一种重组cho细胞、其构建方法、利用其的检测系统和方法
技术领域
1.本技术属于免疫效应检测领域,具体而言,涉及一种重组cho细胞、构建该重组cho细胞的方法、利用该细胞检测抗体的adcc效应和cdc效应的检测系统和检测方法。
背景技术:
2.adcc(antibody-dependent cell-mediated cytotoxicity),即抗体依赖的细胞介导的细胞毒作用,是指抗体通过fab段与靶细胞表面的抗原决定簇特异性结合后,其fc段与具有fcγr的效应细胞结合,触发效应细胞的杀伤活性,直接杀伤靶细胞。adcc效应是机体抗感染、抗肿瘤的重要免疫机制,参与adcc的效应细胞主要包括自然杀伤(natural killed,nk)细胞、吞噬细胞(phagocyte)、嗜酸性粒细胞(eosinophil)、嗜碱性粒细胞(basophil)和肥大细胞(mast cell)等。
3.cdc(complement dependent cytotoxicity),即补体依赖的细胞毒作用,是指补体参与的细胞毒作用,即通过特异性抗体与细胞膜表面相应抗原结合,形成复合物而激活补体经典途径,首先由补体蛋白c1q起始补体经典途径,接着补体蛋白c2-c9被激活形成攻膜复合物(membrane attack complex,mac),对靶细胞发挥裂解效应。
4.考虑到adcc效应和cdc效应在肿瘤免疫中的重要作用,在目前的抗肿瘤抗体的开发中,很多研究者希望通过对抗体结构的特定设计来得到改善的adcc效应和cdc效应。而在其它类型抗体的开发中,抗体介导的adcc效应和cdc效应并不总是期望的。
5.神经生长因子(ngf)是神经营养因子中最早被发现的,产生于新皮质和海马部位,其由两个α亚基、一个β亚基和两个γ亚基构成,能促进中枢和外周神经元的生长、发育、分化、成熟,维持神经系统的正常功能,加快神经系统损伤后的修复。目前主要将重组ngf用于治疗各种神经性病变及神经损伤。
6.中国仓鼠卵巢细胞(cho细胞)是最广泛使用的哺乳动物细胞表达系统之一,其具有良好的翻译后加工能力,使表达产物能够保持天然的结构和活性。目前已经将cho用于表达ngf并将重组的ngf分泌到细胞外,从而能够大规模生产得到ngf(例如xu l et al.,expression,purification,and characterization of recombinant mouse nerve growth factor in chinese hamster ovary cells.protein expr purif,2014,104:41-49;wang xy et al.,characteristic element of matrix attachment region mediates vector attachment and enhances nerve growth factor expression in chinese hamster ovary cells.genet mol res,2015,14(3):9191-9199)。然而,目前尚未报道能够稳定地在重组的cho细胞表面上表达ngf方面的研究。
技术实现要素:
7.为了能够准确地检测到抗ngf抗体的adcc效应和cdc效应,发明人通过研究开发了一种重组cho细胞,该细胞能够在其表面上稳定表达ngf,将其作为靶细胞可有效地用于评估抗ngf抗体的adcc效应和cdc效应。
8.一方面,本技术涉及一种重组cho细胞,其中,在所述细胞的表面上稳定表达ngf。
9.另一方面,本技术涉及一种构建上述的重组cho细胞的方法,包括:
10.(1)将串联的ngf、铰链区和跨膜区的核酸序列克隆到表达载体中,得到包含所述核酸序列的重组表达载体;
11.(2)将所述重组表达载体导入cho细胞中,得到重组cho细胞。
12.另一方面,本技术涉及一种检测抗体的adcc效应的系统,其中,所述系统包括:
13.上述的重组cho细胞,以及
14.效应细胞。
15.另一方面,本技术涉及一种检测抗体的cdc效应的系统,其中,所述系统包括:
16.上述的重组cho细胞,以及
17.补体。
18.又一方面,本技术涉及上述的重组cho细胞在用于检测抗体的adcc效应或cdc效应中的用途。
19.又一方面,本技术涉及一种检测抗体的adcc效应的方法,其中,所述方法包括将上述的重组cho细胞作为靶细胞与待测抗体和效应细胞共同孵育。
20.又一方面,本技术涉及一种检测抗体的cdc效应的方法,其中,所述方法包括将上述的重组cho细胞作为靶细胞与待测抗体和补体共同孵育。
21.在常规的重组ngf表达研究中,通常将cho细胞等哺乳动物细胞用作表达系统,以将ngf表达并分泌到细胞外,使其以与天然形态类似的游离形式存在于上清液中。另外,一些研究人员也尝试了采用原核系统(例如e.coli)来表达ngf,得到的表达产物以不溶性包含体存在(姜静等,来源于e.coli和cho表达系统的重组人β-ngf性质比较,《中国生物工程杂志》,2006,26(2):8-12)。ngf本身作为游离蛋白而非跨膜蛋白是否能够在细胞表面表达存在很大的不确定性。因此,对于在cho细胞表面上稳定表达ngf,本领域迄今为止尚未有相关报道。本技术中通过将ngf的核酸序列与适当的铰链区和跨膜区的核酸序列串联后导入cho细胞中,实现了在重组cho细胞表面上稳定表达ngf,由此使ngf存在于细胞表面上而非分泌到培养液中,并能够使表达的ngf得以进行恰当的翻译后加工(包括正确折叠、糖基化等)而保持天然构象和活性。由此得到的重组cho细胞在细胞表面上具有ngf而能够有效地用作检测抗ngf抗体的adcc效应和cdc效应的靶细胞,从而可用于对抗ngf抗体的adcc效应和cdc效应进行检测。
附图说明
22.图1示出了阳性对照抗体hab20-6-2的sds-page检测结果。根据图1中的结果可知,实施例3中制备的阳性对照抗体hab20-6-2的纯度大于90%。
23.图2示出了cho-ngf重组细胞的流式鉴定结果。其中,图2中的a示出了通过将作为空白对照的cho-s细胞与抗ngf阳性对照抗体hab20-6-2孵育而得到的流式检测结果,阳性率为2%;图2中的b示出了通过将实施例2构建的cho-ngf细胞与抗ngf阳性对照抗体hab20-6-2孵育而得到的流式检测结果,阳性率为82.67%。
24.图3示出了adcc效应检测结果。其中,a:tanezumab(4次检测)和阳性对照抗体hab20-6-2的adcc效应检测结果叠加图;b:阳性对照抗体hab20-6-2的检测结果;c:
tanezumab第1次检测结果;d:tanezumab第2次检测结果;e:tanezumab第3次检测结果;f:tanezumab第4次检测结果。
25.图4示出了cdc效应检测结果。其中,a:tanezumab(4次检测)和阳性对照抗体hab20-6-2的cdc效应检测结果叠加图;b:阳性对照抗体hab20-6-2的检测结果;c:tanezumab第1次检测结果;d:tanezumab第2次检测结果;e:tanezumab第3次检测结果;f:tanezumab第4次检测结果。
