1.本发明涉及智能交通领域;尤其涉及一种大数据驱动的高速公路交通事件持续时间预测方法。
背景技术:
2.高速公路交通事件是指对交通安全、道路运行状态、通行能力、行程时间等有影响以及交通运行管理部门关注的事件。随着智能交通监控系统日益完善,人身和财产的安全得到必要保障,但是由交通事件引发的拥堵和延误日趋常态化。交通事件仍然是高速公路交通拥堵的主要原因,其造成的时间延误成为行业内和社会公众的关注焦点。合理预测高速公路交通事件持续时间,可以实现路网的诱导分流控制,避免巨大的行车时间损失,为公众出行提供决策依据和可靠的道路服务。对于这些事件,倘若不能够及时的进行处理,很可能引发二次交通事故,这就意味着交通事件严重程度的加剧,进一步也延长了交通事件持续时间。因此,对高速公路交通事件持续时间预测这一任务变得格外关键。
3.目前,交通事件持续时间研究侧重于交通事故、车辆抛锚、自然灾害等事件的持续时间预测,但是临时性养护施工、特殊车辆通行、货物掉落、道路损毁等交通事件也时有发生,同样也会造成较长时间的交通拥堵。面对这类交通事件,现有持续时间预测模型的适应性略有不足。同时,交通事件信息在不同运营管理单位和不同业务处置角色之间的流转,包含有自然语言的文本数据描述。相较于结构化的属性特征,文本数据包含的信息具有一定的丰富性和多元性,因此可以从中获取更多对交通事件持续时间研究有帮助的信息,融合交通事件文本信息对预测模型的建立具有积极意义。
技术实现要素:
4.本发明的目的是提供了一种精确可靠的基于大数据技术和文本挖掘的高速公路交通事件持续时间预测方法。本发明在海量、多源的高速公路交通事件数据集的基础上,将结构化数据挖掘与文本分析相结合,以对道路通行能力有影响的交通事件为研究对象,建立高速公路交通事件持续时间预测模型,以避免巨大的行车时间损失,为公众出行提供决策依据和可靠的道路服务。
5.本发明是通过以下技术方案实现的:
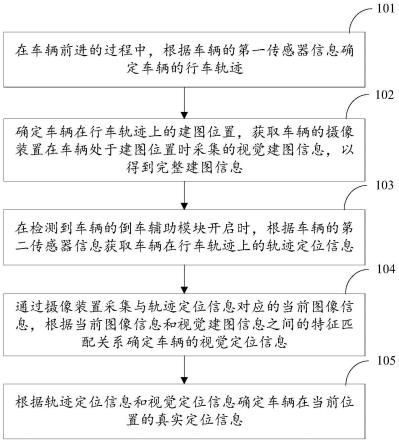
6.本发明涉及一种大数据驱动的高速公路交通事件持续时间预测方法,包括如下步骤:
7.步骤1,建立高速公路交通事件数据集,提取研究所需的字段;
8.步骤2,对提取的数据字段进行预处理,包括对结构化数据的预处理和文本数据的预处理;
9.步骤3,在数据预处理的基础上,采用交通事故、车辆故障、道路遗洒物、天气状况、伤亡人数、发生位置、报警类型属性建立随机森林模型,对高速公路交通事件持续时间进行预测;
10.步骤4,在数据预处理的基础上,采用交通事故、车辆故障、道路遗洒物、天气状况、伤亡人数、发生位置、报警类型属性,结合事件文本信息的特征向量,建立基于随机森林的交通事件持续时间预测模型;
11.步骤5,采用平均绝对误差(mae)、平均相对误差(mape)两项评价指标对2种预测模型精度进行对比分析;通过对比结果,可知基于文本挖掘和随机森林算法的高速公路交通事件持续时间预测模型具有较优的性能指标,并在实际数据中表现出更好的适用性。
12.优选地,步骤1中的具体步骤为:将高速公路交通事件数据中的结构化数据与文本数据相结合,形成高速公路交通事件大数据,并从中提取研究所需要的字段。
13.(1)从结构化数据中,提取所需要的字段包括:事件编号、方向、报警人员、报警时间、伤亡人数、车辆损坏数量、影响范围、天气状况、事件处理完成时间等。
14.(2)从文本数据中,提取的字段包括:事件发生时间、事件发生的具体路段、碰撞事故具体情况(单车撞护栏、两车或者多车相撞等)、是否起火、涉及车辆类型(面包车、半挂车等)、占用车道情况(1车道、2车道、3车道)、道路通行能力(拥堵程度)、道路遗洒物、临时性养护施工、特殊车辆通行、交通流量大、处置措施、处置效果、处置部门、响应进度等字段等。
15.优选地,步骤2中,所述预处理的四个主要任务:数据清洗、数据集成、数据变换和数据规约;该步骤结合研究目标,设计数据库表结构及其字段,以保证海量样本条件下数据查询和分析的效率。数据挖掘需要的数据通常来源不全相同,数据集成是指将多个不同的数据源合并存放于同一个数据存储中的操作。数据变换指结合挖掘任务或挖掘算法的需要,将数据转换成特定的、规范化的形式。可以根据已有的属性集构造出新的属性。通常,对完整的大数据集进行数据挖掘必然耗费很长时间或者进行复杂的分析计算。数据规约是指在保障数据完整性的前提下产生更小的新的数据集。
