基于机器学习模型的网页数据抽取方法
1.技术领域
2.本发明涉及数据处理技术领域,尤其涉及一种基于机器学习模型的网页数据抽取方法。
3.
背景技术:
4.信息时代网页作为互联网信息的主要载体提供了大量的文本信息,虽然图像、音视频等多媒体信息也在日益增多,但是网页文本依旧是互联网信息的主要载体,是研究以及数据挖掘的主要来源。
5.现有的网页数据抽取的最传统的三种方式:1、基于正则表达式的网页提取;2、基于css选择器的网页抽取;3、基于xpath的网页提取,这三种网页抽取都是基于包装器(wrapper)的网页抽取,这类抽取算法的通病就在于,对于不同结构的网页,要制定不同的抽取规则,降低了数据抽取效率。
6.
技术实现要素:
7.本发明的目的在于提供一种基于机器学习模型的网页数据抽取方法,旨在解决现有的网页数据抽取对于不同结构的网页,要制定不同的抽取规则,降低了数据抽取效率的问题。
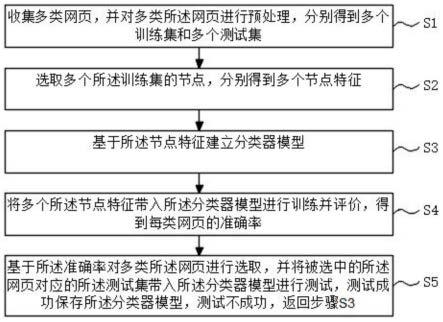
8.为实现上述目的,本发明提供了一种基于机器学习模型的网页数据抽取方法,包括以下步骤:s1收集多类网页,并对多类所述网页进行预处理,分别得到多个训练集和多个测试集;s2选取多个所述训练集的节点,分别得到多个节点特征;s3基于所述节点特征建立分类器模型;s4将多个所述节点特征带入所述分类器模型进行训练并评价,得到每类网页的准确率;s5基于所述准确率对多类所述网页进行选取,并将被选中的所述网页对应的所述测试集带入所述分类器模型进行测试,测试成功保存所述分类器模型,测试不成功,返回步骤s3。
9.其中,所述收集多类网页,并对多类所述网页进行预处理,分别得到多个训练集和多个测试集的具体方式为:s11收集多类网页;s12对多类所述网页进行规范化,得到多个规范化网页;s13对多个所述规范化网页的正文和非正文进行人工标注,分别得到多个标注信
息;s14基于多个所述标注信息将每一所述规范化网页的所述正文抽取,并将所述正文划分为训练集和测试集。
10.其中,所述将多个所述节点特征带入所述分类器模型进行训练并评价,得到每类网页的准确率的具体方式为:s41将多个所述节点特征带入所述分类器模型进行训练,分别得到多个训练结果;s42使用评价指标对多个所述训练结果进行评价,分别得到每类网页的准确率。
11.其中,所述分类器模型包括决策树、支持向量机、神经网络、逻辑回归、朴素贝叶斯和knn中的任意一种。
12.其中,所述评价指标包括查全率、查准率和f值。
13.本发明的一种基于机器学习模型的网页数据抽取方法,通过收集多类网页,并对多类所述网页进行预处理,分别得到多个训练集和多个测试集;选取多个所述训练集的节点,分别得到多个节点特征;建立分类器模型;将多个所述节点特征带入所述分类器模型进行训练并评价,得到每类网页的准确率;基于所述准确率对多类所述网页进行选取,并将被选中的所述网页对应的所述测试集带入所述分类器模型进行测试,测试成功保存所述分类器模型,经多类网页的所述训练集训练得出的所述分类模型应用于不同结构的网页,解决了现有的网页数据抽取对于不同结构的网页,要制定不同的抽取规则,降低了数据抽取效率的问题。
14.附图说明
15.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
16.图1是本发明提供的一种基于机器学习模型的网页数据抽取方法的流程图。
17.图2是收集多类网页,并对多类所述网页进行预处理,分别得到多个训练集和多个测试集的流程图。
18.图3是将多个所述节点特征带入所述分类器模型进行训练并评价,得到每类网页的准确率的流程图。
[0019] 具体实施方式
[0020]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
[0021]
请参阅图1至图3,本发明提供一种基于机器学习模型的网页数据抽取方法,包括以下步骤:s1收集多类网页,并对多类所述网页进行预处理,分别得到多个训练集和多个测
试集;具体方式为:s11收集多类网页;具体的,收集大量的网页,根据网页文本内容的相似性大概分为几类,如新闻类、政府类、招投标类、博客类等。
