1.本发明涉及自然语言处理领域,具体涉及一种面向句子级别的关系抽取方法、设备及存储介质。
背景技术:
2.近年来,人工智能已经成为新一轮科技革命和产业变革的重要驱动力量,而自然语言处理(nlp)作为人工智能的一个重要研究方向,是实现人工智能从感知到认知的关键。关系抽取是自然语言处理领域中一个核心任务,主要实现对文本中实体对之间表达的语义关系的抽取和识别,同时也是构建知识图谱的基础,被广泛应用于信息检索,机器阅读理解、人机对话、个性化推荐、智能搜索等领域,随着深度学习在人工智能领域的广泛应用,研究结果已经表明深度学习利用大量数据能捕获到有效的特征信息,许多研究人员也将深度学习技术应用于关系抽取,并且相比于传统手工抽取特征的方法取得了明显的进展。
3.由于文本表达的多样性,关系抽取是一个复杂且难以解决的任务,对实体对之间的关系抽取很大程度依赖于模型对文本中语义的理解能力,这在自然语言处理中也极具挑战。随着深度学习的发展,目前基于深度学习方法的关系抽取可以分为两类:一类是基于卷积神经网络和循环神经网络等传统神经网络的模型,受限于模型规模和训练数据难以获取,这类模型只能取得有限的效果;另一类则是基于预训练语言模型(如bert,gpt)的关系抽取模型,预训练模型最早是在图像领域被提出的,利用大量训练数据学习得到丰富的知识,再结合迁移学习迁移到其他神经网络以得到更好的效果。大量实验结果表明预训练语言模型已经在许多自然语言处理任务上领先于传统神经网络。
4.尽管国内外已经有许多研究人员基于预训练语言模型完成关系抽取这个任务,但是根据一些实验结果表明,预训练语言模型仍然存在改进空间,并且仍然存在很多潜力有待挖掘。在关系抽取甚至整个自然语言处理领域中,已经存在大量对词向量的研究,毋庸置疑,词向量的质量关乎模型性能表现,然而标签(关系)中丰富的语义信息却鲜有人发掘利用。
技术实现要素:
5.为了克服现有技术存在的缺点与不足,本发明提供一种面向句子级别的关系抽取方法、设备及存储介质,具体涉及基于关系嵌入的注意力机制的关系抽取方法。本发明利用关系中丰富语义信息加强对文本中关键信息的提取,从而实现更好关系抽取性能。
6.本发明采用如下技术方案:
7.一种面向句子级别的关系抽取方法,包括如下:
8.获得一个句子,所述一个句子包括两个实体,在每个实体的两端分别插入特殊标记,输入预训练语言模型得到该句子每个词的词向量;
9.使用随机初始化得到关系嵌入,分别与每个词的词向量采用点积注意力机制得到其相关程度,进一步得到句子的注意力表示集合,将该集合中的每个向量输入二分类器得
到预测结果,计算二分类损失;
10.基于注意力表示集合利用最大池化计算得到关系向量,利用平均池化得到句子向量,两个实体向量,将上述四个向量进行拼接输入多分类器获得多分类损失;
11.将句子中的两个实体按照预先设定概率进行掩藏,获得另外一个句子s’;对另外一个句子重复上述步骤获得二元损失和多元损失,进一步获得两个句子预测结果的一致性损失;
12.对二元损失、多元损失、一致性损失进行联合训练,当损失最小值时获得关系抽取模型。
13.进一步,所述获得一个句子,所述一个句子包括两个实体,在每个实体的两端分别插入特殊标记,具体为:
14.获得一个句子s,在句子开头插入特殊标记“[cls]”,在第一个实体两端插入特殊标记“#”,在第二个实体两端插入特殊标记“$”。
[0015]
进一步,使用随机初始化得到关系嵌入,分别与每个词的词向量采用点积注意力机制得到其相关程度,进一步得到句子的注意力表示集合,具体为:
[0016]
随机初始化获得关系嵌入,每一个关系嵌入分别与每个词向量使用点积注意力机制得到相关程度;
[0017][0018]
公式中ei代表第i种关系的嵌入,hj代表第j个词的词向量,使用得到的相关程度对词向量进行逐元素相乘,并将乘积相加得到句子的注意力表示集合v={v1,v2,
…
,vm};
[0019][0020]
