1.本发明实施例涉及人工智能领域,涉及一种多智能体学习方法、装置及设备。
背景技术:
2.多智能体学习是强化学习领域中一个热门研究方向。多智能体学习是指,在同一个环境中通过具有交互关系的多个智能体之间相互协作或对抗博弈,使每个智能体学习应对其它智能体动作的决策,以提高同一阵营所在智能体群体的对战胜率。
3.通常,在面对复杂学习环境时,例如在具有多个智能体的学习环境中,同一阵营方智能体之间存在协作关系,并且与对立阵营智能体具有对抗关系。通过对整体学习环境所处的学习网络设置多个输出控制单元控制每个智能体的学习内容,进而实现每个智能体在复杂学习环境下的有效学习。但是,在实际应用中,此方法随着智能体数量规模的增加,每个智能体的动作空间以及决策空间的设计难度增大,降低了智能体的学习效率。
技术实现要素:
4.本技术实施例提供了一种多智能体学习方法、装置及设备,以解决复杂环境中多智能体学习随着智能体数量增加,每个智能体的动作空间以及决策空间的设计难度增大,智能体学习效率降低的问题。
5.第一方面,本技术实施例提供了一种多智能体学习方法,所述方法包括:
6.部署至少两个执行网络,每个执行网络对应一个智能体,所述执行网络用于为相应智能体提供动作执行环境;
7.针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体,所述目标第一等级动作是预设决策动作库中与所述智能体当前的状态特征相匹配的第一等级动作,得到所述智能体当前的状态特征对应的动作结果;
8.调用所述执行网络使所述每个动作结果对应的智能体依据所述动作结果进行交互训练,以及检测交互训练的次数是否等于第一预设阈值;
9.当各个智能体的所述交互训练次数等于第一预设阈值时,基于每次交互训练产生的训练结果对全部所述智能体进行训练;
10.当所述交互训练次数小于第一预设阈值时,重复执行针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体的步骤。
11.在一些可能的实施方式中,
12.针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体得到所述智能体当前的状态特征对应的动作结果包括:
13.读取所述相应智能体当前的状态特征;
14.根据所述当前的状态特征从所述决策动作库中获得与所述当前的状态特征相匹配的至少一个目标第一等级动作;
15.调用相应智能体执行所述至少一个目标第一等级动作,使得所述智能体输出第一等级动作或第二等级动作,所述第一等级动作是所述至少一个目标第一等级动作中与所述智能体的当前状态特征相匹配的目标第一等级动作,所述第二等级动作由至少一个第一等级动作组合或衍化得到。
16.在一些可能的实施方式中,所述多智能体学习方法还包括:
17.建立集中训练网络,所述集中训练网络用于调用全部所述智能体基于所有所述训练结果进行训练。
18.在一些可能的实施方式中,
19.所述通过训练相应智能体,使得所述智能体根据所述至少一个目标第一等级动作输出第二等级动作,包括:
20.基于所述智能体当前状态特征,调用所述至少一个目标所对应的决策动作库中的至少两个第一等级动作按照预设顺序组合得到准第二等级动作;
21.执行网络基于所述智能体当前状态特征对所述智能体进行动作训练,获得所执行至少一个第一等级动作中每个第一等级动作对准第二等级动作的可行性影响,准第二等级动作的可执行性参数,以及第一等级动作的可执行性参数;
22.获取所述第一等级动作的可执行性参数以及第二等级动作的可执行性参数,
23.若可执行性参数的最大值对应所述第一等级动作的可执行性参数,则输出第一等级动作;
24.若所述第一等级和/或所述第二等级动作可执行性参数小于第二预设阈值,则获取影响所述可执行性参数的所述第一等级动作,并对相应的所述第一等级动作进行删除或替换,以获得大于预设阈值的所述准第二等级动作。
25.在一些可能的实施方式中,
26.所述智能体当前的状态特征包括:自身特征和当前环境特征,
27.所述自身特征包括以下至少一种:所述智能体当前对应的健康性参数、所述智能体当前距离目标的相对位置信息和相对距离信息以及所述智能体身份信息;
