1.本发明涉及深度神经网络的卷积计算领域,尤其涉及一种基于反向流水线的异构训练加速器。
背景技术:
2.在诸如可学习的自动驾驶系统、智能家居等领域,往往要求部署了人工智能系统的移动端设备具有在动态环境中不断学习的能力。以往的云端训练、移动端推理的方式,因为其高延时、低隐私性,难以满足这种要求,因此在资源受限的移动端实现低功耗的本地训练加速很有必要。
3.在2018年可重构计算和fpga国际会议上发表的文章《a highly parallel fpga implementation of sparse neural network training》提出了一种流水线加速器,通过对稀疏率和网络结构的细粒度设计实现了稀疏网络训练时不同阶段的并行处理,但其采用的方案因为需要细粒度的设计,只适用于简单小巧的网络,如三层mlp网络,不适用与常用的大型网络。ieee固态电路杂志的文章《a pipelined direct feedback alignment-based deep neural network learning processor for fast online learning》提出了一种流水线训练加速器,依赖于dfa(direct feedback alignment)算法,解除了反向时的逐层限制,因此实现了bp和wg的并行处理,然而其采用的方案依赖于特殊的dfa算法,该算法会以损失精度为代价才能完成所有层的训练,只有在该算法只参与最后几层训练的情况下,才能保证精度,但预测同时也损失了训练效率。
技术实现要素:
4.本技术公开了一种基于反向流水线的异构训练加速器,该加速器对神经网络训练过程中的bp和wg过程采用了一种新的流水线并行处理的方式,该方式降低了系统延时,避免了数据在不同层级存储之间的额外传输,同时降低了系统功耗。支持反向流水线的异构架构设计可以实现对不同类型的计算单独优化,从而提高能耗比和加速比。
5.本技术公开了一种基于反向流水线的异构训练加速器,加速器包括数据模块、控制模块和计算模块。
6.计算模块包括前向反向计算核、wg计算核和归一池化计算核。
7.控制模块被配置为执行以下步骤:
8.控制前向反向计算核和归一池化计算核执行深度神经网络的ff阶段所对应的运算;
9.在深度神经网络的bp阶段,控制前向反向计算核从数据模块中获取当前卷积层的第一通道所对应的输入数据,执行对应的卷积运算,并控制所述归一池化计算核对所述卷积运算的结果进行处理,得到第一输出误差,并将第一输出误差传入wg计算核,当前卷积层为深度神经网络中任一网络层,第一通道为当前卷积层中任一卷积核所对应的计算通道;
10.控制wg计算核获取待与第一输出误差进行卷积的输入值,前一卷积层为当前卷积
层的前一网络层;
11.控制wg计算核根据第一输出误差以及输入值,执行深度神经网络的wg阶段所对应的卷积运算;
12.当bp阶段当前卷积层的所有所述第一通道计算完毕后,当前卷积层所有所述第一通道的所述第一输出误差组成所述当前卷积层的输出误差,并将所述输出误差传入上一卷积层的wg计算核。
13.在一种可实现方式中,前向反向计算核包括第一pe阵列和加法树,第一pe阵列包括多个第一pe。
14.第一pe,用于执行ff阶段和bp阶段的卷积运算,ff阶段和bp阶段中任一阶段的卷积运算在各个第一pe中平均分配。
15.加法树,用于对各个第一pe的计算结果进行加和运算,得到卷积计算结果。
16.wg计算核包括第二pe阵列,第二pe阵列包括多个第二pe。
17.第二pe,用于执行wg阶段的卷积运算,wg阶段的卷积运算在各个第二pe中平均分配。
18.在一种可实现方式中,第一pe的数量和第二pe的数量通过以下方式确定:
19.获取bp阶段的第一pe利用率以及wg阶段的第二pe利用率;
20.根据第一pe利用率、第二pe利用率、预设的权重稀疏率、预设的误差稀疏率、bp阶段每一卷积层的通道数以及wg阶段每一卷积层的通道数,确定第一pe的并行度与第二pe的并行度的比率;
21.根据第一pe的并行度与第二pe的并行度的比率,确定第一pe的数量和第二pe的数量。
22.在一种可实现方式中,获取bp阶段的第一pe利用率以及wg阶段的第二pe利用率,包括:
23.对异构训练加速器进行硬件仿真,获取bp阶段的第一pe利用率以及wg阶段的第二pe利用率。
24.在一种可实现方式中,根据第一pe利用率、第二pe利用率、预设的权重稀疏率、预设的误差稀疏率、bp阶段每一卷积通道中的计算量以及wg阶段每一卷积通道中的计算量,确定第一pe的并行度与第二pe的并行度的比率,包括:
25.通过以下公式确定第一pe的并行度与第二pe的并行度的比率:
[0026][0027]
其中,p
bp
表示第一pe的并行度,p
wg
表示第二pe的并行度,u
bp
表示第一pe利用率,u
wg
表示第二pe利用率,spe表示预设的误差稀疏率,m
bp
表示bp阶段每一卷积通道中的计算量,m
wg
表示wg阶段每一卷积通道中的计算量。
[0028]
在一种可实现方式中,数据模块包括总线矩阵模块和存储模块;
[0029]
存储模块,用于存储各个阶段中当前卷积层的输入数据和输出数据;
[0030]
总线矩阵模块,用于分配和调取存储模块中的输入数据。
[0031]
在一种可实现方式中,控制模块包括配置寄存器和总控制单元;
[0032]
配置寄存器,用于对数据和参数进行初始化配置;
[0033]
总控制单元,用于控制数据模块和计算模块执行对应的操作。
[0034]
本技术公开了一种基于反向流水线的异构训练加速器,该加速器包括数据模块、控制模块和计算模块;控制模块控制bp阶段前向反向计算核执行第一通道的卷积运算,第一通道为当前卷积层中任一卷积核所对应的计算通道,并控制所述归一池化计算核对卷积运算结果进行处理,得到当前卷积层的第一通道的第一输出误差,并将第一输出误差传入wg计算核,同时控制wg计算核根据第一输出误差以及前一卷积层的第一通道的输入值,执行深度神经网络的wg阶段所对应的卷积运算。该加速器bp和wg过程的流水线并行处理,降低了系统延时、避免了数据在不同层级存储的额外传输,降低了功耗,同时其异构架构设计可以实现对不同类型的计算单独优化,提高能耗比和加速比。
附图说明
[0035]
为了更清楚地说明本技术的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0036]
图1为本技术实施例的三个阶段计算示意图;
[0037]
图2为本技术实施例的顶层架构示意图;
[0038]
图3为本技术实施例的bpip设计示意图;
[0039]
图4为本技术实施例的bp和wg阶段并行示意图。
具体实施方式
[0040]
下面将详细地对实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同字母表示相同或相似的要素。以下实施例中描述的实施方式并不代表与本技术相一致的所有实施方式。仅是与权利要求书中所详述的、本技术的一些方面相一致的系统和方法的示例。
[0041]
需要说明的是,本技术中对于术语的简要说明,仅是为了方便理解接下来描述的实施方式,而不是意图限定本技术的实施方式。除非另有说明,这些术语应当按照其普通和通常的含义理解。
[0042]
为便于对申请的技术方案进行,以下首先在对本技术所涉及到的一些概念进行说明。
[0043]