进一步,将注意力表示集合中的每个向量输入二分类器得到预测结果,计算二分类损失,具体为:
[0021]
将注意力表示集合中每个向量分别输入二分类器中,得到该关系存在的概率,随后根据真实标签使用交叉熵损失函数得到二元损失l
bin
。
[0022]
其中真实标签根据如下规则生成:对于预定义关系集中的每个关系r,若存在该关系则标签为1,否则标签为0。
[0023]
进一步,所述基于注意力表示集合利用最大池化计算得到关系向量,利用平均池化得到句子向量,两个实体向量具体为:
[0024]
句子向量按照如下公式获得:
[0025]hcls
=w0[tanh(h0)] b0[0026]
两个实体向量按照如下公式获得:
[0027]
[0028][0029]
关系向量按照如下公式获得:
[0030]hv
=w2[tanh(maxpooling(v))] b2[0031]
其中i,j分别是第一个实体的开始下标和结束下标,k,l分别是第二个实体的开始下标和结束下标。
[0032]
进一步,所述设定概率小于0.5。
[0033]
进一步,获得两个句子预测结果的一致性损失,其中一致性损失为:
[0034][0035]
和分别代表句子s和s’的多分类预测结果。
[0036]
进一步,对二元损失、多元损失、一致性损失联合训练得到最优模型:
[0037]
l=0.5*(l
mul
l
′
mul
l
bin
l
′
bin
) l
kl
。
[0038]
l
mul
,l
bin
,l
′
mul
,l
′
bin
分别代表句子s的多元损失、句子s的二元损失、句子s’的多元损失、句子s’的二元损失。
[0039]
一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述的关系抽取方法。
[0040]
一种设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现所述的关系抽取方法。
[0041]
本发明的有益效果:
[0042]
(1)本发明改进传统方法将关系视为硬标签的方式,充分利用关系中丰富的语义帮助模型提取关键信息;
[0043]
(2)本发明使用辅助任务与主任务联合训练的方法,在加强模型性能的同时能学习到更好的关系嵌入,所述辅助任务指二分类任务,主任务指多分类任务。
[0044]
(3)本发明通过掩码实体的方式构造增强样本,防止模型过拟合。
附图说明
[0045]
图1为本发明的流程图。
[0046]
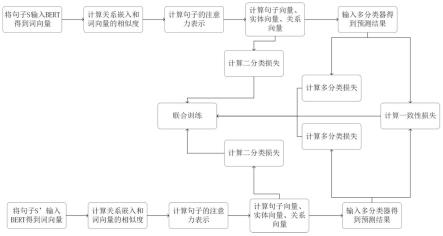
图2为本发明前三个步骤的流程图;
[0047]
图3是本发明第四步骤的流程图。
具体实施方式
[0048]
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
[0049]
实施例1
[0050]
如图1及图2所示,一种面向句子级别的关系抽取方法,该方法包括:1)通过学习关系嵌入,利用注意力机制抽取文本中与特定关系相关的信息;2)设计了一个辅助任务用于
提升模型性能以及联合辅助关系嵌入的学习;3)通过对文本中实体以一定概率掩藏生成相似样本,作为一种数据增强的手段;4)通过最小化样本和相似样本的概率分布差异防止模型过度学习。本发明能够有效抽取文本中的关键信息,捕捉文本中实体的联系,从而达到良好的关系抽取性能。
[0051]
具体包括如下步骤:
[0052]
第一步骤,获得一个句子s,所述一个句子包括两个实体,在每个实体的两端分别插入特殊标记,输入预训练语言bert模型得到该句子每个词的词向量h={h1,h2,
…
,hn},hi∈rd,代表第i个词的词向量。
[0053]
具体为:
[0054]
获得一个句子s={w1,w2,
…