具体实施方式
26.下面结合具体的实施例来进一步描述本技术,本技术的优点和特点将会随着描述而更为清楚。但这些实施例仅是范例性的,并不对本技术的范围构成任何限制。本领域技术人员应该理解的是,在不偏离本技术的精神和范围下可以对本技术技术方案的细节和形式进行修改或替换,但这些修改和替换均落入本技术的保护范围内。
27.除非另外定义,否则本文使用的各技术和科学术语具有与本公开所属领域的普通技术人员通常理解的含义相同的含义。参见如singleton等,dictionary of microbiology and molecular biology 2nd ed.,j.wiley&sons(new york,ny 1994);sambrook等,molecular cloning,a laboratory manual,cold springs harbor press(cold springs harbor,ny 1989);davis等,basic methods in molecular biology,elsevier science publishing inc.,new york,usa(2012);abbas等,cellular and molecular immunology,elsevier science health science div(2009);何维等,医学免疫学(第2版),人民卫生出版社,2010年。
28.在本文中,除非另有说明,术语“包含、包括和含有(comprise、comprises和comprising)”或其等同物(contain、contains、containing、include、includes、including)为开放式表述,意味着除所列出的要素、组分和步骤外,还可涵盖其它未指明的要素、组分和步骤。
29.在本文中,除非另有说明,本文所使用的表示成分的量、测量值或反应条件的所有数字应理解为在所有情况下均由术语“约”修饰。当与百分比相连时,术语“约”可以表示例如
±
1%、优选
±
0.5%、更优选
±
0.1%。
30.除非上下文另有明确指示,单数术语涵盖复数的指示对象,反之亦然。类似地,除非上下文另有明确指示,词语“或”意在包括“和”。
31.在本文中,序列之间的一致性百分比(同源性程度)可以通过例如使用万维网(例如www.ncbi.nlm.nih.gov)上通常用于此目的的免费可用的计算机程序(例如具有默认设置的blastp或blastn)对两个序列进行比较来确定。
32.在本文中,除非另有说明,术语“密码子优化”是指通过在保持天然氨基酸序列的同时将天然序列的至少一个密码子替换为在宿主细胞中更频繁使用或最常使用的密码子以改善在宿主细胞中的表达,来对核酸序列修饰的过程。多种物种对特定氨基酸的特定密码子具有特定偏好,并且该密码子偏好(不同生物体间密码子使用的差别)常与mrna的翻译效率相关。
33.在本发明中,“表达载体”是指包含期望的编码序列和在特定的宿主生物体中表达可操作地连接的编码序列所必需的适当的核酸序列的载体。表达载体可优选包括一个或多
个标记基因。为了表达本发明的目的序列,可以在载体中使用例如如下的多种表达控制序列中的任何一种:复制起点、聚腺苷酸化信号、启动子、增强子、终止子等。
34.自1986年美国fda批准第一款单克隆抗体药物okt3(muromonab-cd3)开始,抗体药物作为疾病治疗的可选项而被越来越多地进行研究,到目前为止,fda已批准了上百款抗体药物(https://www.nature.com/articles/d41573-021-00079-7)。抗体激活人体免疫系统的机制很复杂,最主要包括抗体依赖的细胞介导的细胞毒作用(adcc)和补体依赖的细胞毒作用(cdc)。
35.通常而言,由于ngf本身是游离蛋白,因此,构建得到的能够表达ngf的重组细胞会将表达的ngf分泌到细胞外,使其以实质上等同于天然形态的游离形式存在于培养液中,由此使得常规构建得到的表达ngf的重组细胞并不适宜作为adcc和cdc检测中使用的靶细胞。而对于将ngf表达到细胞表面上来说存在着很大的不确定性,并且即使将ngf表达到重组细胞的表面上,所表达的ngf是否能够保持与游离的ngf相同的天然构象和活性也是未知的。因此,在此之前尚未报道能够在其表面上稳定表达ngf的重组cho细胞或者其它的重组细胞。
36.在一些实施方式中,本技术涉及一种重组cho细胞,其中,在所述细胞的表面上稳定表达ngf。
37.在本文中,可以采用任意已知序列的ngf,例如在ncbi、ensmbl或uniprot数据库中可获得的序列,或采用根据宿主细胞的密码子偏好性(可利用已有的软件例如codon w)而对已知序列进行密码子优化后的序列。在一些优选的实施方式中,ngf可以为哺乳动物ngf,例如人ngf、小鼠ngf、大鼠ngf、牛ngf、马ngf、猪ngf等,但不限于此。示例性的ngf的氨基酸序列和核酸序列可见于如下中的记载,在此以引用的方式将其各自的内容整体并入本文:katherine a.fitzgerald等,the cytokine factsbook and webfacts(second edition),academic press,2001;wei ma et al.,cloning and sequencing of matured fragment of human never growth factor gene,acad j xj tu,15(1),2003:62-65;ya barde等,the nerve growth factor family,progress in growth factor research,2,1990:237-248;wiesmann,c.等,nerve growth factor:structure and function.cmls,cell.mol.life sci.,58,2001:748-759;eric adriaenssens等,nerve growth factor is a potential therapeutic target in breast cancer,cancer res.,68(2),2008:january 15,2008:346-351;wo2021120900a1、wo2021093134a1、wo2021091363a1、wo2019201133a1、us2021079053a1、wo2010128398a1、us2014170137a1等。
38.在一些优选的实施方式中,ngf的氨基酸序列包含seq id no:1-seq id no:3中任一者示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
39.seq id no:1:ngf的氨基酸序列