[0022]
s12对多类所述网页进行规范化,得到多个规范化网页;具体的,采用html tidy工具将多类所述网页转换为规范的dom树,dom树是一个对象模型(dom)节点 (nodes)的集合,补全由书写导致的标签对不全,嵌套不规范等问题,得到规范化网页。
[0023]
s13对多个所述规范化网页的正文和非正文进行人工标注,分别得到多个标注信息;具体的,对多个所述规范化网页的正文和非正文进行人工标注,即需要抽取和不需要抽取的部分,所述正文为需要抽取的部分,所述非正文为不需要抽取的部分。
[0024]
s14基于多个所述标注信息将每一所述规范化网页的所述正文抽取,并将所述正文划分为训练集和测试集。
[0025]
具体的,基于多个所述标注信息将每一所述规范化网页的所述正文抽取,并将所述正文按比例划分为训练集和测试集。
[0026]
s2选取多个所述训练集的节点,分别得到多个节点特征;具体的,以新闻类网页举例,新闻类网页存在大量的文本信息和少量的图片,现代网页结构设计一般用《p》《/p》标签构成段落,在《p》《/p》标签中每行文字嵌套在《span》《/span》标签对中,文章标题一般采用“文章标题” “网站名”放在《title》标签中,且用
“‑”
或者“_”连接在一起,连着
“‑”
或者“_”及后面的文字一起删掉即为文章标题。因此,在选取网页dom树的标签类型作为特征时,可以选择title,div,p,span,img,body等节点,选取节点时,尽量选取较固定的标签。
[0027]
s3基于所述节点特征建立分类器模型;具体的,所述分类器模型包括但不限于决策树、支持向量机、神经网络、逻辑回归、朴素贝叶斯和knn中的任意一种。
[0028]
s4将多个所述节点特征带入所述分类器模型进行训练并评价,得到每类网页的准确率;具体方式为:s41将多个所述节点特征带入所述分类器模型进行训练,分别得到多个训练结果;具体的,依次将多个所述节点特征带入所述分类器模型进行训练,使得每一所述节点特征输出一个对应的测试结果,得到多个测试结果。
[0029]
s42使用评价指标对多个所述训练结果进行评价,分别得到每类网页的准确率。
[0030]
具体的,使用评价指标对多个所述训练结果进行评价,分别得到每类网页的准确率,并建立表格记录所述准确率,所述评价指标为信息抽取技术中常用的查全率(r)、查准率(p)和f值,f值是:f(k)=(1 k)*p*r/((k*k)*p r)注释:k》0度量了查全率对查准率的相对重要性。
[0031]
s5基于所述准确率对多类所述网页进行选取,并将被选中的所述网页对应的所述测试集带入所述分类器模型进行测试,测试成功保存所述分类器模型,测试不成功,返回步
骤s3。
[0032]
具体的,返回步骤s3时,当上一次所述分类器模型选取的决策树、支持向量机、神经网络、逻辑回归、朴素贝叶斯和knn中的决策树时,在重新建立分类器模型时,可选取支持向量机、神经网络、逻辑回归、朴素贝叶斯和knn中的任意一种。
[0033]
本发明的一种基于机器学习模型的网页数据抽取方法,收集多类网页;对多类所述网页进行规范化,得到多个规范化网页;对多个所述规范化网页的正文和非正文进行人工标注,分别得到多个标注信息;基于多个所述标注信息将每一所述规范化网页的所述正文抽取,并将所述正文划分为训练集和测试集;选取多个所述训练集的节点,分别得到多个节点特征;建立分类器模型;多个所述节点特征带入所述分类器模型进行训练,分别得到多个训练结果;使用评价指标对多个所述训练结果进行评价,分别得到每类网页的准确率;基于所述准确率对多类所述网页进行选取,并将被选中的所述网页对应的所述测试集带入所述分类器模型进行测试,测试成功保存所述分类器模型,经多类网页的所述训练集训练得出的所述分类模型应用于不同结构的网页,解决了现有的网页数据抽取对于不同结构的网页,要制定不同的抽取规则,降低了数据抽取效率的问题。
[0034]
以上所揭露的仅为本发明一种基于机器学习模型的网页数据抽取方法较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
