1.本发明属于目标检测领域,涉及一种特征融合方法,尤其涉及一种基于目标检测的多尺度特征融合方法。
背景技术:
2.目标检测的主要任务是从输入图像中定位感兴趣的目标,然后准确地判断每个感兴趣目标的类别。当前的目标检测技术已经广泛地应用于日常生活安全、机器人导航、智能视频监控、交通场景检测及航天航空等领域。
3.在深度学习的发展背景下,卷积神经网络已经得到越来越多的人认同,应用也越来越普遍。基于深度学习的目标检测算法利用卷积神经网络(cnn)自动选取特征,然后再将特征输入到检测器中对目标分类和定位。
4.在一张图片中,物体的尺寸大小是不同的。如果都采用相同尺寸的特征图训练,则效果很不理想,如果将特征图裁剪成不同的尺寸分多次输入训练,则大大地增加了网络的复杂度和训练时间。在目标检测算法中,为了解决对不同尺寸物体的预测问题,lin等人提出了著名的特征金字塔网络fpn,如图1所示,其基本思想在于结合浅层特征图的细粒度空间信息和深层特征图的语义信息对多尺度的目标进行检测。在此基础上,又有许多人提出了改进的fpn结构。liu等人提出了panet,该网络先采用上采样融合不同尺寸的特征图,在此基础上再进行下采样特征融合,重新构建了一个强化了空间信息的金字塔;golnaz ghaisi等人提出了nas-fpn,该网络在一个覆盖所有交叉尺度连接的可扩展搜索空间中,采用神经网络结构搜索,可以跨范围地融合特性;guo等人提出了augfpn,该网络针对fpn存在的缺陷采用了consistent supervision,residual feature augmentation和soft roi selection;tan等人提出了bifpn架构,bifpn同样对特征进行加权融合,让网络能学习到不同输入特征的重要性;siyuan qiao等人提出了recursive-fpn,该网络将传统fpn的融合后的特征图再输入给backbone,进行二次循环。金字塔网络fpn可以平衡目标的分类准确性和定位准确性,有效地解决多尺度预测问题。但是该结构只是在空间结构上对特征进行有效融合,不同的通道之间的信息可能存在关联或者冗余。
技术实现要素:
5.为了解决背景技术中存在的上述技术问题,本发明提供了一种可显著提升检测精度的基于目标检测的多尺度特征融合方法。
6.为了实现上述目的,本发明采用如下技术方案:
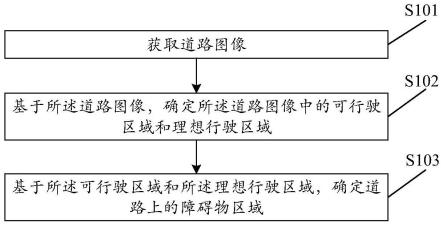
7.一种基于目标检测多尺度特征融合方法,其特征在于:所述基于目标检测多尺度特征融合方法包括以下步骤:
8.1)将不同尺寸的特征图进行卷积处理后得到通道数相同的特征图;
9.2)将步骤1)获取得到的特征图分别进行通道维度融合处理以及空间维度融合处理,分别得到通道维度融合处理特征图以及空间维度融合处理特征图;
10.3)将步骤2)所获取得到的通道维度融合处理特征图以及空间维度融合处理特征图进行融合处理,实现对不同尺寸的特征图在空间和通道两个维度的特征融合。
11.作为优选,本发明所采用的步骤1)的具体实现方式是:
12.1.1)获取不同尺寸的特征图,所述不同尺寸的特征图最少包括特征图c3、特征图c4以及特征图c5;其中特征图c3的尺寸是特征图c4的2倍;特征图c4的尺寸是特征图c5的2倍;
13.1.2)对不同尺寸的特征图进行经过卷积处理,使得卷积处理后的通道数相同。
14.作为优选,本发明所采用的步骤2)中通道维度融合处理的具体实现方式是:将特征图在通带维度上压缩为三维向量,再将不同尺度的特征图在通道维度融合。
15.作为优选,本发明将特征图在通带维度上压缩为三维向量的具体实现方式是:
16.将特征图经过unfold操作,促使特征图由四维tensor转换成三维tensor;所述四维tensor的维度是【b,c,h,w】,所述三维tensor的维度为【b,c’,l】;
17.其中:
18.c’满足以下关系:
19.c
′
=c*k*k
20.其中:
21.c是原特征图的通道大小;
22.k是卷积核的大小;
23.c’是滑动窗口大小;
24.l满足以下关系:
25.l=h'*w'
[0026][0027][0028]
其中:
[0029]
h是原特征图的长度;
[0030]
w是原特征图的宽度;
[0031]
pading是填充大小;
[0032]
k是卷积核大小;
[0033]
stride是步距大小;
[0034]
l是滑动窗口的数量。
[0035]
作为优选,本发明将不同尺度的特征图在通道维度融合的具体实现方式是:
[0036]
