练,获得第二编码子模型时,第二编码子模型在第一样本集中学习的知识,会被在第二样本集学习到的知识覆盖,导致第二编码子模型在第一样本集上的表现下降,因此对于同一个样本,通过第一编码子模型和第二编
码子模型对该样本进行编码,所获得两个向量差距较大。通过训练第一映射子模型,第一映射子模型将第二编码子模型编码出的向量映射为另一个向量,第一映射子模型映射出的向量与第一编码子模型编码出的向量相同或相近,从而第二编码子模型在从第二样本集学习知识的同时,不会覆盖在第一样本集学习的知识,避免了分类预测模型训练过程中出现灾难性遗忘,在针对第二样本集进行模型参数优化的同时,能够保持在第一样本集上的表现。
157.在一种可能的实现方式中,当通过第一样本集进行一次训练获得第一分类预测模型时,第一分类预测模型仅包括第一编码子模型和第一分类子模型,此时基于第一向量与第二向量进行迭代训练,获得第一映射子模型,使得训练出的第一映射子模型能够将第一向量映射为第三向量,且第三向量与第二向量的差值小于损失阈值。
158.在另一种可能的实现方式中,当通过第一样本集所包括的各子样本集进行顺序训练获得第一分类预测模型时,第一分类预测模型包括第一编码子模型、第二映射子模型和第一分类子模型,此时将第一向量输入第二映射子模型,获得第二映射子模型输出的第三向量,将第二向量和第三向量输入损失函数,通过对第二映射子模型的模型参数进行迭代更新,以使损失函数最小化,当损失函数达到最小化时,停止对第二映射子模型的模型参数进行迭代更新,将此时的第二映射子模型确定为第一映射子模型。需要说明的是,当完成损失函数达到最小化时,损失函数输出的最小值小于损失阈值。
159.308、通过第二编码子模型将第二样本集编码为第四向量。
160.在获取到第二编码子模型后,通过第二编码子模型将第二样本集编码为第四向量。本领域技术人员可以知晓,由于第二样本集包括有多个样本,第二编码子模型对第二样本集进行编码,是指分别对第二样本集包括的每个样本进行编码,获得第二样本集中每个样本对应的向量,因此第四向量并非指某一个向量,而是指包括有第二样本集中每个样本经第二编码子模型编码所获得向量的向量集合。
161.参见上述步骤305,第二编码子模型为bilstm模型,且第二样本集中的样本为文本数据时,通过第二编码子模型对第二样本集进行编码时,对于第二样本集中的每个样本,首先对该样本进行分词处理,之后将获得的分词输入第二编码子模型,第二编码子模型对该样本进行两个方向的编码,并将两个方向上的编码拼接起来,获得对该样本对应的向量,进而将第二样本集中各样本所对应向量的集合确定为第四向量。
162.需要说明的是,步骤308和步骤304~307可以是同步执行或者按照当前顺序执行,又或者是先执行步骤304~307再执行步骤308。
163.309、通过第一映射子模型将第四向量映射为第五向量。
164.在训练出第一映射子模型,并获得第四向量后,将第四向量输入第一映射子模型,第一映射子模型会将第四向量映射为第五向量。参见上述步骤308,由于第四向量为包括多个向量的向量集合,在通过第一映射子模型将第四向量映射为第五向量时,分别将第四向量包括的每个向量输入第一映射子模型,获得第一映射子模型映射出的向量,进而将包括第一映射子模型映射出的各向量的集合确定为第五向量。
165.310、通过第五向量对第一分类子模型进行训练,获得第二分类子模型。
166.第二样本集包括有多个样本,而且包括每个样本对应的标签,标签为相应样本的真实分类结果。比如,为了根据用于描述个体属性的文本数据,来预测个体所属的类别而训练分类预测模型,此时第二样本集中的样本为用于描述个体属性的文本数据,而样本的标
签为相应个体所属的类别。
167.对于第五向量所包括的每个向量,将该向量及该向量所对应样本的标签作为一个训练数据,进而通过各训练数据对第一分类子模型进行训练,以对第一分类子模型的模型参数进行优化,获得第二分类子模型,使得在将第五向量包括的向量输入第二分类子模型后,第二分类子模型能够输出相应向量所对应样本的标签。
168.311、通过第二编码子模型、第一映射子模型和第二分类子模型构建第二分类预测模型,第二分类预测模型用于对待进行结果预测的目标数据进行分类预测。