28.环境特征包括以下至少一种:移动方向特征、所述智能体所在阵营的对立阵营智能体的属性特征、所述智能体所在阵营的每个智能体的属性特征、除自身之外所有智能体的身份特征、交互训练次数特征以及目标归属特征;
29.所述移动方向特征包括以下至少一种:东、西、南以及北;
30.所述智能体所在阵营的对立阵营智能体的属性特征包括以下至少一种:当前被攻击的可能性参数、当前被探测的可能性参数、当前距离每个所述智能体的相对位置信息和相对距离信息;
31.所述智能体所在阵营的每个智能体的属性特征包括以下至少一种:当前的健康性参数、每个所述智能体所在阵营的智能体之间的当前相对位置信息和相对距离信息、除自身之外的每个所述智能体所在阵营稍微智能体当前距离目标的相对位置信息和相对距离信息以及除自身之外的每个所在阵营智能体的前一周期的动作结果;
32.所述每个所述智能体的身份特征包括:所述智能体的身份标识,每个所述智能体
对应一个身份标识,所有所述智能体身份标识两两不同。
33.第二方面,本技术实施例还提供了一种多智能体学习装置,所述装置包括:
34.部署模块,用于部署至少两个执行网络,每个执行网络对应一个所述智能体,所述执行网络用于为相应智能体提供动作执行环境;
35.执行网络训练模块,用于针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体,所述目标第一等级动作是预设决策动作库中与所述智能体当前的状态特征相匹配的第一等级动作,得到所述智能体当前的状态特征对应的动作结果;
36.交互训练模块,用于调用所述执行网络使所述每个动作结果对应的智能体依据所述动作结果进行交互训练;检测交互训练的次数是否等于第一预设阈值
37.比对模块,用于检测交互训练的次数是否等于第一预设阈值,
38.当各个智能体的所述交互训练次数等于第一预设阈值时,基于每次交互训练产生的训练结果对全部所述智能体进行训练;
39.当所述交互训练次数小于预设阈值时,重复执行针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体的步骤。
40.第三方面,本技术实施例还提供了一种电子设备,所诉电子设备包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
41.所述存储器用于存储有可执行指令,所述可执行指令运行时使所述处理器执行第一方面或者第二方面任一可能的实施方式中的多智能体学习方法。
42.第四方面,本技术实施例还提供了一种计算机可读存储介质,所述存储介质中存储有可执行指令,所述可执行指令运行时使计算设备执行第一方面或者第二方面任一可能的实施方式中的多智能体学习方法。
43.本技术实施例提供了一种策略模型训练方法,本方案中,通过部署分布执行网络,在每个执行网络中,基于智能体当前的状态特征进行动作训练,输出智能体当前状态下的动作结果,将所有动作结果对应的智能体进行交互训练,进而得到训练结果,最后通过集中训练网络对训练结果进行收集,为所有智能体提供集中训练环境,使所有智能体进行集中训练。这样在多智能体学习过程中,通过分布执行网络使每个智能体训练环境相对独立,并且随着智能体数量增加,只需对分布执行网络进行扩展,智能体动作空间不会变的复杂,因此降低了每个智能体动作空间以及决策空间的涉及难度,进而提升了智能体的学习效率。
附图说明
44.图1是本技术实施例提供的多智能体学习方法流程示意图;
45.图2是本技术实施例提供的多智能体学习方法结构示意图;
46.图3是本技术实施例提供的多智能体学习方法中交互训练示意图;
47.图4是本技术实施例提供的策略模型训练方法装置示意图;
48.图5是本技术实施例提供的策略模型训练电子设备示意图。
具体实施方式
49.本技术以下实施例中所使用的术语是为了描述可选实施方式的目的,而非旨在作为对本技术的限制。如在本技术的说明书和所附权利要求书中所使用的那样,单数表达形式“一个”、“一种”、“所述”、“上述”、“该”和“这一”旨在也包括复数表达形式。还应当理解,尽管在以下实施例中可能采用术语第一、第二等来描述某一类对象,但所述对象不限于这些术语。这些术语用来将该类对象的具体对象进行区分。例如,以下实施例中可能采用术语第一、第二等来描述的其他类对象同理,此处不再赘述。
