1.本发明涉及图像增强技术领域,主要涉及一种基于强化学习和美学评估的低光图像增强方法。
背景技术:
2.在恶劣照明条件下拍摄的图片,由于数码相机传感器的入射光亮不足,会导致图像的动态范围低,同时还会受到噪声的严重干扰,难以获得高质量的图像,而低光图像增强在计算机视觉领域扮演着十分重要的角色。低光照拍摄的图片往往会有很多不良影响,例如拍出来的图像模糊导致图像主体不确定,人脸模糊导致识别不准确,细节模糊导致图像表达意思错误。这样的话不仅会影响人使用摄像设备的体验,降低了照片质量;有时候更是会导致传达错误的信息。低光图像增强使拍摄的图像亮度更亮、对比度更高、结构信息更明显,从而有利于后续的高层次工作,比如目标检测、人脸识别、图像分类等,具有很强的现实意义。
3.近年来,基于深度学习的方法通常以高质量的正常光图像作为指导,来学习如何改进和增强低光图像。ll-net( kin gwn lore, adedotun akintayo, and soumik sarkar. 2017. llnet: a deep autoencoder approach to natural low-light image enhancement. pattern recognition 61 (2017), 650
–
662.)提出了一种堆叠自动编码器,利用合成的低光/正常光图像对同时进行去噪和增强。然而,由于其与真实图像的差异,合成数据的分布不可避免地偏离真实世界的图像,因此在转移到真实情况时导致性能严重下降。随后,wei等人( chen wei, wenjing wang, wenhan yang, and jiaying liu. 2018. deep retinex decomposition for low-light enhancement. arxiv preprint arxiv:1808.04560 (2018).)收集了一个具有低光/正常光图像对的真实数据集,在此基础上,提出了视网膜网络以数据驱动的方式将图像分解为照明和反射率。在此之后,还有很多其他有监督的低光图像增强神经网络被提出( wenhan yang, shiqi wang, yuming fang, yue wang, and jiaying liu. 2020. from fidelity to perceptual quality: a semi-supervised approach for low-light image enhancement. in ieee/cvf conference on computer vision and pattern recognition (cvpr).; yonghua zhang, jiawan zhang, and xiaojie guo. 2019. kindling the darkness: a practical low-light image enhancer. in proceedings of the 27th acm international conference on multimedia. 1632
–
1640.)。最近的方法侧重于无监督的低光图像增强,它可以直接使用没有任何配对训练数据的低光图像来对模型进行训练。最近的zero-dce( chunle guo, chongyi li, jichang guo, chen change loy, junhui hou, sam kwong, and runmin cong. 2020. zero-reference deep curve estimation for low-light image enhancement. in proceedings of the ieee/cvf conference on computer vision and pattern recognition. 1780
–
1789.)使用非参考损失来训练深度低光图像增强模型。然而,现有的深度学习方法往往只关注对亮度不足的低光图像的增强,但是在背光条件和光
照不均匀场景下的低光图像中还会存在正常亮度或者过度曝光的现象。
4.另一方面,对于图像增强任务而言,最重要的评价标准就是用户的主观评价。但是在现有的方法中在模型的训练阶段往往都采用有参考/无参考的客观评价指标(损失函数)来指导模型的训练。其中有参考的损失函数主要包括l1损失、l2损失和ssim损失,无参考的损失函数主要使用的是空间一致性损失(spatial consistency loss)、曝光控制损失(exposure control loss)、颜色恒常损失(color constancy loss)和亮度平滑损失(illumination smoothness loss)。以上所述的有参考/无参考损失函数关注的更多是低光图像和正常亮度图像之间的差距以及图像自身的特征,忽略了用户主观评价。
技术实现要素:
5.发明目的:针对上述背景技术中存在的问题,本发明提供了一种基于强化学习和美学评估的低光图像增强方法,首先考虑到低光图像成像方式和场景的复杂性,将动作空间范围定义的更广,不仅包括将图像像素亮度提高的操作,还有将图像像素亮度降低的操作。增强操作可以多次进行,通过学习一个随机增强策略,对于现实场景具有更高的灵活性,其次在计算损失函数时,在使用更灵活的无参考损失的同时,引入了新的可以近似看作用户主观评价指标的美学质量评分作为损失函数的一部分。
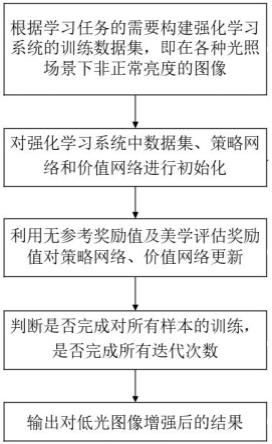
6.技术方案:为实现上述目的,本发明采用的技术方案为:一种基于强化学习和美学评估的低光图像增强方法,包括以下步骤:步骤s1、生成不同光照场景下的非正常亮度图像,并基于所述图像构建强化学习系统的训练数据集;步骤s2、初始化强化学习系统中的训练数据集、策略网络和价值网络;步骤s3、基于无参考奖励值和美学评估奖励值更新策略网络和价值网络;步骤s4、当所有样本训练完成,且完成所有训练迭代次数时,模型训练完毕;步骤s5、输出对低光图像增强后的图像结果。
7.进一步地,所述步骤s2中初始化策略网络和价值网络具体方法包括:使用当前状态作为策略网络和价值网络的输入,代表时间步长t时的状态;策略网络的输出是采取动作的策略;价值网络输出值为,代表来自当前状态的预期总奖励。
8.进一步地,所述步骤s3中更新策略网络和价值网络的具体步骤包括:步骤s3.1、基于历史阶段图像对训练数据集进行训练,获得环境奖励值如下:其中是折扣因子的第i次幂,代表t时刻的环境奖励值;步骤s3.2、基于历史阶段图像对训练数据集进行训练,获得价值网络输出值;步骤s3.3、基于环境奖励值和价值网络输出值对价值网络进行更新:
其中代表价值网络参数;表示对的梯度计算,代表了更新的方向;步骤s3.4、基于环境奖励值和预测价值对策略网络进行更新:所述策略网络的输出采用动作的策略,其中为通过softmax计算得到的概率;a代表动作空间;具体更新如下:通过softmax计算得到的概率;a代表动作空间;具体更新如下:其中代表策略网络参数;表示对的梯度计算,代表了更新的方向。
9.进一步地,所述步骤s3.4中将动作空间a范围设置为,步距为0.05,用于预先定义的输出表示,具体如下:其中代表在t-1步迭代时图像像素点x处的像素值,代表在t步迭代时图像像素点x处选择的动作,代表在t步迭代时图像像素点x处增强后的像素值。
10.进一步地,所述步骤s3.1中环境奖励值考虑以下影响因子:(1)空间一致性损失其中k代表局部区域大小;代表以区域i为中心的四个相邻区域;y代表增强后的图像中局部区域的像素平均灰度值;i代表输入图像中局部区域的像素平均灰度值;(2)曝光控制损失其中e代表图像像素在rgb颜色空间中的灰度水平;m代表非重叠的若干局部区域;y代表增强后的图像中一个局部区域的像素平均灰度值,局部区域的大小为;(3)颜色恒常损失其中代表增强后的图像中p个通道的像素平均灰度值,代表中的任一通道;表示(r,g),(r,b),(g,b)的集合;(4)亮度平滑损失
其中代表每个状态下的参数曲线映射,n代表强化学习中图像增强的迭代次数,和依次代表水平和垂直梯度运算;表示图像中r,g,b三个通道的集合;(5)美学质量损失为了对增强后图像的美学质量进行评分,额外引入图像美学评分深度学习网络模型来对图像进行美学评分,进而计算美学质量损失;分别利用图像的颜色和亮度属性以及质量属性训练两个独立的美学评分模型,记为和;通过一个额外引入的美学评估模型进行评分;美学质量损失表示如下:其中表示增强后的图像中颜色和亮度属性的评分,即将增强后的图像输入到后输出的分数;表示增强后的图像质量属性的评分,即将增强后的图像输入到后输出的分数,评分越高表示图像的质量越好;和均为权重系数;图像增强的目标是使奖励值r尽可能大;空间一致性损失、曝光控制损失、颜色恒常损失和亮度平滑损失越小表示图像质量越好,美学质量损失越大表示图像质量越好;因此,在t时刻的奖励值表示如下:t时刻的环境奖励值在引入影响因子的条件下表示如下:。
11.进一步地,空间一致性损失中将局部区域大小k设置为4
×
4。
12.进一步地,曝光控制损失中将e设置为0.6,m代表大小为16
×
16的非重叠局部区域。
13.有益效果:(1)本发明通过对强化学习中定义的动作空间范围扩大,输入的低光图像得到的增强操作就有了更大的动态范围,对于现实场景具有更高的灵活性。考虑到低光场景中的光照不均匀和背光等情况,不仅设置了将图像亮度增强的动作,而且动作空间中还包括将图像亮度变暗的行为,这样的定义方式能更好的满足真实场景下的低光图像增强需求。
14.(2)本发明通过引入美学质量评估的分数作为损失函数的一部分,可以使增强后的图像具有更好的视觉效果及用户主观评价得分。在现有的基于深度学习的低光增强方法中,大多数方法依赖于成对的训练数据集并采用有参考的损失函数,也有部分方法利用图像自身的信息设计了无参考的损失函数来指导增强网络的训练。但是上述损失均为客观评价指标,本发明引入美学评估分数作为模拟用户主观评价的指标,能够更好的指导低光图
像增强网络生成用户满意的高质量图像。
附图说明
15.图1是本发明提供的基于强化学习和美学评估的低光图像增强方法流程图;图2是本发明提供的基于强化学习和美学评估的低光图像增强方法的算法框架图。
具体实施方式