169.通过训练获得第二编码子模型、第一映射子模型和第二分类子模型后,获得包括有第二编码子模型、第一映射子模型和第二分类子模型的第二分类预测模型。第二分类预测模型能够基于与第二样本集具有相同来源的目标数据进而分类预测,输出较准确的预测分类结果,而且第二分类预测模型还能够基于与第一样本集具有相同来源的目标数据进行分类预测,输出较准确的预测分类结果。
170.在通过第二分类预测模型进行分类预测时,首先将目标数据输入第二编码子模型进行编码,获得第二编码子模型输出的向量,之后将第二编码子模型输出的向量输入第一映射子模型进行映射,获得第一映射子模型输出的向量,之后将第一映射子模型输出的向量输入第二分类子模型,获得第二分类子模型输出的预测分类结果。
171.需要说明的是,上述各个方法实施例中所有的可选技术方案,可以采用任意结合形成本技术的可选实施例,在此不再一一赘述。
172.为了便于理解,下面以训练可基于病历中主诉文本进行分类预测的分类预测模型为例,对本技术实施例提供的分类预测模型的训练方法进行详细说明。
173.病历数据中的主诉文本是指患者到医院就医时,医生根据对患者的问诊结果,通过简洁的文字记录患者的主要症状和需求,比如“感冒后恶心周余”。由于主诉文本为文本数据,在模型训练过程中无需对病历做结构化等复杂处理。
174.假设有包含n个任务的任务序列定义为{t1,t2,t3,
…
,tn},其中每一个任务tk都是一个有监督的疾病预测分类任务,但是每一个任务中的疾病类别是不同的。图4是本技术实施例提供的一种分类预测模型的训练过程的示意图,参见图4,第一个任务的数据中包含有描述鼻炎、腹泻等疾病的文本内容,而第二个任务的数据包括描述痤疮、龋齿等疾病的文本内容。对于任务序列的划分根据不同的应用场景具有相对应的划分方法,例如在基层司辅诊的场景中,考虑基层医院和重点医院的接诊病例存在分布上的差异,以疾病的严重程度(常见疾病对应基层医院,重难疾病对应重点医院)来划分不同任务。
175.传统的机器学习模型在以序列的形式学习多个任务时,会出现各种遗忘问题,即在之前任务的表现大幅度下降。本技术实施例仅训练一个预测模型,并依次序在不同任务的数据上进行训练,即在第k个任务的数据进行训练时,预测模型的模型参数基于tk的数据做优化,但同时保持在前k-1个任务上的表现。因此将所训练预测模型在所有任务上的平均准确率,作为该预测模型的评价指标,如下公式所示:
[0176][0177]
其中,acc
f,k
用于表征所训练的分类预测模型f在任务k上的准确率,k用于表征任
务的数量,用于表征所训练的分类预测模型在所有任务上的平均准确率。
[0178]
在对每一个任务进行训练时,首先对病历中的主诉文本进行分词并输入bilstm模型,该bilstm模型对主诉文本同时进行两个方向的编码,并将在两个方向上的编码拼接起来作为该主诉文本的向量表示。随着训练迭代次数的增加,每个任务都会形成各自的高维表示空间。每个任务的表示空间都具有独特性,在k任务上重新优化的模型参数并不能保留k-1任务的文本特征,因此需要训练一个映射模块来对各个任务的文本特征做统一,以适应所有k个任务。
[0179]
图5是本技术实施例提供的一种主诉文本的示意图,参见图5,对于属于两个任务的两种疾病肺炎和肺癌的描述文本内容,这两种疾病共有咳嗽、咳痰的症状属性,经过映射模块的统一,类似文本的特征被整合到统一的肺疾病的表示空间中。同理,在一个完整的医疗疾病体系下,大多数文本特征会被映射到一个通用的表示空间,而不是仅保留各自在不同疾病中的特定表示。
[0180]
对于包括有映射模块的分类预测模型,分类预测模型在编码层将主诉文本编码为向量,映射模块将编码层编码出的向量映射为统一高维空间中的向量,该过程可以表示为如下公式:
[0181][0182]
其中,xc用于表征输入的样例,hc用于表征样例经过编码层之后的向量,zc用于表征经过编码及映射后的向量,用于表征所训练分类预测模型中的编码子模型,用于表征所训练预测模型中的映射子模型,即映射模块。
[0183]
在训练分类预测模型的过程中,分类预测模型会保留每一个任务的少量数据作为记忆,也作为映射模块训练的目标。所保留的数据不仅以原始文本的形式保留,同时也保留在各自任务向量空间的表征形式。
[0184]
