1.本发明属于数据库建设领域,具体涉及一种基于文献的土壤因素微生物多样性数据库的构建方法。
背景技术:
2.土壤微生物数量巨大、种类繁多且功能活跃,以群落形式存在于土壤中,通过影响土壤养分含量及有机质转化,进而影响土壤质量及植物生长。近年来,由于全球气候变化、土地资源过度利用、环境污染情况日益加剧等因素,土壤微生物多样性遭到严重破坏,因此,开展对土壤因素和土壤微生物多样性关系的研究,不仅能对受人类污染的土壤的微生物多样性和组成成分变化进行预测和评估,还能对微生物优势种群的功能进行进一步探索,为土地污染控制、保护利用、土壤可持续发展提供理论依据。
3.目前已有的大多文献仅限于某一地区或单一因素对土壤微生物多样性的研究,暂无有一定公共认可性的数据集或公开数据库,学者们数据的来源除实地测量外,只有通过阅读海量的历史文献来更加全面的获取。但对于作者来说,需要阅读大量文献资料进行统计整理,而且每过几年就需要更新来保证此类文献的统计知识的实时性,工作量大且繁琐。而对于读者来说,想要快速地获取此类统计知识还需要自行搜索综述文献并判断它们的权威性,获取的知识也受文献撰写者想要展示出的如地区、年份等的限制。而且目前尚未探索出土壤因素,污染情况与土壤微生物多样性之间的关系,想要找出背后的规律,需要大量的数据支持。
4.加之近年来人工智能的快速发展为大数据背景下的数据挖掘提供了新的思路。机器学习作为人工智能的核心方法,已被成功应用于生态环境领域。这给研究任意土壤区域微生物多样性及组成提供了一种新思路,避免了后来学者繁琐的统计工作,对土壤微生物的研究具有重大意义。若想将机器学习应用于探究环境污染、土壤环境因素与土壤微生物多样性及组成之间的关系,筛选并量化重要因素对土壤微生物的影响,并预测全球尺度下的微生物多样性,就必须建立完整全面的土壤因素-微生物多样性数据库。
5.其他领域如临床医学、社会化政务等已经出现了对文献进行结构化分析的思想与应用。在临床医学领域,出现了系统综述和meta分析。在社会化政务领域,有学者在2015年提出了一个结构化的文献分析框架,以此对现有的社会化政务国外研究文献进行了总结和分析,并且已取得了一定的进展,为社会化政务的研究提供了一定的依据和启示。由此可以看到,尽管在其他领域已有一些前期的研究,但在土壤微生物领域少有涉及,这是因为土壤微生物文献数据具有极强的时效性,且数据在文献中多以图表形式,难以通过文献语言处理等智能方法收集,因此在本发明中,主要由项目成员人工阅读分析文献,依照合适的数据筛选原则构建具有时效性,可直接应用于后续人工智能或其他研究的数据库。
技术实现要素:
6.本发明所要解决的问题是,提供一种基于文献的土壤因素微生物多样性数据库的
构建方法,该构建方法能够收集分散在海量土壤微生物历史文献中的数据,存储建成access数据库,并利用access数据库对数据进行更新,可视化及分析。
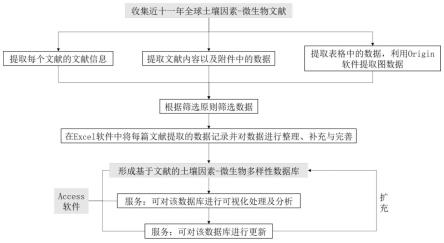
7.本发明的技术方案是基于文献的土壤因素微生物多样性数据库的构建方法,包括以下步骤:
8.(1)收集全球土壤因素-微生物文献,确定文献数据库包含的文献相关属性、土壤因素数据、微生物多样性数据;
9.(2)提取每个文献的文献信息,整理文献信息数据;
10.(3)阅读文献内容以及附件内容,提取数据库包含的土壤因素、污染情况和微生物多样性及组成的数据,整理土壤因素-微生物多样性数据;
11.(4)对文献中图和表进行数据提取,利用origin软件以提取数据图中具体数值,整理土壤因素-微生物多样性数据;
12.(5)在excel软件中将每篇文献中按照步骤(2)、(3)、(4)提取的文献相关属性、土壤因素、微生物多样性数据整理完毕,在access软件中进行存储,形成基于文献的土壤因素-微生物多样性数据库;
13.(6)在access软件中可对该数据库进行更新,可视化及分析。
14.针对数据库更新,可利用access交叉表查询向导进行同日期汇总,或直接进行表合并或导入,后续还可利用众包平台用户输入文献数据、文本统计数据以及上传图像,以实现数据扩增。
15.针对数据库可视化,可利用access数据库集数据存储-数据筛选-数据可视化与一体,结合sql、vba、控件快速开发动态图表。
16.针对数据分析,在access数据库中利用sql语言进行查询分析,分布分析或数据地图分析。
17.技术效果
18.与现有技术相比,本发明构建了基于文献的土壤微生物数据库,该数据库能够提供给用户方便查询的文献及数据,尤其是针对后续可能利用人工智能进行的其他研究。本数据库有大量,简便,数据涵盖全球范围,多重因素分析和时效性等优点,此外,还利用access数据库本身的功能提供更新、可视化、数据分析等附加服务,来吸引用户扩充数据库,应用数据库。
附图说明
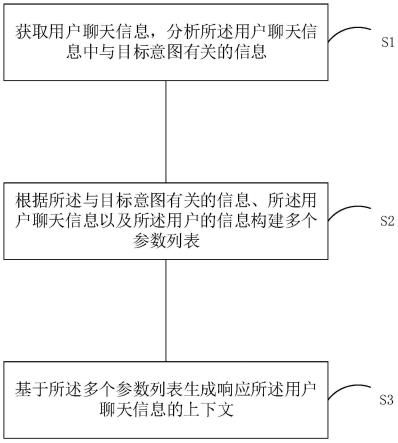
19.图1是本发明提供的基于文献的土壤因素-微生物多样性数据库的构建方法实施例的实现框图
