1.本发明涉及一种视频会议中的流媒体分发系统及方法,属于信息技术领域。
背景技术:
2.随着移动互联网的普及,企业和个人对实时视频通信的需求也越来越大,在家远程办公和远程商业活动逐渐成为流行趋势。视频会议的解决方案交互性强,加速了信息的交流,克服了地理距离的障碍,是实时视频通信中的重要场景。由于网络情况的复杂和不稳定性,传输高质量低延迟的视频流成为了视频会议场景中的重要挑战。
3.视频会议系统的qos(quality of service)很大程度上取决于服务器的设计与实现,良好设计的流媒体分发系统能够合理利用网络资源和计算资源,为各个用户提供高质量低延时的媒体流,达到高性价比的流媒体分发策略。目前,多人视频会议场景中目前主流的通讯架构主要有三种,分别是mesh、sfu、mcu:
4.mesh:参与通讯的每一方,都与其他方建立双向连接,每个人都将数据发送给所有其他用户,并且从所有其他用户那里接收数据,这样形成网状结构。这种结构的优点是没有中心节点,实现简单,并且节省了服务器的资源,但是缺点也很明显,在n个用户的会议中,每个用户要上传n-1份数据,并且下载n-1份数据,对于用户来说带宽消耗极大,只能支持小规模的会议。
5.mcu(multipoint control unit):该架构下有一个多点控制单元mcu作为中心节点,每个用户只需要将自己的数据发送给mcu服务器,并且只需要从mcu服务器上获取融合后的一路数据。即在n个用户的会议中,每个用户都只需要上传一路数据,下载一路数据,服务器也只需要提供n路数据的下载,对于用户和服务器的带宽需求都大为减少。并且能够利用编解码技术提供媒体流异构化的能力,满足更多用户的需求。但该方案要求mcu服务器对所有的媒体数据进行编解码和混流处理,属于计算密集的行为,对服务器性能要求较高。难以满足低延迟的体验。
6.sfu(selective forwarding unit):该架构下sfu像是一个媒体流路由器,接收终端的音视频流,根据需要转发给其他终端。每个用户只需要将自己的数据发送给sfu服务器,并从sfu服务器获取所有其他人的数据,即在n个用户的会议中,每个用户都只需要上传1份数据,并且下载n-1份数据,这样一来有效的降低了用户的带宽,相比mcu模式下服务器的下行带宽从n变为了n*(n-1),对于服务器的带宽要求增大了许多。sfu服务器不对媒体流进行处理,直接进行转发,参与人观看多路视频的时候可能会出现不同步,相同的视频流,不同的参与人看到的画面也可能不一致。但这种结构对服务器的资源消耗很小,直接转发也降低了延迟,提高了实时性。
7.根据上述三种结构的分析,有中心节点的sfu结构和mcu结构对整个会议的掌控力更强,更有利于对视频质量做出调控,但这两个结构又各有利弊:sfu结构下延时低,但是在与会人数较多的情况下,服务器的带宽消耗大,是不太经济的行为;mcu结构对带宽消耗小,能够做更多的质量调控,但是计算量大。
8.因此,如何基于真实的音视频会议场景,将sfu和mcu两种结构进行结合,以构建高性能的媒体拓扑结构,从而为用户提供更高质量的媒体流,已成为现有技术中亟待解决的技术问题之一。
技术实现要素:
9.有鉴于此,本发明的目的是提供一种视频会议中的流媒体分发系统及方法,能基于真实的音视频会议场景,将sfu和mcu两种结构进行结合,以构建高性能的媒体拓扑结构,从而为用户提供更高质量的媒体流。
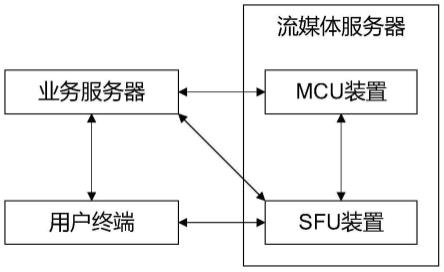
10.为了达到上述目的,本发明提供了一种视频会议中的流媒体分发系统,包括有流媒体服务器、业务服务器和多个用户终端,流媒体服务器上部署有mcu装置和sfu装置,当创建一个视频会议时,参加视频会议的用户包括有会上用户和旁观用户,正在分享视频的用户是会上用户,没有分享视频的用户是旁观用户,会上用户使用的用户终端简称为会上用户终端,旁观用户使用的用户终端简称为旁观用户终端,其中:
11.sfu装置,用于将视频会议中每个会上用户终端发来的媒体流转发给其他所有会上用户终端和mcu装置,并将mcu装置发来的混合媒体流转发给视频会议中的所有旁观用户终端;