在针对每个任务进行训练时,首先从完整数据集中取出一部分作为训练集,另外从完整数据集中随机选取数量较少的子集,用于映射模型的训练。对于第k个任务,随机选取的子集为rk,rk在第k个任务训练结束后的高维向量表示定义为e
k’,同理前k-1个任务在第k个任务训练结束后,所选取的子集和对应高维向量表示分别是{r1,r2,r3,
…
,r
k-1
}和{e1’
,e2’
,e3’
,
…
,e
k-1’}。在对第k 1个任务训练结束后,{r1,r2,r3,
…
,rk}被输入编码层获取对应高维向量{e1,e2,e3,
…
,ek},则以上几组高维向量构成了针对映射层的训练数据(x,y),即{(e1,e1’
),(e2,e2’
),(e3,e3’
),
…
,(ek,e
k’)}。
[0185]
综上所述,对于映射层的训练,以前一个任务的高维向量为目标,以将新任务上优化过的编码结果映射到一个兼容之前所有任务的高维空间。
[0186]
分类预测模型的训练分为两步,第一步是对编码层进行训练,第二步是对映射层进行训练。将训练分为两步,可以保证模型在当前任务和之前所有任务上的表现。示例性地,第一步针对编码层的训练,是为了让分类预测模型从当前任务的数据中学习其特定语境下的语言特征,而第二步以前一时刻的向量表征作为目标,以得到通用于所有任务的向量表示。
[0187]
在第一步训练时,损失函数基于最后一步分类器的结果设计,经过映射层处理之
后向量表示作为分类器的输入,在分类器中利用线性层和softmax函数进行分类操作,可得到如下函数:
[0188][0189]
其中,x用于表征输入的原始数据,z用于表征编码及映射后的向量,y用于表征分类的标签,p(y=l|x;w
clf
)用于表征x对应分类为l的概率,用于表征利用线性层和softmax函数训练出的模型函数。
[0190]
在该步骤的损失函数为:
[0191][0192]
其中,用于表征基于编码及映射后的向量zi所获得的预测结果,与标签yi之间的差值,用于表征编码子模型对原始数据进行编码的初始模型参数,用于表征bilstm模型的模型参数,用于表征映射子模型的模型参数,w
clf
用于表征分类子模型的模型参数。在对该函数做最小化的时候,将映射层参数从参数集合中排除。
[0193]
在第二步训练时,模型只更新映射层对应参数,具体的损失函数如下:
[0194][0195]
其中,α用于表征预设的超参数控制对于向量的映射力度,用于表征映射层函数。
[0196]
图6是本技术实施例提供的一种预测结果对比示意图,参见图6,曲线q2对应ewc预测模型,采用对损失设置约束的方案避免灾难性遗忘,即在对每个任务做训练时,ewc预测模型会对损失函数加正则项,以限制模型中的参数往兼容所有任务的方向做优化。曲线q3对应agem预测模型,在每一个参数的梯度上做二次规划,将当前模型在之前任务上的损失同时记入此次更新的梯度中。曲线q4对应的预测模型,直接在新任务上做更新,不采用任何避免遗忘的策略。曲线q1对应于通过本技术实施例所提供方法训练的预测模型。需要说明的是,图6所示坐标系的横坐标为任务的个数,纵坐标为分类模型的准确率。
[0197]
参见图6,通过本技术实施例所提供方法训练的分类预测模型,在表现上优于其他三种方案。ewc在nlp任务中表现较差,因为ewc的方案仅对损失做约束,而在nlp任务以及常用的神经网络(rnn,lstm)中,损失以及梯度随着时序的回传会逐渐减弱,所以在损失层面的约束很难作用于nlp相关神经网络的优化。本技术实施例提供的分类预测模型的训练方法,直接对于文本向量表示做映射,避开了nlp任务中常出现的梯度消失问题。对于agem模型,虽然其在梯度层面做约束的方案也较好的解决了上述ewc面临的问题,但由于二次规划的引入,在模型参数量较大时,agem的计算复杂度会显著提升,这极大的限制了在实际场景
中的应用价值。本技术实施例提供的分类预测模型的训练方法,应用较轻量的模型,对于向量空间的映射也无需过多的算力,在医疗领域具有更优的表现。
[0198]