40.msmlfytlitafligiqaephsesnvpaghtipqahwtklqhsldtalrrarsapaaaiaarvagqtrnitvdprlfkkrrlrsprvlfstqppreaadtqdldfevggaapfnrthrskrssshpifhrgefsvcdsvsvwvgdkttatdikgkevmvlgevninnsvfkqyffetkcrdpnpvdsgcrgidskhwnsycttthtfvkaltmdgkqaawrfiridtacvcvlsrkavrra
41.seq id no:2:成熟ngf的氨基酸序列1(成熟ngf 1)
42.ssshpifhrgefsvcdsvsvwvgdkttatdikgkevmvlgevninnsvfkqyffetkcrdpnpvdsgcrgidskhwnsycttthtfvkaltmdgkqaawrfiridtacvcvlsrkavrra
43.seq id no:3:成熟ngf的氨基酸序列2(成熟ngf 2)
44.ssshpifhrgefsvcdsvsvwvgdkttatdikgkevmvlgevninnsvfkqyffetkcrdpnpvdsgcrgidskhwnsycttthtfvkaltmdgkqaawrfiridtacvcvlsrkavr
45.在一些优选的实施方式中,所述细胞的基因组中整合有ngf的核酸序列。
46.在一些优选的实施方式中,所述ngf的核酸序列包含seq id no:4-seq id no:6中任一者示出的核酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的核酸序列。
47.seq id no:4:ngf的核酸序列
48.atgagcatgctgttctataccctgatcaccgcctttctgatcggcatccaggccgagcctcacagcgagtctaatgtgcctgccggccacacaatccctcaggctcactggacaaagctgcagcacagcctggatacagctctgcggagagccagatctgctcctgccgctgctattgccgctagagtggctggccagaccagaaacatcaccgtggatccccggctgttcaagaagcggagactgagaagccccagagtgctgttcagcacccagcctccaagagaggccgccgatacacaggacctggattttgaagttggcggcgctgcccctttcaacagaacccacagaagcaagcggagcagctctcaccccatcttccacagaggcgagttcagcgtgtgcgactccgtgtctgtgtgggtcggagataagaccaccgccaccgacatcaagggcaaagaagtgatggtcctgggcgaagtgaacatcaacaacagcgtgttcaagcagtacttcttcgagacaaagtgcagggaccccaatcctgtggacagcggctgtagaggcatcgacagcaagcactggaactcctactgcaccaccacacacaccttcgtgaaggccctgaccatggatggaaaacaggccgcctggcggttcatcagaatcgataccgcttgcgtgtgcgtgctgagcagaaaagccgttagaagggcc
49.seq id no:5:成熟ngf 1的核酸序列
50.agcagctctcaccccatcttccacagaggcgagttcagcgtgtgcgactccgtgtctgtgtgggtcggagataagaccaccgccaccgacatcaagggcaaagaagtgatggtcctgggcgaagtgaacatcaacaacagcgtgttcaagcagtacttcttcgagacaaagtgcagggaccccaatcctgtggacagcggctgtagaggcatcgacagcaagcactggaactcctactgcaccaccacacacaccttcgtgaaggccctgaccatggatggaaaacaggccgcctggcggttcatcagaatcgataccgcttgcgtgtgcgtgctgagcagaaaagccgttagaagggcc
51.seq id no:6:成熟ngf 2的核酸序列
52.agcagctctcaccccatcttccacagaggcgagttcagcgtgtgcgactccgtgtctgtgtgggtcggagataagaccaccgccaccgacatcaagggcaaagaagtgatggtcctgggcgaagtgaacatcaacaacagcgtgttcaagcagtacttcttcgagacaaagtgcagggaccccaatcctgtggacagcggctgtagaggcatcgacagcaagcactggaactcctactgcaccaccacacacaccttcgtgaaggccctgaccatggatggaaaacaggccgcctggcggttcatcagaatcgataccgcttgcgtgtgcgtgctgagcagaaaagccgttaga
53.在一些优选的实施方式中,所述细胞的基因组中整合有串联的ngf、铰链区(hinge)和跨膜区(也称为“跨膜结构域”)的核酸序列。
54.在进一步优选的实施方式中,所述铰链区的氨基酸序列具有3个以上的氨基酸、10个以上的氨基酸、20个以上的氨基酸、30个以上的氨基酸、40个以上的氨基酸、50个以上的氨基酸,或100个以下的氨基酸、90个以下的氨基酸、80个以下的氨基酸、70个以下的氨基酸、60个以下的氨基酸,或处于上述任意两个数值范围内的氨基酸,例如3-100个氨基酸、10-90个氨基酸、10-80个氨基酸、10-70个氨基酸、10-60个氨基酸、10-50个氨基酸、12-45个
氨基酸。
55.在进一步优选的实施方式中,所述跨膜区的氨基酸序列具有10个以上的氨基酸、20个以上的氨基酸、30个以上的氨基酸,或60个以下的氨基酸、50个以下的氨基酸、40个以下的氨基酸,或处于上述任意两个数值范围内的氨基酸,例如10-60个氨基酸、10-50个氨基酸、10-40个氨基酸、10-30个氨基酸、15-30个氨基酸、20-30个氨基酸、20-25个氨基酸。
56.在进一步优选的实施方式中,所述铰链区可为cd8铰链区(例如cd8α铰链区)或人igg1铰链区。
57.在进一步优选的实施方式中,所述跨膜区可为cd8跨膜区、pgfra跨膜区或cd80跨膜区。
58.在一些优选的实施方式中,所述cd8铰链区的氨基酸序列包含seq id no:7示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
59.seq id no:7:cd8铰链区的氨基酸序列
60.tttpaprpptpaptiasqplslrpeacrpaaggavhtrgldfacd
