技术特征:
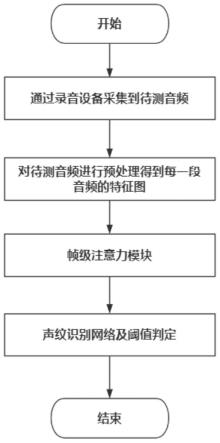
1.一种基于深度残差网络和注意力机制的声纹识别方法,其特征在于:包括以下步骤:s1:对采集到的音频数据进行预处理,得到能够模拟人耳特性的梅尔频率倒谱系数mfcc特征x;s2:构建帧级注意力模块fam,将步骤s1得到的mfcc特征x经过帧级注意力模块对每帧的重要性进行加权运算,得到加权后的mfcc特征s3:构建声纹识别网络并进行声纹识别;引入mobilenet的设计思想,将普通卷积替换为深度可分离卷积以降低网络参数量;在resnet50的每一个layer后加入通道域注意力模块se block建模各个特征通道的重要程度,针对不同的说话人增强或抑制不同的通道,最后将特征输入网络中的分类器进行分类,实现声纹识别。2.根据权利要求1所述的基于深度残差网络和注意力机制的声纹识别方法,其特征在于:所述步骤s1包括如下步骤:s11:将原始音频数据根据预设的固定长度进行分帧;s12:对分帧以后的数据进行快速傅里叶变换,将每一帧的波形特征转换成频谱;s13:将频谱数据转换为mfcc特征,即得到每一帧语音的d维特征向量,原始语音数据被分为n帧,则得到n*d的二维矩阵x。3.根据权利要求1所述的基于深度残差网络和注意力机制的声纹识别方法,其特征在于:所述步骤s2包括如下步骤:所述帧级注意力模块fam由平均池化层和瓶颈层构成;所述平均池化层用于获得mfcc特征每一帧的全局信息嵌入,也就是求每一帧f
n
,n∈{1,n}的特征向量的平均值得到n维向量a,公式如下所示:所述瓶颈层用于生成不同帧的权重,公式如下所示:y=softmax(w2δ(w1a))该过程由两层全连接层实现,其中第一全连接层w1将向量a压缩为n/r维向量减少参数量,之后用relu激活函数δ增加网络的非线性表达能力;第二全连接层w2将向量a恢复为n维,之后经过softmax激活函数得到n维权重向量y;将权重向量y的每一元素分别与原矩阵x的每一行相乘得到新的加权特征图公式如下所示:式中x
n
为原矩阵x的第n行向量,y
n
为权重向量y的第n个元素。4.根据权利要求1所述的基于深度残差网络和注意力机制的声纹识别方法,其特征在于:所述步骤s3包括如下步骤:s31:利用blocka代替resnet50的残差块;s32:将带有通道域注意力机制的se block嵌入每一blocka的尾部构成声纹识别网络基本组成模块blockb;s33:在resnet50原有全连接层的后面加上一层relu激活函数以及一层全连接层构成新的分类器,完成声纹识别网络的构建。
5.根据权利要求4所述的基于深度残差网络和注意力机制的声纹识别方法,其特征在于:步骤s31中所述blocka采用残差连接结构,其中残差分支采用3*3的深度卷积提取特征,所述3*3卷积核后面加上用于控制输出特征图维度的1*1点向卷积构成可降低网络参数量的深度可分离卷积模块,每一卷积核后跟上标准归一化操作和relu激活函数增加网络非线性表达能力,最后将残差分支得到的特征图与当前层特征图进行残差连接。6.根据权利要求4所述的基于深度残差网络和注意力机制的声纹识别方法,其特征在于:步骤s32中所述带有通道域注意力机制的se block通过对特征通道间的重要性进行建模,把重要的特征进行强化来提升准确率,即通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。7.根据权利要求4所述的基于深度残差网络和注意力机制的声纹识别方法,其特征在于:步骤s33中所述分类器由一个瓶颈层和激活函数softmax构成,其中瓶颈层的结构与fam中的瓶颈层结构相同,由两个全连接层和一个relu激活层构成,用于降维减少全连接层的参数量,最后softmax层输出一个c维向量代表c个说话人分别对应的概率,选取其中最大概率值进行阈值判定,大于阈值则将最大概率值对应的说话人id作为最终识别结果,小于阈值则认为是客户语音。8.根据权利要求4所述的基于深度残差网络和注意力机制的声纹识别方法,其特征在于:步骤s33所述声纹识别网络构成如下:3
×
3conv(layer0)->3
×
blockb(layer1)->4
×
blockb(layer2)->6
×
blockb(layer3)->3
×
blockb(layer4)->classifier;其中layer0的通道数为16,后续每一layer的通道数为前一layer通道数的两倍,并且layer1至layer4中每一layer的第一个blocka的3
×
3卷积核步长stride设为2以减小特征图尺寸,其余卷积核步长均为1,另外所有3*3卷积核的填充padding设为1。9.一种基于深度残差网络和注意力机制的声纹识别装置,其特征在于:包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时,实现如权利要求1-8任一项所述的基于深度残差网络和注意力机制的声纹识别方法。
技术总结
本发明涉及一种基于深度残差网络和注意力机制的声纹识别方法、装置及计算机可读存储介质,属于语音识别技术领域,包括步骤:S1:对采集到的音频数据进行预处理,得到能够模拟人耳某些特性的MFCC特征;S2:构建FAM,将S1得到的特征经过帧级注意力模块对每帧的重要性进行加权运算,得到加权后的MFCC特征;S3:构建声纹识别网络并进行声纹识别;引入MobileNet的设计思想,将普通卷积替换为深度可分离卷积以降低网络参数量;在ResNet50的每一个layer后加入通道域注意力模块建模各个特征通道的重要程度,针对不同的说话人增强或抑制不同的通道,最后将特征输入网络中的分类器进行分类,实现声纹识别。实现声纹识别。实现声纹识别。
技术研发人员:钱鹰 陈仕杰 杨世利 陈雪 刘歆 柯礼灵 熊炜
受保护的技术使用者:重庆市住房公积金管理中心
技术研发日:2022.03.17
技术公布日:2022/6/28
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。