1.本发明属于动态草图检索领域,具体涉及一种融合图像标签信息的手绘图像实时检索方法。
背景技术:
2.由于触摸屏的发展,近年来基于草图的图像检索可以灵活地使用不受限制的手绘草图查询自然图像受到广泛关注。草图检索根据检索类别不同可以分为粗粒度草图检索(category-level sketch retrieval,cbir)和细粒度草图检索(fine grained sbir,fg-sbir)。细粒度草图检索fg-sbir是针对手绘草图的细节进行图像匹配,旨在检索图库中的特定照片。目前,对于fg-sbir的研究取得了很大的进展,但在绘制草图的过程中存在三个问题阻碍了fg-sbir在实践中的广泛应用:(1)用户的绘图技能不足,绘制的草图样式差异比较大,造成检索效率低下。(2)绘制完整草图所需的时间以及用最少的笔画检索到目标图像缩短草图检索时间这也是必须考虑的问题。(3)草图具有抽象性,草图检索时一般用简单的线条搜索目标图像,样本草图含有的信息仅有黑白线条,信息比较少。其次,草图具有多异性,样式差异小的目标图像(例如:女士高跟鞋)的轮廓相似性极高,导致他们的草图也具有极高相似性,从草图中没有办法区分,这也是导致早期草图检索效率低下的原因。传统方法中用户检索商品时,只能使用线条来检索目标图像,在检索过程中如果用户想要红色颜色的椅子,但是因为线条信息不包含颜色信息,可能在检索时用户在后期草图完整时才能检索到想要的内容。
3.综上所述,现有技术存在技术问题是:在笔画信息少的时候如何提升检索效率。
技术实现要素:
4.本发明为解决上述技术问题,提出了一种融合图像标签信息的手绘图像实时检索方法,将草图的样式融合草图检索框架中增加草图信息,增强草图检索的早期检索效率。用户在进行早期草图检索时,同时使用目标图像的颜色、特征等信息进行查询,可以在笔画信息少的时候大大增加检索效率。
5.一种融合图像标签信息的手绘图像实时检索方法,包括:
6.向通过训练集训练改进的神经网络模型输入目标图像的手绘图像和标签信息,实时检索并获得检索结果;
7.所述训练改进的神经网络模型,包括f1、f2、f3、f
ex
,其中,f1为预训练网络,f2为注意力层,f3为降维层,f
ex
为标签提取层;
8.改进的神经网络模型的训练过程包括以下步骤:
9.s1:构建训练集,训练集包括由多张图像及其对应收回的完整草图组成的图像集和图像对应的扩充标签集,图像对应的扩充标签集由该图像所有标签信息组成;
10.s2:训练中每一步选取图像集中的一张图像作为目标图像,利用该图像对应的手绘草图,训练神经网络模型的f1、f2、f3三个分支,训练完成后固定f1、f2参数,同时训练完成
后通过f1、f2、f3提取所有目标图像的嵌入向量;
11.s3:将图像集中的目标图像输入进训练好的f1中,得到目标图像的特征图,将特征图输入进f
ex
,预测图像的标签,根据扩充标签集中的标签信息,采用交叉熵损失函数,训练f
ex
,训练完成后固定参数;
12.s4:将图像集中每一张图像的完整草图按照绘图的笔画顺序渲染为多张草图,每一张草图渲染完成后组成该图像集的草图分支集,通过f1、f2、f3提取草图分支的嵌入向量;
13.s5:采用三重损失函数计算草图分支中每一张图片的嵌入向量和目标图像的嵌入向量误差,将该误差进行反向传播,以逼近目标图像、远离非目标图像为目标,调整模型中f3的参数;
14.s6:获取下一张目标图像的草图分支,重复上述步骤s4-s6,直至模型达到训练次数上限。
15.进一步的,将一张图像的完整草图根据绘图的笔画顺序渲染为n张图片,n张图片组成一个草图分支,该草图分支中每一张图片包括完整草图的第一笔至第n笔且每张图片笔画不同,1≤n≤n,根据图片包含的笔画数升序排列,则一个草图分支s={s1,s2,
…
,sn,
…
,sn},sn表示包含第一笔到第n笔笔画的图片。
16.进一步的,对训练集中的图像设置标签l={l1,l2,