61.在一些优选的实施方式中,所述人igg1铰链区的氨基酸序列包含seq id no:8示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
62.seq id no:8:人igg1铰链区的氨基酸序列
63.epkscdkthtcp
64.在一些优选的实施方式中,编码所述cd8铰链区的核酸序列包含seq id no:9示出的核酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的核酸序列。
65.seq id no:9:cd8铰链区的核酸序列
66.accactaccccagcaccgaggccacccaccccggctcctaccatcgcctcccagcctctgtccctgcgtccggaggcatgtagacccgcagctggtggggccgtgcatacccgtggtcttgacttcgcctgcgat
67.在一些优选的实施方式中,所述cd8跨膜区的氨基酸序列包含seq id no:10示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
68.seq id no:10:cd8跨膜区的氨基酸序列
69.iyiwaplagtcgvlllslvitlyc
70.在一些优选的实施方式中,所述pgfra跨膜区的氨基酸序列包含seq id no:11示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
71.seq id no:11:pgfra跨膜区的氨基酸序列
72.aavlvllviviislivlvviw
73.在一些优选的实施方式中,所述cd80跨膜区的氨基酸序列包含seq id no:12示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
74.seq id no:12:cd80跨膜区的氨基酸序列
75.llpswaitlisvngifviccl
76.在一些优选的实施方式中,编码所述cd8跨膜区的核酸序列包含seq id no:13示出的核酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的核酸序列。
77.seq id no:13:cd8跨膜区的核酸序列
78.atctacatttgggcccctctggctggtacttgcggggtcctgctgctttcactcgtgatcactctttactgt
79.在一些优选的实施方式中,所述铰链区为cd8铰链区,且所述跨膜区为cd8跨膜区、pgfra跨膜区或cd80跨膜区。例如,在一些情况中,所述铰链区为cd8铰链区,且所述跨膜区为cd8跨膜区。或者例如,所述铰链区为cd8铰链区,且所述跨膜区为pgfra跨膜区。或者例如,所述铰链区为cd8铰链区,且所述跨膜区为cd80跨膜区。
80.在一些优选的实施方式中,所述铰链区为人igg1铰链区,且所述跨膜区为cd8跨膜区、pgfra跨膜区或cd80跨膜区。例如,在一些情况中,所述铰链区为人igg1铰链区,且所述跨膜区为cd8跨膜区。或者例如,所述铰链区为人igg1铰链区,且所述跨膜区为pgfra跨膜区。或者例如,所述铰链区为人igg1铰链区,且所述跨膜区为cd80跨膜区。
81.在一些优选的实施方式中,所述串联的ngf、铰链区和跨膜区的核酸序列为串联的ngf、cd8铰链区和cd8跨膜区的核酸序列。
82.在一些实施方式中,本技术涉及一种构建上述的重组cho细胞的方法,包括:
83.(1)将串联的ngf、铰链区和跨膜区的核酸序列克隆到表达载体中,得到包含所述核酸序列的重组表达载体;
84.(2)将所述重组表达载体导入cho细胞中,得到重组cho细胞。
85.在一些优选的实施方式中,ngf可以为哺乳动物ngf,例如人ngf、小鼠ngf、大鼠ngf、牛ngf、马ngf、猪ngf等,但不限于此。
86.在一些优选的实施方式中,ngf的氨基酸序列包含seq id no:1-seq id no:3中任一者示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
87.在一些优选的实施方式中,所述ngf的核酸序列包含seq id no:4-seq id no:6中任一者示出的核酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的核酸序列。
88.在进一步优选的实施方式中,所述铰链区的氨基酸序列具有3个以上的氨基酸、10个以上的氨基酸、20个以上的氨基酸、30个以上的氨基酸、40个以上的氨基酸、50个以上的氨基酸,或100个以下的氨基酸、90个以下的氨基酸、80个以下的氨基酸、70个以下的氨基酸、60个以下的氨基酸,或处于上述任意两个数值范围内的氨基酸,例如3-100个氨基酸、10-100个氨基酸、10-90个氨基酸、10-80个氨基酸、10-70个氨基酸、10-60个氨基酸、10-50个氨基酸、12-45个氨基酸。
89.在进一步优选的实施方式中,所述跨膜区的氨基酸序列长度具有10个以上的氨基酸、20个以上的氨基酸、30个以上的氨基酸,或60个以下的氨基酸、50个以下的氨基酸、40个以下的氨基酸,或处于上述任意两个数值范围内的氨基酸,例如10-60个氨基酸、10-50个氨基酸、10-40个氨基酸、10-30个氨基酸、15-30个氨基酸、20-30个氨基酸、20-25个氨基酸。
90.在一些优选的实施方式中,所述铰链区可为cd8铰链区(例如cd8α铰链区)或人igg1铰链区。
91.在一些优选的实施方式中,所述跨膜区可为cd8跨膜区、pgfra跨膜区或cd80跨膜区。
92.在一些优选的实施方式中,所述cd8铰链区的氨基酸序列包含seq id no:7示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。在一些优选的实施方式中,所述人igg1铰链区的氨基酸序列包含seq id no:8示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
93.在一些优选的实施方式中,编码所述cd8铰链区的核酸序列包含seq id no:9示出的核酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的核酸序列。
94.在一些优选的实施方式中,所述cd8跨膜区的氨基酸序列包含seq id no:10示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。在一些优选的实施方式中,所述pgfra跨膜区的氨基酸序列包含seq id no:11示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。在一些优选的实施方式中,所述cd80跨膜区的氨基酸序列包含seq id no:12示出的氨基酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的氨基酸序列。
