1.本发明关于人工智能,且涉及一种运行深度神经网络的人工智能加速器。
背景技术:
2.深度神经网络(deep neural network,dnn)近年来发展迅速。应用dnn进行影像辨识的精确度也逐渐提高,甚至比人类辨识得更为精准。为了配合dnn的计算需求,人工智能加速器(即运行dnn模型的处理器)必须提升硬件效能。从穿戴装置、行动通信装置以至于自驾车、云端服务器所用的人工智能系统,其所需的运算量随着装置规模而指数性成长。
3.一般而言,dnn专用的处理器须满足计算力与输入输出频宽两方面的需求。增加运算单元(processing element,pe)的数量理论上可提升运算力,然而也需要一个适用于大量运算单元的数据网络架构才能将输入数据实时地送入每一个运算单元。对于一个运算单元,其电路面积中占最大比例部分的是储存元件,其次才是控制逻辑与运算逻辑。考虑到大量运算单元所伴随的功耗与电路面积,如何设计良好的数据传输路径,借此减少储存元件的用量成为设计人工智慧加速器时的一个重要议题。
技术实现要素:
4.有鉴于此,本发明提出一种运算单元架构、运算单元丛集及卷积运算的执行方法,在保有人工智能加速器原本的运算效能的同时减少所需的储存空间,并且兼具延展性。
5.依据本发明一实施例的一种运算单元架构,适用于一卷积运算,该架构包括:多个运算单元,该些运算单元中具有一第一运算单元及一第二运算单元,该第一运算单元及该第二运算单元至少依据一共享数据进行该卷积运算;以及一延迟伫列,连接该第一运算单元及该第二运算单元,该延迟伫列接收该第一运算单元传送的该共享数据,并在接收该共享数据且经过一延迟周期后将该共享数据传送至该第二运算单元。
6.依据本发明一实施例的一种运算单元丛集,适用于一卷积运算,该丛集包括:一第一运算群,具有多个第一运算单元;一第二运算群,具有多个第二运算单元;一汇流排,连接该第一运算群及该第二运算群,该汇流排提供多个共享数据至每一该些第一运算单元;以及多个延迟伫列,该些延迟伫列中的一者连接该些第一运算单元中的一者及该些第二运算单元中的一者,该些延迟伫列中的另一者连接该些第二运算单元的二者,且每一该些延迟伫列传递该些共享数据中的一者;其中该第一运算群中的每一该些第一运算单元包括一储存装置,该储存装置用以储存该些共享数据中对应的该者;且该第二运算群中的每一该些第二运算单元不包括该储存装置。
7.依据本发明一实施例的一种卷积运算的执行方法,适用于本发明一实施例的运算单元架构,该方法包括:以该第一运算单元接收一输入数据及该共享数据并依据该输入数据及该共享数据执行该卷积运算;以该第一运算单元传送该共享数据至该延迟伫列;以该延迟伫列等待该延迟周期;在该延迟伫列等待该延迟周期之后,以该延迟伫列传送该共享数据至该第二运算单元;以及以该第二运算单元接收另一输入数据,并依据该另一输入数
据及该共享数据进行该卷积运算。
8.以上关于本发明内容的说明及以下的实施方式的说明是用以示范与解释本发明的精神与原理,并且提供本发明的专利保护范围更进一步的解释。
附图说明
9.图1是本发明一实施例的运算单元架构的框图;
10.图2是本发明另一实施例的运算单元架构的框图;
11.图3是本发明一实施例的运算单元丛集的框图;以及
12.图4是本发明一实施例的卷积运算的执行方法的流程图。
13.【附图符号说明】
14.运算单元架构10、10
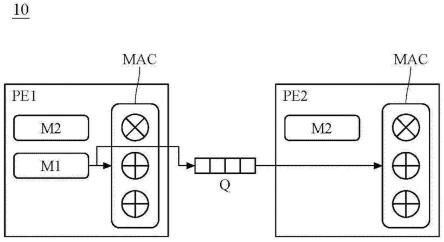
′
;第一运算单元pe1;第二运算单元pe2、pe2a、pe2b;运算电路mac;第一储存装置m1;第二储存装置m2;延迟伫列q、q1、q2;运算单元丛集20;第一运算群21;第二运算群22;汇流排23;步骤s1~s8。
具体实施方式
15.以下在实施方式中详细叙述本发明的详细特征以及特点,其内容足以使本领域技术人员了解本发明的技术内容并据以实施,且根据本说明书所公开的内容、权利要求及附图,本领域技术人员可轻易地理解本发明相关的构想及特点。以下的实施例是进一步详细说明本发明的观点,但非以任何观点限制本发明的范围。