,wn,n是文本中词的数量,在句子开头插入特殊标记“[cls]”,在第一个实体两端插入特殊标记“#”,在第二个实体两端插入特殊标记“$”。例如“[cls]this machine is blowing#sand#into$molds$.”,“sand”和“molds”分别是两个实体。
[0055]
第二步骤,使用随机初始化得到关系嵌入,分别与每个词的词向量采用点积注意力机制得到其相关程度,进一步得到句子的注意力表示集合,将该集合中的每个向量输入二分类器得到预测结果,计算二分类损失。
[0056]
具体为:
[0057]
随机初始化获得关系嵌入,设e={e0,e1,
…
,em},ei∈rd,m是关系的数量,ei代表第i种关系的嵌入,hj代表第j个词的词向量,每一个关系嵌入分别与每个词向量使用点积注意力机制得到相关程度;
[0058][0059]
中α
ij
表示第i种关系与第j个词的相关程度。
[0060]
使用得到的相关程度对词向量进行逐元素相乘,并将乘积相加得到句子的注意力表示集合;
[0061][0062]
对每种关系重复公式(1)(2)的操作,得到关系注意力表示的集合v={v1,v2,
…
,vm},vi∈rd。
[0063]
为了加强对特定关系嵌入ei的学习,利用原有的标签设计一个二分类任务跟主任务联合训练。将v中的每个向量分别输入二分类器中,得到该特征向量检测到关系存在的概率其中:
[0064][0065]
其中w
bin
∈rd是参数矩阵,b
bin
是偏置,代表该句子中存在第i种关系的概率。
[0066]
根据真实标签可以使用交叉熵损失函数计算相应的二元损失,用公式表示为:
[0067]
[0068][0069]
其中代表第i种关系的二元损失,l
bin
代表总的二元损失。由于上述处理方式会导致正样本的数量远远少于负样本的数量,在公式(4)中λb可以调节正样本的损失权重,是一个可调整的超参数,能够使模型在训练过程中可以更加专注于正样本的优化。
[0070]
其中真实标签根据如下规则生成:对于预定义关系集中的每个关系r,若存在该关系则标签为1,否则标签为0。
[0071]
第三步骤,基于注意力表示集合利用最大池化计算得到关系向量,利用平均池化得到句子向量,两个实体向量,将上述四个向量进行拼接输入多分类器获得多分类损失。
[0072]
具体为:
[0073]
使用特殊标记“[cls]”的输出作为句子的表示;使用实体的平均池化输出作为实体表示;使用关系注意力输出的最大池化作为关系表示。用公式分别表示为:
[0074]hcls
=w0[tanh(h0)] b0ꢀꢀ
(6)
[0075][0076][0077]hv
=w2[tanh(maxpooling(v))] b2ꢀꢀ
(9)
[0078]
其中i,j分别是第一个实体的开始下标和结束下标,k,l分别是第二个实体的开始下标和结束下标。w0,w1,w2∈rd×d,b0,b1,b2是偏置。对关系注意力表示v的最大池化操作定义如下:
[0079]
(v
max
)i=max{(v
t
)i},t∈{0,1,
…
,s-1}
ꢀꢀ
(10)
[0080]hv
=[(v
max
)1;(v
max
)2;
…
;(v
max
)d]
ꢀꢀ
(11)
[0081]
其中i是特征的索引,即代表向量的第i个元素。
[0082]
将四个向量拼接输入多分类器,得到分类结果:
[0083][0084][0085]
根据真实标签y计算多元交叉熵损失:
[0086][0087]
其中c是类别的数量。
[0088]
第四步骤,如图3所示,将句子中的两个实体按照预先设定概率进行掩藏,获得另外一个句子;对另外一个句子重复上述步骤获得二元损失和多元损失,进一步获得两个句子预测结果的一致性损失。
[0089]
具体为:
[0090]