本技术实施例提供的分类预测模型的训练方法,仅需病历数据,以主诉文本作为输入,对于数据的需求较低。在所训练的分类预测模型接入新医院或迭代版本时,仅需在新数据上进行训练,无需保留大量相关数据,甚至可以在数据不出院的前提下完成分类预测模型的训练,从而能够满足医院对于病患隐私进行保护的需求。在接入新医院时,不需要对分类预测模型的模型结构进行调整,也不如投入热力和时间成本对模型进行大规模的重新训练,仅需要在新医院的数据集上作进一步优化即可,从而能够降低成本。
[0199]
图7是本技术实施例提供的一种分类预测方法的流程图,参见图7,该分类预测方法包括:
[0200]
701、获取待进行结果预测的目标数据。
[0201]
由于后续需要基于第二分类预测模型对目标数据进行结果预测,第二分类预测模型通过第二样本集训练获得,第二分类预测模型中的第二编码子模型能够识别第二样本集中样本的数据类型,并将第二样本集中的样本编码成相应的向量,为了保证输入的目标数据能够被第二编码子模型编码成相应的向量,目标数据应与第一样本集和第二样本集中的样本具有相同的数据类型。比如,第一样本集和第二样本集中的样本为用于描述个体属性的文本数据,则目标数据也为用于描述个性属性的文本数据。
[0202]
在一种可能的实现方式中,由于第二分类预测模型是通过第二样本集训练获得的,而相同来源的数据通常具有相同的数据格式,为了保证第二分类预测模型对目标数据进行结果预测的准确性,目标数据与第二样本集具有相同的来源。比如,第一样本集中的样本均来自于单位a,第二样本集中的样本均来自于单位b,第一样本集和第二样本集中的样本均为用于描述个体属性的文本数据,但是来自于单位a和单位b的样本的数据格式并不完全相同。例如,文本数据中个体属性的排序、命名等不同,通过第二样本集训练获得第二分类预测模型后,单位b通过第二分类预测模型进行结果预测,后续将单位b产生或获取到的目标数据输入第二分类预测模型进行结果预测,由于目标数据与第二样本集中的样本具有相同的数据格式,从而能够进一步保证预测分类结果的准确性。
[0203]
702、获取第二分类预测模型。
[0204]
第二分类预测模型包括第二编码子模型、第一映射子模型和第二分类子模型,第二分类预测模型基于第二样本集和第一分类预测模型得到,第一分类预测模型通过第一样本集进行训练得到,第一分类预测模型包括第一编码子模型和第一分类子模型,第一映射子模型对第一向量进行映射所获得的第三向量与第二向量的差值小于损失阈值,第一向量由第二编码子模型对映射样本集进行编码获得,第二向量通过第一编码子模型对映射样本集进行编码获得。
[0205]
在一种可能的实现方式中,第二分类预测模型为上述任一分类预测模型的训练方法实施例中所训练出的第二分类预测模型。
[0206]
703、通过第二编码子模型,对目标数据进行编码,获得第一目标向量。
[0207]
在获取到的第二分类预测模型和目标数据后,将目标数据输入第二分类预测模型中的第二编码子模型,第二编码子模型对目标数据进行编码,获得第二编码子模型输出的第一目标向量。
[0208]
在一种可能的实现方式中,目标数据为用于描述个体属性的文本数据,此时第二编码子模型为bilstm模型,通过第二编码子模型对目标数据进行编码时,首先目标数据进行分词处理,之后将获得的分词输入第二编码子模型,第二编码子模型对目标数据进行两个方向的编码,并将两个方向上的编码拼接起来作为第一目标向量。
[0209]
704、通过第一映射子模型,将第一目标向量映射为第二目标向量。
[0210]
在获取到第二编码子模型输出的第一目标向量后,将获取到的第一目标向量输入第一映射子模型,第一映射子模型将第一目标向量映射为第二目标向量。
[0211]
705、将第二目标向量输入第二分类子模型,获得第二分类子模型输出的第二预测分类结果,将第二预测分类结果作为目标数据的分类结果。
[0212]
示例性地,第一映射子模型将第一目标向量映射为第二目标向量后,将第二目标向量输入第二分类子模型,第二分类子模型基于第二目标向量输出预测分类结果,预测分类结果即为目标数据所属类别的标签。
[0213]
比如,目标数据为描述汽车厂所生产汽车出现缺陷的文本数据,将第二目标向量输入第二分类子模型后,第二分类子模型输出的预测解结果为汽车生产线的故障位置。
[0214]