a)特征图c3经过1次unfold操作得到c’3;特征图c4经过2次unfold操作后得到c’4_1以及c’4_2;特征图c5经过1次unfold操作得到c’5;其中:c’3和c’4_1大小相等,c’4_2和c’5大小相等;
[0037]
b)将c’3和c’4_1融合得到三维tensor、将c’4_2和c’5进行融合得到三维tensor;
[0038]
c)再将步骤b)的结果通过reshape恢复到4个四维tensor,其中,第一个四维tensor的尺寸和特征图c3的尺寸相同,第2个四维tensor的尺寸以及第3个四维tensor的尺
寸分别与特征图c4的尺寸相同,第4个四维tensor的尺寸和特征图c5的尺寸相同;
[0039]
d)第一个四维tensor得到经过通道维度上融合的特征图p3_1;第4个四维tensor得到经过通道维度上融合的特征图p5_1;将第2个四维tensor和第3个四维tensor相加得到经过通道维度上融合的特征图p4_1;所述特征图p3_1的尺寸、特征图p4_1的尺寸以及特征图p5_1的尺寸均是非等同的。
[0040]
作为优选,本发明所采用的步骤2)中空间维度融合处理是对特征图进行上采样,再将不同不同尺度的特征图在空间维度融合。
[0041]
作为优选,本发明所采用的步骤2)中空间维度融合处理的具体实现方式是:
[0042]
将特征图c5经过上采样与特征图c4融合得到p4_2,将p4_2再经过上采样与特征图c3融合得到p3_2,最终得到经过空间维度上融合的特征图p3_2、特征图p4_2以及特征图p5_2;所述特征图p3_2的尺寸、特征图p4_2的尺寸以及特征图p5_2的尺寸是非等同的。
[0043]
作为优选,本发明所采用的步骤3)中的融合处理的具体实现方式是:
[0044]
3.1)对通道维度和空间维度的相同尺寸的特征图进行整合;
[0045]
3.2)将步骤3.1)整合后的结果进行消融和降采样操作,最终实现对不同尺寸的特征图在空间和通道两个维度的特征融合。
[0046]
本发明的优点是:
[0047]
本发明提供了一种基于目标检测的多尺度特征融合方法,该方法首先将不同尺寸的特征图进行卷积处理后得到通道数相同的特征图,其次,对获取得到的特征图分别进行通道维度融合处理以及空间维度融合处理,分别得到通道维度融合处理特征图以及空间维度融合处理特征图,即,采用了两条分支,第一条分支采用压缩操作,将特征图在通带维度上压缩为三维向量,然后再将不同尺度的特征图在通道维度融合;第二条分支采用上采样操作,然后再将不同尺度的特征图在空间维度融合;最后,将获取得到的通道维度融合处理特征图以及空间维度融合处理特征图进行融合处理,实现对不同尺寸的特征图在空间和通道两个维度的特征融合。本发明所提供的基于目标检测的多尺度特征融合方法在fpn的基础上增加了一条支路,该支路将所有的通道信息压缩在一起并进行语义信息融合,最终获得丰富的语义空间信息。通过实验对比发现,本发明构建的网络结构在不同的网络上均取得一定的提升,尤其是中等目标和大目标的检测精度均得到了显著提升。
附图说明
[0048]
图1是现有技术中特征金字塔网络fpn的结构示意图;
[0049]
图2是本发明所提供的mfpn的结构示意图;
[0050]
图3是基于本发明所提供的mfpn形成的目标检测网络的总体结构示意图;
[0051]
图4至图7是基于不同目标检测网络针对不同检测对象的检测效果图。
具体实施方式
[0052]
参见图2,本发明提供了一种基于目标检测多尺度特征融合方法,该方法包括:
[0053]
1)将不同尺寸的特征图进行卷积处理后得到通道数相同的特征图;
[0054]
1.1)获取不同尺寸的特征图,不同尺寸的特征图最少包括特征图c3、特征图c4以及特征图c5;其中特征图c3的尺寸是特征图c4的2倍;特征图c4的尺寸是特征图c5的2倍;
[0055]
1.2)对不同尺寸的特征图进行经过卷积处理,使得卷积处理后的通道数相同。
[0056]
2)将步骤1)获取得到的特征图分别进行通道维度融合处理以及空间维度融合处理,分别得到通道维度融合处理特征图以及空间维度融合处理特征图;
[0057]
其中:
[0058]
通道维度融合处理的具体实现方式是:将特征图在通带维度上压缩为三维向量,再将不同尺度的特征图在通道维度融合。将特征图在通带维度上压缩为三维向量的具体实现方式是:
[0059]
将特征图经过unfold操作,促使特征图由四维tensor转换成三维tensor;四维tensor的维度是【b,c,h,w】,三维tensor的维度为【b,c’,l】;
[0060]
其中:
[0061]
c’满足以下关系:
[0062]c′
=c*k*k
[0063]
其中:
[0064]
c是原特征图的通道大小;
[0065]
