1.本发明涉及数控机床海量运行数据的实时监测领域,具体涉及一种基于spark流处理的轴承剩余寿命预测方法。
背景技术:
2.数控机床是高端制造业的一个基本资源,减少故障时间,增加机床的使用效率,为企业创造了更多的经济效益,是一个紧迫的问题。滚动轴承由滚动体、保持架、轴承内圈和轴承外圈组成。数控机床系统产生的运行数据正逐渐出现高容量、高速度、多样性和低值的“4v”大数据特性。故障具有隐蔽性及复杂性的特点,如何从大量历史数据中提取关键信息并预测设备的运行状况,对于设备的预先维修和正常运行至关重要。郭兴利用基于广泛数据的存储和管理技术、数据检索和分析技术,收集机床运行期间产生的大量数据,并对历史数据进行在线存储和分析。彭博对工业能耗大数据分析平台进行研究,对能耗数据进行离线分析,实现了能耗与设备综合信息的聚类与影响分析。
3.目前主流的大数据流处理框架有storm、spark streaming和flink。spark streaming在实时性方面不如strom。然而spark streaming的集成性更好,通过rdd不仅可以和spark进行衔接,也可以很容易的与kafka结合。同时spark streaming的吞吐量也远远高于strom。spark streaming可以支持秒级计算,它属于微小批次处理框架,flink属于准实时处理框架,它支持毫秒级计算,然而本文对轴承剩余寿命的预测精度为分钟量级,所以都可以满足条件,同时spark对sql的支持比flink要多一些,而且支持对sql的优化。鉴于以上研究,选择spark streaming作为流处理框架。
技术实现要素:
4.针对机床运行数据的特殊性,传统的离线数据处理框架难以满足实时流处理和动态弹性计算等需求。本发明从对多台数控机床实时监控入手,引入了kafka消息缓存机制来实现多台数控机床的同时监控,引入了spark streaming来提高数据处理效率,同时通过相似度最高的思路对轴承剩余寿命进行预测。可以对多个轴承当前剩余使用寿命做出实时预测。
5.本发明为实现上述目的所采用的技术方案是:
6.一种基于spark流处理的轴承剩余使用寿命预测方法,包括以下步骤:
7.通过振动传感器实时采集多个轴承的运行时数据,并将该数据储存在作为消息中间件的kafka中;
8.spark streaming对历史数据中轴承的运行时数据进行计算,得到参考值并以设定形式进行存储;
9.spark streaming接收来自kafka的运行时数据并进行计算,将计算结果与参考值进行比较,得到预测结果,即轴承剩余使用寿命;
10.将预测结果储存并展示。
11.所述轴承的运行时数据为轴承运行时的水平加速度和垂直加速度。
12.对运行时数据进行计算具体为:计算水平加速度和垂直加速度的平方和的平均值。
13.所述设定的形式为:map《该时间段内加速度平方和的平均值,时间》。
14.所述将计算结果与参考值进行比较,得到预测的轴承剩余使用寿命具体为:将计算结果即水平加速度和垂直加速度的平方和的平均值与map的键进行比较,选择出与该平均值之差的绝对值最小的键,得到该键对应的值,即为预测的剩余使用寿命。
15.所述将预测结果储存并展示具体为:将预测结果写入到mysql数据库中存储并通过web页面的方式对预测结果进行展示。
16.一种基于spark流处理的轴承剩余使用寿命预测装置,包括:
17.振动传感器,用于实时采集多个轴承的运行时数据,并将该数据储存在作为消息中间件的kafka中;
18.kafka:用于储存轴承的运行时数据并转发给spark streaming;
19.spark streaming:用于对历史数据中轴承的运行时数据进行计算,得到参考值并以设定形式进行存储以及接收来自kafka的运行时数据并进行计算,将计算结果与参考值进行比较,得到预测结果,即轴承剩余使用寿命;
20.数据存储展示模块,用于将预测结果写入到mysql数据库中存储并通过web页面的方式对预测结果进行展示。
21.本发明具有以下有益效果及优点:
22.1.适用于对多台数控机床的轴承同时进行剩余使用寿命的预测。
23.2.适用于数据量比较大,并且预测的精确度可以达到分钟级别,即每分钟都会对数据进行分析处理,更新剩余寿命的预测值。
24.3.基于相似度的预测可以达到较好的预测效果,提高剩余寿命预测的准确度。
附图说明
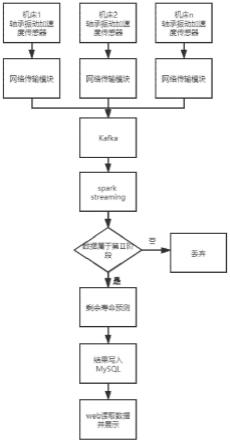
25.图1为总体流程图;
26.图2为窗口时间间隔示意图;
27.图3为振动加速度变化趋势图;
28.图4为第ⅱ阶段振动加速度变化趋势图;
29.图5为平滑处理后振动加速度变化趋势图;
30.图6为预测效果图。
具体实施方式
31.下面结合附图及实施例对本发明做进一步的详细说明。
32.一种基于spark流处理的轴承剩余寿命预测方法,包括以下步骤:
33.s1:通过传感器等组件采集数控机床关键部件的运行数据;
34.s2:通过消息缓存机制来对数据进行缓存,解决速度传输差异;
35.s3:通过spark streaming微批次处理框架对采集到的数据进行批次处理,做到分钟级别的预测精度;
