1.本发明涉及强化学习的优化方法,具体涉及一种基于人类知识优化强化学习的方法及系统。
背景技术:
2.深度强化学习在许多问题上都取得了令人瞩目的成绩,例如机器人和游戏。近年来,多智能体强化学习(marl)在各种任务中取得了显著的进展。但是在多个智能体的环境中学习从根本上来说依然是困难的,因为代理不仅与环境交互,而且彼此之间也交互。随着智能体数量的增加,策略空间急剧扩大,多智能体同时学习使得环境非平稳,给每个智能体找到收敛策略带来了很大的困难。
3.尽管基于ddpg的多智能体深度强化学习算法(maddpg)提出了多智能体强化学习中最常用集中训练-分布执行(ctde)的范式,但是其可扩展性和可支持的智能体数量受到网络规模的限制。由于集中训练需要综合其他智能体的信息,当智能体数量增加时,网络规模呈线性增长,策略梯度的方差将以指数增长。因此,maddpg、qmix、maac等使用ctde框架的多智能体强化学习算法,在智能体规模很大时往往难以收敛,智能体规模巨大的情况依然是多智能体强化学习(multi agent reinforcement learning,marl)的重要挑战。
技术实现要素:
4.为了解决现有技术中所存在的问题,本发明提供一种基于人类知识优化强化学习的方法,包括:
5.基于人类领域知识,从智能体要执行的任务中提取多个知识节点,并构建多个行动节点;基于所述多个知识节点、多个行动节点以及多种训练过程确定多个方案;
6.从所述多个方案和基于预先构建的强化学习算法所确定的各输出动作中进行选择,确定所述智能体所执行的动作;并利用所述智能体所述执行的动作对所述强化学习算法进行训练;
7.其中,每个行动节点对应一个动作。
8.优选的,所述基于所述知识节点、行动节点以及多种训练过程确定多个方案,包括:
9.步骤1、从所述多个知识节点中分别确定若干输入的知识节点,从所述多个行动节点中确定若干备选的行动节点;
10.步骤2、基于所述执行的任务所确定的状态s,采用超网络结构经过mlp生成权重和偏置项;
11.步骤3、将所述确定输入的知识节点与所述权重和偏置项相结合并经过激活函数处理后,从所述备选的行动节点中确定概率最大的行动节点;以所述行动节点对应的动作作为输出;基于所述输入和输出得到方案;
12.步骤4、重复执行步骤1,直到得到满足数量的多个方案后,停止执行;
13.其中,每次重复执行步骤1时,至少满足下述一种条件:不同的若干输入的知识节点、不同的若干备选的行动节点和超网络结构。
14.优选的,利用下式将将所述确定输入的知识节点与所述权重和偏置项相结合:
15.hypernet
out
=relu((wi*ini(s)) bi)
16.式中,ini为第i个知识节点,s为状态,relu为不同的mlp算法,wi为第i个知识节点对应的权重,bi为第i个知识节点对应的偏置项。
17.优选的,所述从智能体要执行的任务中提取多个知识节点,包括:
18.从智能体要执行的所有任务所对应的原始的状态空间和动作空间中,利用人类领域知识确定特征信息;
19.基于所述特征信息构建知识节点。
20.优选的,所述构建多个行动节点,包括:
21.基于人类领域知识,从所述原始动作空间中剔除非法和无效的动作后,得到多个行动节点。
22.优选的,所述基于预先构建的强化学习算法所确定的各输出动作,包括:
23.基于智能体要执行的任务,利用演员-评论家架构的强化学习方法使用随机策略得到各动作及各动作的概率;
24.其中,所述演员-评论家架构的强化学习方法包括:执行器和评价器。
25.优选的,所述从所述多个方案和基于预先构建的强化学习算法所确定的各输出动作中进行选择,确定所述智能体所执行的动作,包括:
26.基于每个方案和由所述执行器确定的各输出动作分别进行博弈;
27.以所述博弈胜率大的对应的方案集或执行器所对应的动作作为所述智能体所执行的动作。
28.基于同一种发明构思本发明提供一种基于人类知识优化强化学习的系统,包括:
29.规则混合模块用于:基于人类领域知识,从智能体要执行的任务中提取多个知识节点,并构建多个行动节点;基于所述多个知识节点、多个行动节点以及多种训练过程确定多个方案;
30.方案扩展模块用于:从所述多个方案和基于预先构建的强化学习算法所确定的各输出动作中进行选择,确定所述智能体所执行的动作;并利用所述智能体所述执行的动作对所述强化学习算法进行训练;
31.其中,每个行动节点对应一个动作。
32.优选的,所述多个方案的确定包括如下步骤:
33.步骤1、从所述多个知识节点中分别确定若干输入的知识节点,从所述多个行动节点中确定若干备选的行动节点;
34.步骤2、基于所述执行的任务所确定的状态s,采用超网络结构经过mlp生成权重和偏置项;
35.步骤3、将所述确定输入的知识节点与所述权重和偏置项相结合并经过激活函数处理后,从所述备选的行动节点中确定概率最大的行动节点;以所述行动节点对应的动作作为输出;基于所述输入和输出得到方案;
36.步骤4、重复执行步骤1,直到得到满足数量的多个方案后,停止执行;
37.其中,每次重复执行步骤1时,至少满足下述一种条件:不同的若干输入的知识节点、不同的若干备选的行动节点和超网络结构。
38.优选的,所述行动节点包括:
39.基于人类领域知识,从所述原始动作空间中剔除非法和无效的动作后得到的动作,作为行动节点。
40.优选的,所述知识节点由如下方法确定:
41.从智能体要执行的所有任务所对应的原始的状态空间和动作空间中,利用人类领域知识确定特征信息,基于所述特征信息确定知识节点。
42.优选的,所述方案扩展模块包括:选择器和强化学习算法模块。
43.优选的,所述强化学习算法模块包括:利用演员-评论家架构的强化学习方法;所述演员-评论家架构的强化学习方法包括:执行器和评价器;
44.所述执行以智能体要执行的任务为输入以动作及动作的概率为输出;
45.演员-评论家架构的强化学习方法用于基于智能体要执行的任务,利用评价器对所述执行器进行训练,确定各动作及各动作的概率。
46.优选的,所述选择器用于:基于每个方案和由所述执行器确定的各输出动作分别进行博弈;
47.以所述博弈胜率大的对应的方案集或执行器所对应的动作作为所述智能体所执行的动作。
48.与现有技术相比,本发明的有益效果为:
49.本发明提供的一种基于人类知识优化强化学习的方法及系统,包括规则混合模块和方案扩展模块,利用规则混合模块结合人类的领域知识构建多个方案,并利用方案扩展模块将规则混合模块构建的方案与强化学习方法进行扩展,避免了强化学习早期低效的随机探索,提高了多智能体强化学习算法的收敛速度,在magent实验环境下取得了更好的效果。
附图说明
50.图1为本发明提供的一种基于人类知识优化强化学习的方法的流程图;
51.图2为kg-rl的整体结构;
52.图3为rule-mix通过超网络学习比决策树更复杂的逻辑结构;
53.图4为手工设计的决策树作为baseline;
54.图5为不同模型获胜场数热图;
55.图6为以baseline为对手时,各算法的胜率;
56.图7为使用不同决策模块的模型比较;
57.图8为kg-rl(右)和mfac(左)之间的战斗截图。
具体实施方式
58.以independent q-learning(tan,1993)为代表的算法,将其他智能体和环境当作一个整体,具有更强的可扩展性。平均场强化学习方法(mean field reinforcement learning,mfrl)进一步提出了一种可证明收敛的平均场公式,通过将状态信息和附近智能
体行为的平均值反馈给评价器来扩大actor-critic框架的规模,增强了学习的稳定性。mfrl通过个体的学习,最终能够展现出群体的智能,这是一个非常有意义的工作,也取得了比较好的效果。但是,mfrl解决的对战问题往往也可以通过手工编写简单的规则实现,本技术实验部分对此进行了比对(见实验部分),这是因为学习从随机初化开始训练,大量的无用信息和无效探索浪费了学习时间和算力。