50.本技术实施例提供了一种策略模型训练方法,基于对博弈学习中具有对战关系的双方智能体的所用策略同预设阈值的比对结果,选择大于预设阈值的策略输入至与各方智能体对应的策略种群中,并提高此策略后续被对应的策略模型选取的可能性参数。这样不仅可以将己方智能体得到进化策略训练,同时也可以使对战方智能体得到进化策略训练,提升了博弈学习网络中策略模型的进化程度上限,使策略模型对策略多样的博弈场景适应性更强。
51.本技术实施例提供的策略模型训练方法可以由一个电子设备执行,也可以由计算机集群执行。该计算机集群包括至少两个支持本技术实施例的策略模型训练方法的电子设备,任一电子设备可通过策略模型训练方法实现本技术实施例所描述的策略模型训练功能。
52.本技术实施例设计的任一电子设备可以是诸如手机、平板电脑、可穿戴设备(例如,智能手表、只能手环等)、笔记本电脑、台式计算机和车载设备等电子设备。该电子设备预先安装有策略模型训练应用程序。可以理解的是,本技术实施例对电子设备的具体类型不作任何限制。
53.通常的,多智能体学习是指在同一个环境中由多个可交互的智能体构建的学习场景,通过多个智能体之间相互协作或对抗博弈,使每个智能体学习应对其它智能体动作的决策,以在智能体之间的对抗提高同一阵营所在智能体群体的对战胜率。
54.通常,在面对复杂学习环境时,例如在具有多个智能体的学习环境中,同一阵营方智能体之间存在协作关系,并且与对立阵营智能体具有对抗关系。通过对整体学习环境所处的学习网络设置多个输出控制单元控制每个智能体的学习内容,进而实现每个智能体在复杂学习环境下的有效学习。但是,在实际应用中,此方法随着智能体数量规模的增加,每个智能体的动作空间以及决策空间的设计难度增大,降低了智能体的学习效率。
55.下面是对几个示例性实施方式的描述,对本技术实施例的技术方案以及本技术的技术方案产生的技术效果进行说明。
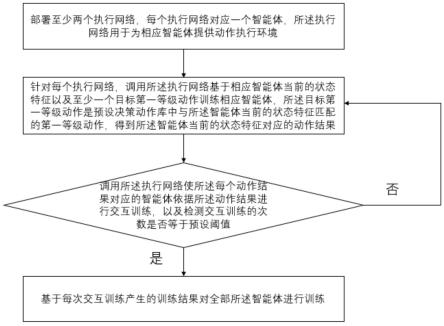
56.参见图1,图1是本技术实施例提供的多智能体学习方法流程示意图,包括以下步骤:
57.部署至少两个执行网络,每个执行网络对应一个智能体,所述执行网络用于为相应智能体提供动作执行环境;
58.针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体,所述目标第一等级动作是预设决策动作库中与所述智能体当前的状态特征相匹配的第一等级动作,得到所述智能体当前的状态特征对应的动作结果;
59.调用所述执行网络使所述每个动作结果对应的智能体依据所述动作结果进行交互训练,以及检测交互训练的次数是否等于第一预设阈值;
60.当各个智能体的所述交互训练次数等于第一预设阈值时,基于每次交互训练产生的训练结果对全部所述智能体进行训练;
61.当所述交互训练次数小于第一预设阈值时,重复执行针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体的步骤。
62.示例性的,如图2所示,所述学习方法中至少包括两个分布执行网络,所述分布执行网络,每个所述分布执行网络对应一个智能体(例如智能体1,智能体2
……
智能体n),这里的智能体可以对应相同类别的智能体,也可对应不同类别的智能体(例如智能体1~智能体5属于仅作移动型智能体,智能体6~智能体10属于可做攻击动作型智能体);
63.可选的,以其中一个执行网络为例:所述执行网络调用当前智能体状态特征进行强化学习训练,此部分需要预先对智能体进行状态特征设计、决策动作设计以及奖励设计,以保证所述执行网络基于当前所述智能体状态特征执行有效的动作决策;
64.其中智能体的所述状态特征设计,包括:自身特征以及当前环境特征;
65.所述自身特征包括以下至少一种:所述智能体当前对应的健康性参数(例如在游戏场景下,智能体对应的血量)、所述智能体当前距离目标的相对位置信息和相对距离信息(包括水平面的方向和距离信息以及竖直面的方向和距离信息)以及所述智能体身份信息(例如智能体的身份id等其它身份辨别信息),