…
,ln,
…
,ln},用于训练标签提取层f
ex
,其交叉熵损失loss表达式为:
[0017][0018]
其中k表示标签包含的类别总数;n表示样本总数;n表示第n个样本;p
nc
表示样本n属于c类的概率;l
nc
表示样本n的c类的正确概率标签;
[0019]
进一步的,采用三重损失函数计算草图分支中每一张图片的嵌入向量和目标图像的嵌入向量误差,其三重损失loss的表达式为:
[0020]
loss=max(d(v
si
,v
p
)-d(v
si
,vn) α,0)
[0021]
其中,v
si
表示草图分支中第i张图片的嵌入向量;v
p
表示目标图像的嵌入向量;vn表示图像集中除目标图像外的随机一个图像的嵌入向量;α是一个常数;d是欧式距离计算。
[0022]
进一步的,用户输入目标图像的手绘草图和标签信息,实时检索并获得最终检索结果步骤包括:
[0023]
步骤一:用户输入的草图经过图像距离网络f1、f2、f3获得第i步的草图嵌入向量v
si
;
[0024]
步骤二:计算v
si
与数据库中每个图像的嵌入向量v
p
的欧氏距离,获得距离向量d={d1,d2,
…
,dn,
…
,dn};
[0025]
步骤三:计算距离向量中元素的平均值,并将f1输出的特征图输入f
ex
预测输入草图的标签概率,利用softmax处理标签概率,得到伪标签;
[0026]
步骤四:根据伪标签与输入标签的关系对距离向量中元素的平均值dm进行加权,得到标签加权距离值d
l
;
[0027]
步骤五:对标签加权距离赋予一个衰减系数,根据d与d
l
之和对数据库中的图像进行排序,并获得检索结果。
[0028]
进一步的,采用卷积神经网络预测图像的标签概率,并经过softmax处理得到n个样本分别属于类别c的概率向量集pc={p
1c
,p
2c
,
…
,p
nc
,
…
,p
nc
},将pc作为伪标签,样本n属于类别c的概率p
nc
表示为:
[0029][0030]
其中,v
nc
表示样本n属于类别c的概率向量;v
nk
表示样本n的标签类别总数的概率向量;k表示标签包含的类别总数;n表示样本总数;n表示第n个样本;p
nc
表示样本n属于c类的概率。
[0031]
进一步的,根据伪标签与输入标签的关系对距离向量中元素的平均值dm加权处理,得到标签加权距离值d
l
,样本n的伪标签的最大值即max(pn)为该样本所属标签类别,若max(pn)》0.8,则将样本n标记为可信样本,否则标记为不可信样本;若伪标签max(pn)》0.8且与输入标签相同,样本n为可信正样本;若伪标签max(pn)》0.8且与输入标签不同,样本n为可信负样本;否则为不可信样本,距离不进行加权处理;计算标签加权距离值d
l
的表达式为:
[0032][0033]
其中,dm表示距离向量中元素的平均值;dn表示样本n与草图的向量的欧式距离;n表示样本总数;ω
p
《0,ω
p
为可信负样本标签加权权重,ωn》0,ωn为可信正样本标签加权权重;pn表示样本n的概率值伪标签。
[0034]
进一步的,对标签加权距离赋予一个衰减系数,d与d
l
之和对数据库中的图像进行排序,其表达式为:
[0035]dfinal
=d ω
·dl
[0036]
其中,d为草图分支与所有图像间距离向量;d
l
为标签距离加权值;d
final
为最终排序依据的距离;ω为标签加权距离权重,当i增大,即输入草图越完整时,ω逐渐减小。
[0037]
本发明融合草图的图像标签信息进行早期图像检索,根据目标图像的扩充标签集在早期含有笔画比较少的图像进行检索,将草图的样式融合草图检索框架中增加草图信息可以用最少的草图笔画检索出目标图片,从而减少了手绘草图的早期检索时间,提高了检索效率。
附图说明
[0038]
图1为本发明的基线模型图;
[0039]
图2为本发明的深度神经网络检索框架模型图;
[0040]