12.mcu装置,用于将sfu装置发来的所有媒体流进行编解码和混流处理,以合成一路混合媒体流,然后将合成后的混合媒体流发给sfu装置;
13.用户终端,当用户是会上用户时,采集自身的媒体流,并发送给sfu装置,然后将sfu装置转发来的其他所有会上用户终端的媒体流进行编解码和混流处理,以合成一路混合媒体流在本地播放;当用户是旁观用户时,接收、并播放sfu装置发来的混合媒体流。
14.为了达到上述目的,本发明还提供了一种视频会议中的流媒体分发方法,包括有流媒体服务器、业务服务器和多个用户终端,流媒体服务器上部署有mcu装置和sfu装置,当创建一个视频会议时,参加视频会议的用户包括有会上用户和旁观用户,正在分享视频的用户是会上用户,没有分享视频的用户是旁观用户,会上用户使用的用户终端简称为会上用户终端,旁观用户使用的用户终端简称为旁观用户终端,还包括有:
15.步骤一、视频会议中每个会上用户终端分别采集自身的媒体流,并发送给sfu装置;
16.步骤二、sfu装置将每个会上用户终端发来的媒体流转发给视频会议中的其他所有会上用户终端和mcu装置;
17.步骤三、每个会上用户终端和mcu装置分别将sfu装置发来的所有媒体流进行编解码和混流处理,以合成一路混合媒体流,然后,每个会上用户终端将自身合成的混合媒体流在本地播放,mcu装置将合成后的混合媒体流发给sfu装置;
18.步骤四、sfu装置将mcu装置发来的混合媒体流转发给视频会议中的所有旁观用户终端,旁观用户终端接收、并播放sfu装置发来的混合媒体流。
19.与现有技术相比,本发明的有益效果是:本发明结合mcu和sfu两种流媒体拓扑结构,构建了一种高性能的新型流媒体拓扑结构,不仅减少了mcu模式下的进行混流的计算量,还减少了sfu模式下对带宽的大量消耗,同时满足了视频会议中“会上用户”(有媒体流分享,正在交流沟通的用户)对低延迟的需求,“旁观用户”(关闭麦克风和视频分享,正在旁
观的用户)对视频质量异构化的需求,即从计算量、带宽消耗、低延迟、以及视频质量可控等多个方面,对媒体拓扑结构进行了优化,尽可能节省带宽、降低延迟、减少计算量、满足不同用户的需求,尤其适用于人数众多的视频会议;由于网络的复杂多变和视频内容的多样性,启发式的方法通常不能应对所有复杂场景的组合和突发情况,本发明采用深度强化学习的方法,通过观察到的网络状态和过去的视频帧内容来选择未来的视频码率,相对于大多数码率自适应方法都只参考网络情况以提供高视频比特率为目的,本发明在作出决策时不仅考虑网络状态也考虑视频内容,从而以较低的发送速率来获得较高的视频质量,有效减少码率边际递减效应对带宽资源的浪费。
附图说明
20.图1是本发明一种视频会议中的流媒体分发系统的组成结构示意图。
21.图2是应用本发明的一个视频会议实施例的组成结构示意图。
22.图3是本发明一种视频会议中的流媒体分发方法的流程图。
具体实施方式
23.为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步的详细描述。
24.如图1所示,本发明一种视频会议中的流媒体分发系统,包括有流媒体服务器、业务服务器和多个用户终端,流媒体服务器上部署有mcu装置和sfu装置,当创建一个视频会议时,参加视频会议的用户包括有会上用户和旁观用户,正在分享视频的用户是会上用户,没有分享视频的用户是旁观用户,会上用户使用的用户终端简称为会上用户终端,旁观用户使用的用户终端简称为旁观用户终端,其中:
25.业务服务器,用于处理视频会议的业务信息;
26.sfu装置,用于将视频会议中每个会上用户终端发来的媒体流转发给其他所有会上用户终端和mcu装置,并将mcu装置发来的混合媒体流转发给视频会议中的所有旁观用户终端;
27.mcu装置,用于将sfu装置发来的所有媒体流进行编解码和混流处理,以合成一路混合媒体流,然后将合成后的混合媒体流发给sfu装置;
28.用户终端,当用户是会上用户时,采集自身的媒体流,并发送给sfu装置,然后将sfu装置转发来的其他所有会上用户终端的媒体流进行编解码和混流处理,以合成一路混合媒体流在本地播放;当用户是旁观用户时,接收、并播放sfu装置发来的混合媒体流。