16.步骤2中,所述结构化数据的预处理具体为:
17.(1)数据清洗就是将原始数据集中的重复数据、噪声数据等与研究目标无关的数据进行筛选和删除。剔除异常数据,包括缺失数据、错误数据等。异常数据主要包含:缺少交通事件报警时间或者事件处理完成时间、异常时间数据记录、异常位置数据记录。
18.(2)根据高速公路交通事件发生后,数据记录中的报警时间和交通事件处理完成时间两个字段,构造新的字段,计算高速公路交通事件持续时间,表达式(5)如下所示:
19.t
duration
=t
processdone-t
alarm
ꢀꢀꢀ
(5)
20.式(1)中,t
duration
交通事件持续时间,t
processdone
为交通事件处理完成时间,t
alarm
为报警时间。
21.(3)计算交通事件持续时间样本数据的上下四分位数,以上下两个分位值为有效数据区间的上限和下限,超出该范围的数据被认为是噪声数据。表达式(6)、(7)如下所示:
22.t
limit-down
=t
25%-1.5
×
(t
75%-t
25%
)
ꢀꢀꢀ
(6)
23.t
limit-up
=t
25%
1.5
×
(t
75%-t
25%
)
ꢀꢀꢀ
(7)
24.式(6)中,t
limit-down
为有效数据区间g的下限;式(7)中t
limit-up
为有效数据区间g的上限;t
25%
和t
75%
分别表示样本数据的25%和75%分位数。
25.(4)对研究字段中的类型数据,如天气状况、交通事故类型、天气状况、涉及车辆类型等字段进行数字编码,便于后续计算。
26.步骤2中,所述文本数据的预处理具体为:
27.对文本数据进行分词处理,需保证文本的主要信息。文本中存在大量感叹词、语气词、虚词等一些对研究无意义的词,因此,需要进行去停用词处理,从而大大降低文本中冗余特征数量,避免无用特征对后续模型构建的干扰,处理过程如下:
28.对于一个含有n个文本的集合d={d1,d1,
…
,dn},以及在所有文本中出现的m个单词的集合w={w1,w2,
…
,wm}。将单词在文本中出现的数据用一个单词-文本矩阵表示,记作x,如下:
[0029][0030]
这是一个m
×
n矩阵,元素x
ij
表示单词wi在文本dj中出现的权值,权值通常用单词频率-逆文本频率(tf-idf)表示,其表达式(8)如下所示:
[0031][0032]
式中tf
ij
是单词wi出现在文本dj中的频数,tf
.j
是文本dj中出现的所有单词的频数之和,dfi是含有单词wi的文本数,df是文本集合d的全部文本数。
[0033]
所述步骤3的具体分析过程为:
[0034]
(1)在步骤2的基础上,从结构化数据中,进行s次随机抽样,每次随机抽取(有放回抽样)m个特征和n个数据样本组成特征向量空间cs和数据集ds(其中,s=1,2,3,
…
),构建s棵决策树,构建决策树所采用的算法为c4.5,其用信息增益比来选择特征,其信息增益比表达式(9)如下所示:
[0035][0036]
式(5)中,a代表某个特征,d代表数据集。
[0037]
其中
[0038]
n表示根据特征a将数据集d划分为子集的个数,分别为d1,d2,
…dn
,i=1,2,3
…
,n,θ(d,a)为特征a对训练数据集的信息增益。
[0039]
(2)对决策树进行剪枝处理
[0040]
为了防止在构建决策树之后,出现过拟合的现象,即队训数据集有很强的预测效果,但对测试数据集的预测效果却大大降低。对每棵决策树进行剪枝处理,具体步骤如下:
[0041]
决策树的剪枝往往通过极小化决策树整体的损失函数来实现,设树t的叶结点个数为|t|,t是树t的叶结点,该叶结点有n
t
个样本点,其中k类的样本点有n
tk
个,k=1,2,
…
,k,h
t
(t)为叶节点t上的经验熵,α≥0为参数,则决策树学习的损失函数可以定义为
[0042][0043]
其中,经验熵为
[0044]
[0045]
将式(2)代入式(1),并将最终表达式中右端第一项记作
[0046][0047]
综合以上,可得
[0048]cα
(t)=c(t) α|t|
………
(4)
[0049]
式(3)中,c(t)表示模型对训练集的预测误差,|t|表示模型的复杂度;式(4)中参数α≥0控制两者之间的影响。