以句子“this machine is blowing sand into molds.”为例,两个实体分别为“sand”和“molds”,对实体词以一定的概率p用特殊标记“[mask]”替换,p是可以调节的超参数,一般不大于0.5。经过替换的句子可能为:“this machine is blowing sand into[mask].”。
[0091]
随后将处理后的句子s
′
按照公式(1)-(14)的计算,分别得到对应的二元损失l
′
bin
,多元损失l
′
mul
,预测分布对于分布和计算kullback-leibler散度:
[0092][0093]
第五步骤,对二元损失、多元损失、一致性损失进行联合训练,当损失最小值时获得用于关系抽取模型。
[0094]
模型最终的损失如下:
[0095]
l=0.5*(l
mul
l
′
mul
l
bin
l
′
bin
) l
kl
ꢀꢀ
(16)
[0096]
使用梯度下降的方式最小化损失直至模型收敛,得到关系抽取模型。
[0097]
第六步骤,将待抽取的句子输入关系抽取模型,实现关系抽取性能。
[0098]
表1:本发明bert remb与主流关系抽取模型在semeval-2010task 8数据集上的性能对比
[0099]
模型macro-f1att-pooling-cnn88.0r-bert89.2bert mtb89.5bert remb89.8
[0100]
表1显示的是本发明bert remb与主流关系抽取模型在semeval-2010task8数据集上的性能对比,本发明在这个数据集上取得了最优的结果。
[0101]
实施例2
[0102]
一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述的关系抽取方法。
[0103]
一种面向句子级别的关系抽取方法,包括如下:
[0104]
获得一个句子,所述一个句子包括两个实体,在每个实体的两端分别插入特殊标记,输入预训练语言模型得到该句子每个词的词向量;
[0105]
使用随机初始化得到关系嵌入,分别与每个词的词向量采用点积注意力机制得到其相关程度,进一步得到句子的注意力表示集合,将该集合中的每个向量输入二分类器得到预测结果,计算二分类损失;
[0106]
基于注意力表示集合利用最大池化计算得到关系向量,利用平均池化得到句子向量,两个实体向量,将上述四个向量进行拼接输入多分类器获得多分类损失;
[0107]
将句子中的两个实体按照预先设定概率进行掩藏,获得另外一个句子s’;对另外一个句子重复上述步骤获得二元损失和多元损失,进一步获得两个句子预测结果的一致性损失;
[0108]
对二元损失、多元损失、一致性损失进行联合训练,当损失最小值时获得用于关系
抽取模型。
[0109]
实施例3
[0110]
一种设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的所述的关系抽取方法。
[0111]
一种面向句子级别的关系抽取方法,包括如下:
[0112]
获得一个句子,所述一个句子包括两个实体,在每个实体的两端分别插入特殊标记,输入预训练语言模型得到该句子每个词的词向量;
[0113]
使用随机初始化得到关系嵌入,分别与每个词的词向量采用点积注意力机制得到其相关程度,进一步得到句子的注意力表示集合,将该集合中的每个向量输入二分类器得到预测结果,计算二分类损失;
[0114]
基于注意力表示集合利用最大池化计算得到关系向量,利用平均池化得到句子向量,两个实体向量,将上述四个向量进行拼接输入多分类器获得多分类损失;
[0115]
将句子中的两个实体按照预先设定概率进行掩藏,获得另外一个句子s’;对另外一个句子重复上述步骤获得二元损失和多元损失,进一步获得两个句子预测结果的一致性损失;
[0116]
对二元损失、多元损失、一致性损失进行联合训练,当损失最小值时获得用于关系抽取模型。
[0117]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。