59.因此,本技术将人类的领域知识与强化学习相结合,提出知识引导的强化学习方法(knowledge guided reinforcement learning kg-rl),其包括规则混合模块(rule-mix)和方案扩展模块(plan-extend)两个模块,首先通过rule—mix将人类知识组合起来,然后通过plan—extend进行扩展。相比于原始的强化学习的方法,我们的方法收敛速度更快。即使是与纯手工编写的规则相比,我们的方法效果也有很大的提升。
60.为了更好地理解本发明,下面结合说明书附图和实例对本发明的内容做进一步的说明。
61.实施例1
62.本发明提供一种基于人类知识优化强化学习的方法,如图1所示,包括:
63.利用规则混合模块执行步骤s1:基于人类领域知识,从智能体要执行的任务中提取多个知识节点,并构建多个行动节点;基于所述多个知识节点、多个行动节点以及多种训练过程确定多个方案;
64.利用方案扩展模块执行步骤s2:从所述多个方案和基于预先构建的强化学习算法所确定的各输出动作中进行选择,确定所述智能体所执行的动作;并利用所述智能体所述执行的动作对所述强化学习算法进行训练;
65.其中,每个行动节点对应一个动作。
66.步骤s1中基于所述知识节点、行动节点以及多种训练过程确定多个方案,包括:
67.步骤1、从所述多个知识节点中分别确定若干输入的知识节点,从所述多个行动节点中确定若干备选的行动节点;
68.步骤2、基于所述执行的任务所确定的状态s,采用超网络结构经过mlp生成权重和偏置项;
69.步骤3、将所述确定输入的知识节点与所述权重和偏置项相结合并经过激活函数处理后,从所述备选的行动节点中确定概率最大的行动节点;以所述行动节点对应的动作作为输出;基于所述输入和输出得到方案;
70.步骤4、重复执行步骤1,直到得到满足数量的多个方案后,停止执行;
71.其中,每次重复执行步骤1时,至少满足下述一种条件:不同的若干输入的知识节点、不同的若干备选的行动节点和超网络结构。
72.利用下式将将所述确定输入的知识节点与所述权重和偏置项相结合:
73.hypernet
out
=relu((wi*ini(s)) bi)
74.式中,ini为第i个知识节点,s为状态,relu为不同的mlp算法,wi为第i个知识节点对应的权重,bi为第i个知识节点对应的偏置项。
75.从智能体要执行的任务中提取多个知识节点,包括:
76.从智能体要执行的所有任务所对应的原始的状态空间和动作空间中,利用人类领域知识确定特征信息;
77.基于所述特征信息构建知识节点。
78.构建多个行动节点,包括:
79.基于人类领域知识,从所述原始动作空间中剔除非法和无效的动作后,得到多个行动节点。
80.基于预先构建的强化学习算法所确定的各输出动作,包括:
81.基于智能体要执行的任务,利用演员-评论家架构的强化学习方法使用随机策略得到各动作及各动作的概率;
82.其中,所述演员-评论家架构的强化学习方法包括:执行器和评价器。
83.从所述多个方案和基于预先构建的强化学习算法所确定的各输出动作中进行选择,确定所述智能体所执行的动作,包括:
84.基于每个方案和由所述执行器确定的各输出动作分别进行博弈;
85.以所述博弈胜率大的对应的方案集或执行器所对应的动作作为所述智能体所执行的动作。
86.实施例2
87.基于同一种发明构思,本发明提供一种基于人类知识优化强化学习的系统,包括:规则混合模块和方案扩展模块。
88.1、规则混合模块(rule-mix)包括知识节点、行动节点和决策过程,下面对这三方面进行具体介绍:
89.知识节点。
90.在许多任务中,环境返回的状态包含着大量的冗余信息,原始的动作空间也包含了许多无效、非法的动作选项。因此,基于人类领域知识,通过对任务的理解,利用一些已有的方法或工具,从原始的状态空间和动作空间中编码出一些额外的有价值信息是非常必要的,这些信息被称为知识节点。例如,对于多智能体对战问题,攻击范围内是否有敌人、观察范围内是否有敌人可作为知识节点。
91.行动节点。
