基于改进transformer的强化学习电熔镁炉工况识别方法
技术领域
1.本发明涉及一种基于改进transformer的强化学习电熔镁炉工况识别方法,属于人工智能技术领域。
背景技术:
2.电熔镁砂(又称电熔镁)是最轻的金属结构材料,具有耐压强度高、抗氧化耐腐蚀性强、绝缘性强、耐高温(可承受两千多度的高温而不产生性能变化)等一系列优点,主要应用领域包括航空航天、核子熔炉、电子电器等。由于在电熔镁炉烧制电熔镁砂的过程中,原料杂质多易导致异常工况,需要现场对电熔镁炉进行观测以便及时调节,以降低产品能耗,减少资源浪费,如何准确把握电熔镁炉的运行状态信息是完成对整个电熔镁生产的优化与决策的基础环节与关键步骤。
3.目前电熔镁炉欠烧工况的识别手段主要依靠操作人员亲临生产现场对电熔镁炉进行观测,并凭借其经验知识进行判断。然而,受制于人的经验、责任心和劳动强度等主观因素,以及欠烧工况初期烧红区域目标小识别方法鲁棒性不强的客观因素,难以满足智能巡检的运维需求。
技术实现要素:
4.本发明是为了解决上述背景技术中的存在的问题,提出一种基于改进transformer的强化学习电熔镁炉工况识别方法,以期能获取深层图像特征,提高不同状态下电熔镁炉欠烧工况的检测准确度,从而满足电熔镁炉工况识别快速化准确化的实际需求。
5.本发明为解决技术问题采用如下技术方案:
6.本发明一种基于改进transformer的强化学习电熔镁炉工况识别方法的特点在于,是按以下步骤进行:
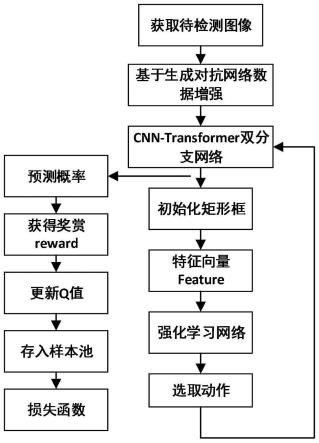
7.步骤1:获取带类别的原始目标图像集并输入基于生成对抗网络的图像增强模型中进行数据增强,得到增强后的目标图像集,为增强后的目标图像集中的图像添加类别后,与原始目标图像集合并为训练集b;
8.步骤2:建立基于改进transformer的强化学习网络,包括:用于特征提取的cnn-transformer双分支异构网络、用于生成动作策略的强化学习网络;
9.所述cnn-transformer双分支异构网络包括:cnn卷积神经网络分支、transformer网络分支、双向特征交互模块和scn分类器组成;
10.所述cnn卷积神经网络分支是基于resnet18网络构建的分支,并包含x个卷积块,分别为convblock1,...,convblock
x
,...,convblock
x
;其中,convblock
x
表示第x级卷积块;
11.所述第x级卷积块convblock
x
依次由通道数为m的点卷积、通道数为m的二维卷积层和通道数为4m的点卷积组成,其中,每一个卷积后连接有一个批量归一化层,所述第x级卷积块convblock
x
的输入直接与通道数为4m的点卷积的输出进行跳跃连接后再连接有
relu激活函数;
12.所述transformer网络分支是基于vit网络构建的分支,并包含y个transformer块,分别为transformer1,...,transformery,...,transformery;其中,transformery表示第y级transformer块;
13.所述第y级transformer块transformery依次由第一个层归一化层、多头注意力机制层、第二个层归一化层以及多层感知机组成,其中,第一个层归一化层的输入与所述多头注意力机制层的输出进行跳跃连接,第二个层归一化层的输入与所述多层感知机的输出进行跳跃连接;
14.所述双向特征交互模块是由点卷积层和归一化层组成;
15.所述第x个卷积块convblock
x
的输出与所述双向特征交互模块的输入相连;所述双向特征交互模块的输出与所述第y个卷积块convblocky的输入相连;
16.所述第y个卷积块convblocky的输出与所述双向特征交互模块的输入相连,所述双向特征交互模块的输出与所述第x个卷积块convblock
x
的输入相连;
17.所述强化学习网络由全连接层组成;
18.步骤3、将所述训练集b输入到cnn-transformer双分支异构网络中得到特征feature和分类概率pred;