k是卷积核的大小;
[0066]
c’是滑动窗口大小;
[0067]
l满足以下关系:
[0068]
l=h'*w'
[0069][0070][0071]
其中:
[0072]
h是原特征图的长度;
[0073]
w是原特征图的宽度;
[0074]
pading是填充大小;
[0075]
k是卷积核大小;
[0076]
stride是步距大小;
[0077]
l是滑动窗口的数量。
[0078]
将不同尺度的特征图在通道维度融合的具体实现方式是:
[0079]
a)特征图c3经过1次unfold操作得到c’3;特征图c4经过2次unfold操作后得到c’4_1以及c’4_2;特征图c5经过1次unfold操作得到c’5;其中:c’3和c’4_1大小相等,c’4_2和c’5大小相等;
[0080]
b)将c’3和c’4_1融合得到三维tensor、将c’4_2和c’5进行融合得到三维tensor;
[0081]
假设,c5的大小为四维tensor【b,c,h,w】,由步骤1.1)和步骤1.2)的介绍可知,c4的大小为【b.c,2*h,2*w】,c3的大小为【b,c,4*h,4*w】。根据步骤1.2)中的公式,经过unfold操作后,c’3的大小为【b,c*k*k,h*w】,c’4_1的大小为【b,c*k*k,h*w】,c’4_2的大小为【b,c*k*k,4*h*w】,c’5的大小为【b,c*k*k,4*h*w】,所以c’3和c’4_1融合后得到三维tensor【b,c*k*k,h*w】;c’4_2和c’3融合后得到三维tensor【b,c*k*k,4*h*w】;
[0082]
c)再将步骤b)的结果通过reshape恢复到4个四维tensor,其中,第一个四维tensor的尺寸和特征图c3的尺寸相同,第2个四维tensor的尺寸以及第3个四维tensor的尺寸分别与特征图c4的尺寸相同,第4个四维tensor的尺寸和特征图c5的尺寸相同;
[0083]
d)第一个四维tensor得到经过通道维度上融合的特征图p3_1;第4个四维tensor得到经过通道维度上融合的特征图p5_1;将第2个四维tensor和第3个四维tensor相加得到经过通道维度上融合的特征图p4_1;特征图p3_1的尺寸、特征图p4_1的尺寸以及特征图p5_1的尺寸均是非等同的。
[0084]
空间维度融合处理是对特征图进行上采样,再将不同不同尺度的特征图在空间维度融合。
[0085]
空间维度融合处理的具体实现方式是:
[0086]
将特征图c5经过上采样与特征图c4融合得到p4_2,将p4_2再经过上采样与特征图c3融合得到p3_2,最终得到经过空间维度上融合的特征图p3_2、特征图p4_2以及特征图p5_2(c5的直接输出);特征图p3_2的尺寸、特征图p4_2的尺寸以及特征图p5_2的尺寸是非等同的。
[0087]
3)将步骤2)所获取得到的通道维度融合处理特征图以及空间维度融合处理特征图进行融合处理,实现对不同尺寸的特征图在空间和通道两个维度的特征融合,其中融合处理的具体实现方式是:
[0088]
3.1)对通道维度和空间维度的相同尺寸的特征图进行整合;
[0089]
3.2)将步骤3.1)整合后的结果进行消融和降采样操作,最终实现对不同尺寸的特征图在空间和通道两个维度的特征融合。
[0090]
具体而言,首先获取不同尺寸的特征图【c3,c4,c5】(c3的尺寸是c4的2倍,c4的尺寸是c5的2倍)经过卷积处理后通道数都变成256,然后再经过两条并行分支branch1和branch2在不同维度进行特征融合,分别得到三个不同尺寸大小的特征图【p3_1,p4_1,p5_1】和【p3_2,p4_2,p5_2】,将不同维度的相同尺寸的特征图得到新的特征图【p3,p4,p5】(p3的尺寸是p4的2倍,p4的尺寸是p5的2倍),最后经过消融和降采样操作得到5个不同尺寸的特征图【p3,p4,p5,p6,p7】。
[0091]
下面结合附图和实施例对本发明的技术方案作进一步说明。
[0092]
本发明是以mfpn网络为基础的优化神经网络,其步骤包括:
[0093]
步骤1:数据输入和预处理。
[0094]
采用了ms coco2017数据集。coco数据集共包含80个用于检测的类别。分别为“人”,“自行车”,“汽车”,“摩托车”,“飞机”,“公共汽车”,“火车”,“卡车”,“船”,“交通信号灯”等日常生活中常见个体,它是一个大型的、丰富的物体检测,分割和字幕数据集。包含annotations、test2017、train2017、val2017四个文件。其中train包含118287张图像,val包含5000张图像,test包含28660张图像。annotations为标注类型的集合:object instances,object keypoints和image captions,使用json文件存储。