[0050]
对剪枝前后的决策树进行,运用上述式(4),分别计算两棵树的预测误差,若满足以下条件:
[0051]cα
(t
后
)≤c
α
(t
前
)
[0052]
则进行剪枝,即将父节点变为新的叶节点。
[0053]
(3)构建随机森林模型
[0054]
在上述所生成的决策树的基础上,构建随机森林模型,构建规则为:
[0055]
需要运用每一棵决策树对实时的交通事件持续时间进行预测,最后以“少数服从多数”的原则,确定为最终的交通事件持续时间预测值。
[0056]
所述步骤4的具体分析过程为:
[0057]
将结构化数据处理的结果和对文本进行数据挖掘的结果相结合,构成新的交通事件数据集,采用数据集中的特征量和样本,构建基于随机森林的文本数据特征预测模型,其构建过程与步骤3中预测模型构建相似,不同的是二者采用的数据集有所差异,主要体现在特征数量上的不同。
[0058]
所述步骤5的具体分析过程为:
[0059]
平均绝对误差e
mae
和平均相对误差e
mape
计算公式如下所示。
[0060][0061][0062]
式中,n为样本数量,t
p
(i)表示第i个样本的预测值,ta(i)表示第i个样本的实际值。
[0063]
采用平均绝对误差(mae)、平均相对误差(mape)评价指标对两种预测模型精度进行对比分析。实验结果显示:基于随机森林和文本挖掘的预测模型相较于单纯的随机森林预测模型,其平均绝对误差和平均相对误差有明显降低。基于随机森林和文本挖掘的高速公路交通事件预测模型不仅预测精度高,而且对不同类型的交通事件,该预测模型在适应能力方面也呈现出一定的优势。
[0064]
现有持续时间预测模型注重关注追尾、相撞、等突发性交通事故,数据来源主要为公安部门或者交警部门的统计数据。然而,交通事件仍然是高速公路交通拥堵的主要原因,道路遗洒物、临时性养护施工、特殊车辆通行、交通流量大导致通行缓慢等偶发性交通事件的持续时间尚未被充分讨论。现有研究的数据源大多数为事故类型、涉及车辆类型、伤亡人数、受影响的车道数目、事故地点、天气状况、时段等结构化属性数据。在高速公路交通事件
记录中同时包含自然语言描述的文本信息,对事件的基础信息、响应措施、实施效果等进行描述。
[0065]
交通事件持续时间与多种因素相关,如时间特征、事件特征、道路特性、交通特征和天气状况等。现有技术通过结构化数据分析致因机理,提取显著性影响因素来对交通事件持续时间进行预测。
[0066]
本发明具有以下优点:
[0067]
(1)本发明在海量、多源的高速公路交通事件数据集的基础上,将结构化数据挖掘与文本分析相结合,以对道路通行能力有影响的交通事件为对象,建立高速公路交通事件持续时间预测模型,以避免巨大的行车时间损失,为公众出行提供决策依据和可靠的道路服务;所涉及的预测模型不仅能够对突发性交通事故、自然灾害进行持续时间预测,而且能够对道路遗洒物、临时性养护施工、特殊车辆通行、交通流量大导致通行缓慢等典型偶发性交通事件进行预测。
[0068]
(2)本发明不仅考虑显著性影响因素,而且将数据集中半结构化数据纳入预测方法,对交通事件信息报送的自然语言描述进行文本分析,丰富交通事件的特征向量维度,以实现更准确的持续时间预测;本发明将交通事件文本信息纳入研究范畴,运用自然语言的文本分析提取特征向量。本发明融合文本挖掘和数据驱动算法建立高速公路交通事件持续时间预测模型,以实现预测模型准确性和适应性的提升。
附图说明
[0069]
图1是本发明方法计算过程流程图。
具体实施方式
[0070]
下面结合具体实施例对本发明进行详细说明。应当指出的是,以下的实施实例只是对本发明的进一步说明,但本发明的保护范围并不限于以下实施例。
[0071]
实施例
[0072]
本实施例涉及一种大数据驱动的高速公路交通事件持续时间预测方法,见图1所示,包括如下步骤:
[0073]
步骤1,建立高速公路交通事件数据集,提取研究所需的字段;
[0074]
步骤2,对提取的数据字段进行预处理,包括对结构化数据的预处理和文本数据的预处理;
[0075]
步骤3,在数据预处理的基础上,采用交通事故、车辆故障、道路遗洒物、天气状况、伤亡人数、发生位置、报警类型属性建立随机森林模型,对高速公路交通事件持续时间进行预测;