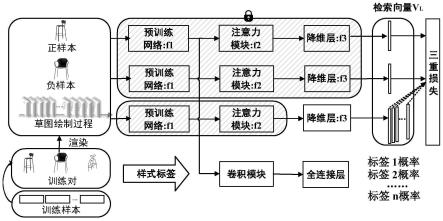
图3给出草图分支渲染过程以及图片标签分类示意图;
具体实施方式
[0041]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于
本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0042]
一种融合图像标签信息的手绘图像实时检索方法,该方法如图1-2所示,包括:
[0043]
获取目标图像的完整草图以及所有目标图像的标签信息,所有目标图像的标签信息组成一个扩充标签集,之后将一张完整草图根据绘图的笔画顺序渲染为n张图片,渲染完成后的n张图片组成一个草图分支,该草图分支中每一张图片包含完整草图的第一笔至第n笔且每张图片笔画不同,1≤n≤n,根据图片包含的笔画数升序排列,则一个草图分支s={s1,s2,
…
,sn,
…
,sn},sn表示包含第一笔到第n笔笔画的图片。
[0044]
如图3所示,从细粒度草图检索fg-sbir的图像检索数据集中选取qmul-shoe-v2数据集和qmul-chair-v2数据集作为本次模型训练数据集,从qmul-shoe-v2数据集和qmul-chair-v2数据集中分别选取一张图像为目标图像,获取该图像的完整草图和标签信息,构成扩充标签集,根据图片笔画顺序渲染得到目标图像的草图分支。
[0045]
具体地,如图3中(b)标签信息所示,找到不同绘画基础的志愿者让他们根据目标图像手绘出完整草图。根据两个数据集中的图片信息,给这两个数据集中的每一张图片打上相应的标签信息,并对标签信息的内容人为给出分类。
[0046]
具体地,如图3中的(a)手绘草图过程所示,对一张完整草图,根据草图的完整性将其渲染为n张图片,渲染完成后的n张图片为一个草图分支,该草图分支中每一张图片包含完整草图的第一笔至第n笔。例如:草图分支中的第一张图片只包含完整草图的第一笔,第二张图片包含了完整草图的第一笔和第二笔,第三张图片包含了完整草图的第一笔,第二笔,第三笔,以此类推。
[0047]
从qmul-shoe-v2数据集和qmul-chair-v2数据集中获取的多张目标图像与其对应手绘的完整草图组成图像集和所有目标图像的标签信息组成一个扩充标签集组成一个训练集,在训练模型时,同时给出一个分支专门用来训练图像的标签信息,检索时用该分支判断图像的的标签和输入的标签进行对比进行辅助检索;向完成训练的改进的神经网络模型输入目标图像的手绘草图和标签信息,实时检索并获得目标图像;
[0048]
改进的神经网络模型的训练过程包括以下步骤:
[0049]
s1:构建训练集,训练集包括由多张图像及其对应收回的完整草图组成的图像集和图像对应的扩充标签集,图像对应的扩充标签集由该图像所有标签信息组成;
[0050]
s2:训练中每一步选取图像集中的一张图像作为目标图像,利用该图像对应的手绘草图,训练神经网络模型的f1、f2、f3三个分支,训练完成后固定f1、f2参数,同时训练完成后通过f1、f2、f3提取所有目标图像的嵌入向量;
[0051]
s3:将图像集中的目标图像输入进训练好的f1中,得到目标图像的特征图,将特征图输入进f
ex
,预测目标图像的标签;根据扩充标签集中的标签信息,采用交叉熵损失函数,训练f
ex
,训练完成后固定参数;
[0052]
s4:将图像集中每一张图像的完整草图按照绘图的笔画顺序渲染为多张草图,每一张草图渲染完成后组成该图像集的草图分支集,通过f1、f2、f3提取草图分支的嵌入向量;
[0053]
s5:采用三重损失函数计算草图分支中每一张图片的嵌入向量和目标图像的嵌入向量误差,将该误差进行反向传播,以逼近目标图像、远离非目标图像为目标,调整模型中f3的参数;
[0054]
s6:获取下一张目标图像的草图分支,重复上述步骤s4-s6,直至模型达到训练次数上限。
