1.本发明属语音识别技术领域,涉及一种基于深度残差网络和注意力机制的声纹识别方法及装置。
背景技术:
2.随着人工智能技术的发展,声纹识别领域取得了巨大的进步。声纹识别又称说话人识别,即通过声音识别出“谁在说话”,是根据语音信号中的说话人个性信息来识别说话人身份的一项生物特征识别技术。该技术被广泛应用于服务行业,在工作人员服务过程中存在着大量与客户交互的场景,为了规范工作人员的言语以提升客户好感度,急需一种在环境噪音过大,工作人员和客户交互频繁的情况下,仍能准确对工作人员身份进行识别的方法。
3.传统的说话人识别算法所采用的模型,一般属于浅层结构,只是对原始的输入信号进行较少层次的线性或者非线性处理以达到特征提取的目的。这种结构的优点在于易于学习,而且有比较完整的数学算法证明推导。但是对于复杂场景下的语音信号,其模型表达能力有限,不能够充分地学习到信号中的结构化信息和高层信息。而深层结构的模型,如深度神经网络(deep neural network,dnn),由于其多层非线性变换的复杂性,具有更强的表达与建模能力,更适合处理这类语音信号。神经网络层数越多,对输入特征抽象的层次越深,对其理解的准确度相对来说也就越深。然而,深度神经网络单纯的堆叠层数,会出现梯度消失、梯度爆炸和网络退化的问题。所以目前说话人识别领域常用的深度神经网络是可以避免这类问题的resnet网络,但过深的resnet网络虽然提取特征的能力增强,但训练的时间也越长,并且当提取的特征过于深的时候,容易发生过拟合的现象,即在验证集内识别效果良好,但在实际应用中表现不佳。
技术实现要素:
4.有鉴于此,本发明的目的在于针对resnet层数过深时训练时间过长且容易过拟合的问题,引入轻量级网络mobilenet的设计思想,在resnet50模型的基础上利用深度可分离卷积来构建网络,针对环境噪声过大的问题,引入注意力机制筛选重要帧并采用加噪训练的方式增强模型的抗干扰能力。提供一种基于深度残差网络和注意力机制的声纹识别方法及装置。
5.为达到上述目的,本发明提供如下技术方案:
6.一种基于深度残差网络和注意力机制的声纹识别方法,包括以下步骤:
7.s1:对采集到的音频数据进行预处理,得到能够模拟人耳某些特性(如对低频更敏感)的梅尔频率倒谱系数(mel frequency cepstral coefficents,mfcc)特征x;
8.s2:构建帧级注意力模块(frame-level attention module,fam),将s1得到的mfcc特征x经过帧级注意力模块对每帧的重要性进行加权运算,得到加权后的mfcc特征
9.s3:构建声纹识别网络并进行声纹识别;引入mobilenet的设计思想,将普通卷积
替换为深度可分离卷积以降低网络参数量;在resnet50的每一个layer后加入通道域注意力模块se block建模各个特征通道的重要程度,针对不同的说话人增强或抑制不同的通道,最后将特征输入网络中的分类器进行分类,实现声纹识别。
10.进一步,所述步骤s1包括如下步骤:
11.s11:将原始音频数据根据预设的固定长度进行分帧;
12.s12:对分帧以后的数据进行快速傅里叶变换,将每一帧的波形特征转换成频谱;
13.s13:将频谱数据转换为mfcc特征,即得到每一帧语音的d维特征向量,原始语音数据被分为n帧,则得到n*d的二维矩阵x。
14.进一步,所述步骤s2包括如下步骤:
15.所述帧级注意力模块fam由平均池化层和瓶颈层构成;所述平均池化层用于获得mfcc特征每一帧的全局信息嵌入,也就是求每一帧fn,n∈{1,n}的特征向量的平均值得到n维向量a,公式如下所示:
[0016][0017]
所述瓶颈层用于生成不同帧的权重,公式如下所示:
[0018]
y=softmax(w2δ(w1a))
[0019]
该过程由两层全连接层实现,其中第一全连接层w1将向量a压缩为n/r维向量减少参数量,之后用relu激活函数δ增加网络的非线性表达能力;第二全连接层w2将向量a恢复为n维,之后经过softmax激活函数得到n维权重向量y;将权重向量y的每一元素分别与原矩阵x的每一行相乘得到新的加权特征图公式如下所示:
[0020][0021]
式中xn为原矩阵x的第n行向量,yn为权重向量y的第n个元素。
[0022]
进一步,所述步骤s3包括如下步骤:
[0023]
s31:利用blocka代替resnet50的残差块;
[0024]
s32:将带有通道域注意力机制的se block嵌入每一blocka的尾部构成声纹识别网络基本组成模块blockb;
[0025]
s33:在resnet50原有全连接层的后面加上一层relu激活函数以及一层全连接层构成新的分类器(classifier),完成声纹识别网络的构建。
[0026]
进一步,步骤s31中所述blocka采用残差连接结构,其中残差分支采用3*3的深度卷积(depthwise convolution)提取特征,所述3*3卷积核后面加上用于控制输出特征图维度的1*1点向卷积(pointwise convolution)构成可降低网络参数量的深度可分离卷积模块,每一卷积核后跟上标准归一化操作和relu激活函数增加网络非线性表达能力,最后将残差分支得到的特征图与当前层特征图进行残差连接。
[0027]
进一步,步骤s32中所述带有通道域注意力机制的se block通过对特征通道间的重要性进行建模,把重要的特征进行强化来提升准确率,即通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。
[0028]