66.所述自身特征还包括:智能体自身执行的历史动作;
67.环境特征包括以下至少一种:移动方向特征、所述智能体所在阵营的对立阵营智能体的属性特征、所述智能体所在阵营的每个智能体的属性特征、除自身之外所有智能体的身份特征、交互训练次数特征以及目标归属特征;
68.所述移动方向特征包括以下至少一种:东、西、南以及北(或者其它方向表示,例如上、下、左以及右);
69.所述智能体所在阵营的对立阵营智能体的属性特征包括以下至少一种:当前被攻击的可能性参数(即对方智能体是否可以被攻击,若一定可以被攻击则可能性参数为预设最大值,若一定不能被攻击则可能性参数为预设最小值)、当前被探测的可能性参数(即对方智能体是否可以被探测,若一定可以被探测发现,则可能性参数为预设最大值,若一定不能被探测发现,则可能性参数为预设最小值)、当前距离每个所述智能体的相对位置信息和相对距离信息(包括水平面的方向和距离信息以及竖直面的方向和距离信息);
70.所述智能体所在阵营的每个智能体的属性特征包括以下至少一种:当前的健康性参数(例如游戏场景下智能体对应的血量)、每个所述智能体所在阵营的智能体之间的当前相对位置信息和相对距离信息(包括水平面的方向和距离信息以及竖直面的方向和距离信息)、除自身之外的每个所述智能体所在阵营稍微智能体当前距离目标的相对位置信息和相对距离信息(包括水平面的方向和距离信息以及竖直面的方向和距离信息)以及除自身之外的每个所在阵营智能体的前一周期的历史动作结果;
71.所述每个所述智能体的身份特征包括:所述智能体的身份标识(例如智能体的身份id等其它身份辨别信息),每个所述智能体对应一个身份标识,所有所述智能体身份标识
两两不同;
72.示例性的,可以将上述的智能体状态特征选取部分进行组合,并输入至所述执行网络,例如,在1号执行网络中存在智能体1,所述智能体1所处在游戏场景中,当前的状态特征包括:自身血量80%,东南方向100码处探测到敌对智能体2,所述敌对智能体2血量20%,并且所述智能体2可以被攻击等。
73.可选的,其中所述智能体的决策动作设计中,设计的动作内容包括智能体在当前应用场景下可能发生的全部离散的基础动作(即所述第一等级动作),并将其存入所述决策动作库中,智能体实际训练产生的动作结果可以为第一动作或者为第二动作。
74.例如:智能体在游戏场景下可能出现的全部动作为:驾驶汽车,向东奔跑(或其它有目标方向性奔跑)以及射击(驾驶汽车,向东奔跑以及射击即所述准第二等级动作),
75.执行网络基于所述智能体当前状态特征对所述智能体进行动作训练,获得所执行至少一个第一等级动作中每个第一等级动作对准第二等级动作的可行性影响(每个第一等级动作对即将输出的第二等级动作的影响程度,例如抬腿和摆臂分别对向东奔跑的影响程度),准第二等级动作的可执行性参数(例如被执行的概率),以及第一等级动作的可执行性参数(例如被执行的概率),
76.那么对于所述智能体在该游戏场景下,对于构成“驾驶汽车”的离散动作构成包括:上车、下车、启动、停车以及驾驶;
77.构成“向东奔跑”的离散动作构成包括:朝向目标方向(此处为朝向东方)、奔跑、抬腿以及摆臂;
78.构成“射击”的离散动作构成包括:持枪、瞄准以及扣动扳机。
79.可选的,所述智能体在上述游戏场景下训练时,若可执行性参数的最大值对应所述第二等级动作的可执行性参数,则所述可执行性参数中的最大值对应的准第二等级动作作为所述第二等级动作输出,例如可以根据自身当前的状态特征(此处依据场景的可执行性,例如是否有汽车,是否汽车具备驾驶能力,驾驶员是否具备驾驶能力等这些相当于第二预设阈值),当所述可执行性参数大于等于所述第二预设阈值时,经由所述执行网络训练后输出“驾驶汽车”的准第二等级动作升级为第二等级动作。
80.可选的,所述智能体在上述游戏场景下训练时,若可执行性参数的最大值对应所述第一等级动作的可执行性参数,则输出第一等级动作,例如:若执行“奔跑”动作时,距离目标点过远,则持续执行向目标点方向奔跑的离散型动作(即第一等级动作),例如:持续向东方奔跑。