本技术实施例提供的方案,第二分类预测模型基于第二样本集和第一分类预测模型得到,第二分类预测模型包括的第二编码子模型能够将映射样本集编码成第一向量,第一分类预测模型包括的第一编码子模型能够将映射样本集编码成第二向量,而第二分类预测模型包括的第一映射子模型能够将第一向量映射为第三向量,第二向量与第三向量的差值小于损失阈值,由于第二分类预测模型所包括的第一映射子模型,使得通过第二样本集对第一分类预测模型进行优化获得第二分类预测模型的同时,第二分类预测模型在第一样本集上的表现不会下降,因此通过第二分类预测模型进行分类预测时,能够提高预测分类结果的准确性。
[0215]
需要说明的是,上述各个方法实施例中所有的可选技术方案,可以采用任意结合形成本技术的可选实施例,在此不再一一赘述。
[0216]
图8是本技术实施例提供的一种分类预测模型的训练装置的结构图,参见图8,该装置包括:
[0217]
第一获取模块801,用于获取通过第一样本集进行训练所获得的第一分类预测模型,第一分类预测模型包括第一编码子模型和第一分类子模型;
[0218]
编码训练模块802,用于通过第二样本集对第一编码子模型进行训练,获得第二编码子模型,第二样本集与该第一样本集从多媒体资料中提取得到,且第二样本集与第一样本集的来源不同;多媒体资料包括文本、视频、图片或音频中的至少一种数据;
[0219]
第一编码模块803,用于通过第二编码子模型对映射样本集进行编码,获得第一向量;
[0220]
映射训练模块804,用于通过该第一向量和第二向量训练第一映射子模型,该第二向量通过该第一编码子模型对该映射样本集进行编码获得,该第二向量与第三向量的差值小于损失阈值,该第三向量通过该第一映射子模型对该第一向量进行映射获得;
[0221]
第一编码模块803,还用于通过第二编码子模型将第二样本集编码为第四向量;
[0222]
第一映射模块805,用于通过第一映射子模型,将第四向量映射为第五向量;
[0223]
分类训练模块806,用于通过第五向量对第一分类子模型进行训练,获得第二分类
子模型;
[0224]
构建模块807,用于通过第二编码子模型、第一映射子模型和第二分类子模型构建第二分类预测模型,第二分类预测模型用于对待进行结果预测的目标数据进行分类预测。
[0225]
本技术实施例提供的装置,编码训练模块通过第二样本集对第一编码子模型进行训练,获得第二编码子模型后,映射训练模块根据第一编码子模型和第二编码子模型对相同映射样本集的编码结果,训练第一映射子模型,第一编码子模型和第二编码子模型将同一样本编码成向量后,第一映射子模型能够将第二编码子模型编码出的向量映射为另一个向量,而第一映射子模型映射出的向量与第一编码子模型所编码出向量的差值小于损失阈值,即基于第二样本集对第一分类预测模型进行优化获得第二分类预测模型后,第二分类预测模型仍保留在第一样本集中学习到的知识,因此能够避免分类预测模型的训练过程中出现灾难性遗忘,从而能够提高所训练的分类预测模型的准确性。
[0226]
在一种可能的实现方式中,编码训练模块802,用于执行如下处理:
[0227]
通过该第一编码子模型对该第二样本集进行编码,获得第六向量;
[0228]
获取该第一分类子模型基于该第六向量,输出的第一预测分类结果;
[0229]
根据该第一预测分类结果,对该第一编码子模型的模型参数进行迭代更新,直至该第一预测分类结果与该第二样本集的真实分类结果相匹配,获得该第二编码子模型。
[0230]
在一种可能的实现方式中,映射样本集包括第一样本集中的全部或部分样本,映射样本集从第一存储空间读取,且映射样本集在训练获得第一分类预测模型后被存储到第一存储空间。
[0231]
在一种可能的实现方式中,第二向量从第二存储空间读取,且第二向量在训练获得第一分类预测模型后被存储到第二存储空间。
[0232]
在一种可能的实现方式中,第一样本集包括至少两个子样本集,不同的子样本集的来源不同;第一分类预测模型通过至少两个子样本集进行顺序训练获得,通过每个子样本集训练第一分类预测模型的方法,与通过第二样本集训练第二分类预测模型的方法相同。
[0233]
在一种可能的实现方式中,第一分类预测模型还包括第二映射子模型;
[0234]
映射训练模块804,用于将第一向量作为输入对第二映射子模型进行迭代训练,直至第二映射子模型输出的第三向量与第二向量的差值小于损失阈值。
[0235]
在一种可能的实现方式中,映射训练模块804,用于执行如下处理:
[0236]
将第一向量输入第二映射子模型,获得第二映射子模型输出的第三向量;
[0237]
将第二向量和第三向量输入损失函数;
[0238]
对第二映射子模型的模型参数进行迭代更新,使损失函数最小化,直至损失函数输出最小值时,获得第一映射子模型,损失函数输出的最小值小于损失阈值。
[0239]
在一种可能的实现方式中,映射样本集包括至少两个子映射样本集,每个子映射样本集对应一个子样本集,不同的子映射样本集对应不同的子样本集,子映射样本集包括相对应子样本集中的全部或部分样本。
[0240]
在一种可能的实现方式中,图9是本技术实施例提供的另一种分类预测模型训练装置的示意图,参见图9,该装置还包括:
[0241]
模型评价模块808,用于获取第二分类预测模型对每个子样本集进行预测的第一
准确率,获取第二分类预测模型对第二样本集进行预测的第二准确率,将各第一准确率和第二准确率的平均值,确定为第二分类预测模型的预测准确率。
[0242]
在本技术实施例中,由于第二分类预测模型在从第二样本集中学到新知识后,之前在第一样本集所学到的知识并不会被覆盖,因此第二分类预测模型能够对第一样本集和第二样本集中的样本进行预测,将第一准确率和第二准确率的平均值作为第二分类预测模型的预测准确率,可以更加客观的评价第二分类预测模型进行分类预测的准确性。
[0243]
在一种可能的实现方式中,第一编码子模型包括双向长短期记忆网络bilstm模型。
[0244]
需要说明的是,本技术实施例所提供分类预测模型训练装置包括的各模块,可以执行上述分类预测模型的训练方法实施例中的处理,因此各模块的具体处理过程可参见上述分类预测模型的训练方法实施例中的描述,在此不再进行赘述。
[0245]
图10是本技术实施例提供的一种分类预测装置的结构图,参见图10,该装置包括:
[0246]
第二获取模块1001,用于获取待进行结果预测的目标数据;
[0247]
第三获取模块1002,用于获取第二分类预测模型,第二分类预测模型包括第二编码子模型、第一映射子模型和第二分类子模型,第二分类预测模型基于第二样本集和第一分类预测模型得到,第一分类预测模型通过第一样本集进行训练得到,第一分类预测模型包括第一编码子模型和第一分类子模型,第一映射子模型对第一向量进行映射获得的第二向量,与第一编码子模型对映射样本集进行编码获得的第三向量的差值小于损失阈值,第一向量通过第二编码子模型对映射样本集进行编码获得;第二样本集与第一样本集从多媒体资料中提取得到,且第一样本集与该第二样本集的来源不同,多媒体资料包括文本、视频、图片或音频中的至少一种数据;
[0248]
第二编码模块1003,用于通过第二编码子模型,对目标数据进行编码,获得第一目标向量;
[0249]
第二映射模块1004,用于通过第一映射子模型,将第一目标向量映射为第二目标向量;
[0250]
分类模块1005,用于将第二目标向量输入第二分类子模型,获得第二分类子模型输出的第二预测分类结果,将第二预测分类结果作为目标数据的分类结果。
[0251]
在本技术实施例中,第二编码模块1003通过第二编码子模型对目标数据进行编码,获得第一目标向量后,第二映射模块1004通过第一映射子模型将第一目标向量映射为第二目标向量,由于第一编码子模型和第二编码子模型将同一样本编码成向量后,第一映射子模型能够将第二编码子模型编码出的向量映射为另一个向量,而第一映射子模型映射出的向量与第一编码子模型所编码出向量的差值小于损失阈值,即基于第二样本集对第一分类预测模型进行优化获得第二分类预测模型后,第二分类预测模型仍保留在第一样本集中学习到的知识,因此能够避免分类预测模型的训练过程中出现灾难性遗忘,从而能够提高所训练的分类预测模型的准确性。
[0252]
需要说明的是,本技术实施例所提供分类预测装置包括的各模块,可以执行上述分类预测方法实施例中的处理,因此各模块的具体处理过程可参见上述分类预测方法实施例中的描述,在此不再进行赘述。
[0253]
本技术实施例提供了一种计算机设备,用于执行上述各实施例提供的方法,该计
算机设备可以实现为终端或者服务器,下面对终端的结构进行介绍:
[0254]