29.在真实的音视频会议中,大部分人都是关闭麦克风和摄像头,只有少数正在发言和准备发言的人会打开麦克风和摄像头。也即是说,会上用户和旁观用户的需求也略有差异,会上用户之间会彼此进行沟通,所以对实时性要求更高,而旁观用户则对接收到的媒体质量要求更高。针对这两种用户的不同需求,本发明中sfu装置用于转发媒体流,对媒体流不进行处理,mcu装置用于处理媒体流,将多路媒体流融合成一路媒体流。用户终端与业务服务器之间建立websocket连接来进行通信,包括用户的登录注册、会议房间的业务管理等,都是通过websocket消息进行传递。用户终端和sfu装置之间建立rtp/rtcp连接来传输音频流和视频流。sfu装置和mcu装置之间也是建立rtp/rtcp连接来通信。业务服务器和sfu
装置、mcu装置之间是通过http来进行业务消息的传递。
30.在mcu装置和sfu装置、用户终端和sfu装置之间建立的rtp/rtcp连接中,可以使用两个相邻的端口分别用于监听rtp媒体流和rtcp控制信息流,例如:sfu装置用于监听用户终端的端口为:52304和52305两个端口,52304这个端口用于接收来自用户终端的rtp媒体流,52305这个端口用于接收来自用户终端的rtcp控制信息流,控制信息可以包括sfu装置和用户终端之间的网络情况,比如实时带宽、丢包率和延迟等信息。
31.图2示出了应用本发明的一个视频会议的实施例。如图2所示,本视频会议中的会上用户终端包括有c1-3,旁观用户终端包括有c4-6,c1、c2、c3将各自采集到的视频数据s1、s2、s3发送给sfu装置,sfu装置将视频数据s1、s2、s3转发给mcu装置进行混合,同时也将视频数据转发给其他会上用户终端,例如将s2、s3转发给c1,而mcu装置混合好的视频数据s123由sfu装置转发给所有旁观用户装置c4-6。这样,旁观用户终端收到的是由mcu装置混合好的全部会上用户的视频s123,而会上用户终端通过sfu装置接收所有其他的视频数据,并在本地混合,从而获得不含自己视频的其他会上用户的视频。在图2所示的六人(三名会上、三名旁观)视频会议场景下,相比纯sfu结构,本发明sfu装置的下行数据流从15路减少到9路,服务器的带宽减少了40%;相比纯mcu结构,本发明mcu装置进行混流的路数从4路减少到1路,减少了75%的计算量;会上用户直接获取不经处理的视频流,低时延得到了保证,同时利用mcu装置更容易控制各个旁观用户得到的混合视频流的质量。从计算量、带宽消耗、低延迟、以及视频质量可控几个方面,本发明的媒体拓扑结构都得到了优化。
32.本发明还可以根据负载均衡,同时部署多台流媒体服务器以实现分布式部署,并在每台流媒体服务器上均部署有相互配合的sfu装置和mcu装置,也即是说,sfu装置和mcu装置部署的节点数相同,在创建视频会议时,根据负载均衡分配完sfu装置节点,那么与之配合的mcu装置节点就确定了。
33.当视频会议中的所有用户都是会上用户时,由于此时没有旁观用户,可以采取纯sfu模式或者纯mcu模式:纯sfu模式下,mcu装置停止混流计算,所有用户终端得到的是其他所有会上用户的媒体流;纯mcu模式下,每个用户终端得到的都是一路不包含自己媒体流的混流,这就意味着mcu装置针对每个用户都要进行一次混流。本发明可以具备有模式自动调节机制,即根据当前sfu装置的带宽占用和mcu装置的计算量占用,自动进行纯sfu或mcu模式选择,模式选择对用户来说是无感的,但可以有效优化服务器的计算成本和带宽成本,并且提升用户的画面质量,减少延迟,这样,业务服务器进一步包括有:
34.模式控制装置,当检测到视频会议中的所有用户都是会上用户时,向sfu装置和mcu装置发送通知消息,然后根据sfu装置、mcu装置返回的平均带宽占用率b、平均cpu占用率c,计算模式调节参数:其中,n是当前视频会议的用户终端数,并据此通知sfu装置:当模式调节参数大于1时,则说明当前带宽消耗大,带宽资源紧缺,通知sfu装置采取mcu模式;当模式调节参数小于1时,则说明当前cpu计算消耗大,计算资源紧缺,通知sfu装置采取sfu模式,