81.可选的,所述智能体在上述游戏场景下训练时,若所述第一等级和/或所述第二等级动作可执行性参数小于第二预设阈值,则获取影响所述可执行性参数的所述第一等级动作,并对相应的所述第一等级动作进删除或替换,以获得大于预设阈值的所述准第二等级动作,可以根据所述自身当前状态特征,进行无效动作的剔除,例如:所述智能体若执行“射击”动作,若已经完成持枪动作(即所述智能体保持持枪状态下),则所述智能体的“射击”动作将剔除“持枪”动作,直接进行瞄准以及射击。
82.可选的,所述剔除动作可以在进行所述第一等级动作可执行性参数以及所述第二等级动作可执行性参数获取比较过程中进行,例如选取数值最高的可行性参数对应的动作作为输出结果。
83.可选的,所述智能体在上述游戏场景下训练时,可以根据述自身当前状态特征,进行所述第一等级的动作衍化得到新的第二等级动作,例如:所述智能体在奔跑的过程中,若需要提高奔跑速度,可以调整抬腿以及摆臂的动作实现加速奔跑(即新的第二等级动作)。
84.这样,一方面可以保证智能体在对应场景下的动作空间尽可能完整,避免在实际运行做成中出现“状态盲区”,无法执行相应的动作。另一方面,将原本的连续动作化整为零,在满足基本控制精度的前提下,可以显著压缩动作空间维度,提高探索效率。
85.可选的,其中所述智能体的奖励设计中,通过将任务目标具体化以及数值化,实现所述目标与算法的连接,所述奖励射击内容包括以下至少一种:所有智能体的健康性参数变化(即游戏场景下的血量变化,计算公式为:当前血量-上一学习周期的血量)、智能体自身的死亡惩罚(即游戏场景下,当前学习周期所述智能体血量为0给予负值奖励)、对手阵营的智能体死亡奖励(即游戏场景下,当前学习周期所述对手阵营智能体死亡,给予正值奖励)、评判分数(即游戏场景下,环境返回的原始奖励值)以及胜利奖赏(即游戏场景下,最后一个学习周期时所述智能体所在阵营获胜,给予更大正值奖励)。这样,可以使所述智能体会朝向指定(本场景下是使己方智能体所在阵营胜利为目标)的训练方向学习。
86.可选的,对于所述分布执行网络中所述其中一个执行网络,所诉和状态特征设计、所述决策动作设计以及所述奖励设计完成后,进行网络设计,此处采用策略-评价网络架构(actor-critic)网络;
87.可选的,actor网络以及critic网络均采用3层全连接层结构,actor网络的输出为决策该控件上每个动作被实际选取的概率,critic网络输出为当前态势下的价值,通过概率和价值的综合比价,选取智能体更适合当前状态特征的动作,例如:智能体在东方100码以及西方100码处均有要获取的目标,使智能体在朝向东方移动以及西方移动的概率各为50%,但是当探测到所在地为东方的目标奖励分数更大时,判定所述智能体朝向东方移动更有价值,因此,所述智能体的输出动作为朝向东方目标所在地移动。
88.可选的,对于actor-critic网络中的策略优化算法,采用近端策略优化算法(ppo,proximal policy optimization)实现,具体包括:
89.初始化actor的相关网络参数π
θ
以及critic的相关网络参数v
θ
;
90.建立循环对抗局数(即建立对抗循环周期),具体包括:
91.每个智能体在对应的所述执行网络中进行动作执行,选取每个智能体当前状态的动作a
t
=π
θ
(a|s
t
),其中π
θ
(a|s
t
)表示actor网络的输出,按照概率分布选取动作,其中s
t
为环境返回的状态特征,
92.将每个智能体与环境交互生成轨迹数据(s
t
,a
t
,r
t
,s
t 1
)存入buffer模块,其中,r
t
表示t时刻环境返回的奖励。。。,s
t 1
表示t 1时刻的智能体状态。。。,
93.依据轨迹数据记录每一步(即每一周期)中的优势估计a
t
;
94.当上述建立循环对抗局数过程持续k次后(k为预设次数),从buffer模块中随机采样小批量数据(特定场景也可以为全部数据)输入至集中训练网络;
95.所述集中训练网络求解累计期望汇报函数的策略梯度,并用策略梯度更新网络相关参数,具体累积期望回报的目标函数为:
96.l
t
(θ)=min(r
t
(θ)ar,clip(r
t
(θ),1-∈,1 ∈)a
t
)
97.因此,此处更新的相关参数为θ,
98.γ
t
(θ)具体可以表示为:
[0099][0100]
其中a
t
为优势估计函数,γ
t
(θ)表示为新策略和就策略的权重,min操作时取两者中较小的值,也就是γ
t
(θ)a和clip(γ
t
(θ),1-ε,1 ε)a中的较小值。ε是一个固定较小的超参数,取值范围通常为0《ε《1,clip是数据剪裁操作,通过clip处理将γ
t
(θ)约束在1-ε与1 ε之间。
[0101]
可选的,此处的网络结构可以根据实际应用场景进行修改,
[0102]
例如可以换的网络包括:卷积网络、长短期记忆网络、变换网络等。
[0103]
可选的,在获取所有的所述执行网络输出的所述动作结果后,将每个所述动作结果对应的智能体依据所述动作结果进行交互训练,训练场景如图3所示,第一阵营与第二阵营互为对立阵营,每个阵营所拥有的智能体种类以及数量不同,并且所处环境存在差异,例如在游戏场景下,a类智能体代表驾驶员,b类智能体代表机枪手,c类智能体代表观察员,d类智能体代表卫生员,环境信息1代表该处拥有树林环境,环境信息2代表该处拥有河流环境,目标1以及目标2为双方想要抢占的据点。这样,可以将对应所述执行动作结果的所有智能实际环境中进行训练,以准确更新动作的有效性以及及时性。
[0104]
可选的,每次交互训练完成后,记录交互训练的次数,当所述交互训练的次数总值等于次数的预设阈值时(即第一预设阈值),将交互训练的轨迹数据统一录入集中训练网络,
[0105]
所述轨迹数据包括在交互训练过程中所有智能体的所述状态特征,以及环境回馈,
[0106]
所述集中训练网络主要模块包括:actor、learner、environment以及buffer;
[0107]
所述集中训练网络至少包括1个所述actor模块,每个所述actor模块与每个所述执行网络的智能体对应,所述actor模块用于根据每个对应的智能体的所述动作结果以及所述智能体与环境的交互状态进行当前每个智能体的所述状态特征以及环境反馈数据进行采集。所述多个actor模块可以并行运行;
[0108]
所述learner模块用于依据奖励结果执行优化算法,根据所述actor模块生成的数据信息进行智能体训练,更新相关参数;
[0109]
所述buffer模块用作存储所述actor模块采集的相关数据,并且将所有数据输出至learner模块用作智能体的强化学习;
[0110]
所述environment模块用于提供智能体所述交互训练环境。
[0111]
一种可能的实施方式中,所述多智能体学习方法中对于智能体的强化学习训练过程可以引入训练技巧,用于提升训练效率和训练效果,所述训练技巧至少包括以下一种:归一化、全局信息共享、稳定训练以及动作有效性;
[0112]
所述归一化具体表现为特征和奖励归一化,用于简化计算过程;
[0113]
所述全局信息共享具体表现为在训练时向所述执行网络加入全局可见信息(即只有第三方观众可以获取的的区别于场景内智能体所拥有的信息,例如游戏场景下隐藏在地形内的智能体信息)以减小方差,提高训练精准度;
[0114]
所述稳定训练具体表现为可以加入popart(preserving outputs precisely,
while adaptively rescaling targets)方式进行归一化处理,在自适应重新缩放目标的同时精确保留原有输出,让不同游戏的奖励尺度互相适应起来,使智能体学习更加稳定;
[0115]
所述动作有效性具体表现为采用action mask(动作约束)进行无效动作剔除(例如上述实施例提及,智能体已经持枪状态下执行射击,则无需再次执行持枪动作),并且采用death mask(死亡约束)对已判定死亡的智能体进行剔除。
[0116]
一种可能的实施方式中,所述多智能体学习方法还可以用于基于对手的集成强化学习,具体包括:
[0117]
根据己方智能体的网络结构设计,初始化所述己方智能体的actor网络以及critic网络;