图11是本技术实施例提供的一种终端的结构示意图。该终端1100可以是:智能手机、平板电脑、笔记本电脑或台式电脑。终端1100还可能被称为用户设备、便携式终端、膝上型终端、台式终端等其他名称。
[0255]
通常,终端1100包括有:一个或多个处理器1101和一个或多个存储器1102。
[0256]
处理器1101可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器1101可以采用dsp(digital signal processing,数字信号处理)、fpga(field-programmable gate array,现场可编程门阵列)、pla(programmable logic array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器1101也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称cpu(central processing unit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器1101可以在集成有gpu(graphics processing unit,图像处理器),gpu用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器1101还可以包括ai(artificial intelligence,人工智能)处理器,该ai处理器用于处理有关机器学习的计算操作。
[0257]
存储器1102可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器1102还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器1102中的非暂态的计算机可读存储介质用于存储至少一个计算机程序,该至少一个计算机程序用于被处理器1101所执行以实现本技术中方法实施例提供的分类预测模型的训练方法或分类预测方法。
[0258]
在一些实施例中,终端1100还可选包括有:外围设备接口1103和至少一个外围设备。处理器1101、存储器1102和外围设备接口1103之间可以通过总线或信号线相连。各个外围设备可以通过总线、信号线或电路板与外围设备接口1103相连。具体地,外围设备包括:射频电路1104、显示屏1105、摄像头组件1106、音频电路1107、定位组件1108和电源1109中的至少一种。
[0259]
外围设备接口1103可被用于将i/o(input/output,输入/输出)相关的至少一个外围设备连接到处理器1101和存储器1102。在一些实施例中,处理器1101、存储器1102和外围设备接口1103被集成在同一芯片或电路板上;在一些其他实施例中,处理器1101、存储器1102和外围设备接口1103中的任意一个或两个可以在单独的芯片或电路板上实现,本实施例对此不加以限定。
[0260]
射频电路1104用于接收和发射rf(radio frequency,射频)信号,也称电磁信号。射频电路1104通过电磁信号与通信网络以及其他通信设备进行通信。射频电路1104将电信号转换为电磁信号进行发送,或者,将接收到的电磁信号转换为电信号。可选地,射频电路1104包括:天线系统、rf收发器、一个或多个放大器、调谐器、振荡器、数字信号处理器、编解码芯片组、用户身份模块卡等等。
[0261]
显示屏1105用于显示ui(user interface,用户界面)。该ui可以包括图形、文本、图标、视频及其它们的任意组合。当显示屏1105是触摸显示屏时,显示屏1105还具有采集在显示屏1105的表面或表面上方的触摸信号的能力。该触摸信号可以作为控制信号输入至处理器1101进行处理。此时,显示屏1105还可以用于提供虚拟按钮和/或虚拟键盘,也称软按
钮和/或软键盘。
[0262]
摄像头组件1106用于采集图像或视频。可选地,摄像头组件1106包括前置摄像头和后置摄像头。通常,前置摄像头设置在终端的前面板,后置摄像头设置在终端的背面。
[0263]
音频电路1107可以包括麦克风和扬声器。麦克风用于采集用户及环境的声波,并将声波转换为电信号输入至处理器1101进行处理,或者输入至射频电路1104以实现语音通信。