92.基于人类领域知识将规则编码构建成行动节点,使动作执行更加高效,例如,对于多智能体对战问题,攻击血量最少的敌人、向最近的对手移动等可以看作是行动节点。多个行动节点构成行动节点集。
93.决策过程。
94.决策过程就是以原始状态信息、知识节点作为输入,输出选择行动节点策略的过程。
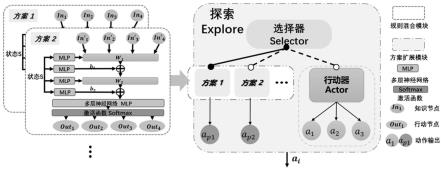
95.策略指在行动节点集中依照学习得到的概率分布进行选择。该决策过程基于强化学习进行训练,目标是最大化设定奖励。
96.以上规则混合模块得到的策略被称为方案,通过构建不同的知识节点、行动节点,以及不同的训练过程,可以得到基于人类知识的多个方案:方案1(plan1)、方案2(plan 2)、
……
方案n(plan n)。
97.2、方案扩展模块(plan-extend),
98.规则混合模块可以得到适应人类知识的策略,为进一步提升效果、挖掘多方案联合的潜力,提出利用方案集和强化学习方法的方案扩展模块。在方案扩展模块中,将快速得
到的方案与演员-评论家(actor-critic)算法的探索阶段相结合,通过构建选择器进行联合探索,减少强化学习早期无效的探索,加速收敛,最后得到更优的策略。本技术称以上方法为人类知识引导的强化学习算法(knowledge guided reinforcement learning,kg-rl)包括方案集、强化学习算法、探索选择器,具体如下:
99.方案集:基于规则混合模块得到的多个方案集合。
100.强化学习算法:基于演员-评论家(actor-critic)架构的强化学习方法,即包含执行器和评价器。
101.探索选择器:在训练阶段,基于效果评估的统计结果,在方案集和强化学习执行器之间进行选择,得到智能体的最终执行动作。该动作实际是训练过程中的探索动作,在训练前期,强化学习算法较弱的时候,更多选择方案的动作,以提升动作探索的效率,减小前期的无用探索。
102.实施例3:
103.本实施例基于图2的整体结构对本发明提供的进行介绍,图2左侧是规则混合模块,右侧是方案扩展模块。
104.1、规则混合模块
105.原始的输入往往包含很多的信息,不易于处理。比如对于图像输入我们往往关心的只画面的内容,而直接将整幅图像直接输入网络中去进行端到端的训练是相当费时的。可以借助已有的算法或者常识,基于当前的观察得到一些有助于决策的信息。因此,我们首先将从原始的观察中抽取这些更有价值的信息的方法形成知识节点,n个知识节点用符号ini,i=1,2,
…
,n表示。
106.原始的动作空间一般直接使用类似上、下、左、右、攻击等最直接的动作,不包含任何知识。因此很多情况下往往选择了无效或者非法的动作,有时在一些环境中非法动作的代价往往是高昂的。实际上,这些无效、非法的动作在很多问题中对人类而言是很容易判断的,因此可以基于规则将最后决定输出的动作嵌入人类知识,得到行动节点,n个行动节点用符号outi,i=1,2,
…
,n表示。
107.受qmix的启发,规则混合模块的决策过程采用超网络结构,如图3左边所示。使用状态s经过mlp生成权重wi和偏置项bi,并将它们与知识节点ini相结合,如公式(1)所示:
108.hypernet
out
=relu((wi*ini(s)) bi)
ꢀꢀ
(1)
109.网络最后一层输出通过softmax函数处理后,选择输出概率最大的行动节点产生的动作。这种超网络结构使状态s与知识节点通过乘法相关联,通过该关联将当前状态对知识节点的梯度集成到网络中,这样可以提供更多的信息。最后,使用actor-critic算法对网络进行训练,训练的目标是最大化长期回报。超网络的作用是生成类似于图3右边决策树的逻辑结构,凭借深度神经网络的强大表示能力,设计的这种超网络结构比决策树具备更复杂的逻辑结构。
110.2、方案扩展模块
111.我们将通过规则混合模块得到的策略称为方案(plan),对于从规则混合模块生成的plan,其最终的动作输出由行动节点决定,缺乏对动态环境的探索性。然而强化学习算法可以提供持续的学习和探索能力,但是训练早期的探索效率较低。因此,设计将方案与强化学习算法相结合提高其探索和学习能力。