95.在一些优选的实施方式中,编码所述cd8跨膜区的核酸序列包含seq id no:13示出的核酸序列或与其具有至少80%(例如85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%或更高)序列一致性的核酸序列。
96.在一些优选的实施方式中,所述铰链区为cd8铰链区,且所述跨膜区为cd8跨膜区、pgfra跨膜区或cd80跨膜区。例如,在一些情况中,所述铰链区为cd8铰链区,且所述跨膜区为cd8跨膜区。或者例如,所述铰链区为cd8铰链区,且所述跨膜区为pgfra跨膜区。或者例如,所述铰链区为cd8铰链区,且所述跨膜区为cd80跨膜区。
97.在一些优选的实施方式中,所述铰链区为人igg1铰链区,且所述跨膜区为cd8跨膜区、pgfra跨膜区或cd80跨膜区。例如,在一些情况中,所述铰链区为人igg1铰链区,且所述跨膜区为cd8跨膜区。或者例如,所述铰链区为人igg1铰链区,且所述跨膜区为pgfra跨膜区。或者例如,所述铰链区为人igg1铰链区,且所述跨膜区为cd80跨膜区。
98.在一些优选的实施方式中,所述串联的ngf、铰链区和跨膜区的核酸序列为串联的ngf、cd8铰链区和cd8跨膜区的核酸序列。
99.在一些优选的实施方式中,所述表达载体可为慢病毒表达载体、腺病毒载体、腺相关病毒载体、逆转录病毒载体、痘病毒载体或单纯疱疹病毒载体,但不限于此。作为慢病毒表达载体的示例,慢病毒表达载体例如可为lenti-cmv-puro慢病毒表达载体、pcdh系列慢病毒表达载体、或plenti系列慢病毒表达载体,但不限于此。
100.在一些优选的实施方式中,在步骤(2)中,将所述重组表达载体和病毒包装质粒共
转染包装细胞,经培养后,制备得到含有所述核酸序列的病毒,然后利用所述病毒转染cho细胞,得到所述重组cho细胞。
101.在进一步优选的实施方式中,所述病毒包装质粒可为pmd2.g、pspax2、lenti-packaging mix、pcmv-dr8.91、pcmv-dr8.74、plp1、plp2、pvsv-g等,但不限于此。
102.在进一步优选的实施方式中,所述包装细胞可为293t细胞、293ft细胞等,但不限于此。
103.在本文中,除非另有说明,细胞的培养采用本领域常规的培养条件和常见的细胞培养基(例如1640培养基、dmem培养基、mem培养基、f12培养基等)进行,可参见例如如下的记载:兰容等,《细胞培养技术》,化学工业出版社,2007年;r.i.fershney,culture of animal cells:a manual of basic technique and specialized applications(sixth edition),john wiley&sons,inc;2010;刘斌等,《细胞培养(第3版)》,世界图书出版公司,2018年;以引用的方式将其各自的内容整体并入本文。
104.转染是本领域已知的用于将目标外源dna(提取自感兴趣的供体或者直接合成)导入宿主细胞中的常用手段之一。病毒介导的转染是本领域常用的转染方法之一,其利用包装有期望的外源基因的病毒感染细胞的方法使得感兴趣的外源基因进入细胞中,该方法具有转染效率最高、以及细胞毒性很低等优点。
105.在一些实施方式中,本技术涉及一种检测抗体的adcc效应的系统,其中,所述系统包括:
106.上述的重组cho细胞,以及
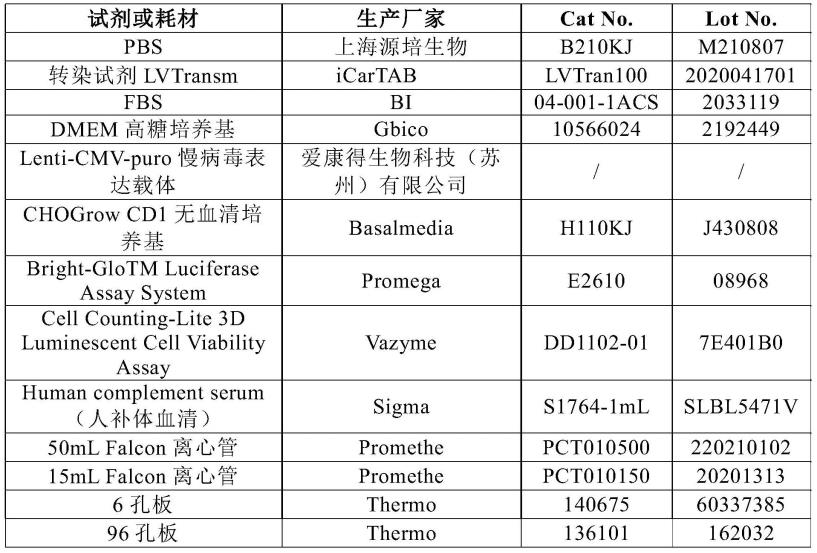
107.效应细胞。
108.在本文中,所述效应细胞可以为本领域已知的任何常规的效应细胞。作为示例,在一些优选的实施方式中,效应细胞可包括但不限于效应t细胞、nk细胞、吞噬细胞、嗜酸性粒细胞、嗜碱性粒细胞和肥大细胞等,例如jurkat-nfat-luciferase-cd16细胞、原代nk细胞等。
109.在一些优选的实施方式中,所述效应细胞与所述重组cho细胞以数量计的效靶比(e:t)可为1:1-1:20,例如1:5。
110.在一些优选的实施方式中,所述系统还包括萤光素酶底物。作为典型的萤光素酶,萤火虫萤光素酶(firefly luciferase)是分子量为约61kda的蛋白质,其在atp、镁离子和氧气存在的条件下能够催化萤光素(luciferin)氧化成oxyluciferin,并在氧化的过程中发出生物荧光。
111.在一些实施方式中,本技术涉及一种检测抗体的cdc效应的系统,其中,所述系统包括:
112.上述的重组cho细胞,以及
113.补体。
114.补体,也被称为补体系统,是存在于人和动物血清或组织液中的可介导免疫应答和炎症反应的蛋白质,包括30多种可溶性蛋白和膜结合蛋白。在一些优选的实施方式中,所述补体为包含补体蛋白c1-c9的补体血清。
115.在一些优选的实施方式中,所述系统还包括萤光素酶底物。
116.在一些实施方式中,本技术涉及上述的重组cho细胞在用于检测抗体的adcc效应
或cdc效应中的用途。
117.在一些实施方式中,本技术涉及一种检测抗体的adcc效应的方法,其中,所述方法包括将上述的重组cho细胞作为靶细胞与待测抗体和效应细胞共同孵育。在进一步优选的实施方式中,所述效应细胞与所述靶细胞以数量计的效靶比可为1:1-1:20,例如1:5。在一些优选的实施方式中,所述方法还包括:向共同孵育后的体系中加入萤光素酶底物。
118.在一些实施方式中,本技术涉及一种检测抗体的cdc效应的方法,其中,所述方法包括将上述的重组cho细胞作为靶细胞与待测抗体和补体共同孵育。在进一步优选的实施方式中,所述补体为包含补体蛋白c1-c9的补体血清。在一些优选的实施方式中,所述方法还包括:向共同孵育后的体系中加入萤光素酶底物。
119.实施例
120.下面通过实施例对本技术进行详细描述,但并不旨在将本技术的保护范围限制于此。对本领域的技术人员而言,在不脱离本技术的精神和范围的情况下,可以基于下述各实施例的描述而进行各种变化、修饰和改进,由此得到的方案仍然落入了本技术的保护范围内。
121.需要说明的是,本技术中涉及的基因的设计、合成和克隆,基因片段的连接,表达载体的构建,序列分析及鉴定,重组细胞的构建,以及表达产物的分离和纯化等操作步骤,可按照本领域已知的技术进行(例如参见current protocols in molecular biology的记载)。若未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段。除非另外说明,下述实施例中使用的试剂、材料和设备均为可商购的试剂、材料和设备。
122.现将如下实施例中使用的主要的试剂、耗材和设备及其来源等在下表中示出,本领域技术人员可以采用任何其它具有等同效果的试剂、耗材和设备。
123.[0124][0125]
实施例1ngf过表达慢病毒载体构建和慢病毒制备
[0126]