[0076]
步骤4,在数据预处理的基础上,采用交通事故、车辆故障、道路遗洒物、天气状况、伤亡人数、发生位置、报警类型属性,结合事件文本信息的特征向量,建立基于随机森林的交通事件持续时间预测模型;
[0077]
步骤5,采用平均绝对误差(mae)、平均相对误差(mape)两项评价指标对2种预测模型精度进行对比分析;通过对比结果,可知基于文本挖掘和随机森林算法的高速公路交通事件持续时间预测模型具有较优的性能指标,并在实际数据中表现出更好的适用性。
[0078]
步骤1中的具体步骤为:将高速公路交通事件数据中的结构化数据与文本数据相结合,形成高速公路交通事件大数据,并从中提取研究所需要的字段。
[0079]
(1)从结构化数据中,提取所需要的字段包括事件编号、方向、报警人员、报警时间、伤亡人数、车辆损坏数量、影响范围、天气状况、事件处理完成时间等。
[0080]
(2)从文本数据中,提取的字段包括事件发生时间、事件发生的具体路段、碰撞事故具体情况(单车撞护栏、两车或者多车相撞等)、是否起火、涉及车辆类型(面包车、半挂车等)、占用车道情况(1车道、2车道、3车道)、道路通行能力(拥堵程度)、道路遗洒物、临时性养护施工、特殊车辆通行、交通流量大、处置措施、处置效果、处置部门、响应进度等字段等。
[0081]
步骤2中,所述预处理的四个主要任务:数据清洗、数据集成、数据变换和数据规约;该步骤结合研究目标,设计数据库表结构及其字段,以保证海量样本条件下数据查询和分析的效率。数据挖掘需要的数据通常来源不全相同,数据集成是指将多个不同的数据源合并存放于同一个数据存储中的操作。数据变换指结合挖掘任务或挖掘算法的需要,将数据转换成特定的、规范化的形式。可以根据已有的属性集构造出新的属性。通常,对完整的大数据集进行数据挖掘必然耗费很长时间或者进行复杂的分析计算。数据规约是指在保障数据完整性的前提下产生更小的新的数据集。
[0082]
所述结构化数据的预处理具体为:
[0083]
(1)数据清洗就是将原始数据集中的重复数据、噪声数据等与研究目标无关的数据进行筛选和删除。剔除异常数据,包括缺失数据、错误数据等。异常数据主要包含:缺少交通事件报警时间或者事件处理完成时间、异常时间数据记录、异常位置数据记录。
[0084]
(2)根据高速公路交通事件发生后,数据记录中的报警时间和交通事件处理完成时间两个字段,构造新的字段,计算高速公路交通事件持续时间,表达式(5)如下所示:
[0085]
t
duration
=t
processdone-t
alarm
ꢀꢀꢀ
(5)
[0086]
式(1)中,t
duration
交通事件持续时间,t
processdone
为交通事件处理完成时间,t
alarm
为报警时间。
[0087]
(3)计算交通事件持续时间样本数据的上下四分位数,以上下两个分位值为有效数据区间的上限和下限,超出该范围的数据被认为是噪声数据。表达式(6)、(7)如下所示:
[0088]
t
limit-down
=t
25%-1.5
×
(t
75%-t
25%
)
ꢀꢀꢀ
(6)
[0089]
t
limit-up
=t
25%
1.5
×
(t
75%-t
25%
)
ꢀꢀꢀ
(7)
[0090]
式(6)中,t
limit-down
为有效数据区间g的下限;式(7)中t
limit-up
为有效数据区间g的上限;t
25%
和t
75%
分别表示样本数据的25%和75%分位数。
[0091]
(4)对研究字段中的类型数据,如天气状况、交通事故类型、天气状况、涉及车辆类型等字段进行数字编码,便于后续计算。
[0092]
所述文本数据的预处理具体为:
[0093]
对文本数据进行分词处理,需保证文本的主要信息。文本中存在大量感叹词、语气词、虚词等一些对研究无意义的词,因此,需要进行去停用词处理,从而大大降低文本中冗余特征数量,避免无用特征对后续模型构建的干扰,处理过程如下:
[0094]
对于一个含有n个文本的集合d={d1,d1,
…
,dn},以及在所有文本中出现的m个单词的集合w={w1,w2,
…
,wm}。将单词在文本中出现的数据用一个单词-文本矩阵表示,记作x,如下:
[0095][0096]
这是一个m
×
n矩阵,元素x
ij
