1.本发明属于智能电网技术领域,涉及电网潮流调控的人工智能增强,特别涉及一种基于分层的深度策略梯度网络的电网调控方法。
背景技术:
2.电网是国民经济运行的核心基础设施,是高维紧耦合复杂动力学系统。通过向工业、服务和消费者提供可靠的电力,发挥着中心的经济和社会作用。电网运行调度与调控高度依靠安全稳定自动化装置作为第一道安全防线,防线失效后,整个系统最终的安全由人对电网的经验认知决策来保障。
3.传统的电网调控系统很难对调控策略及时进行调整,且调控策略制定周期较长。现有的调控策略通常是调度人员根据的电网安全稳定分析技术,通过计算机仿真计算,充分掌握电网安全运行的特征和规律,并需要迅速、精确地明晰电网薄弱点离线制定故障策略,因此十分依赖人工的经验。随着现代电网中可再生能源的不断接入,电网的运行方式的复杂性与时变性不断增加,使得调度员对安全运行时的特征信息与规律难以掌握,处理可再生能源和其他系统突发事件引起的不确定性方面的能力有限,传统的调控规则不能完全适应,面临重大的适应性和鲁棒性问题,增加了电网运行的风险。
4.现有的电网智能化调控方法多通过在电力系统的运行与管理中产生的海量数据与信息,提取电网中的关键特征帮助调度人员更有效的获取电网关键信息,或者根据电网运行状态制定精细的决策树辅助决策。然而当电网结构发生改变时,建立的电网调控模型需要重新设计和训练,无法根据电网整体状况确定调控策略,难以保证电网全局决策的可靠性和敏捷性。因此亟需建立泛化能力更强的,效率更高的电网调控模型。
5.文献[孙宏斌,黄天恩,郭庆来,等.面向调度决策的智能机器调度员研制与应用[j].电网技术,2020,44(1):1-8.]提出了一种电网调度运行“邻域知识”模型,该方法通过海量样本,并基于机器学习形成运行规则和知识图谱。
[0006]
文献[lan t,duan j,zhang b,et al.ai-based autonomous line flow control via topology adjustment for maximizing time-series atcs[c]//2020ieee power&energy society general meeting(pesgm).ieee,2020:1-5.]提出了一种模仿学习与深度强化学习相结合的方法,从而有效地提高了系统的容错性和鲁棒性。
[0007]
文献[kim b g,zhang y,van der schaar m,et al.dynamic pricing and energy consumption scheduling with reinforcement learning[j].ieee transactions on smart grid,2015,7(5):2187-2198.]、[lincoln r,galloway s,stephen b,et al.comparing policy gradient and value function based reinforcement learning methods in simulated electrical power trade[j].ieee transactions on power systems,2011,27(1):373-380.]通过开发强化学习q值学习(q learning)算法,在无需微电网相关的先验信息前提下,帮助微电网运行智能动态定价和客户的能耗调度策略,有效地平衡微电网经济管理运行和负载的能耗需求。
[0008]
文献[黄天恩,孙宏斌,郭庆来,等.基于电网运行大数据的在线分布式安全特征选择[j].电力系统自动化,2016,40(4):32-40.]提出了一种基于电网特征量相关性分组、适应于电网运行大数据的在线分布式安全特征选择方法,该方法能在线挖掘出关键的电网安全运行特征。
[0009]
[duan j,shi d,diao r,et al.deep-reinforcement-learning-based autonomous voltage control for power grid operations[j].ieee transactions on power systems,2019,35(1):814-817.]基于深度强化学习技术,提出具有在线学习功能的电网自主优化控制和决策框架,即“电网脑”系统,该方案使用深度q值学习网络(deep q-learning,dqn)和深度确定性策略梯度网络(deep deterministic policy gradient network,ddpg)两种最新drl算法解决自动电压控制问题,ai智能体可以学习和解决考虑各种不确定性和实际约束的电网下各发电设备出力问题。