进一步,步骤s33中所述分类器由一个瓶颈层和激活函数softmax构成,其中瓶颈
层的结构与fam中的瓶颈层结构相同,由两个全连接层和一个relu激活层构成,用于降维减少全连接层的参数量,最后softmax层输出一个c维向量代表c个说话人分别对应的概率,选取其中最大概率值进行阈值判定,大于阈值则将最大概率值对应的说话人id作为最终识别结果,小于阈值则认为是客户语音。
[0029]
进一步,步骤s33所述声纹识别网络构成如下:3
×
3conv(layer0)-》3
×
blockb(layer1)-》4
×
blockb(layer2)-》6
×
blockb(layer3)-》3
×
blockb(layer4)-》classifier;其中layer0的通道数为16,后续每一layer的通道数为前一layer通道数的两倍,并且layer1至layer4中每一layer的第一个blocka的3
×
3卷积核步长stride设为2以减小特征图尺寸,其余卷积核步长均为1,另外所有3*3卷积核的填充padding设为1。
[0030]
本发明还提供一种基于深度残差网络和注意力机制的声纹识别装置,包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时,实现如上任一所述的基于深度残差网络和注意力机制的声纹识别方法。
[0031]
本发明的有益效果在于:本发明提供的帧级注意力模块,适用于大部分声纹识别方法,通过对mfcc特征进行加权运算,削弱受噪声影响较大的语音帧,可有效提升声纹识别方法精度。本发明提供的声纹识别网络,适用于大部分基于深度神经网络的声纹识别方法,通过引入深度可分离卷积和通道域注意力机制,有效克服传统神经网络参数量大、效率低等缺点,可在有效提升算法精度指标的情况下进一步缩短网络推理时延。
[0032]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0033]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0034]
图1为本发明所述一种基于深度残差网络和注意力机制的声纹识别方法流程图;
[0035]
图2为本发明中提出的帧级注意力模块详细结构图;
[0036]
图3为本发明中改进的blocka结构图;
[0037]
图4为本发明中所述的se block结构图。
具体实施方式
[0038]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0039]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不
代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0040]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0041]
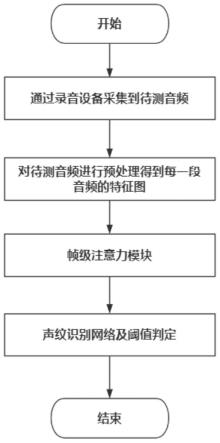
本发明提供一种基于深度残差网络和注意力机制的声纹识别方法,该方法能够显著提高识别模型的鲁棒性并改善说话人识别的识别准确率。如图1所示,本方法包括如下步骤:
[0042]
s1:对采集到的音频数据进行预处理,得到mfcc特征x;
[0043]
s11:在一种实施方式中,取每100秒的音频进行识别,将原始音频数据根据预设的固定长度35毫秒进行分帧,帧与帧之间重叠10毫秒;
[0044]
s12:对分帧以后的数据进行快速傅里叶变换,将每一帧的波形特征转换成频谱;
[0045]
s13:将频谱转换为梅尔频率倒谱系数(mfcc)特征以得到每一帧语音的160维特征向量,由s11可知原始语音数据被分为4000帧,这样即得到160*4000的二维矩阵x;
[0046]
s2:构建帧级注意力模块筛选重要帧。考虑到在采集语音信号时某些语音帧会受到噪声的影响,而一定程度的噪声会使得该帧语音信号对识别任务不起作用,所以引入本发明提出的帧级注意力模块削弱受噪声影响过大的语音帧权重以降低其对识别任务的影响。该识别模型首先将步骤s1得到的特征经过帧级注意力模块fam对每帧的重要性进行加权运算,得到加权后的mfcc特征
[0047]
如图2所示,所述帧级注意力模块fam由平均池化层和瓶颈层构成。所述平均池化层用于获得mfcc特征每一帧的全局信息嵌入,也就是求每一帧fn,n∈{1,n}的特征向量的平均值得到n维向量a,公式如下所示:
[0048][0049]
所述瓶颈层用于生成不同帧的权重,公式如下所示:
[0050]
y=softmax(w2δ(w1a))
[0051]
该过程由两层全连接层实现,其中第一全连接层w1将向量a压缩为n/r维向量减少参数量,之后用relu激活函数δ增加网络的非线性表达能力;第二全连接层w2将向量a恢复为n维,之后经过softmax激活函数得到n维权重向量y。将该权重向量y的每一元素分别与原矩阵x的每一行相乘得到新的加权特征图公式如下所示:
[0052][0053]
式中xn为原矩阵x的第n行向量,yn为权重向量y的第n个元素。
[0054]
s3:构建声纹识别网络并进行声纹识别。考虑到普通卷积方式中每个卷积核与特征图的通道数相同,随着网络层数的增加,特征图的通道数会不断倍增,这样卷积核的参数
量会成指数增长的方式增加,所以这里引入mobilenet的设计思想,将普通卷积替换为深度可分离卷积以降低网络参数量。另外在resnet50的每一个layer后加入通道域注意力模块se block建模各个特征通道的重要程度,针对不同的说话人增强或抑制不同的通道,最后将特征输入网络中的分类器进行分类,实现声纹识别。具体包括以下步骤:
[0055]
s31:利用本发明改进的blocka代替resnet50的残差块;如图3所示,所述blocka采用残差连接结构,其中残差分支采用3*3的深度卷积(depthwise convolution)提取特征,所述3*3卷积核后面加上用于控制输出特征图维度的1*1点向卷积(pointwise convolution)构成可降低网络参数量的深度可分离卷积模块,每一卷积核后跟上标准归一化操作和relu激活函数增加网络非线性表达能力,最后将残差分支得到的特征图与当前层特征图进行残差连接。
[0056]
s32:将带有通道域注意力机制的se block嵌入每一blocka的尾部构成声纹识别网络基本组成模块blockb;如图4所示,所述带有通道域注意力机制的se block可通过对特征通道间的重要性进行建模,把重要的特征进行强化来提升准确率。即通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。
[0057]
s33:在resnet50原有全连接层的后面加上一层relu激活函数以及一层全连接层构成新的分类器(classifier),完成声纹识别网络的构建。所述分类器由一个瓶颈层和激活函数softmax构成,其中瓶颈层的结构与fam中的瓶颈层结构相同,由两个全连接层和一个relu激活层构成,用于降维减少全连接层的参数量,最后softmax层输出一个300维向量代表300个说话人分别对应的概率,选取其中最大概率值进行阈值判定,大于阈值则将最大概率值对应的说话人id作为最终识别结果,小于阈值则认为是客户语音。
[0058]
所述声纹识别网络构成如下:3
×
3conv(layer0)-》3
×
blockb(layer1)-》4
×
blockb(layer2)-》6
×
blockb(layer3)-》3
×
blockb(layer4)-》classifier。其中layer0的通道数为16,后续每一layer的通道数为前一layer通道数的两倍,并且layer1至layer4中每一layer的第一个blocka的3
×
3卷积核步长stride设为2以减小特征图尺寸,其余卷积核步长均为1,另外所有3*3卷积核的填充padding设为1。如表1所示,是本实施例中使用的声纹识别网络结构详细信息。
[0059]
表1
[0060]
[0061][0062]
本发明还可提供一种声纹识别模型训练方式,包括:准备每个说话人的至少200条纯净语音数据,所述每条语音数据为wav文件,且长度在2至8秒内。将所得数据集以2:8的比例划分为测试集和训练集,其中训练集存入train文件夹,测试集存入test文件夹。为了模拟真实场景中的数据分布,对训练集进行加噪处理,得到相应的加噪语音。采用kaldi的数据增强方法在纯净语音中分别对应增加背景音乐声、背景说话人声、环境噪声,将得到的加背景音乐语音数据存放在music文件夹中、加背景说话人语音数据存放在babble文件夹中、加环境噪声语音存放在noise文件夹中,初始的纯净语音存放在voice文件夹中。对每条语音数据进行数据标注,这里以voice文件夹中的数据标注为例,标签文件voice_label.csv中每一行对应一条语音数据的标签,第一列代表类别,第二列代表对应语音数据的相对路径,将标签文件存放于voice文件夹下,另外music、babble和noise文件夹下的数据标注方式相同。
[0063]
训练声纹识别网络:使用pytorch框架,将所述train文件夹、test文件夹中的文件装载到dataloader中,参数初始值使用基于方差缩放的xavier初始化,批处理大小设置为256,初始学习率设置为0.001,第100轮开始每隔10轮学习率降低为之前的90%,选用adam优化器,用梯度下降法更新声纹识别网络的权重值,训练迭代次数为200次,选取第150轮之后loss值最低的一轮作为最终模型,得到训练好的声纹识别网络。
[0064]
本发明还可提供的一种计算机设备,包括:至少一个处理器、存储器、至少一个网络接口和用户接口。该设备中的各个组件通过总线系统耦合在一起。可理解,总线系统用于实现这些组件之间的连接通信。总线系统除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。
[0065]
其中,用户接口可以包括显示器、键盘或者点击设备(例如,鼠标,轨迹球(trackball)、触感板或者触摸屏等。
[0066]
可以理解,本技术公开实施例中的存储器可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read-only memory,rom)。易失性存储器可以是随机存取存储器(random access memory,ram),其用作外部高速缓存。
[0067]
在一些实施方式中,存储器存储了如下的元素,可执行模块或者数据结构,或者他们的子集,或者他们的扩展集:操作系统和应用程序。其中,操作系统,包含各种系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务。应用
程序,包含各种应用程序,例如媒体播放器(media player)、浏览器(browser)等,用于实现各种应用业务。实现本公开实施例方法的程序可以包含在应用程序中。
[0068]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。