19.步骤3.1、在所述训练集b中的任意一幅图像上随机初始化一个矩形框box;
20.步骤3.2、将矩形框box中的图像上采样到原始图像的尺寸,从而得到处理后的图像image;
21.步骤3.3、将处理后的图像image作为cnn-transformer双分支异构网络的输入,并同时输入到cnn卷积神经网络分支和transformer网络分支中,并在所述双向特征交互模块进行双向信息交互,得到特征feature,并输入到所述scn分类器中,从而得到分类概率pred;
22.步骤4、将所述cnn-transformer双分支异构网络输出的特征feature输入到强化学习网络进行训练;
23.步骤4.1、定义动作空间的动作类型包括有m种动作:每种动作是以矩形框的中心点为基准点进行移动,且动作移动的幅度为当前的矩形框box的α倍,α《1;
24.步骤4.2、从动作空间的中选择一种动作a改变矩形框大小并输入所述cnn-transformer双分支异构网络中,输出预测概率preda;
25.根据训练集b的所有类别c、所选一种动作a和预测概率preda按式(1)设定奖励reward:
26.reward=sign(preda(c)-pred(c))
ꢀꢀꢀ
(1)
27.式(1)中,preda(c)表示所有类别c在选定做动作a下的预测概率,pred(c)表示所有类别c在未选定动作下的预测概率;
28.步骤4.3、将所述特征feature作为当前状态s,输入到所述强化学习模型中,并根据式(2)得到动作空间中动作a下的q值q(s,a);
[0029][0030]
式(2)中,γ
t
为t时刻的学习率,reward(s
t
,a
t
)为t时刻在状态s
t
下采取动作a
t
获得
transformer双分支异构网络、用于生成动作策略的强化学习网络;
[0051]
cnn-transformer双分支异构网络包括:cnn卷积神经网络分支、transformer网络分支、双向特征交互模块和scn分类器组成,cnn-transformer的双分支异构网络结构图如图2所示;
[0052]
cnn卷积神经网络分支是基于resnet18网络构建的分支,并包含x个卷积块,分别为convblock1,...,convblock
x
,...,convblock
x
;其中,convblock
x
表示第x级卷积块;本实施例中,取卷积块个数x=12;
[0053]
第x级卷积块convblock
x
依次由通道数为m的点卷积、通道数为m的二维卷积层和通道数为4m的点卷积组成,其中,每一个卷积后连接有一个批量归一化层,第x级卷积块convblock
x
的输入直接与通道数为4m的点卷积的输出进行跳跃连接后再连接有relu激活函数;本实施例中,第x级卷积块convblock
x
中,m=64,点卷积的卷积核大小为1
×
1,二维卷积层的卷积核大小为3
×
3,convblock结构如图3所示;
[0054]
transformer网络分支是基于vit网络构建的分支,并包含y个transformer块,分别为transformer1,...,transformery,...,transformery;其中,transformery表示第y级transformer块;本实施例中,取transformer块个数y=12;
[0055]
第y级transformer块transformery依次由第一个层归一化层、多头注意力机制层、第二个层归一化层以及多层感知机组成,其中,第一个层归一化层的输入与多头注意力机制层的输出进行跳跃连接,第二个层归一化层的输入与多层感知机的输出进行跳跃连接;本实施例中,transformer块结构如图4所示;
[0056]
双向特征交互模块是由点卷积层和归一化层组成;本实施例中,点卷积大小为1
×
1;
[0057]
第x个卷积块convblock
x
的输出与双向特征交互模块的输入相连;双向特征交互模块的输出与第y个卷积块convblocky的输入相连;