[0055]
改进的神经网络模型的训练过程步骤s3中,所述根据扩充标签集中的标签信息,采用交叉熵损失函数,训练f
ex
,包括:对训练集中的图像设置标签l={l1,l2,
…
,ln,
…
,ln},用于训练标签提取层f
ex
,其交叉熵损失loss表达式为:
[0056][0057]
其中k表示标签包含的类别总数;n表示样本总数;p
nc
表示样本n属于c类的概率;l
nc
表示样本n的c类的正确概率标签。
[0058]
改进的神经网络模型的训练过程步骤s5中采用三重损失函数计算草图分支中每一张图片的嵌入向量和目标图像的嵌入向量误差,其三重损失loss的表达式为:
[0059]
loss=max(d(v
si
,v
p
)-d(v
si
,vn) α,0)
[0060]
其中,v
si
表示草图分支中第i张图片的嵌入向量;v
p
表示目标图像的嵌入向量;vn表示图像集中除目标图像外的随机一个图像的嵌入向量;α是一个常数;d是欧式距离计算。
[0061]
优选的,用户输入目标图像的手绘草图进f1,通过f
ex
预测目标图像的标签概率,利用softmax处理标签概率,得到伪标签,将伪标签存入数据库;
[0062]
进一步的,采用卷积神经网络预测图像的标签概率,并经过softmax处理得到n个样本分别属于类别c的概率向量集pc={p
1c
,p
2c
,
…
,p
nc
,
…
,p
nc
},将pc作为伪标签,保存在数据库中,样本n属于类别c的概率p
nc
表示为:
[0063][0064]
其中,v
nc
表示样本n属于类别c的概率向量;v
nk
表示样本n的标签类别总数的概率向量;k表示标签包含的类别总数;n表示样本总数;n表示第n个样本;p
nc
表示样本n属于c类的概率;
[0065]
进一步的,输入的草图经过图像距离网络f1、f2、f3获得第i步的草图嵌入向量v
si
,计算v
si
与数据库中每个图像的嵌入向量v
p
的欧氏距离,获得距离向量d={d1,d2,
…
,dn,
…
,dn};取d的平均值dm作为标签距离基准值,根据输入标签,选取数据库中所存softmax处理的对应输入标签类别的概率值伪标签pc={p
1c
,p
2c
,
…
,p
nc
,
…
,p
nc
},对距离dm进行加权,得到标签加权距离值d
l
,样本n的伪标签的最大值即max(pn)为该样本所属标签类别,若max(pn)》0.8,则将样本n标记为可信样本,否则标记为不可信样本;若伪标签max(pn)》0.8且与输入标签相同,样本n为可信正样本;若伪标签max(pn)》0.8且与输入标签不同,样本n为可信负样本;否则为不可信样本,距离不进行加权处理;同时对加权距离赋予一个衰减系数,使标签对检索结果的影响随着步骤增加而减少,最终根据d与d
l
之和对数据库中的图像进行排序,同时将数据库中的伪标签与目标图像的标签信息对比,并获得检索结果;其表达式为:
[0066]
[0067][0068]dfinal
=d ω
·dl
[0069]
其中,ω为标签加权距离权重,当i增大,即输入草图越完整时,ω逐渐减小;ω
p
《0,ω
p
表示可信负样本标签加权权重,ωn》0,ωn表示可信正样本标签加权权重;dn表示距离向量中元素的平均值;d为草图分支与所有图像间距离向量;d
l
为标签距离加权值;d
final
为最终排序依据的距离。
[0070]
在没有商品图片,且文字难以描述该商品时,用户可以凭借对商品的映象在触屏设备上手绘商品草图,同时可以输入想要检索到商品的特征(颜色、高低、形状等)同时检索,商品草图渲染为草图分支后输入训练好的神经网络模型,模型通过对草图分支的检索和标签分支部分的检索返回k张与商品草图最相似的图像,在笔画信息少的时候提升了检索效率。
[0071]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。