16.下面结合附图对本发明作更进一步的说明。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
17.本发明提供了一种基于强化学习和美学评估的低光图像增强方法,具体原理如图1所示,包括以下步骤:步骤s1、生成不同光照场景下的非正常亮度图像,并基于图像构建强化学习系统的训练数据集。
18.步骤s2、初始化强化学习系统中的训练数据集、策略网络和价值网络。
19.具体地,参考图2,使用当前状态作为策略网络和价值网络的输入,代表时间步长t时的状态。策略网络的输出是采取动作的策略。价值网络输出值为,代表来自当前状态的预期总奖励,这显示了当前网络状态有多好。
20.步骤s3、基于无参考奖励值和美学评估奖励值更新策略网络和价值网络。具体地,步骤s3.1、基于历史阶段图像对训练数据集进行训练,获得环境奖励值如下:其中是折扣因子的第i次幂。代表t时刻的环境奖励值。计算环境奖励值时考虑以下影响因子:(1)空间一致性损失其中k代表局部区域大小。代表以区域i为中心的四个相邻区域。y代表增强后的图像中局部区域的像素平均灰度值。i代表输入图像中局部区域的像素平均灰度值。本实施例中根据经验将局部区域大小k设置为4
×
4。
21.(2)曝光控制损失其中e代表图像像素在rgb颜色空间中的灰度水平。m代表非重叠的若干局部区域。
y代表增强后的图像中一个局部区域的像素平均灰度值,局部区域的大小为;本实施例中将e设置为0.6,m代表大小为16
×
16的非重叠局部区域。
22.(3)颜色恒常损失其中代表增强后的图像中p个通道的像素平均灰度值,代表中的任一通道,表示(r,g),(r,b),(g,b)的集合;(4)亮度平滑损失其中代表每个状态下的参数曲线映射,n代表强化学习中图像增强的迭代次数,和依次代表水平和垂直梯度运算,表示图像中r,g,b三个通道的集合;。
23.(5)美学质量损失目前美学图像分析在计算机视觉领域中引起了越来越多的关注。它与对视觉美学的高级感知有关。用于图像美学质量评估的机器学习模型具备广泛应用前景,如图像检索、照片管理、图像编辑和摄影等。对于人类来说,审美质量评价总是与图像的颜色和亮度、图像的质量、构图和深度以及语义内容相关联。很难将审美质量评价视为一项孤立的任务。为了对增强后图像的美学质量进行评分,本发明额外引入图像美学评分深度学习网络模型来对图像进行美学评分,进而计算美学质量损失。分别利用图像的颜色和亮度属性以及质量属性训练两个独立的美学评分模型,记为和。美学质量损失的表示如下:其中表示增强后的图像中颜色和亮度属性的评分,即将增强后的图像输入到后输出的分数。表示增强后的图像质量属性的评分,即将增强后的图像输入到后输出的分数,评分越高表示图像的质量越好。和均为权重系数。
24.图像增强的目标是使奖励值r尽可能大。空间一致性损失、曝光控制损失、颜色恒常损失和亮度平滑损失越小表示图像质量越好,美学质量损失越大表示图像质量越好。因此,在t时刻的奖励值表示如下:t时刻的环境奖励值在引入影响因子的条件下表示如下:。
25.步骤s3.2、基于历史阶段图像对训练数据集进行训练,获得价值网络输出值。
26.步骤s3.3、基于环境奖励值和价值网络输出值对价值网络进行更新:其中代表价值网络参数。表示对的梯度计算,代表了更新的方向。
27.步骤s3.4、基于环境奖励值和价值网络输出值对策略网络进行更新:策略网络的输出采用动作的策略,其中为通过softmax计算得到的概率。a代表动作空间。具体更新如下:过softmax计算得到的概率。a代表动作空间。具体更新如下:其中代表策略网络参数。表示对的梯度计算,代表了更新的方向。
28.在增强操作的每一步中,首先将该状态下的低光图像输入策略网络。策略网格根据当前输入的图像对图像中每个像素制定一个增强策略并输出。输入的图像根据策略网络制定的策略执行增强操作。该增强操作在预先制定的方案需要迭代多次。
29.动作空间a对于网络的性能而言至关重要,因为太小的范围会导致对低光图像的增强有限,而太大的范围会导致非常大的搜索空间,网络训练会变得非常困难。本实施例中,根据经验设置范围a∈[
−
0.5,0.5],步距为0.05。这一设置作用在预先定义的输出表示,具体如下:其中代表在t-1步迭代时图像像素点x处的像素值,代表在t步迭代时图像像素点x处选择的动作,代表在t步迭代时图像像素点x处增强后的像素值。
[0030]
类似照片编辑软件中使用的图像亮度曲线调整,这里预先定义的输出表示是一个二次曲线,表示为:其中x表示像素坐标,是调整参数。表示输入图像x坐标处的像素值,像素值被归一化在[0,1]范围内,表示经过调整参数调整后输出的像素值。
[0031]
上述设置可以确保:a、每个像素都在[0,1]的归一化范围内。
[0032]
b、降低了寻找合适增强策略的成本。对于不同的增强迭代次数选择,我们的增强曲线可以有效地覆盖该动作空间设置下的像素值空间。
[0033]
步骤s4、当满足对所有样本训练完成,且完成所有训练迭代次数时,模型训练完成。
[0034]
步骤s5、输出对低光图像增强后的图像结果。
[0035]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。