[0010]
由此可见基于传统的机器学习算法的研究无法满足电网的运行方式的复杂性,和电网需要的全局决策的可靠性和敏捷性,而深度强化学习技术已经成为了解决电网调控问题的有效方法。为此本发明针对深度强化学习技术应用在电网高维的连续状态空间与高维离散动作空间的环境下,在电网调控中深度强学学习模型训练与探索的效率情况,提出一种更有效的决策方法,提升在实际电网应用中的效果。
技术实现要素:
[0011]
为了克服上述现有技术的不足,本发明的目的是在于提供一种基于分层的深度策略梯度网络的电网调控方法,基于深度强化学习的智能体与仿真电网环境的交互,学习大量电网调控知识和电网状态与调控行为的映射关系,对电网实时调控提供一种可行手段,并针对复杂问题存在的高维状态和动作空间进行算法设计。
[0012]
为了实现上述目的,本发明采用的技术方案是:
[0013]
一种基于分层的深度策略梯度网络的电网调控方法,包括:
[0014]
步骤1,获取电网信息,构建状态空间和动作空间,所述状态空间和动作空间均由连续空间变量和离散空间变量组成;所述状态空间的连续空间变量包括时间、发电机发电功率和机端电压、负载功率、节点电压、线路潮流值以及电压,离散空间变量包括网络拓扑结构;所述动作空间的连续空间变量包括发电机出力调整和负载功率调整,离散空间变量包括传输线路通断状态和变电站节点内双母线与各元器件的连接拓扑结构;
[0015]
步骤2,对所述动作空间进行聚类,使得每个簇的动作数目相等;
[0016]
步骤3,为电网设计其状态表征向量s和动作表征向量a;
[0017]
步骤4,基于分层的策略梯度网络设计电网调控模型,所述电网调控模型共有两层,每层均为独立的策略梯度网络,将状态表征向量s作为每层策略梯度网络的输入,使用策略梯度算法训练电网调控模型,进行连续选择,电网调控模型的第一层先选择动作簇,第二层再选择簇内具体动作,其中,在给定状态s
t
后输出具体电网动作a
t
的概率是两次选择的概率的乘积;
[0018]
步骤5,基于离散化的电网运行数据集仿真电网运行环境,将所述电网调控模型和仿真电网运行环境进行交互,电网调控模型从仿真电网运行环境中得到当前状态和要执行的最终动作,将要执行的最终动作交由仿真电网运行环境执行,实现电网调控的目的,并反
馈即时奖励,将电网的状态、电网调控的动作以及反馈得到的奖励组合,收集经验样本数据;
[0019]
步骤6,根据收集经验样本数据和返回的奖励估计动作的价值,并更新网络参数,然后返回执行步骤5,实现对仿真电网运行环境不断交互,并达到训练电网调控模型的目的。
[0020]
所述步骤2中,引入仿真环境探索机制对动作空间进行降维处理,经过降维后的动作空间中,将每个电网动作在电网环境执行前后的电网的状态信息,即电网中每条电力传输线中的电流值的大小,作为表示该电网动作的特征向量,然后对此进行聚类操作。
[0021]
所述聚类采用k-means算法,首先随机选择动作空间中的k个电网动作的特征向量作为初始的聚类中心,对其余的特征向量则计算它们与各聚类中心的距离并就近归类,然后通过迭代的方式,多次更新聚类中心,直至获取到每类数目相等的聚类结果,即同一个簇中的对象相似度高,不同簇中的对象相似度低。
[0022]
所述步骤3,利用编号将电网中包含的元器件和传输线路进行表示和对应,所述元器件包括变电站节点、发电机节点和负载节点;然后将元器件和传输线路包含的变量构成一维的状态表征向量s;
[0023]
将发电机出力功率调整和负载功率调整的具体增/减功率值放入一维动作向量s对应编号位置,通过1、0代表传输线路通/断状态切换动作,通过0、1、2代表变电站节点内各元器件与双母线的连接状态,0表示该元器件与所有母线断开,1代表该元器件与1号母线连接,2代表该元器件与2号母线连接,得到动作表征向量a。
[0024]
所述步骤4,以当前状态表征向量s
t
作为每层策略梯度网络的输入,初始化策略θ=(θ1,θ2),θ1和θ2分别表示第一层策略梯度网络和第二层策略梯度网络的目标策略的参数向量,p