[0118]
基于预设的对手智能体的策略库随机获取一个对手策略;
[0119]
所述己方智能体以及对方智能体分别处于第一执行网络以及第二执行网络;
[0120]
初始化训练环境,分别获取所述己方智能体以及所述对手智能体的初始状态特征;
[0121]
所述第一执行网络基于所述己方智能体的所述状态特征输出第一动作结果,所述第二执行网络基于所述对手智能体的所述状态特征输出第二动作结果,并将双方所述动作结果作用于环境中,所述环境返回下一时刻的状态;
[0122]
所述己方智能体、所述对方智能体分别于环境进行交互训练,并输出轨迹数据至buffer模块;
[0123]
待交互训练次数达到预设次数是,所述buffer模块输出轨迹数据至所述己方智能体,用作优化训练,并更新己方智能体相关参数。
[0124]
本技术实施例提供了一种策略模型训练方法,本方案中,通过部署分布执行网络,在每个执行网络中,基于智能体当前的状态特征进行动作训练,输出智能体当前状态下的动作结果,将所有动作结果对应的智能体进行交互训练,进而得到训练结果,最后通过集中训练网络对训练结果进行收集,为所有智能体提供集中训练环境,使所有智能体进行集中训练。这样在多智能体学习过程中,通过分布执行网络使每个智能体训练环境相对独立,并且随着智能体数量增加,只需对分布执行网络进行扩展,智能体动作空间不会变的复杂,因此降低了每个智能体动作空间以及决策空间的涉及难度,进而提升了智能体的学习效率。
[0125]
上述实施例从部署分布执行网络,智能体与执行网络之间的对应关系建立,智能体状态特征、动作决策特征以及奖励设计,智能体动作结果数据获取以及集中训练网络根据动作结果进行交互训练产生的结果对智能体进行集中训练等电子设备所执行的动作逻辑和学习算法处理角度,对本技术实施例提供的策略模型的训练方法的各实施方式进行了介绍。应理解,对应部署分布执行网络,智能体与执行网络之间的对应关系建立,智能体状态特征、动作决策特征以及奖励设计,智能体动作结果数据获取等的处理步骤,本技术实施例可以以硬件或硬件和计算机软件的结合形式来实现上述功能。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0126]
例如,若上述实现步骤通过软件模块来实现相应的功能,如图4所示,策略模型训练装置可以包括:部署模块、执行网络训练模块、交互训练模块以及比对模块
[0127]
所述部署模块,用于部署至少两个执行网络,每个执行网络对应一个所述智能体,所述执行网络用于为相应智能体提供动作执行环境;
[0128]
所述执行网络训练模块,用于针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体,所述目标第一等级动作是预设决策动作库中与所述智能体当前的状态特征相匹配的第一等级动作,得到所述智能体当前的状态特征对应的动作结果;
[0129]
所述交互训练模块:用于调用所述执行网络使所述每个动作结果对应的智能体依据所述动作结果进行交互训练;检测交互训练的次数是否等于第一预设阈值;
[0130]
所述比对模块:
[0131]
用于检测交互训练的次数是否等于第一预设阈值,
[0132]
当各个智能体的所述交互训练次数等于第一预设阈值时,基于每次交互训练产生的训练结果对全部所述智能体进行训练;
[0133]
当所述交互训练次数小于第一预设阈值时,重复执行针对所述至少两个执行网络中的每个执行网络,调用所述执行网络基于相应智能体当前的状态特征以及至少一个目标第一等级动作训练相应智能体的步骤。
[0134]
可以理解的是,以上各个模块/单元的划分仅仅是一种逻辑功能的划分,实际实现时,以上各模块的功能可以集成到硬件实体实现,例如,部署模块、执行网络训练模块、交互训练模块以及比对模块可以集成到处理器实现,,实现上述各模块功能的程序和指令,可以维护在存储器中。例如,图5提供了一种电子设备,该电子设备包括可以包括处理器、收发器和存储器。其中,收发器智能体训练产生的动作结果获取。存储器可以用于存储智能体学习训练产生的轨迹数据,也可以存储用于处理器执行的代码等。当处理器运行存储器存储的代码过程中,使得电子设备执行上述方法中策略模型训练方法的部分或全部操作。