卷积神经网络的训练一般包含ff(feed-forward,前向传播阶段)、bp(backward propagation,反向传播阶段)和wg(weight gradient generation,权重更新阶段)三个阶段的计算,其中ff过程对一批数据进行前向传播并得到它们的损失,bp过程通过对损失反向传播得到各个中间特征图的误差,wg过程利用中间特征的误差求出权重的梯度值及更新值,并对权重进行更新。
[0044]
以上三个阶段所涉及的具体计算如下:
[0045]
在ff阶段,前一卷积层的中间特征图a
l-1
被当前卷积层的权重w
l
卷积,并在与偏置b
l
相加后通过非线性函数σ产生当前卷积层的中间特征图。用z
l
表示卷积结果,*表示卷积运算,ff的计算可表示如下:
[0046]al
=σ(z
l
)=σ(w
l
*a
l-1
b
l
)
ꢀꢀꢀ
公式(1)
[0047]
bp的运算与ff类似,下一卷积层的误差δ
l 1
与该层转置后的权重w
l 1
卷积,得到当前卷积层的误差δ
l
,σ
′
(z
l
)表示非线性函数的导数,该计算用公式表达如下:
[0048]
δ
l
=rot180(w
l 1
)*δ
l 1
·
σ
′
(z
l
)
ꢀꢀꢀ
公式(2)
[0049]
wg将bp得到的当前卷积层误差δ
l
与上一卷积层的中间特征图a
l-1
卷积,得到当前卷积层权重w
l
的梯度,并用梯度对权重进行更新。用α表示学习率,wg用公式表示如下:
[0050][0051]
如图1示出了本技术实施例的三个阶段计算示意图。
[0052]
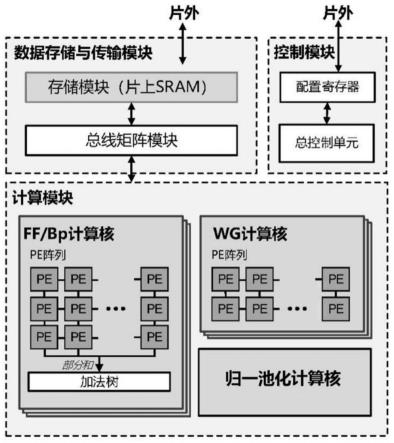
基于上述原理的一种加速器硬件实现,本技术实施例提供了一种基于反向流水线的异构训练加速器,如图2本技术实施例的顶层架构示意图所示,该加速器包括数据模块、控制模块和计算模块。
[0053]
计算模块包括前向反向计算核、wg计算核和归一池化计算核。
[0054]
具体地,前向反向计算核包括第一pe阵列和加法树,第一pe阵列包括多个第一pe。第一pe,用于执行ff阶段和bp阶段的卷积运算,值得说明的是,ff阶段和bp阶段中任一阶段的卷积运算在各个第一pe(processing unit,计算单元)中平均分配。加法树用于对各个第一pe的计算结果进行加和运算,得到卷积计算结果。
[0055]
另外,wg计算核包括第二pe阵列,第二pe阵列包括多个第二pe,第二pe用于执行wg阶段的卷积运算,值得说明的是,wg阶段的卷积运算在各个第二pe中平均分配。
[0056]
控制模块被配置为执行以下步骤:
[0057]
步骤一,控制所述前向反向计算核和所述归一池化计算核执行深度神经网络的ff阶段所对应的运算。
[0058]
在步骤一中,前向反向计算核用于执行ff和bp两个阶段的计算过程,其中,在整个卷积计算过程中,前向反向计算核先执行ff阶段的计算过程,此时,控制模块控制wg计算核处于低功耗闲置状态,可选地,采用时钟门控技术。
[0059]
步骤二,在深度神经网络的bp阶段,控制所述前向反向计算核从所述数据模块中获取当前卷积层的第一通道所对应的输入数据,执行对应的卷积运算,并控制归一池化计算核对卷积运算的结果进行处理,得到第一输出误差,并将所述第一输出误差传入所述wg计算核,当前卷积层为深度神经网络中任一网络层,第一通道为当前卷积层中任一卷积核所对应的计算通道。
[0060]
在步骤二中,前向反向计算和执行完ff阶段的计算过程后,开始执行bp阶段的计算过程,控制模块控制前向反向计算核从数据模块中获取当前卷积层的第一通道所对应的输入数据,执行对应的卷积运算,并控制归一池化计算核对卷积运算的结果进行处理,得到第一输出误差。