16.本发明涉及人工智能加速器中的处理单元阵列(processing element array,pe array)。处理单元阵列用于处理一或多个卷积(convolution)运算。处理单元阵列从总体缓冲器(global buffer,glb)接收卷积运算时所需的输入数据,例如输入特征图(input feature map,ifmap)、卷积核(kernel map)以及部分和(partial sum)等。处理单元阵列中包含多个处理单元。一般而言,每个处理单元包含暂存记忆体(scratch pad memory,spad),用于暂存前述的输入数据、乘积累加运算(multiply accumulate,mac)器以及控制逻辑。
17.本发明提出的运算单元架构包括两种运算单元:第一运算单元及第二运算单元,其中第一运算单元pe1的数量为1个,第二运算单元pe2的数量至少为1个以上。图1及图2分别绘示一个第二运算单元及两个第二运算单元的两个实施例。两个以上的第二运算单元的实施例则可按照图1及图2自行推得。
18.图1是本发明一实施例的运算单元架构的框图。所述的运算单元架构适用于卷积运算,且包括多个运算单元以及一延迟伫列。图1所示的运算单元架构10包括一个第一运算单元pe1、一个第二运算单元pe2以及一个延迟伫列q。
19.第一运算单元pe1及第二运算单元pe2至少依据一共享数据进行卷积运算。在一实施例中,共享数据为卷积核或过滤器(filter)。第一运算单元pe1包括第一储存装置m1、第二储存装置m2及运算电路mac。第二运算单元pe2的硬体结构类似于第一运算单元pe1,其差别在于第二运算单元pe2并没有设置第一储存装置m1。在实际应用过程中,第一储存装置m1用于暂存共享数据,例如卷积核或过滤器。第二储存装置m2用于暂存非共享数据,例如输入特征图或部分和。运算电路mac例如为乘积累加运算器。运算电路mac依据取自第一储存装
置m1的卷积核、取自第二储存装置m2的输入特征图、以及取自第二储存装置m2的部分和等资料进行卷积运算。卷积核属于共享数据,输入特征图及部分和属于非共享数据。在实际应用过程中,输入特征图及部分和可分别储存在两个相异的储存装置,或是储存在一个储存装置下的相异储存空间,本发明对此不予限制。
20.延迟伫列(delayed-control queue)q连接第一运算单元pe1及第二运算单元pe2。延迟伫列q用以接收第一运算单元pe1传送的共享数据,并在接收共享数据且经过一延迟周期p后将共享数据传送至第二运算单元pe2。在实际应用过程中,延迟伫列q具有先进先出(first in-first out,fifo)的数据结构。举例说明如下,其中以tk代表第k个单位时间;
21.在tk时,第一运算单元pe1传送共享数据f1至延迟伫列q;
22.在t
k 1
时,第一运算单元pe1传送共享数据f2至延迟伫列q;因此,
23.在第t
k p
时,第二运算单元pe2从延迟伫列q接收到共享数据f1:且在第t
k 1 p
时,第二运算单元pe2从延迟伫列q接收到共享数据f2。
24.在本发明一实施例中,延迟周期p的数量级与卷积运算的步幅(stride)数值相同。举例来说,若步幅为2,则延迟周期也为2个单位时间。
25.在本发明一实施例中,延迟伫列q的储存空间的大小(size)不小于卷积运算的步幅。举例说明如下,若卷积运算的步幅为3,且第一运算单元pe1在tk时取得共享数据f1并进行第一次卷积运算,则第一运算单元pe1将在t
k 3
时取得共享数据f4并进行第二次卷积运算。然而,在t
k 1
至t
k 2
的期间,延迟伫列q仍需要暂存来自第一运算单元pe1的共享数据f2及共享数据f3,且在t
k 3
时,延迟伫列q将共享数据f1传送至第二运算装置pe2。因此延迟伫列q至少需要3个单位空间,用于储存共享数据f1~f3。
26.图2是本发明另一实施例的运算单元架构10
′
的框图。相较于前一实施例,此实施例的运算单元架构10
′
包括一个第一运算单元pe1、一个第二运算单元pe2a、另一个第二运算单元pe2b、一个延迟伫列q1以及另一个延迟伫列q2。第二运算单元pe2a及另一第二运算单元pe2b至少依据共享数据进行卷积运算。另一延迟伫列q2连接第二运算单元pe2a及另一第二运算单元pe2b。此另一延迟伫列q2接收第二运算单元pe2a传送的共享数据,并在接收共享数据且经过延迟周期后将共享数据传送至另一第二运算单元pe2b。在实际应用过程中,可依据需求,自行增加串接在第一运算单元pe1后的多个第二运算单元pe2以及对应这些第二运算单元pe2的延迟伫列q。由上述可知,运算单元架构10中的延迟伫列q的数量与第二运算单元pe2的数量相同。