36.s4:剩余使用寿命数据的存储和可视化。
37.在步骤1中:
38.在轴承上安装加速度传感器,同时采集轴承的水平加速度和垂直加速度等数据,并将数据通过网络传输模块发送到服务器接收端。
39.在步骤2中:
40.spark streaming结合kafka分布式日志收集框架进行数据缓存。由于多台数控机床设备同时运行会产生大量数据,如果不使用消息缓存机制,容易造成数据过时或数据丢失等问题,使用kafka消息缓存框架可以以生产者消费者模式对数据进行缓存,解决速度差异问题。同时kafka作为分布式的框架,更加适合于同时对多台数控机床设备进行数据采集的任务。
41.所述步骤3包括:
42.步骤3.1:spark streaming对于数据的接收是实时的,但是对于数据的处理是分批次进行的。将批处理时间间隔设置为1分钟,设置窗口时间间隔为5分钟。在系统启动的前5分钟内,进入窗口的rdd数量不足5个,但是会随着时间的推移,满足条件。将滑动时间间隔设置为1分钟。
43.步骤3.2:对数据进行平滑处理。首先获取接收到数据的总条数n,利用小顶堆存放总条数n*0.1个最小数据集之和summin,利用大顶堆存放总条数n*0.1个的最大数据集之和summax。同时记录全部数据的总和sum。利用如下公式得到去毛刺的效果:
44.avg=(sum-summax-summin)/(0.8*n)
45.同时将数据的时间粒度进行扩大,通过多组数据的对比,发现将时间粒度设置为5分钟比较合适。
46.步骤3.3:对样本数据进行过滤,并计算每隔5分钟内数据的平均值,利用线程安全的map键值对的形式对模型进行保存。最终通过样本得到的预测工具就是“map《该时间段内加速度平方和的平均值,时间》”的形式。
47.步骤3.4:对于要预测数据,系统每隔1分钟都会计算出一个最近5分钟内数据的平均值,并且会将该平均值与map的键进行比较,会选择出与该平均值之差的绝对值最小的键,然后可以得到该键对应的值,也就是剩余使用寿命的时间。
48.在步骤4中:
49.可视化组件主要通过web端实现,web程序通过访问存储了剩余使用寿命的mysql数据库来获取相应的数据,随后将数据进行显示。
50.如图1所示,为本发明的总体流程,主要包括以下过程:
51.1:通过振动加速度传感器收集轴承的运行时数据,并通过网络传输模块将数据发送出去;
52.2:利用kafka作为消息中间件,对多台机床发送来的数据进行缓存;
53.3:计算水平加速度和垂直加速度的平方和的平均值,并以“map《该时间段内加速度平方和的平均值,时间》”形式存储。
54.4:spark streaming接收来自kafka的数据,计算每台机床的加速度平均值,将该平均值与map的键进行比较,选择出与该平均值之差的绝对值最小的键,得到该键对应的值,即为预测的剩余使用寿命。
55.5:将预测结果写入到mysql数据库中存储。
56.6:通过web页面的方式对结果进行展示。
57.如图2所示,为本发明的窗口时间间隔示意图,可以看到窗口内rdd的数量为5,也就是每次对5个rdd的数据进行处理分析。考虑到服务器的性能以及每次处理完成的时间不到1分钟,所以将批处理时间间隔设置为1分钟,考虑到轴承的加速度数据在5分钟为时间间隔的时候较为平稳,所以设置窗口时间间隔为5分钟。在系统启动的前5分钟内,进入窗口的rdd数量不足5个,但是会随着时间的推移,满足条件。
58.滑动时间间隔代表了数据分析的频率。滑动时间间隔是基于批处理时间间隔提出的。对应图中两个蓝色透明框之间的时间间隔,这里将滑动时间间隔设置为1分钟,即每隔1分钟,对数据进行一次处理分析。
59.如图3所示,为本发明的加速度随时间变化趋势图。可以发现,能够将数据整体分为三部分(由黑色粗线进行划分),在第ⅰ阶段,数据呈现平稳状态,几乎没有变化,此阶段称为平稳期;在第ⅱ阶段,加速度的平方和呈现缓慢的上升状态,但是变化的幅度没有太大,此阶段称为退化期;在第ⅲ部分,加速度的平方和呈现快速上升的状态,意味着轴承迅速损坏,此阶段称为失效期。
60.如图4所示,为本发明的第ⅱ阶段加速度随时间变化趋势图。从图中可以发现轴承振动加速度存在很多的毛刺,所以对数据进行平滑处理。
61.如图5所示,为本发明的第ⅱ阶段进行平滑处理后的加速度变化趋势图。首先获取接收到数据的总条数n,利用小顶堆存放总条数n*0.1个最小数据集之和summin,利用大顶堆存放总条数n*0.1个的最大数据集之和summax。同时记录全部数据的总和sum。利用如下公式得到去毛刺的效果:
62.avg=(sum-summax-summin)/(0.8*n)
63.同时将数据的时间粒度进行扩大,通过多组数据的对比,发现将时间粒度设置为5分钟比较合适。
64.如图6所示,为本发明的预测效果图,蓝色为预测数据,红色为实际数据,按照轴承实际已使用时间和预测已使用时间之差是否大于5分钟为基准,小于等于5分钟则认为预测正确。得到的预测准确度为0.8606。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