35.sfu装置进一步包括有:
36.模式调节单元,根据业务服务器发来的通知消息,计算自身进程在一段时间内的
平均带宽占用率b,并返回给业务服务器,然后再根据业务服务器的通知消息,执行相应的模式:如果是mcu模式,则将收到的每路用户终端的媒体流都转发给mcu装置,然后将mcu装置发来的混合媒体流发送给视频会议中的所有用户终端;如果是sfu模式,则将收到的每路用户终端的媒体流转发给视频会议中的其他用户终端,
37.mcu装置,还根据业务服务器发来的通知消息,计算自身进程在一段时间内的平均cpu占用率c。
38.自适应码率是通过动态调整视频流的码率来自动适应网络的容量和性能的方法,为终端用户提供尽可能好的视频质量,这已经成为了向用户提供高质量视频的流行方案。目前主要的自适应码率的方法可以分为四类:基于客户端缓冲区的、基于网络吞吐量(网络速率)的、基于模型的和基于强化学习的,这些算法的策略都是在网络条件允许的时候选择尽可能高的码率,但是由于码率具有边际递减效应,即随着视频码率的提升,视频质量的增长率是减少的,并且编码技术的改进也不能解决这个问题。这种选择尽可能高码率的策略会造成网络资源和编码计算资源的浪费,而且忽视了视频内容特性对视频质量的影响。如果一个视频由黑暗的场景或者很少的对象组成,较低的码率也能提供令人满意的视频,同时可以节约带宽资源。基于上述因素,本发明还可以采用深度强化学习的方法来选择未来的码率,即通过观察到的网络状态和过去的视频帧内容来选择未来的视频码率,从而根据视频内容进行动态自适应码率调整,在提高视频质量的基础上,有效减少码率的边际递减效应带来的不必要的带宽的消耗。如果直接输入原始图片作为状态的输入,状态空间将导致“状态爆炸”,本发明为了克服这个技术问题,将强化学习模型分为两个可行且有用的模型:一个是基于深度学习的视频质量预测模型,另一个是基于强化学习的码率决策模型,第一个模型用于帮助第二个模型学习不同视频内容下视频码率和视频质量之间的关系。这样,用户终端或sfu装置中还可以进一步包含有:
39.视频质量预测模型构建单元,构建、并训练视频质量预测模型,所述视频质量预测模型用于根据每个时间段的视频帧来预测下一个时间段的平均视频质量,其输入是一个时间段内的若干视频帧,输出是预测得到的下一个时间段内不同码率分别对应的平均视频质量分数值,所述视频质量预测模型由提取图片空间特征的cnn(convolutional neural network)和提取时域特征的rnn(recurrent neural network)构成,cnn输出一个视频帧的时间序列数据,使用rnn的时间记忆特性可以有效预测未来的视频质量,对输入视频帧的处理流程如下:先将视频帧输入至cnn,以输出获得一个视频帧序列特征,然后再将cnn输出的视频帧序列特征继续输入至rnn,rnn的输出即是视频质量预测模型的输出值,其中,cnn包括有5层,依次为:一个包含64个5*5卷积核的卷积层和一个3
×
3的平均池化层,另一个包含64个3*3卷积核的卷积层和一个3
×
3的平均池化层,最后是一个2
×
2的最大池化层,rnn包括有2个具有64个隐藏单元的gru(gated recurrent unit)层,视频质量预测模型的输出是一个向量,可以预先设置300、500、800、1100、1400等多个不同码率,输出向量中的每个值分别表示每个码率预测得到的平均视频质量分数值;
40.码率决策模型构建单元,采用a3c算法,构建、并训练码率决策模型,所述码率决策模型用于根据每个时间段的状态(包括网络情况,视频内容和视频质量等)来挑选下一个时间段的码率,从而在不浪费资源的情况下提供最好的视频质量,其输入是一个时间段的状态空间:s
t
=(p
t-1
,v
t
,s
t-1
,d
t-1
,l
t-1
),输出是预测得到的下一个时间段内不同码率的选择概
率,其中,s
t
表示第t个时间段的状态空间,p
t-1