[0058]
第y个卷积块convblocky的输出与双向特征交互模块的输入相连,双向特征交互模块的输出与第x个卷积块convblock
x
的输入相连;
[0059]
强化学习网络由全连接层组成;
[0060]
步骤3、将训练集b输入到cnn-transformer双分支异构网络中得到特征feature和分类概率pred;
[0061]
步骤3.1、在训练集b中的任意一幅图像上随机初始化一个矩形框box;
[0062]
步骤3.2、将矩形框box中的图像上采样到原始图像的尺寸,从而得到处理后的图像image;
[0063]
步骤3.3、将处理后的图像image作为cnn-transformer双分支异构网络的输入,并同时输入到cnn卷积神经网络分支和transformer网络分支中,并在双向特征交互模块进行双向信息交互,得到特征feature,并输入到scn分类器中,从而得到分类概率pred;
[0064]
步骤4、将cnn-transformer双分支异构网络输出的特征feature输入到强化学习网络进行训练;
[0065]
步骤4.1、定义动作空间的动作类型包括有m种动作:每种动作是以矩形框的中心点为基准点进行移动,且动作移动的幅度为当前的矩形框box的α倍,α《1;本实施例中,α=1/3,m=5,有5种动作包括:上移、下移、左移、右移、终止;
[0066]
步骤4.2、从动作空间的中选择一种动作a改变矩形框大小并输入cnn-transformer双分支异构网络中,输出预测概率preda;
[0067]
根据训练集b的所有类别c、所选一种动作a和预测概率preda按式(1)设定奖励reward:
[0068]
reward=sign(preda(c)-pred(c))
ꢀꢀ
(1)
[0069]
式(1)中,preda(c)表示所有类别c在选定做动作a下的预测概率,pred(c)表示所有类别c在未选定动作下的预测概率;
[0070]
步骤4.3、将特征feature作为当前状态s,输入到强化学习模型中,并根据式(2)得到动作空间中动作a下的q值q(s,a);本实施例中,动作的q值表示矩形框在采取此动作后位置发生改变,从而对预测概率产生影响,动作q值越大预测效果越好,反之动作q值越小预测效果越差;
[0071][0072]
式(2)中,γ
t
为t时刻的学习率,reward(s
t
,a
t
)为t时刻在状态s
t
下采取动作a
t
获得的奖励,t为预设的时间值;
[0073]
步骤4.4、利用贪婪策略选取动作空间中所有动作的最大q值,并按照最大q值的一个动作对矩形框的位置改变,得到新的矩形框box’;
[0074]
步骤4.5、将新的矩形框box’带入步骤3.2、步骤3.3的过程得到新的特征feature’和预测概率pred’;从而根据式(1)计算得采取q值最大的一个动作所产生的奖励值reward
′
;
[0075]
步骤4.6、通过式(3)定义选定动作a后的目标q值q
target
;
[0076]qtarget
=reward
′
γ*max(q(s,a))
ꢀꢀ
(3)
[0077]
式(3)中,q(s,a)表示当前状态s下采取动作a后产生的q值,γ*为学习率;
[0078]
步骤4.7、将新的特征feature’和目标q值q
target
作为样本存储到样本池中;
[0079]
步骤4.8、按照步骤3.1到步骤4.7的过程,并将新的特征feature’带入步骤4.3中进行处理,直到样本池中样本达到预设数量为止;
[0080]
步骤4.9、从样本池中随机选取特征和目标q值,并将特征输入到强化学习网络中得到q值q
eval
,利用式(4)所示的损失函数loss对强化学习网络进行反向传播,并更新网络参数,直到达到最大迭代次数为止,从而得到最优模型用于实现对电熔镁炉工况的识别;
[0081]
loss=(q
target-q
eval
)2ꢀꢀ
(4)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。