[0135]
具体实现过程详见上述方法示意的实施例所述,此处不再详述。
[0136]
具体实现中,对应前述电子设备,本技术实施例还提供一种计算机存储介质,其中,设置在电子设备中的计算机存储介质可存储有程序,该程序执行时,可实施包括多智能体学习方法的各实施例中的部分或全部步骤。该存储介质均可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random access memory,ram)等。
[0137]
以上模块或单元的一个或多个可以软件、硬件或二者结合来实现。当以上任一模块或单元以软件实现的时候,所述软件以计算机程序指令的方式存在,并被存储在存储器中,处理器可以用于执行所述程序指令并实现以上方法流程。所述处理器可以包括但不限于以下至少一种:中央处理单元(central processing unit,cpu)、微处理器、数字信号处理器(dsp)、微控制器(microcontroller unit,mcu)、或人工智能处理器等各类运行软件的计算设备,每种计算设备可包括一个或多个用于执行软件指令以进行运算或处理的核。该处理器可以内置于soc(片上系统)或专用集成电路(application specific integrated circuit,asic),也可是一个独立的半导体芯片。该处理器内处理用于执行软件指令以进行运算或处理的核外,还可进一步包括必要的硬件加速器,如现场可编程门阵列(field programmable gate array,fpga)、pld(可编程逻辑器件)、或者实现专用逻辑运算的逻辑电路。
[0138]
当以上模块或单元以硬件实现的时候,该硬件可以是cpu、微处理器、dsp、mcu、人
工智能处理器、asic、soc、fpga、pld、专用数字电路、硬件加速器或非集成的分立器件中的任一个或任一组合,其可以运行必要的软件或不依赖于软件以执行以上方法流程。
[0139]
进一步的,图5中还可以包括总线接口,总线接口可以包括任意数量的互联的总线和桥,具体由处理器代表的一个或多个处理器和存储器代表的存储器的各种电路链接在一起。总线接口还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路链接在一起,这些都是本领域所公知的,因此,本文不再对其进行进一步描述。总线接口提供接口。收发器提供用于在传输介质上与各种其他设备通信的单元。处理器负责管理总线架构和通常的处理,存储器可以存储处理器在执行操作时所使用的数据。
[0140]
当以上模块或单元使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solid state disk(ssd))等。
[0141]
应理解,在本技术的各种实施例中,各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对实施例的实施过程构成任何限定。
[0142]
本说明书的各个部分均采用递进的方式进行描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点介绍的都是与其他实施例不同之处。尤其,对于装置和系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例部分的说明即可。
[0143]
尽管已描述了本技术的可选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本技术范围的所有变更和修改。
[0144]
以上所述的具体实施方式,对本技术的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本技术的具体实施方式而已,并不用于限定本技术的保护范围,凡在本技术的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。