112.actor-critic算法使用随机策略输出各个动作的概率,该算法通过对actor策略的分布采样进行探索。然而,在训练早期,由于策略网络包含的信息较少,这几乎等同于随机探索。当状态和动作空间较大时,随机探索获得奖励的概率较低,这导致算法早期的学习较慢。因此,设计了一个探索选择器,在基于规则混合模块得到的方案集和强化学习动作执行器之间进行选择,选择的标准是对比方案集和强化学习动作执行器当前胜率差异。
113.探索选择器决定了使用plan i或者当前行动器actor(即基于演员-评论家架构的强化学习方法中的执行器)的策略来与环境进行交互,如图2右边所示。可以在执行每一步动作或者在一幕结束时进行选择。选择器的目标是选出当前更好的策略,因此可以产生更优质的样本,加快算法的收敛速度。
114.探索选择器的作用是在actor的策略不如方案时使用方案进行探索,在每轮训练之后的根据评估结果重新赋值。在评估中统计分别基于不同方案和强化学习执行器最近30轮的胜率,决定最终选择哪种动作策略进行探索。需要注意的是,这里的选择器和和plan i都只用于与环境交互产生轨迹t(s
t
,a
t
,r
t
,s
t 1
,done),而不包含在训练得到的模型中。其次,plan是确定性的动作策略,在状态s
t
下得到a
t
的概率p(a
t
|s
t
)=1。通过探索得到的轨迹数据都可用于ac算法的更新。
115.实施例4
116.本实施例通过在magent环境中与原始的mfrl方法、纯手工设计的策略(基于知识节点构建决策树,得到行动策略)以及只有规则混合模块的方法进行了比较,结果表明,本发明提供的包含两个模块的一种人类知识优化强化学习的方法表现最好。下面对实验过程进行介绍。
117.1环境
118.为了证明我们所提方法的有效性,我们在magent环境进行了实验。magent是由上海交通大学团队开发,用于大规模智能体的对抗环境。环境采用离散状态和离散动作,有良好的用户接口和方便的可视化界面。对战环境中对战双方是平等的,便于进行self-play的训练。实验中采用40*40的地图,对战双方各控制一组智能体。初始时双方各有64个智能体,战斗死亡后不补充。终止条件是一方被全灭,或者达到最大幕数。当达到终止状态时存活智能体数量多者取胜。智能体的局部观察是一个7通道的13*13的矩阵,分别表示障碍物、队友、队友的血量、己方迷你地图、对手位置、对手血量、对手的迷你地图,和一个长度为34的向量表示自己上一步的动作、上一步奖励和相对位置。智能体的21个动作包括智能体周围13个可移动位置和8个可攻击位置。强化学习中的奖励设置与mfrl中相同。
119.2人类知识模块设计
120.在magent环境中,我们利用人类在对战问题中经验规则:在攻击范围内有敌人时才攻击;优先攻击血量最少或者距离最近的敌人;为了加强合作,会向队友靠近;同时为了更好的生存,人类会及时关注自己的血量。根据以上人类知识,我们可以抽象成如表1中的知识节点和行动节点。
121.表1实验中使用的知识节点和行动节点
[0122] in(i)out(i)1攻击范围内是否有敌人攻击血量最少的敌人2观察范围内是否有敌人向最近的的对手移动
3观察范围内是否有队友向对手最密集的的方向4自己的血量是否大于一半向血量最少的队友移动5观察范围内我方数量是否大于对方攻击最近的敌人6上一个动作是否是攻击攻击在射程内的任意一个
[0123]
3实验设置
[0124]
实验中己方的所有智能体都共享参数,以应对大规模智能体学习。使用adam优化器,学习率为1*10-4
。折扣因子γ均为0.95。对于基于值函数的方法(mfq、dqn、pmlpe),batch size设置为64,buffer为8*104。所有的模型都使用自博弈的方式训练2000轮。
[0125]