t
表示在时间步t从第一层策略梯度网络的状态输入到第二层策略梯度网络的目标策略输出的路径,该路径由两次选择组成,第一层策略梯度网络每个选择均表示为1到c1之间的整数,第二层策略梯度网络表示1到c2之间的整数,c1是动作聚类后簇的个数,c2是簇内具体动作的个数。
[0025]
所述步骤5中,根据得到的奖励计算
[0026][0027]
并计算策略函数:
[0028][0029]
更新网络参数,对网络的更新损失函数如下:
[0030][0031]
式中,表示当前状态表征向量s
t
下对策略网络输出后选择的电网动作a
t
的价值估计,其中γ为折扣奖励系数,γ∈[0,1],n是一次序列的长度,即采样次数;θ为策略梯度网络参数,表示当前输入时对策略网络的输出求梯度,s
t
、a
t
表示第t时刻下的状态表征向量、动作表征向量,π
θ
′
(a
t
|s
t
)为当前状态表征向量s
t
下策略网络的输出,
表示当前状态表征向量s
t
下对策略网络输出后选择的a
t
的价值估计;
[0032]
更新策略梯度网络的网络参数,如下式:
[0033]
θ=θ αδθ
[0034]
式中,θ为策略梯度网络参数,α为更新步长即学习率,且α∈[0,1]。
[0035]
与现有技术相比,本发明学习大量电网调控知识和电网状态与调控行为的映射关系,对电网实时调控提供一种可行手段,在高维空间下对模型的训练和收敛速度有重要影响,理论和实验证明本发明能够适用于实际复杂电网调控场景。
附图说明
[0036]
图1是本发明整体流程图。
[0037]
图2是本发明实施例中电网结构编号示意图。
[0038]
图3是本发明实施例中基于分层策略梯度网络设计的电网调控模型结构图。
具体实施方式
[0039]
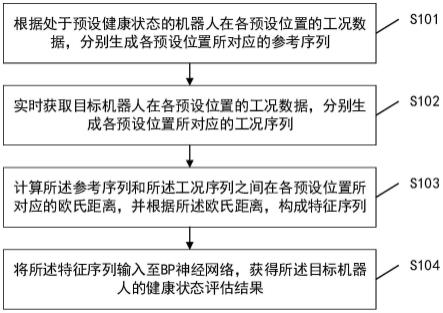
下面结合附图和实施例对本发明做进一步详细说明。
[0040]
如图1所示,本发明为一种基于分层的深度策略梯度网络的电网调控方法,包括如下步骤:
[0041]
步骤1:获取电网信息,构建状态空间和动作空间。
[0042]
电网的状态空间和动作空间均由连续空间变量和离散空间变量组成。一般地,状态空间的连续空间变量包括时间、发电机发电功率和机端电压、负载功率、节点电压、线路潮流值以及电压等,离散空间变量主要包括网络拓扑结构。动作空间的连续变量包括发电机出力调整和负载功率调整等,离散变量包括传输线路通断状态和变电站节点内双母线与各元件的连接拓扑结构等。
[0043]
步骤2,对动作空间进行聚类,使得每个簇的动作数目相等。
[0044]
在电网的动作空间中,调整电网拓扑结构的动作空间中存在大量的无实际意义的动作。对于此,本发明的一个实施例中,引入仿真环境探索机制对动作空间进行降维处理。具体操作是针对电网种子数据集(数据集中包含不同年份、月份、日期的离散化电网运行种子数据,每一份都是一种不同的运行场景)中的每一场景进行仿真运行,遍历执行动作空间中的某一动作,记录该动作解决故障的能力,并量化为所获取的即时奖励,重复该步骤(状态输入,动作选择,动作执行,反馈奖励和下一状态),直到探索的电网场景数量达到训练的数据集总场景数量的比例n(超参数,介于0~1)为止。如果平均奖励值为负,则认为该动作的潜在价值为负,从动作空间中删除该动作,从而实现对动作空间的降维处理。以此可简化动作空间,提高网络的探索效率。
[0045]
经过降维后的动作空间中,将每个电网动作在电网环境执行前后的电网的状态信息,即电网中每条电力传输线中的电流值的大小,作为表示该电网动作的特征向量,然后对此进行聚类操作,使得对电网环境解决故障作用相似的动作可以被划分到一个簇中,构成动作类。
[0046]
示例地,本发明的聚类采用k-means算法,首先随机选择动作空间中的k个电网动
作的特征向量作为初始的聚类中心,对其余的特征向量则计算它们与各聚类中心的距离并就近归类,然后通过迭代的方式,多次更新聚类中心,直至获取到每类数目相等的聚类结果,即同一个簇中的对象相似度高,不同簇中的对象相似度低。
[0047]
步骤3,为电网设计其状态表征向量s和动作表征向量a。
[0048]
