1.本技术属于文本多标签分类技术领域,尤其涉及一种基于异构图神经网络的纪检线索多标签分类方法。
背景技术:
2.纪检线索是由纪检监察机关受理的反映党组织、党员和行政监察对象涉嫌违犯党的纪律、行政纪律和国家法律法规的线索材料。主要包括:领导批转的信访案件线索;各级纪检监察组织在办案过程中,发现的有关单位或个人涉嫌违纪的线索;各镇(区、街道、中心社区)、区直部门、司法机关报送的线索;其他方面收集、掌握的涉案信息等。纪检线索的管理方式通常为在区纪委案管室设立案件线索储备库,确定专人管理,具体负责案件线索的收集、登记、分类、归档等工作。现有技术中,对纪检线索进行多标签分类方法多为采用人工针对文本进行多标签分类,效率较低,大量耗费了纪检监察干部人力。现有的基于图神经网络的分类方法对文本进行多标签分类,但没有将文本的句法信息、语义信息和结构信息进行综合考虑,文本的向量表示没有充分融合多种信息,限制了文本的表示能力;同时,缺乏针对不同边信息和节点类型信息的节点更新方法,导致文本多标签分类结果不理想。
技术实现要素:
3.本技术提供了一种基于异构图神经网络的纪检线索多标签分类方法,用以解决现有的纪检线索多标签分类方法存在的分类效率较低,限制了文本的表示能力以及不能根据不同边信息和节点类型信息进行节点更新的技术问题。
4.有鉴于此,本技术提供了一种基于异构图神经网络的纪检线索多标签分类方法,包括:
5.构建基于文本异构图的文本多标签分类模型,基于文本异构图的文本多标签分类模型包括异构图神经网络、bilstm神经网络、基于注意力机制的文本表示模块和全连接网络;
6.对文本进行预处理,构建文本的异构图结构,获得异构图结构的节点、边及边的权重,按照节点和边的关系建立邻接矩阵;
7.将异构图结构中的不同类型的节点的向量表示初始化,得到初始向量表示;
8.将节点向量表示和异构图结构输入异构图神经网络,得到句子节点向量表示;
9.将句子节点向量表示按句子的顺序输入bilstm神经网络,得到文本的内容向量表示;
10.通过内容向量表示和句子节点向量表示的基于注意力机制的文本表示模块,获得句子在文本表示中的权重,并获得文本向量表示;
11.将文本向量表示输入全连接网络,输出标签分类结果。
12.可选地,对文本进行预处理,包括:
13.对文本进行分词、分句、去除停用词,对文本进行句法分析,并计算文本中词语的
语义相似度,获得文本的单词集合和句子集合。
14.可选地,对文本进行分词、分句、去除停用词,对文本进行句法分析,并计算文本中词语的语义相似度,获得文本的单词集合和句子集合,包括:
15.对文本进行分词、分句、去除停用词,对文本中的每个句子使用句法依赖工具进行句法分析,对每个句子的词语按共现信息进行结构分析,对文本中的词语按照emebedding的词向量计算词语之间的语义距离,获得文本的单词集合和句子集合。
16.可选地,节点包括由句子集合内的句子转换成的句子节点和由单词集内的词语转换成的词语节点。
17.可选地,将异构图结构中的不同类型的节点的向量表示初始化,得到初始向量表示,包括:
18.对单词集中的词语采用嵌入式的emedding获得词语向量表示,将词语向量表示分别输入bilstm模型和不同卷积核的cnn模型,并将两个模型的输出结果进行拼接获得句子的初始向量表示。
19.可选地,将节点向量表示和异构图结构输入异构图神经网络,得到句子节点向量表示,包括:
20.将初始向量表示和异构图结构输入异构图神经网络,经过了同类型边相邻节点更新和不同类型边的信息融合两个阶段的更新方式更新后获得句子节点向量表示。
21.可选地,通过内容向量表示和句子节点向量表示的基于注意力机制的文本表示模块,获得句子在文本表示中的权重,并获得文本向量表示,包括:
22.以内容向量为查询向量,句子节点向量表示为key和value的注意力,得到基于注意力机制的文本向量表示。