具体实施方式
20.为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
21.基于背景技术,本发明通过调研和查询等形式研究土壤及土壤微生物领域的关键指标参数,归纳出包含文章发表信息、研究情境及方法、土壤微生物群落指标和土壤指标的
数据库基本信息提取指标,规定数据筛选原则,收集世界各地范围内近十一年来(2010年1月至2021年12月)的相关论文作为数据源,提取文献信息、文献内容及附件数据及图表中数据,在excel中记录,导入access软件生成数据库,并在access中设置以文献序号作为主键字段以方便后续补充查找。
22.后续可按照同样的检索与筛选方法查找新论文,针对数据库实时更新,利用access交叉表查询向导进行汇总补充,还可以以在线网站的形式利用众包平台用户输入文献信息、文献内容数据以及上传图像,最终实现一个实时、全面、可扩展的全球土壤因素-微生物数据库知识获取平台。
23.参见图1,本实施例提供的基于文献的土壤因素-微生物多样性数据库的构建方法,包括以下步骤:
24.(1)收集全球土壤因素-微生物文献,确定文献数据库包含的文献相关属性、土壤因素数据、微生物多样性数据。我们在web of science网站上使用“soil”“bacteri*”“fung*”作为关键词查找2010年1月至2021年12月近十一年内共计422篇出版物。根据已有论文和经验,我们收集数据范围涵盖土壤微生物群落的27个指标,在微生物多样性方面,除了包括细菌生物量(16s基因数)、真菌生物量(its基因数)、细菌多样性(香农指数、辛普森指数)、真菌多样性(香农指数、辛普森指数)这些常规的多样性指标,我们还收集了一些常见的优势物种在门水平上的相对丰度(例如细菌中的变形菌门、酸杆菌门、真菌中的子囊菌门和被孢霉纲),这些指标可以体现微生物的物种组成,利于我们对污染物影响微生物物种组成的分析研究。除了微生物群落指标,数据集还包括21个土壤因素指标,包括采样时间、土壤位置(经纬度、海拔)、年均温、年均降水、土壤机械组成、样本深度、植被类型(森林、灌木、草原、苔原、湿地、沙漠、农田)、ph、土壤总碳、土壤总有机质、土壤总氮、磷。此外,为了研究土壤污染情况对微生物多样性的影响,我们收集了土壤污染的类型(重金属污染、有机物污染、无机物污染、有害微生物污染、放射性污染)。这些数据分别从文献文本,附件和图表中提取,在整理数据时,我们按照一定的条件筛选,数据的筛选条件为:
①
只选择实地研究,不包括实验室孵化研究;
②
数据至少包含一个微生物群落指标,包括微生物生物量(16s基因和its基因数)、微生物多样性(香农指数、辛普森指数)、优势种在门层面的相对丰度;
③
数据至少包含了一种微生物类型(细菌或真菌);
④
通过高通量测序技术量化了微生物群落结构;
⑤
数据至少包含了一种污染类型
25.(2)提取每个文献的文献信息,整理文献信息数据;先将每篇文献的标题、出版年提取到excel表格内,按照并以一定的文献序号排列,便于后续导入access的查找。
26.(3)阅读文献内容以及附件内容,提取数据库包含的土壤因素和微生物多样性数据并按照筛选原则筛选,整理土壤因素-微生物多样性数据;
27.(4)对文献中图和表进行数据提取,利用origin软件以提取图中具体数值并根据筛选原则筛选,整理土壤因素-微生物多样性数据。这里具体应用到了图数据处理软件origin,具体操作步骤为:将图片在软件中打开,利用工具中的图像数字化工具,手动选取坐标轴,并输入图中坐标值。坐标规定完成后即可开始手动取点,手动选取图像中应提取数值的点。取点完成后点击结果,跳转到数据,打开数据列表,就能得到选取的点所对应的数值了,在excel表格中记录,将格式统一。
28.(5)在excel软件中将每篇文献中按照步骤(2)、(3)、(4)提取的文献相关属性、土
微生物多样性数据库。该数据库可为机器学习等人工智能的应用提供数据基础。现简单介绍一种该数据库在机器学习中的应用方法。
38.我们利用三种机器学习算法:随机森林、人工神经网络和支持向量机训练土壤因素-微生物多样性回归模型,旨在探究土壤因素与微生物多样性之间的关系。通过不同的污染类型,将数据集分成5个子集,对于每个机器学习算法,建立了5个回归模型。模型均基于scikit-learn进行训练。随机森林模型采用500个随机决策树并在每个节点选择5个随机特征。人工神经网络模型是两层全连接的,能够更好地学习到非线性的规律,工作流程与随机森林的工作流程类似。支持向量机模型选择径向基函数(rbf)作为核函数,正则化参数设置为1。对于每个模型,选择“adam”作为优化器,提升模型的收敛速度和调参性能,应用十折交叉验证方法来估计算法的平均回归准确度,计算预测值和观察值之间的10倍r2和均方根误差(rmse)值的平均值以衡量模型性能。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。