针对要应用的具体电网结构,如图2所示,确定电网中包含的变电站节点、发电机节点、负载节点和传输线路等的数量,并进行编号。利用编号将电网中包含的变电站节点、发电机节点、负载节点等元器件和传输线路进行表示和对应。然后将元器件和传输线路包含的变量放入合适位置构成一维的状态表征向量s。如发电机节点包含发电功率和机端电压变量、负载节点包含负载功率变量、变电站和传输线路包含通过编号连接代表拓扑结构等。将发电机出力功率调整和负载功率调整的具体增/减功率值放入一维动作向量s对应编号位置,通过1、0代表传输线路通/断状态切换动作,通过0、1、2代表变电站节点内各元器件与双母线的连接状态,0表示该元器件与所有母线断开,1代表该元器件与1号母线连接,2代表该元器件与2号母线连接,得到动作表征向量a。
[0049]
其中,对状态中的组成部分解释如下:
[0050]
时间:电网运行的实时时刻,具体到年月日时分;
[0051]
发电机的发电功率:当前时间,每台发电机发出的有功功率p与无功功率q;
[0052]
机端电压:当前时间,每台发电机的出口电压;
[0053]
负载功率:当前时间,每个负载节点(如一个用电区域等效为一个整体)的总功率(包括有功功率和无功功率);
[0054]
节点电压:当前时间,每个变电站节点的电压值;
[0055]
线路潮流值及电压:当前时间,每条电力传输线中的电流值及其两端电压值;
[0056]
网络拓扑结构:当前时间,电网中所有元器件的连接关系和状态。
[0057]
步骤4,基于分层的策略梯度网络设计电网调控模型,电网调控模型共有两层,每层均为独立的策略梯度网络,将状态表征向量s作为每层策略梯度网络的输入(可经过归一化等数据预处理函数进行预处理),使用策略梯度算法训练电网调控模型,进行连续选择,电网调控模型的第一层先选择动作簇,第二层再选择簇内具体动作,其中,在给定状态s
t
后输出具体电网动作a
t
的概率是两次选择的概率的乘积。
[0058]
本发明的电网调控模型中共有两次策略的选择,第一次策略是选择动作所在的类a(s),第二次策略选择是在上次选择的簇中选择具体的动作a。图3所示为分层的电网调控模型,其中一级网络即模型第一层,二级网络即模型第二层。
[0059]
步骤5,基于离散化的电网运行数据集仿真电网运行环境,将电网调控模型和仿真电网运行环境进行交互,电网调控模型从仿真电网运行环境中得到当前状态和要执行的最终动作,将要执行的最终动作交由仿真电网运行环境执行,实现电网调控的目的,并反馈即时奖励,将电网的状态、电网调控的动作以及反馈得到的奖励组合,收集经验样本数据。
[0060]
网络训练的目的是最大限度地提高预期的折现累积奖励,即
[0061][0062]
其对参数的梯度计算是:
[0063][0064]
其中π
θ
(a|s)是在状态s采取动作a的概率,而q
π
(s,a)表示以s和a开头的预期折现累积奖励,可以通过对遵循策略的轨迹进行采样来凭经验估算π
θ
。
[0065]
具体地,本发明电网调控模型的设计与训练方法如下:
[0066]
步骤3.1,确定深度分层策略梯度网络的结构参数,如输入层、隐藏层和输出层的神经元个数、激活函数、参数初始化等超参数。
[0067]
步骤3.2,以当前电网状态表征向量s
t
作为每层策略梯度网络的输入,初始化策略θ=(θ1,θ2),θ1和θ2分别表示第一层策略梯度网络和第二层策略梯度网络的目标策略的参数向量,p
t
表示在时间步t从第一层策略梯度网络的状态输入到第二层策略梯度网络的目标策略输出的路径,该路径由两次选择组成,第一层策略梯度网络每个选择均表示为1到c1之间的整数,第二层策略梯度网络表示1到c2之间的整数,c1是动作聚类后簇的个数,c2是簇内具体动作的个数。电网动作的输出,是对应于p
t
的两次选择,沿着p
t
遍历两层策略梯度网络,最后到达第二层策略梯度网络的输出;这样,路径p
t
被映射到a
t
处的电网动作,因此在电网环境中,给定状态s
t
时,选择某一个电网动作输出的概率是沿p
t
进行两次选择的概率的乘积,在第二层得到具体的动作a
t
。在电网环境中执行,并得到反馈即时奖励值r
t
和下一时刻状态表征向量s
t 1
;将电网的状态,电网调控的动作,以及反馈得到的奖励组《s
t
,r
t
,a,s
t 1
》,收集经验样本数据。
[0068]
步骤3.3,根据得到的奖励计算
[0069][0070]
并计算策略函数,因为经过了两次策略的选择,因此策略函数的计算为:
[0071][0072]
式中,表示当前状态表征向量s
t
下对策略网络输出后选择的电网动作a
t