可将ngf的核酸序列与编码铰链区和跨膜区的核酸序列串联并插入适当的表达载体中,由此来实现上述核酸序列的异源表达。对于ngf而言,可以选用来自哺乳动物的ngf,例如人ngf、小鼠ngf、大鼠ngf、牛ngf、马ngf、猪ngf等,并且可根据常用的核酸序列和蛋白质序列的数据库例如ncbi、ensmbl或uniprot公开的已知序列来合成ngf及其核酸序列。
[0127]
在此,以人ngf为例,并将cd8铰链区和cd8跨膜区用于与该ngf串联。具体来说,将人ngf的全长序列根据宿主细胞cho-s细胞的密码子偏好性进行密码子优化,得到具有以seq no id:1示出的氨基酸序列的ngf(相应的核酸序列以seq id no:4示出),将其与cd8铰链区(氨基酸序列以seq id no:7示出;核酸序列以seq id no:9示出)和cd8跨膜区(氨基酸序列以seq id no:10示出;核酸序列以seq id no:13示出)串联,在串联后进行基因合成并将合成的基因片段亚克隆至lenti-cmv-puro慢病毒表达载体(爱康得生物科技(苏州)有限公司),制备目的基因过表达载体lenti-cmv-ngf-full(cd8-tm)载体,测序验证序列无误后,制备去内毒素质粒备用。
[0128]
接下来,按照如下步骤制备慢病毒:
[0129]
1.准备15cm细胞培养皿,以5
×
106个细胞/皿接种293t细胞(吉妮欧生物),加入完全培养基(补充有10%fbs的dmem高糖培养基),置于37℃、5%co2培养箱过夜培养。
[0130]
2.从冰箱中取出转染试剂lvtransm、lenti-cmv-ngf-full(cd8-tm)表达载体以及慢病毒包装质粒lenti-packaging mix,室温解冻后,用移液枪上下吹打完全混匀。按照以下流程制备转染复合物:取1
×
pbs或hbss缓冲液温热至室温,然后取2ml pbs或hbss缓冲液加入至6孔板的一个孔,分别加入10μg lenti-cmv-ngf-full(cd8-tm)表达载体、30μl lenti-packaging mix,移液枪上下吹打充分混匀后,加入50μl lvtransm,立即用移液器上下吹打混匀,室温下静置10-15分钟。
[0131]
3.将上述转染复合物逐滴加入到步骤1的15cm细胞培养皿中,轻轻晃动培养皿,充分混匀。将培养皿置于37℃、5%co2培养箱培养6~8小时后,将含有转染试剂的培养基去掉,更换为新鲜的完全培养基,将培养皿重新放回培养箱中继续培养。
[0132]
4.连续培养24小时后,收集培养皿中含有病毒的培养基上清至50ml离心管中;向培养皿内重新加入25ml左右新鲜的完全培养基,继续培养24小时;
[0133]
5.收集培养皿中含有病毒的培养基上清至50ml离心管中;向培养皿内重新加入25ml左右新鲜的完全培养基,继续培养24小时;
[0134]
6.收集培养皿中含有病毒的培养基上清,并与前面收集的两次培养基上清混合;
[0135]
7.用0.45μm的pes材质的滤膜将上述的培养基上清过滤后,将滤液转至无菌离心
管中,50000
×
g、4℃下离心2小时。离心结束后,在生物安全柜中,小心地将离心管中的液体吸去,加入1ml pbs缓冲液将沉淀重悬,将得到的lenti-cmv-ngf-full(cd8-tm)过表达慢病毒置于-80℃保存。
[0136]
实施例2重组cho细胞的构建
[0137]
采用实施例1中制备的lenti-cmv-ngf-full(cd8-tm)过表达慢病毒,按照如下过程制备能够在细胞表面稳定表达ngf的重组cho细胞(也称为“cho-ngf重组细胞”或“cho-ngf细胞”):
[0138]
1.从液氮中复苏cho-s细胞,并使用chogrow cd1无血清培养基在37℃、5%co2培养箱中进行培养。连续传代5次,使细胞处于对数生长期。
[0139]
2.取新的6孔板,按照5
×
106个细胞/孔的密度将上述对数生长期的cho-s细胞接种至6孔板中,并加入3ml chogrow cd1无血清培养基,按照moi=5,根据接种细胞数以及病毒滴度计算所需的病毒量,计算公式如下:
[0140]
病毒量(ml)=(细胞数
×
moi)/病毒滴度
[0141]
3.将实施例1中制备得到的lenti-cmv-ngf-full(cd8-tm)过表达慢病毒按照上述公式计算的量加入6孔板中,用移液器轻轻混匀后,将6孔板置于离心机中,800
×
g室温离心1小时;
[0142]
4.离心结束后,将6孔板取出,置于37℃、5%co2培养箱中继续培养24小时;
[0143]
5.培养24h后,将6孔板中的培养基更换为新鲜的chogrow cd1无血清培养基,继续培养24小时;
[0144]
6.将6孔板中的培养基更换为含有8μg/ml puromycin的chogrow cd1无血清培养基,连续培养5天,直至将所有的未被感染的cho-s细胞杀死。
[0145]
7.将剩余的活细胞继续扩大培养,收集细胞,得到构建的重组cho细胞。
[0146]
实施例3重组cho细胞的流式鉴定
[0147]
采用阳性对照抗体,利用流式细胞术对实施例2中构建的重组cho细胞进行鉴定。其中,阳性对照抗体hab20-6-2按照如下过程制备:
[0148]
1.从辉瑞开发的igg2亚型的抗ngf抗体tanezumab出发,根据tanezumab抗体序列信息(其重链序列以seq no id:14示出;轻链序列以seq no id:15示出),将tanezumab抗体的fc段恒定区序列替换为人igg1亚型的恒定区序列(氨基酸序列以seq no id:16示出;核苷酸序列以seq no id:17示出),其余部分不变,利用pcdna3.1-higg1载体(爱康得生物科技(苏州)有限公司制备)构建得到human igg1亚型重组抗体表达载体,置于冰箱冷冻保藏备用。
[0149]
2.从冰箱中取出转染试剂lvtransm及human igg1亚型重组抗体表达载体,室温解冻后,将二者分别用移液枪上下吹打均匀。取1
×
pbs或hbss缓冲液温热至室温。然后,取2ml pbs或hbss缓冲液加入至6孔板的一个孔,向其中加入90μg human igg1亚型重组抗体表达载体(轻链和重链比例为2:1),移液枪上下吹打充分混匀后,再向其中加入270μl lvtransm,立即用移液器上下吹打混匀,室温下静置10分钟,得到复合物。
[0150]
3.将上述得到的复合物加入到50ml 293f细胞中,轻轻晃动充分混匀。将细胞置于37℃、5%co2培养箱中,130rpm下培养6~8小时后,向细胞中加入50ml新鲜的293f培养基,将细胞重新放回培养箱中继续培养。
[0151]
4.连续培养7天后,离心收集培养基上清,用0.45μm的滤膜过滤,滤液转至无菌离心管中,使用protein a亲和柱纯化抗体,获得阳性对照抗体hab20-6-2。
[0152]
5.通过sds-page检测蛋白纯度。
[0153]
检测结果在图1中示出,根据sds-page检测结果,上述制备得到的阳性对照抗体hab20-6-2的纯度大于90%,可以用于adcc效应检测。