表示在第t个时间段之前的第t-1个时间段内发送视频的平均视频质量分数,v
t
表示在第t个时间段的平均视频质量分数预测值,s
t-1
表示第t-1个时间段内的视频流的发送码率,d
t-1
表示第t-1个时间段内发送方和接收方的延迟梯度,l
t-1
表示第t-1个时间段内的视频帧序列的丢包率,p
t-1
、v
t
的值可以是视频质量预测模型对于第t-1、t个时间段的预测结果,s
t-1
的值可以是码率决策模型对于第t-1个时间段的预测结果,d
t-1
、l
t-1
的值可以从发送方和接收方之间交互的rtcp控制信息中获取;
41.自适应码率单元,在自身所属装置向其他装置(即会上用户终端向sfu装置、或者sfu装置向每个旁观用户终端)发送媒体流时,通过训练好的视频质量预测模型和码率决策模型,为媒体流的发送方和接收方选择下一个时间段的码率:将自身所属装置(即会上用户终端或sfu装置)收到的每个时间段内的视频帧输入视频质量预测模型,获取并保存视频质量预测模型对应于每个时间段的输出结果,然后提取发送方和接收方在上一个时间段的rtcp控制信息、视频质量预测模型在上一个时间段和当前时间段的输出结果、码率决策模型在上一个时间段的输出结果,构建获得每个时间段的状态空间,将所构建的每个时间段的状态空间输入码率决策模型,从而获取码率决策模型对应于每个时间段的输出结果,并从中选取选择概率最大的码率,在下一时间段内以所选择的码率来向接收方发送媒体流。
42.如图3所示,本发明一种视频会议中的流媒体分发方法,包括有流媒体服务器、业务服务器和多个用户终端,流媒体服务器上部署有mcu装置和sfu装置,当创建一个视频会议时,参加视频会议的用户包括有会上用户和旁观用户,正在分享视频的用户是会上用户,没有分享视频的用户是旁观用户,会上用户使用的用户终端简称为会上用户终端,旁观用户使用的用户终端简称为旁观用户终端,还包括有:
43.步骤一、视频会议中每个会上用户终端分别采集自身的媒体流,并发送给sfu装置;
44.步骤二、sfu装置将每个会上用户终端发来的媒体流转发给视频会议中的其他所有会上用户终端和mcu装置;
45.步骤三、每个会上用户终端和mcu装置分别将sfu装置发来的所有媒体流进行编解码和混流处理,以合成一路混合媒体流,然后,每个会上用户终端将自身合成的混合媒体流在本地播放,mcu装置将合成后的混合媒体流发给sfu装置;
46.步骤四、sfu装置将mcu装置发来的混合媒体流转发给视频会议中的所有旁观用户终端,旁观用户终端接收、并播放sfu装置发来的混合媒体流。
47.本发明还可以根据负载均衡,同时部署多台流媒体服务器以实现分布式部署,并在每台流媒体服务器上均部署有相互配合的sfu装置和mcu装置,也即是说,sfu装置和mcu装置部署的节点数相同,在创建视频会议时,根据负载均衡分配完sfu装置节点,那么与之配合的mcu装置节点就确定了。
48.当视频会议中的所有用户都是会上用户时,由于此时没有旁观用户,可以采取纯sfu模式或者纯mcu模式:纯sfu模式下,mcu装置停止混流计算,所有用户终端得到的是其他所有会上用户的媒体流;纯mcu模式下,每个用户终端得到的都是一路不包含自己媒体流的混流,这就意味着mcu装置针对每个用户都要进行一次混流。本发明可以具备有模式自动调节机制,即根据当前sfu装置的带宽占用和mcu装置的计算量占用,自动进行纯sfu或mcu模式选择,模式选择对用户来说是无感的,但可以有效优化服务器的计算成本和带宽成本,并
且提升用户的画面质量,减少延迟,本发明还可以包括有:
49.步骤a1、业务服务器当检测到视频会议中的所有用户都是会上用户时,向sfu装置和mcu装置发送通知消息;
50.步骤a2、sfu装置、mcu装置分别计算自身进程在一段时间内的平均带宽占用率b、平均cpu占用率c,并返回给业务服务器;
51.步骤a3、业务服务器计算模式调节参数:其中,n是当前视频会议的用户终端数,并据此通知sfu装置:当模式调节参数大于1时,则说明当前带宽消耗大,带宽资源紧缺,通知sfu装置采取mcu模式;当模式调节参数小于1时,则说明当前cpu计算消耗大,计算资源紧缺,通知sfu装置采取sfu模式;