[0264]
定位组件1108用于定位终端1100的当前地理位置,以实现导航或lbs(location based service,基于位置的服务)。
[0265]
电源1109用于为终端1100中的各个组件进行供电。电源1109可以是交流电、直流电、一次性电池或可充电电池。
[0266]
在一些实施例中,终端1100还包括有一个或多个传感器1110。该一个或多个传感器1110包括但不限于:加速度传感器1111、陀螺仪传感器1112、压力传感器1113、指纹传感器1114、光学传感器1115以及接近传感器1116。
[0267]
加速度传感器1111可以检测以终端1100建立的坐标系的三个坐标轴上的加速度大小。
[0268]
陀螺仪传感器1112可以终端1100的机体方向及转动角度,陀螺仪传感器1112可以与加速度传感器1111协同采集用户对终端1100的3d动作。
[0269]
压力传感器1113可以设置在终端1100的侧边框和/或显示屏1105的下层。当压力传感器1113设置在终端1100的侧边框时,可以检测用户对终端1100的握持信号,由处理器1101根据压力传感器1113采集的握持信号进行左右手识别或快捷操作。当压力传感器1113设置在显示屏1105的下层时,由处理器1101根据用户对显示屏1105的压力操作,实现对ui界面上的可操作性控件进行控制。
[0270]
指纹传感器1114用于采集用户的指纹,由处理器1101根据指纹传感器1114采集到的指纹识别用户的身份,或者,由指纹传感器1114根据采集到的指纹识别用户的身份。
[0271]
光学传感器1115用于采集环境光强度。在一个实施例中,处理器1101可以根据光学传感器1115采集的环境光强度,控制显示屏1105的显示亮度。
[0272]
接近传感器1116用于采集用户与终端1100的正面之间的距离。
[0273]
本领域技术人员可以理解,图11中示出的结构并不构成对终端1100的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。
[0274]
上述计算机设备还可以实现为服务器,下面对服务器的结构进行介绍:
[0275]
图12是本技术实施例提供的一种服务器的结构示意图,该服务器1200可因配置或性能不同而产生比较大的差异,可以包括一个或多个处理器(central processing units,cpu)1201和一个或多个的存储器1202,其中,一个或多个存储器1202中存储有至少一条计算机程序,至少一条计算机程序由一个或多个处理器1201加载并执行以实现上述各个方法实施例提供的方法。当然,该服务器1200还可以具有有线或无线网络接口、键盘以及输入输出接口等部件,以便进行输入输出,该服务器1200还可以包括其他用于实现设备功能的部件,在此不做赘述。
[0276]
在示例性实施例中,还提供了一种计算机可读存储介质,例如包括计算机程序的存储器,上述计算机程序可由处理器执行以完成上述实施例中的分类预测模型的训练方法
或分类预测方法。例如,该计算机可读存储介质可以是只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、只读光盘(compact disc read-only memory,cd-rom)、磁带、软盘和光数据存储设备等。
[0277]
在示例性实施例中,还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括程序代码,该程序代码存储在计算机可读存储介质中,计算机设备的处理器从计算机可读存储介质读取该程序代码,处理器执行该程序代码以完成上述实施例中的分类预测模型的训练方法或分类预测方法。
[0278]
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,该程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0279]
上述仅为本技术的可选实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。