表示单词wi在文本dj中出现的权值,权值通常用单词频率-逆文本频率(tf-idf)表示,其表达式(8)如下所示:
[0097][0098]
式中tf
ij
是单词wi出现在文本dj中的频数,tf
.j
是文本dj中出现的所有单词的频数之和,dfi是含有单词wi的文本数,df是文本集合d的全部文本数。
[0099]
所述步骤3的具体分析过程为:
[0100]
(1)在步骤2的基础上,从结构化数据中,进行s次随机抽样,每次随机抽取(有放回抽样)m个特征和n个数据样本组成特征向量空间cs和数据集ds(其中,s=1,2,3,
…
),构建s棵决策树,构建决策树所采用的算法为c4.5,其用信息增益比来选择特征,其信息增益比表达式(9)如下所示:
[0101][0102]
式(5)中,a代表某个特征,d代表数据集。
[0103]
其中
[0104]
n表示根据特征a将数据集d划分为子集的个数,分别为d1,d2,
…dn
,i=1,2,3
…
,n,θ(d,a)为特征a对训练数据集的信息增益。
[0105]
(2)对决策树进行剪枝处理
[0106]
为了防止在构建决策树之后,出现过拟合的现象,即队训数据集有很强的预测效果,但对测试数据集的预测效果却大大降低。对每棵决策树进行剪枝处理,具体步骤如下:
[0107]
决策树的剪枝往往通过极小化决策树整体的损失函数来实现,设树t的叶结点个数为|t|,t是树t的叶结点,该叶结点有n
t
个样本点,其中k类的样本点有n
tk
个,k=1,2,
…
,k,h
t
(t)为叶节点t上的经验熵,α≥0为参数,则决策树学习的损失函数可以定义为
[0108][0109]
其中,经验熵为
[0110][0111]
将式(2)代入式(1),并将最终表达式中右端第一项记作
[0112][0113]
综合以上,可得
[0114]cα
(t)=c(t) α|t|
………
(4)
[0115]
式(3)中,c(t)表示模型对训练集的预测误差,|t|表示模型的复杂度;式(4)中参数α≥0控制两者之间的影响。
[0116]
对剪枝前后的决策树进行,运用上述式(4),分别计算两棵树的预测误差,若满足以下条件:
[0117]cα
(t
后
)≤c
α
(t
前
)
[0118]
则进行剪枝,即将父节点变为新的叶节点。
[0119]
(3)构建随机森林模型
[0120]
在上述所生成的决策树的基础上,构建随机森林模型,构建规则为:
[0121]
需要运用每一棵决策树对实时的交通事件持续时间进行预测,最后以“少数服从多数”的原则,确定为最终的交通事件持续时间预测值。
[0122]
所述步骤4的具体分析过程为:
[0123]
将结构化数据处理的结果和对文本进行数据挖掘的结果相结合,构成新的交通事件数据集,采用数据集中的特征量和样本,构建基于随机森林的文本数据特征预测模型,其构建过程与步骤3中预测模型构建相似,不同的是二者采用的数据集有所差异,主要体现在特征数量上的不同。
[0124]
所述步骤5的具体分析过程为:
[0125]
平均绝对误差e
mae
和平均相对误差e
mape
计算公式如下所示。
[0126][0127][0128]
式中,n为样本数量,t
p
(i)表示第i个样本的预测值,ta(i)表示第i个样本的实际值。
[0129]
采用平均绝对误差(mae)、平均相对误差(mape)评价指标对两种预测模型精度进行对比分析。实验结果显示:基于随机森林和文本挖掘的预测模型相较于单纯的随机森林预测模型,其平均绝对误差和平均相对误差有明显降低。基于随机森林和文本挖掘的高速公路交通事件预测模型不仅预测精度高,而且对不同类型的交通事件,该预测模型在适应能力方面也呈现出一定的优势。
[0130]
本发明在以往交通事件持续时间研究的基础上,结合文本数据挖掘,融合结构化的属性特征和半结构化的文本数据,形成新的交通事件数据集。在此基础上,构建了一种基于大数据技术和文本挖掘的高速公路交通事件持续时间预测模型,以实现预测模型准确性和适应性的提升。对于交通管理者而言,能够根据预测时间合理进行应急指挥调度;对于道路使用者而言,能够根据预测时间合理的安排行程规划。总而言之,可以更好的提高道路交通的使用效率。
[0131]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。