27.图3是本发明一实施例的运算单元丛集20的框图。所述的运算单元丛集20适用于卷积运算,且包括第一运算群21、第二运算群22、汇流排23以及多个延迟伫列q。第一运算群21及第二运算群22排列为m列n行的二维阵列。在m列中的每一者具有多个第一运算单元中的一个及多个第二运算单元中的(n-1)个。在图2绘示的范例中,m=3且n=7,然而本发明并不限制m及n的数值大小。延迟伫列q具有m组,这m组的每一者具有(n-1)个延迟伫列q。
28.第一运算群21具有m个第一运算单元pe1,第一运算群21中的每个第一运算单元pe1与前一实施例所述的第一运算单元pei相同。第一运算单元pe1具有用以储存共享数据的第一储存装置m1。
29.第二运算群22具有m
×
(n-1)个第二运算单元pe2。第二运算群22中的每个第二运算单元pe2不包括第一储存装置m1。
30.汇流排23连接第一运算群21及第二运算群22。在本发明一实施例中,汇流排23至连接每一个第一运算单元pe1,且汇流排23连接至每一个第二运算单元pe2。汇流排23提供多个共享数据至每个第一运算单元pe1。汇流排23提供多个非共享数据至每个第一运算单元pe1及每个第二运算单元pe2。共享数据及非共享数据的来源例如为glb。
31.请参考图3,运算单元丛集20的延迟伫列q的数量有m
×
(n-1)个,每个延迟伫列q用以传递共享数据。
32.这些延迟伫列q中的一者连接这些第一运算单元pe1中的一者及这些第二运算单元pe2中的一者。这些延迟伫列q中的另一者连接这些第二运算单元pe2的二者,且每个些延迟伫列q传递这些共享数据中的一者。换个角度而言,第一运算群21中的每个第一运算单元pe1通过一延迟伫列q连接第二运算群22中的一个第二运算单元pe2。第二运算群22中位于同一列且相邻两行的两个第二运算单元pe2通过该些延迟伫列中的一者彼此连接。
33.图4是本发明一实施例的卷积运算的执行方法的流程图。图4所示的卷积运算的执行方法适用于图1所示的运算单元架构10、图2所示的运算单元架构10
′
或图3所示的运算单元丛集20。
34.步骤s1为第一运算单元pe1接收输入数据及共享数据,并依据输入数据及共享数据执行卷积运算。输入数据及共享数据例如由汇流排23传送至第一运算单元pe1。
35.步骤s2为第一运算单元pe1传送共享数据至第k个延迟伫列q,其中k=1。k同时代表延迟伫列的编号及第二处理单元的编号。步骤s1及s2并不限制先后执行顺序。步骤s1及s2可同时执行。
36.步骤s3为第k个延迟伫列q等待一延迟时间。延迟时间的长度取决于卷积运算的步幅。
37.步骤s4为第k个延迟伫列q传送共享数据至第k个第二运算单元pe2。
38.步骤s5为第k个第二运算单元pe2接收另一输入数据,并依据另一输入数据及共享数据进行卷积运算。
39.步骤s6为判断第k个第二运算单元pe2是否为最后一个第二运算单元pe2。若步骤s6的判断结果为是,则结束本发明一实施例的卷积运算的执行方法。若步骤s6的判断结果为否,则执行步骤s7。
40.步骤s7为第k个第二运算单元pe2传送共享数据至第k 1个延迟伫列q。步骤s7类似于步骤s2,步骤s7及s2都为第一运算单元pe1或第二运算单元pe2将共享数据传送至下一级的延迟伫列q。
41.步骤s8为k=k 1,即递增k的值。依据运算单元架构10或10
′
中的第二运算单元pe2的数量,步骤s3~s8可能被重复执行复数次。
42.综上所述,本发明提出的运算单元架构、运算单元丛集及卷积运算的执行方法通过第二运算单元及延迟伫列的设计,可节省原本用于储存共享数据的大量储存装置。当人工智能加速器中属于第二运算群的第二运算单元的数量越多,应用本发明可节省的电路面积越大,因此也节省大量的功率消耗。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。