[0095]
将所有图片的尺寸调整到512x512大小多尺度训练,采用数据增强对图像数据集进行各种操作:随机翻转操作,对不符合要求的图片进行pad填充操作,对不符合指定大小的图片进行随机裁剪操作,归一化处理操作,图像失真处理操作。
[0096]
步骤2:模型的构建。
[0097]
如图3所示,基于vfnet提出了目标检测网络,该目标检测网络由backbone、neck和heads三部分构成。对于不同的目标检测网络,它们通常都采用相同的backbone和neck,但是不同的目标检测网络的heads是不同的。backbone采用的是resnet50,用于提取图片的特征,该网络输出4个不同尺寸的特征图【c2,c3,c4,c5】,步距为【4,8,16,32】,通道大小为【256,512,1024,2048】。neck结构用于连接backbone和heads,用于融合特征。该结构采用了backbone的三个特征图【c3,c4,c5】,经过1*1卷积后通道都降为256,mfpn特征融合结构,然后对c5进行两次下采样得到c6和c7,最后采用3*3卷积对特征图进行消融处理,输出5个不同尺寸的特征图【p3,p4,p5,p6,p7】,步距为【8,16,32,64,128】,通道大小都为256。heads用于物体的检测,实现目标的分类和回归。
[0098]
步骤3:训练测试。
[0099]
实验的评价标准采用平均精度(average-precision,ap),ap50,ap75,ap_s,ap_m,ap_l作为主要评价标准。
[0100]
实验环境:搭建以pytorch1.6.0、torchvision=0.7.0、cuda10.0、cudnn7.4为深度学习框架的python编译环境,并在平台mmdetection2.6上实现。
[0101]
experimental equipment:
[0102]
cpu:intel xeon e5-2683 v3@2.00ghz;
[0103]
ram:32gb;
[0104]
graphics card:nvidia gtx 1080ti;
[0105]
hard disk:500gb;
[0106]
测试了多尺度融合结构对物体精度的影响,并在多个网络上进行了对比实验,实验结果如表1所示。
[0107]
表1 mfpn对不同网络的效果
[0108][0109]
mfpn结构在四个网络上都有不同程度的改进。在atss网络上,ap从32.7%增加到34%,ap50和ap_l甚至增加了2%。在fcos的ap从29.1%提高了0.9%,其他指标也可以提高1%以上。vfnet的ap从34.1%增加了0.4%,但ap_l从50.5%增加到了52.8%。mfpn结构在foveabox中提升最为明显,其ap提升了2.4%,ap_l从43.8%提升到了47.8%。这说明mfpn模块得到的语义信息比fpn模块得到的语义信息丰富。
[0110]
mfpn对不同的网络有不同的影响。它在vfnet上的ap增加了0.4%,在foveabox上的ap_l增加了2.4%。认为这与基准网络有关。vfnet的原始网络ap高达34.1%,而foveabox的ap只有28.5%。mfpn对小物体的改进有限,但在中型物体和大物体的检测精度上有显着的提升。在物体检测领域,为了提高小物体的检测精度,需要更大尺寸的特征图。mfpn结构的branch1虽然在通道维度融合了特征图,但是特征图的滑动窗口是c*k*k,它的特征图尺寸在空间上是k*k,所以mfpn对于提高小物体不是很理想。
[0111]
本发明测试了mfpn和其他网络的检测效果,其结果如图4至图7所示。其中(a)均是fcos的检测效果图,(b)均是atss的检测效果图,(c)均是foveabox的检测效果图,(d)均是本发明所提供的mfpn网络的检测效果图。在图4的汽车检测中,可以看出对于密集物体,本发明提供的mfpn网络能检测到的对象更多。在图5对单个狗的检测中,所有网络都能准确检测到目标,但是本发明所提供的mfpn网络分类精度更高,达到96%。在图6的多物体检测中,本发明提供的mfpn网络不仅能较好地检测出人与自行车,而且还能检测到半遮挡物。在图7的图形中,本发明所提供的mfpn网络对人与马的检测能更好地分离,并且检测精度也达到最高。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。