的价值估计,其中γ为折扣奖励系数,γ∈[0,1],n是一次序列的长度,即采样次数。
[0073]
步骤3.4,更新网络参数,对网络的更新损失函数如下:
[0074][0075]
式中,θ为策略梯度网络参数,表示当前输入时对策略网络的输出求梯度,s
t
、a
t
表示第t时刻下的状态表征向量、动作表征向量,π
θ
′
(a
t
|s
t
)为当前状态表征向量s
t
下策略网络的输出,表示当前状态表征向量s
t
下对策略网络输出后选择的a
t
的价值估计。
[0076]
步骤3.5:更新策略梯度网络的网络参数,如下式:
[0077]
θ=θ αδθ
[0078]
式中,θ为策略梯度网络参数,α为更新步长即学习率,且α∈[0,1]。
[0079]
以上为分层策略梯度网络设计过程,如图3所示流程。
[0080]
步骤6,根据设计好的网络损失函数、优化目标等,使用采样的样本数据计算损失,
通过梯度反向传播更新优化网络参数。基于更新后的网络参数,继续使网络与仿真电网环境交互收集新的更加多样性的电网样本数据,根据收集经验样本数据和返回的奖励估计动作的价值,并更新网络参数,然后返回执行步骤5,实现对仿真电网运行环境不断交互,直至网络收敛,达到训练电网调控模型的目的。收敛后的模型可以直接在电网出现故障时,输出能够解决故障的电网动作达到快速响应解决故障的目的。
[0081]
以上即为基于分层策略网络的电网调控模型的设计过程,如图所示的逻辑流程。本发明中,由于电网动作空间是由变电站节点内双母线与各元件的连接拓扑结构调整等部分组成,均为离散空间变量,由于电网物理结构的限制,只能以固定的排列组合进行调整,不可随意增加或删除元器件以达到使拓扑结构连续更改的目的。
[0082]
因此,本发明基于分层的策略梯度网络在电网潮流调控问题中的应用条件便可满足——网络的输入和输出均为离散空间。而对于决策推理在电网潮流调控问题中的解释,本发明认为在实际电网调控中的某一时刻状态下,有效的调控行为并不唯一,可能存在一对多的情况;反过来,一种调整动作也并不仅仅只对某一种状态有效,完全可能存在多对一的情况。
[0083]
本发明的整体流程可总结为如下算法:
[0084]
输入:迭代回合数t,电网状态表征向量s和动作表征向量a,衰减系数γ,更新系数α,动作簇的数目c1,簇内动作的数目c2,batch_size=n,策略网络参数θ;
[0085]
输出:最优策略网络参数θ;
[0086]
初始化:对电网的动作空间进行k-means聚类操作,得到c1个动作簇{a1,a2,
…ac1
},随机初始化每个策略梯度网络参数θ;
[0087]
对于每个回合,循环操作:
[0088]
step 1初始化起始电网状态表征s;
[0089]
对当前回合的每个时步,循环操作:
[0090]
step 2两层策略网络分别输出当前电网状态下的动作簇的编号i,以及簇内具体电网动作编号j,其中i∈[1,c1],j∈[1,c2];
[0091]
step 3根据两次选择p
t
=(i,j),得到对应的电网动作a
t
;
[0092]
step 4根据当前电网状态s
t
,经过策略网络得到电网动作a
t
,并对电网仿真环境实施,获取奖励r
t 1
和电网环境下的新状态s
t 1
;
[0093]
step 5生成一幕序列s0,a0,r1,s1,a1,r2,
…
,s
t-1
,a
t-1
,r
t
,s
t
;
[0094]
对于每一步循环,t=0,1,
……
t-1
[0095]
step 6计算q值:
[0096][0097]
step 7根据p
t
两次选择的路径得到p
t1
及p
t2
,计算策略函数:
[0098][0099]
其中策略函数是softmax策略函数,softmax策略使用描述状态和行为的特征φ(s,a)与参数θ的线性组合来权衡一个行为发生的几率
[0100][0101]
step 8使用如下损失函数,通过反向传播更新网络参数θ:
[0102][0103]
step 9更新全局神经网络的网络参数,如下式:
[0104]
θ=θ αδθ
[0105]
step 10直至到达终止状态s,结束当前回合
[0106]
训练结束后的模型可以直接在电网出现故障时,输出能够解决故障的电网动作达到快速响应实现电网调控的目的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。