23.可选地,将文本向量表示输入全连接网络,输出标签分类结果,包括:
24.将文本向量表示输入全连接网络经过sigmod函数输出标签分类结果。
25.可选地,将文本向量表示输入全连接网络,输出标签分类结果,之后还包括:
26.对基于文本异构图的文本多标签分类模型中的异构图神经网络进行迭代训练提取数据特征,计算得到损失函数,并利用随机梯度下降法以降低损失函数数值为目的进行迭代训练,直至满足预期阈值规定,并按照训练结束后得到的参数,对文本进行输入得到标签分类结果。
27.可选地,对基于文本异构图的文本多标签分类模型中的异构图神经网络进行迭代训练提取数据特征,计算得到损失函数,并利用随机梯度下降法以降低损失函数数值为目的进行迭代训练,直至满足预期阈值规定,并按照训练结束后得到的参数,对文本进行输入得到标签分类结果,包括:
28.对基于文本异构图的文本多标签分类模型中的异构图神经网络进行迭代训练提取数据特征,直至损失函数数值不再减小,计算模型的准确率、召回率以及f值,通过评价指标验证模型的性能,如果f值低于预期阈值,则通过人工干预后进行再次训练,反复迭代,直至f值高于预期阈值,并按照训练结束后得到的参数,对文本进行输入得到标签分类结果。
29.从以上技术方案可以看出,本技术实施例具有以下优点:
30.本技术提供的一种基于异构图神经网络的纪检线索多标签分类方法,通过构建基于文本异构图的文本多标签分类模型,利用基于文本异构图的文本多标签分类模型进行分
类,可减少分类时间,提高分类效率。对文本进行预处理,并构建具有文本的结构信息、语义信息和句法信息的异构图结构,对文本的句法信息、语义信息和结构信息进行综合考虑,使文本的向量表示充分融合多种信息,提高文本的表示能力。将异构图结构中的不同类型的节点的向量表示初始化,将得到的节点向量表示和异构图结构输入异构图神经网络,并将得到的句子节点向量表示按句子的顺序输入bilstm神经网络,接着通过内容向量表示和句子节点向量表示的基于注意力机制的文本表示模块,获得基于注意力机制的文本向量表示,最后将文本向量表示输入全连接网络,输出标签分类结果,从而实现针对不同边信息和节点类型信息进行节点更新。解决了现有的纪检线索多标签分类方法存在的分类效率较低,限制了文本的表示能力以及不能根据不同边信息和节点类型信息进行节点更新的技术问题。
附图说明
31.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
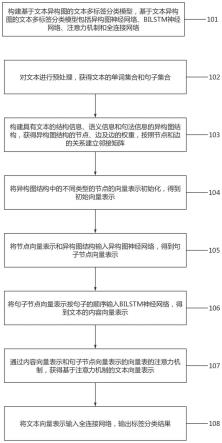
32.图1为本技术实施例中提供的一种基于异构图神经网络的纪检线索多标签分类方法的流程示意图;
33.图2为本技术实施例中提供的基于文本异构图的文本多标签分类模型的结构示意图;
34.图3为本技术实施例中提供的异构图结构的结构示意图;
35.图4为本技术实施例中提供的异构图结构中节点向量表示初始化的流程示意图。
具体实施方式
36.为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
37.为了便于理解,请参阅图1至图4,本技术提供的一种基于异构图神经网络的纪检线索多标签分类方法的一个实施例,包括:
38.步骤101、构建基于文本异构图的文本多标签分类模型,基于文本异构图的文本多标签分类模型包括异构图神经网络、bilstm神经网络、注意力机制和全连接网络。
39.步骤102、对文本进行预处理,构建文本的异构图结构,具体的,获得异构图结构的节点、边及边的权重,按照节点和边的关系建立邻接矩阵,从而获得异构图结构。步骤103、将异构图结构中的不同类型的节点的向量表示初始化,得到初始向量表示。
40.步骤104、将节点向量表示(即初始向量表示)和异构图结构输入异构图神经网络,得到句子节点向量表示。