52.步骤a4、sfu装置根据业务服务器的通知消息,执行相应的模式:如果是mcu模式,则将收到的每路用户终端的媒体流都转发给mcu装置,然后将mcu装置发来的混合媒体流发送给视频会议中的所有用户终端;如果是sfu模式,则将收到的每路用户终端的媒体流转发给视频会议中的其他用户终端。
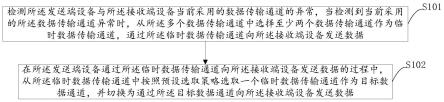
53.本发明还可以采用深度强化学习的方法来选择未来的码率,即通过观察到的网络状态和过去的视频帧内容来选择未来的视频码率,从而根据视频内容进行动态自适应码率调整,在提高视频质量的基础上,有效减少码率的边际递减效应带来的不必要的带宽的消耗。用户终端或sfu装置中还可以进一步包含有视频质量预测模型和码率决策模型,本发明还可以包括有:
54.步骤a、构建、并训练视频质量预测模型,所述视频质量预测模型用于根据当前时间段的视频帧来预测下一个时间段的平均视频质量,其输入是一个时间段内的若干视频帧,输出是预测得到的下一个时间段内不同码率分别对应的平均视频质量分数值,所述视频质量预测模型由提取图片空间特征的cnn和提取时域特征的rnn构成,cnn输出一个视频帧的时间序列数据,使用rnn的时间记忆特性可以有效预测未来的视频质量,对输入视频帧的处理流程如下:先将视频帧输入至cnn,以输出获得一个视频帧序列特征,然后再将cnn输出的视频帧序列特征继续输入至rnn,rnn的输出即是视频质量预测模型的输出值,其中,cnn包括有5层,依次为:一个包含64个5*5卷积核的卷积层和一个3
×
3的平均池化层,另一个包含64个3*3卷积核的卷积层和一个3
×
3的平均池化层,最后是一个2
×
2的最大池化层,rnn包括有2个具有64个隐藏单元的gru层,视频质量预测模型的输出是一个向量,可以预先设置300、500、800、1100、1400等多个不同码率,输出向量中的每个值分别表示每个码率预测得到的平均视频质量分数值;
55.步骤b、采用a3c算法,构建、并训练码率决策模型,所述码率决策模型用于根据每个时间段的状态来挑选下一个时间段的码率,从而在不浪费资源的情况下提供最好的视频质量,其输入是一个时间段的状态空间:s
t
=(p
t-1
,v
t
,s
t-1
,d
t-1
,l
t-1
),输出是预测得到的下一个时间段内不同码率的选择概率,其中,s
t
表示第t个时间段的状态空间,p
t-1
表示在第t个时间段之前的第t-1个时间段内发送视频的平均视频质量分数,v
t
表示在第t个时间段的平均视频质量分数预测值,s
t-1
表示第t-1个时间段内的视频流的发送码率,d
t-1
表示第t-1个时间段内发送方和接收方的延迟梯度,l
t-1
表示第t-1个时间段内的视频帧序列的丢包率,p
t-1
、v
t
的值可以是视频质量预测模型对于第t-1、t个时间段的预测结果,s
t-1
的值可以
是码率决策模型对于第t-1个时间段的预测结果,d
t-1
、l
t-1
的值可以从发送方和接收方之间交互的rtcp控制信息中获取,
56.这样,步骤一中,当会上用户终端将媒体流发送给sfu装置之前,或者,步骤四中,当sfu装置将混合媒体流发送给每个旁观用户终端之前,本发明还包括有:
57.通过训练好的视频质量预测模型和码率决策模型,为媒体流的发送方和接收方(即会上用户终端和sfu装置、或者sfu装置和每个旁观用户终端)选择下一个时间段的码率:将自身所属装置(即会上用户终端或sfu装置)收到的每个时间段内的视频帧输入视频质量预测模型,获取并保存视频质量预测模型对应于每个时间段的输出结果,然后提取发送方和接收方在上一个时间段的rtcp控制信息、视频质量预测模型在上一个时间段和当前时间段的输出结果、码率决策模型在上一个时间段的输出结果,构建获得每个时间段的状态空间,将所构建的每个时间段的状态空间输入码率决策模型,从而获取码率决策模型对应于每个时间段的输出结果,并从中选取选择概率最大的码率,在下一时间段内以所选择的码率来向接收方发送媒体流。