[0061]
具体地,由于bp阶段执行的是反向传播过程,当以l表示当前卷积层,l 1表示当前卷积层的下一卷积层,则bp阶段执行的是将l 1层的权重转置与l 1层的误差进行卷积,通过归一池化计算核是处理后得到l层的误差,参见图1所示本技术实施例的三个阶段计算示意图,当前层的运算由公式(2)表示。值得说明的是,当前卷积层代表当前神经网络中的任意一层卷积层。
[0062]
进一步地,每个卷积层包括多个卷积核的卷积运算,每个卷积核的卷积运算用一
个通道表示,本技术实施例应用的网络结构中,深度神经网络的所有卷积层拥有相同数目的卷积核。每个卷积层的卷积核数目以字母c表示,也即是每个卷积层有c个通道,每个卷积层依次执行c个通道的卷积运算。值得说明的是,步骤二中的第一通道表示当前卷积层中的任一卷积核的计算通道。参见图3本技术实施例的bpip(backward pipeline,反向流水线)设计示意图,示出了本技术实施例对卷积层进行通道划分,每个通道在时间线上串行运算的表示。同时,每个通道进行相应运算得到第一输出误差,该误差为当前卷积层输出误差的一部分。当前卷积层所有通道的第一输出误差组成了当前卷积层的输出误差。
[0063]
另外,bp阶段一个通道运算得到的第一输出误差会立即传入wg阶段对应的通道中,与bp阶段当前卷积层的下一通道同时进行运算。
[0064]
步骤三,控制wg计算核获取待与所述第一输出误差进行卷积的输入值,所述前一卷积层为当前卷积层的前一网络层。
[0065]
在步骤三中,将第一输出误差作为wg阶段的卷积核,执行wg阶段对应的卷积运算,此时,wg阶段的第一通道为第一输出误差所对应的计算通道,控制模块控制wg计算核获取待与第一输出误差进行卷积的输入值,参见图1本技术实施例的三个阶段计算示意图,该输入值即为ff阶段前向传播过程中,前一卷积层的中间特征值的一部分。
[0066]
步骤四,控制wg计算核根据第一输出误差以及输入值,执行深度神经网络的wg阶段所对应的卷积运算。
[0067]
在步骤四中,执行第一输出误差与输入值的卷积计算过程。具体地,参见图4本技术实施例的bp和wg阶段并行示意图所示,当bp阶段l 1层的通道c将卷积得到的误差输入wg阶段l层的通道c后,bp阶段l 1层的通道c 1和wg阶段的通道c并行运行,为了使bp阶段每个通道计算完成后,计算核都能够立即执行对应通道的计算,使得系统达到较小的延时,需要对前向反向计算和和wg计算核中的硬件进行配置,也就是对第一pe和第二pe的数量进行配置,第一pe的数量和所述第二pe的数量通过以下方式确定:
[0068]
获取bp阶段的第一pe利用率以及wg阶段的第二pe利用率。
[0069]
根据所述第一pe利用率、所述第二pe利用率、预设的权重稀疏率、预设的误差稀疏率、bp阶段每一卷积层的通道数以及wg阶段每一卷积层的通道数,确定第一pe的并行度与第二pe的并行度的比率,具体地,可以通过对所述异构训练加速器进行硬件仿真,获取bp阶段的第一pe利用率以及wg阶段的第二pe利用率。
[0070]
根据第一pe的并行度与第二pe的并行度的比率,确定第一pe的数量和第二pe的数量。值得说明的是,第一pe并行度表示参与运算的第一pe的数量,第二pe并行度表示参与运算的第二pe的数量。
[0071]
进一步地,下面对获取第一pe和第二pe数量的具体过程进行解释。
[0072]
具体地,参见图4本技术实施例的bp和wg阶段并行示意图所示,要使bp阶段和wg阶段卷积层并行执行,需要保证bp阶段的通道和wg阶段的通道具有相同的延迟,因而需要保证bp阶段和wg阶段的每个通道具有相同的延时,该延时的计算方法如下:
[0073]