41.步骤105、将句子节点向量表示按句子的顺序输入bilstm神经网络,得到文本的内容向量表示。
42.步骤106、通过内容向量表示和句子节点向量表示的向量表的注意力机制,获得基
于注意力机制的文本向量表示。
43.步骤107、将文本向量表示输入全连接网络,输出标签分类结果。
44.步骤108、对基于文本异构图的文本多标签分类模型中的异构图神经网络进行迭代训练提取数据特征,计算得到损失函数,并利用随机梯度下降法以降低损失函数数值为目的进行迭代训练,直至满足预期阈值规定,并按照训练结束后得到的参数,对文本进行输入得到标签分类结果。
45.需要说明的是,节点包括由句子集合内的句子转换成的句子节点和由单词集内的词语转换成的词语节点。随机梯度下降(sgd)是一种简单但非常有效的方法,多用用于支持向量机、逻辑回归等凸损失函数下的线性分类器的学习,并且sgd已成功应用于文本分类和自然语言处理中经常遇到的大规模和稀疏机器学习问题,sgd既可以用于分类计算,也可以用于回归计算。
46.构建基于文本异构图的文本多标签分类模型,对文本进行分词、分句、去除停用词,对文本进行句法分析,计算文本中词语的语义相似度,通过对每个句子的词语按共现信息进行结构分析,对文本中的词语按照emebedding的词向量计算词语之间的语义距离,获得文本的单词集合和句子集合。接着构建具有文本的结构信息、语义信息和句法信息的异构图结构,获得异构图结构的节点、边及边的权重,按照节点和边的关系建立邻接矩阵。对于文本可以表示为:s={s1,s2,
…
,sn},s表示文本中的句子集合;w={w1,w2,
…
,wm},w表示文本中词语的集合。异构图结构g={v,e}其中v表示异构图结构中的节点,e表示异构图结构中边的集合,包含边的连接关系及边的权重,v=s∪w,e={e
syn
,e
stu
,e
sem
,e
sw
,e
ss
},其中,e
syn
表示词语之间的句法关系构成的边,有:
[0047][0048]estu
表示词语之间的结构关系构成的边,有:
[0049][0050]
其中pi表示在词语wi句子中的位置。若两个词语在多个句子中共现,则对该值进行叠加。
[0051]esem
表示词语之间的语义关系,有:
[0052]eij
=|cos(hi,hj)|,若|cos(hi,hj)|》α,其中α为阈值参数。
[0053]esw
表示词语是否在句子中出现,若出现则为1否则为0;
[0054]ess
表示句子之间的顺序关系。
[0055]
因此,最终得到文本异构图g。
[0056]
假设有一个文本有两个句子s1和s2,其中s1包含的单词序列为w1w2w3w4,s2包含的单词序列为w5,则每个单词转换为单词节点,单词节点的集合为w={w1,w2,w3,w4,w5},句子节点集合为s={s1,s2}。
[0057]
则构建出的异构图如图3所示的实例,该实例中文档包含两个句子s1,s2。其中s1包含单词w1,w2,w3,w4,s2包含单词w5。在共现距离为2的设置之下,w1与w2相邻接;w2和w1、w3邻接;w3和w2、w4邻接;w4和w3邻接。w1和w4存在语义关系,w2和w1、w4存在句法关系,w4和w3存在句法关系。假设共现窗口的大小为2,构建的异构图结构结构示例如图3所示。其中w2和w3的结构关系的权重为:w2和w2自身的权重为:
[0058]
步骤103:
[0059]
在构建好异构图结构后,将异构图结构中的不同类型的节点的向量表示初始化,对单词集中的词语采用嵌入式的emedding获得词语向量表示将词语向量表示分别输入bilstm模型和不同卷积核的cnn模型,并将两个模型的输出结果进行拼接获得句子的初始向量表示如具体的流程图4所示,其中bilstm为双向长短时记忆网络,cnn为卷积神经网络,emedding是一种将离散变量转变为连续向量的方式。
[0060]
步骤104-步骤106:
[0061]
将初始向量表示和异构图结构输入异构图神经网络,经过了同类型边相邻节点更新和不同类型边的信息融合两个阶段的更新方式更新后获得句子节点向量表示然后再将句子节点按顺序输入到bilstm神经网络中,得到文本内容的向量表示hd。以hd为查询向量,句子节点向量表示为key和value的注意力,并得到基于注意力机制的文本向量表示。其中对相同类型的边的邻接节点按注意力机制获得关注权重并得到该类型信息传递的向量表示。
[0062][0063]w′
是学习参数;表示节点i在第l-1层的向量表示;n
t
表示t类型的邻接节点,[]表示连接操作。
[0064][0065]
表示节点i在l层异构图神经网络中t类型的相邻信息表示,w
t
表示参数矩阵,σ()表示非线性激活函数。
[0066]
对不同类型的边汇聚得到的信息,按照注意力机制获得每种类型的关注权重,并最终得到节点的向量表示。
[0067][0068]
α
t
为注意力机制获得的权重,w
l
为参数矩阵。
[0069]
将句子的向量表示和内容向量表示通过注意力机制获得每个句子的关注权重,并最终得到文本的向量表示
[0070]
α
ds
表示注意力权重,w
″
为学习参数。
[0071]
文本的向量表示为:
[0072][0073]
其中ws是参数矩阵。
[0074]
步骤107-步骤108:最后将文本向量表示输入全连接网络经过sigmod函数输出标签分类结果。接着对基于文本异构图的文本多标签分类模型中的异构图神经网络进行迭代训练提取数据特征,计算得到损失函数,并利用随机梯度下降法以降低损失函数数值为目的进行迭代训练,直至满足预期阈值规定,并按照训练结束后得到的参数,对文本进行输入得到标签分类结果,通过训练后的模型进行文本多标签分类能得到更为准确的标签分类结果。
[0075]
本技术实施例中提供的一种基于异构图神经网络的纪检线索多标签分类方法,构建基于文本异构图的文本多标签分类模型,对纪检线索文本进行分词、分句、去除停用词,利用python中的分词工具jieba对文本进行分词、分句、去除停用词。利用spacy工具对词语进行句法分析,获得句法依赖关系,spacy是世界上最快的工业级自然语言处理工具,支持多种自然语言处理基本功能,spacy主要功能包括分词、词性标注、词干化、命名实体识别、名词短语提取等等。利用glove模型计算词语的语义相似度,glove模型表示的语义词向量相似度尽可能接近在统计共现矩阵中统计相似度,并且不同共现的词有不同权值。对文本进行预处理后获得文本的单词集合和句子集合。然后构建具有文本的结构信息、语义信息和句法信息的异构图结构,获得异构图结构的节点、边及边的权重,按照节点和边的关系建立邻接矩阵。将异构图结构中的不同类型的节点的向量表示初始化,得到初始向量表示。接着将节点向量表示和异构图结构输入异构图神经网络,得到句子节点向量表示,将句子节点向量表示按句子的顺序输入bilstm神经网络,得到纪检线索文本的内容向量表示。最后将纪检线索文本向量表示输入全连接网络,输出标签分类结果,并对该模型进行迭代训练提取数据特征,直至损失函数数值不再减小,计算模型的准确率、召回率以及f值,通过评价指标验证模型的性能,如果f值低于预期阈值,则通过人工干预后进行再次训练,反复迭代,直至f值高于预期阈值,得到训练好的模型,根据训练得到的模型进行纪检线索多标签分类任务,并输出文档对应的标签分类结果,标签分类结果如表1所示。
[0076]
表1纪检线索的标签类型
[0077][0078][0079]
解决了现有的纪检线索多标签分类方法存在的分类效率较低,限制了文本的表示能力以及不能根据不同边信息和节点类型信息进行节点更新的技术问题。
[0080]
以上所述,以上实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