58.为了更清楚的解释本发明中的视频质量预测模型和码率决策模型的实现技术,下面将对这两个模型再进一步具体介绍:
59.(1)视频质量预测模型
60.为了帮助码率决策模型为下一帧选择合适的编码码率,需要首先让模型“知道”码率和相应视频质量之间的关系。然而,这种形式的预测是相当具有挑战性的,因为感知视频质量与视频本身密切相关。视频类型、亮度和运动程度都对码率和视频质量之间的相关性有很大影响。基于神经网络在预测时间序列数据方面的有效性,本发明设计了视频质量预测模型,可以帮助码率决策模型预测未来帧的感知视频质量。
61.在视频质量预测模型中,本发明采用视频多方法评估融合(video multimethod assessment fusion,vmaf)来作为视频质量的度量,这种方式将多种基本的质量指标结合在一起预测主观质量。使用平均视频质量来度量一段时间内视频的质量。对于视频在时间段t内第i帧视频质量记为v
fi,bitarate
,表示这个视频帧fi在这个码率的编码下的视频质量。利用v
fi,bitarate
的平均值,也就是v
t,bitarate
来表示时间段t内的平均视频质量,视频质量的度量采用了vmaf的标准,并进行归一化,视频质量评分都分布在[0,1]。
[0062]
本发明可以使用均方误差来表示损失函数:其中,θ是视频质量预测模型的神经网络参数,v
t
是第t个时间段模型输出的平均视频质量分数预测值,是第t个时间段实际的平均视频质量分数值,n是计算的时间段总数,γ是对损失函数的调节系数γ的值可以根据多次试验获得。此外,还考虑增加损失函数进行调节,以减少训练集过拟合的概率,其中λ是调节系数。
[0063]
(2)码率决策模型
[0064]
码率决策模型可以采用a3c(asynchronous advantage actor-critic)算法,相比actor-critic算法,a3c提出了异步训练框架,能够加速收敛。在强化学习的场景下,agent在某个状态s
t
下会采取相应的动作a
t
,然后就会得到相应的reward,目标就是选择一个动作能够最大化reward,策略网络会在这个方向下改变参数来达到这个目标。这里策略网络的
训练采用policy gradient的方法。其中:
[0065]
1)状态空间s
t
[0066]
发送方作为rl问题的agent,观察一组指标,包括未来的视频质量和以前的网络状态作为状态空间s
t
,然后,神经网络选择动作作为输出,表示下一个时段的视频码率。
[0067]
2)动作空间a
t
[0068]
agent在接收状态时会根据policy需要采取行动,一般来说动作空间是离散的,策略网络的输出是一个概率分布f(s
t
,a
t
),表示在状态s
t
时选择a
t
这个动作的概率,这里动作空间包含下一个时间段t中的候选的比特率信息。由于状态空间巨大,所以采用了神经网络来表示策略,而神经网络的权重称为策略参数θ。
[0069]
3)奖励函数reward
[0070]
目标是在尽可能小的比特率下获得较高的视频质量,所以qoe主要评估四个因素,视频质量,发送的比特率,丢失率,延迟梯度以及视频切换的平滑性。本发明相比原算法,重新设计了以下qoe:算中,v
t
、v
t-1
分别表示在第t、t-1个时间段视频质量预测模型输出的平均视频质量分数预测值,b
t
表示第t个时间段发送方选择的码率,d
t
表示第t个时间段接收方测量的延迟梯度,l
t
表示第t个时间段接收方的丢包率,t表示计算的时间段个数,|v
t-v
t-1
|表示视频质量的平滑,α、β、δ、γ表示衡量不同指标的权重。
[0071]
4)码率决策的网络模型
[0072]
actor网络的输出是一个具有softmax激活的5维向量,而critic网络的最终输出是一个没有激活函数的线性值,对actor网络的决策作出价值评估。两个网络使用了相同网络结构,都是通过三层神经网络提取状态特征,并利用全连接的方式进行多维特征向量融合处理。
[0073]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。