[0154]
seq no id:14:tanezumab的重链序列
[0155]
qvqlqesgpglvkpsetlsltctvsgfsligydlnwirqppgkglewigiiwgdgttdynsavksrvtiskdtsknqfslklssvtaadtavyycarggywyatsyyfdywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssnfgtqtytcnvdhkpsntkvdktverkccvecppcpappvagpsvflfppkpkdtlmisrtpevtcvvvdvshedpevqfnwyvdgvevhnaktkpreeqfnstfrvvsvltvvhqdwlngkeykckvsnkglpssiektisktkgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppmldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
[0156]
seq no id:15:tanezuab的轻链序列
[0157]
diqmtqspsslsasvgdrvtitcrasqsisnnlnwyqqkpgkapklliyytsrfhsgvpsrfsgsgsgtdftftisslqpediatyycqqehtlpytfgqgtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
[0158]
seq no id:16:人igg1恒定区的氨基酸序列
[0159]
astkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
[0160]
seq no id:17:人igg1恒定区的核酸序列
[0161]
gcctctacaaagggcccctccgtttttccactggctcccagcagcaagtctacctctggtggaacagccgctctgggctgcctggtcaaggattactttcccgagccagtgaccgtgtcctggaactctggcgctctgacatctggcgtgcacacatttccagccgtgctgcagtctagcggcctgtactctctgagcagcgtggtcacagtgcctagctctagcctgggcacccagacctacatctgcaatgtgaaccacaagcctagcaacaccaaggtggacaagaaggtggaacccaagagctgcgacaagacccacacctgtcctccatgtcctgctccagaactgctcggcggaccttccgtgtttctgttccctccaaagcctaaggacaccctgatgatcagcagaacccctgaagtgacctgcgtggtggtggatgtgtcccacgaggaccccgaagtgaagttcaattggtacgtggacggcgtggaagtgcacaacgccaagaccaagcctagagaggaacagtacaacagcacctacagagtggtgtccgtgctgacagtgctgcatcaggactggctgaacggcaaagagtacaagtgcaaggtgtccaacaaggccctgcctgctcctatcgagaaaaccatcagcaaggccaagggccagcctagggaaccccaggtttacacactgcctccaagcagggacgagctgaccaagaatcaggtgtccctgacctgcctcgtgaagggcttctacccttccgatatcgccgtggaatgggagagcaatggccagcctgagaacaactacaagacaacccctcctgtgctggacagcgacggctcattcttcctgtacagcaagctgaccgtggacaagtccagatggcagcagggcaacgtgttcagctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgagcctgtctcctggcaaataa
[0162]
基于上述制备的阳性对照抗体hab20-6-2,可以通过流式细胞术对重组cho细胞进行鉴定,例如可以按照如下过程来鉴定实施例2中构建的重组cho细胞(cho-ngf细胞):
[0163]
(1)将实施例2中构建的cho-ngf细胞和作为空白对照的cho-s细胞用chogrow cd1无血清培养基在37℃、5%co2培养箱中进行培养,调整细胞状态至对数生长期。
[0164]
(2)将上述两种细胞各自按照5
×
105个细胞的数量分别加入6孔板的1个孔中,向具有上述细胞的孔中各加入100μl 1
×
pbs缓冲液以重悬细胞,然后向其中各加入1μg阳性对照抗体hab20-6-2,充分混匀后,室温孵育45min;同时设置不加入阳性对照抗体的孔,作为阴性对照。
[0165]
(3)800
×
g室温离心5min,去掉含有抗体的上清,使用1
×
pbs缓冲液洗涤细胞3次;
[0166]
(4)加入pe anti-human igg fc二抗(1:200稀释),充分混匀后,室温避光孵育30min;
[0167]
(5)800
×
g室温离心5min,去掉含有二抗的上清,使用1
×
pbs缓冲液洗涤细胞3次;
[0168]
(6)使用500ul 1
×
pbs缓冲液重悬细胞,进行流式分析。
[0169]
流式鉴定结果在图2中示出。根据图2的流式检测结果可知,实施例2构建的cho-ngf细胞的阳性对照抗体的阳性率为82.67%,因此,可以作为adcc效应检测的靶细胞。
[0170]
实施例4 adcc效应检测
[0171]
本实施例中以上述实施例2构建的在细胞表面稳定表达人ngf的cho-ngf重组细胞作为靶细胞,以稳定转染萤光素酶的jurkat-nfat-luciferase-cd16细胞系为效应细胞。当待测样品或阳性对照抗体的fab段与靶细胞上的抗原结合以后,待测样品或阳性对照抗体的fc段与效应细胞jurkat-nfat-luciferase-cd16表面的cd16结合,细胞内nfat相关信号通路活化,进而导致荧光素酶表达水平上升,通过检测荧光素酶活性的变化,评估待测样品和阳性对照抗体的adcc效应。
[0172]
待测样品tanezumab为辉瑞开发的重组抗ngf人源化单克隆抗体,靶向人神经生长因子,采用cho细胞表达系统合成。本实施例中采用的tanezumab和阳性对照抗体hab20-6-2的相关信息见下表。
[0173]
样品名称浓度保存tanezumab10mg/ml-70
±
10℃阳性对照抗体hab20-6-23.5mg/ml-70
±
10℃
[0174]
使用adcc reporter bioassay进行adcc效应检测实验,实验步骤如下。
[0175]