延时近似等于计算量除以并行度,在考虑对bp阶段输入的误差数据进行稀疏的情形下,bp和wg阶段每个通道的计算延时分别如下表示:
[0074]
[0075][0076]
其中,l
bp
表示bp阶段每个通道的计算延时,l
wg
表示wg阶段每个通道的计算延时,p
bp
表示第一pe的并行度,p
wg
表示第二pe并行度,u
bp
代表第一pe利用率,u
wg
代表第二pe的利用率,spe表示对wg阶段的误差稀疏率,e、f、k、c、分别表示bp阶段输出误差的宽度和高度以及卷积核尺寸,m
bp
表示bp阶段每一卷积通道中的计算量,m
wg
表示wg阶段每一卷积通道中的计算量。值得说明的是,在考虑其他稀疏情况下,以上公式可以基于原有形式进行适当调整。
[0077]
具体地,e
×f×k×
k表示一维卷积核与一维输入数据卷积过程中乘累加的次数,在具体实践中,bp阶段和wg阶段的两个该数据是相等的,因此在本技术实施例中不再区别表示。每个通道的卷积计算维度为输入数据的维数乘以卷积核的维数。
[0078]
令l
bp
=l
wg
,可以得到:
[0079][0080]
上式即为第一pe和第二pe的并行度比率,通过以上并行度比率,结合硬件设备和实际需要,可以设置第一pe和第二pe的数目。
[0081]
值得说明的是,bp阶段的池化过程会影响输出误差的尺寸,也即是e、f的尺寸,但对应的误差稀疏率也会受到相应的影响,在具体实验过程中,发现两者的增长乘正相关,且可以相互抵消,因而可以忽略池化过程对运算的影响。
[0082]
步骤五,当bp阶段当前卷积层的所有第一通道计算完毕后,当前卷积层所有第一通道的第一输出误差组成当前卷积层的输出误差,并将输出误差传入上一卷积层的wg计算核。
[0083]
在步骤五中,bp阶段的每个卷积层计算结束后,得到总的输出误差。计算得到的输出误差将继续进行前一层的卷积计算过程。值得说明的是,归一池化计算核中的相关计算具有较小延时,在本技术实施例中忽略不计。
[0084]
另外,控制模块包括配置寄存器和总控制单元。
[0085]
其中,配置寄存器,用于对数据和参数进行初始化配置。
[0086]
总控制单元,用于控制数据模块和计算模块执行对应的操作。
[0087]
此外,数据模块包括总线矩阵模块和存储模块。
[0088]
其中,存储模块,用于存储各个阶段中当前卷积层的输入数据和输出数据。
[0089]
总线矩阵模块,用于分配和调取存储模块中的输入数据。
[0090]
本技术公开了一种基于反向流水线的异构训练加速器,该加速器包括数据模块、控制模块和计算模块;控制模块控制bp阶段前向反向计算核执行第一通道的卷积运算,第一通道为当前卷积层中任一卷积核所对应的计算通道,并控制所述归一池化计算核对卷积运算结果进行处理,得到当前卷积层的第一通道的第一输出误差,并将第一输出误差传入wg计算核,同时控制wg计算核根据第一输出误差以及前一卷积层的第一通道的输入值,执行深度神经网络的wg阶段所对应的卷积运算。该加速器bp和wg过程的流水线并行处理,降低了系统延时、避免了数据在不同层级存储的额外传输,降低了功耗,同时其异构架构设计可以实现对不同类型的计算单独优化,提高能耗比和加速比。
[0091]
以上结合具体实施方式和范例性实例对本技术进行了详细说明,不过这些说明并不能理解为对本技术的限制。本领域技术人员理解,在不偏离本技术精神和范围的情况下,可以对本技术技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本技术的范围内。本技术的保护范围以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。