1、以jurkat-nfat-luciferase-cd16过表达细胞作为效应细胞,以实施例2构建的cho-ngf细胞作为靶细胞,按照效靶比1:5建立adcc的实验体系(共100μl),其中效应细胞的数量为2
×
104个,靶细胞的数量为1
×
105个/孔,接入96孔板作为后续的实验体系。
[0176]
2、将tanezumab和阳性对照抗体hab20-6-2先用rpmi 1640培养基稀释至浓度为200μg/ml,得到各自相应的母液,然后进行10倍梯度稀释(取20μl上述稀释得到的各母液,加入到180μl rpmi 1640培养基中,依次进行梯度稀释),连续稀释9个梯度(200、20、2、0.2、0.02、0.002、0.0002、0.00002、0.000002、0μg/ml)。
[0177]
3、在上述的实验体系中分别加入上述稀释得到的不同浓度梯度的待测样品tanezumab及阳性对照抗体hab20-6-2,每孔接种100μl上述的待测样品和阳性对照抗体(其在各孔中的终浓度分别为100、10、1、0.1、0.01、0.001、0.0001、0.00001、0.000001、0μg/ml),每个浓度2个复孔,37℃、5%co2培养箱共培养18小时后,加入20μl one-glo试剂,室温反应5min,通过检测荧光素酶活性的变化,评估抗体的adcc效应。其中,tanezumab重复检测
4次。
[0178]
在该实施例中,利用实施例2构建的在细胞表面上稳定表达ngf的cho-ngf重组细胞作为靶细胞,并利用现有的效应细胞,通过报告基因法来评价阳性对照抗体hab20-6-2和tanezumab介导adcc效应的能力。adcc效应的检测结果在图3中示出。根据图3中的检测结果可知,阳性对照抗体hab20-6-2可引起jurkat-nfat-luciferase-cd16效应细胞产生显著的adcc效应,且在一定剂量范围内存在明显的剂量效应关系。然而,与上述阳性对照抗体相比区别仅在于fc段恒定区序列的tanezumab的4次检测均未检测出明显的adcc效应。
[0179]
可见,在上述实验条件下,阳性对照抗体产生显著的adcc效应,而与其具有相同的可变区(由此可预期抗体tanezumab能够识别并特异性地结合至相同的抗原,即cho-ngf重组细胞表达的ngf)的tanezumab却没有产生明显的adcc效应。因此,本发明的cho-ngf重组细胞可有效地用作体外检测抗ngf抗体介导的adcc效应的靶细胞,从而准确地检测待测抗体是否能够引起效应细胞产生adcc效应。
[0180]
实施例5 cdc效应检测
[0181]
本实施例以实施例2构建的在细胞表面稳定表达人ngf的cho-ngf重组细胞作为靶细胞,将靶细胞、人补体血清、待测样品或阳性对照抗体共同孵育,当待测样品或阳性对照抗体的fab段与靶细胞上的抗原结合以后,待测样品或阳性对照抗体的fc段与人血清中的补体结合并引发cdc效应,造成靶细胞杀伤。atp是活细胞新陈代谢的重要指标,其含量直接反映了活细胞的数量。向孵育完成后的反应体系中加入cell counting-lite 3d luminescent试剂,该试剂中含有热稳定的萤光素酶及其底物荧光素,并且可促进反应体系中的活细胞裂解释放出atp,atp促进萤光素酶作用于底物使其发光,通过检测发光强度,可以反映检测体系中活细胞的数量,进而可反映出所述待测样品或阳性对照抗体通过cdc作用对靶细胞的裂解效应。
[0182]
待测样品tanezumab以及阳性对照抗体hab20-6-2的相关信息同实施例4。按照如下步骤进行cdc效应检测实验:
[0183]
1、以实施例2构建的cho-ngf细胞作为靶细胞,接种细胞量为4
×
104个/孔(90μl),接入96孔板作为后续的实验体系。
[0184]
2、将待测样品tanezumab和阳性对照抗体hab20-6-2先用rpmi1640培养基稀释至浓度为200μg/ml,得到各自相应的母液,然后进行10倍梯度稀释(取20μl上述稀释得到的各母液,加入到180μl rpmi 1640培养基中,依次进行梯度稀释),连续稀释9个梯度(200、20、2、0.2、0.02、0.002、0.0002、0.00002、0.000002、0μg/ml)。
[0185]
3、在上述的实验体系中分别加入上述稀释得到的不同浓度梯度的待测样品tanezumab和阳性对照抗体hab20-6-2(其在各孔中的终浓度分别为100、10、1、0.1、0.01、0.001、0.0001、0.00001、0.000001、0μg/ml),同时加入10μl human complement serum(人补体血清),每个浓度2个复孔,37℃、5%co2培养箱共培养18小时后,加入50μl cellcounting-lite 3d试剂,振荡2min使细胞团充分裂解;室温放置25min后,使用多功能酶标仪检测发光值。通过检测发光值的变化反映靶细胞的裂解,评估抗体的cdc效应。其中,tanezumab重复检测4次。
[0186]
4、靶细胞裂解百分数(lysis%)计算公式(rlu
max
:细胞空白对照孔的荧光强度;rlu
sample
:加入待测样品或阳性对照抗体的孔的荧光强度):
[0187][0188]
在该实施例中,利用实施例2构建的在细胞表面上稳定表达ngf的cho-ngf重组细胞作为靶细胞,评价阳性对照抗体hab20-6-2和tanezumab介导cdc效应的能力。根据图4中的检测结果可知,阳性对照抗体hab20-6-2对cho-ngf靶细胞产生显著的cdc效应,且在一定剂量范围内存在明显的剂量效应关系。然而,与上述阳性对照抗体相比区别仅在于fc段恒定区序列的tanezumab的4次检测均未检测出明显的cdc效应。
[0189]
可见,在上述实验条件下,阳性对照抗体hab20-6-2产生显著的cdc效应,tanezumab(与所述阳性对照抗体具有相同的可变区,由此可预期抗体tanezumab也能够识别并特异性地结合至所述cho-ngf重组细胞表面上表达的ngf)却没有产生明显的cdc效应。因此,本发明的cho-ngf重组细胞可有效地用作体外检测抗ngf抗体介导的cdc效应的靶细胞,从而准确地检测待测抗体是否能够针对靶细胞产生cdc效应。
[0190]
为了描述和公开的目的,以引用的方式将所有的专利、专利申请和其它出版物在此明确地并入本文。这些出版物仅因为它们的公开早于本技术的申请日而提供。所有关于这些文件的日期的声明或这些文件的内容的表述是基于申请者可得的信息,并且不构成任何关于这些文件的日期或这些文件的内容的正确性的承认。而且,在任何国家,在本中对这些出版物的任何引用并不构成关于该出版物成为本领域的公知常识的一部分的认可。
[0191]
本领域技术人员将认识到,本技术的范围并不限于上文描述的各种具体实施方式和实施例,而是能够在不脱离本技术的精神的情况下,进行各种修改、替换、或重新组合,这都落入了本技术的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。