通过人类知识模块的组合,可以手工设计一个如图4的基于人类知识的决策树作为baseline。实验证明即使是这种的简单组合效果就已经大大超越了其他从零开始训练的算法。此外,还选择了此环境上当前表现最好的mfrl方法和同样基于人类领域知识的pmlpe方法作为对比。
[0126]
4实验结果
[0127]
胜负是对战环境的一个很好的判定条件,也是最有价值的指标。因此,首先使用各个算法训练得到的模型相互对战并统计各个模型取得胜利的场次、击杀和被击杀的智能体数量作为衡量的标准。然后,以baseline为对手,对比了各模型的训练阶段模型提升速度。此外还对比了rule—mix、plan—extend和baseline选择输出的行动节点,展示了它们之间的差异。最后,我们结合战场回放分析了模型行为。
[0128]
一)对战游戏battle game
[0129]
这个实验中我们直接使用各个算法训练得到的模型进行对比,为了合理评估各个算法的效果,在各算法训练得到的模型中每次随机选择2个进行两两对战,共进行10000场对决。除了各模型的获胜场数,另外统计了各个模型击杀和被击杀的数量,使用了国际象棋中常用的elo评分机制计算分数。
[0130]
表2对战结果
[0131][0132][0133]
为了减少随机误差,我们为每个算法分别训练了3个模型,命名为算法a,b,c。对战的结果在表2中,各个模型获胜的场次我们在图5中用热图表示。
[0134]
可以看到我们提出的方法rule—extend无论是得分、胜率还是击杀和被击杀的比
值(kd)比上都好于其他方法。尤其是rule—mix和rule—extend均优于手工设计的baseline,相反,从随机初始化开始的方法表现都不如baseline。这说明了将人类知识嵌入强化学习的巨大潜力。
[0135]
二)训练过程对比
[0136]
由于,各算法训练时为自博弈,而自己本身在更新时是不断变化的。为了评估各算法的收敛速度,训练中,我们让模型在每轮训练之后与baseline进行一轮对战,统计最近30轮的胜率。从图6中可以看出plan-extend收敛最快,在200步时就稳定达到1.0的胜率,且最终只有rule-mix和plan-extend胜率达到1.0。这说明了基于人类知识强化学习的良好的表现。
[0137]
三)知识节点和行动节点的影响
[0138]
知识节点和行动节点的不同选择对算法有不同的影响。我们分别将使用了知识节点(in1,in2,in3,in4)、(in1,in2,in3)、(in1,in2)、(in1)和没有使用知识节点的模型分别命名为:rule_mix_in4、rule_mix_in3、rule_mix_in2、rule_mix_inl、rule_mix_in0。图7是他们的训练曲线,可见输入模块越多收敛越快。
[0139]
我们选择了行动节点为(out1,out2,out3,out4)、(out1,out2,out3,out5)、(out2,out3,out4,out5)、(out2,out3,out4,out6)的模型分别命名为rule_mix_out1、rule_mix_out2、rule_mix_out3、rule_mix_out4。表3是训练所得模型胜率的对比。可见选择不同的行动节点对最终模型的效果是有影响的。在本文中rule_mix_out1表现最好,因此它对应的动作模块也被应用于其他实验中。
[0140]
表3使用不同动作模块的模型比较。
[0141] el0分数胜率rule_mix_out 1158682%rule_mix_out 2126821%rule_mix_out 3136943%rule_mix_out 4147951%
[0142]
四)discussion
[0143]
环境中包含64个智能体,集中训练的maddpg和qmix方法在这样大的规模上基本失效。我们提出的基于人类知识的强化学习方法加速了算法的收敛速度,采用了分布训练和参数共享的技巧在大规模群体智能上表现得更好。
[0144]
通过加入的知识节点减少了原始状态中的冗余信息,为网络提更简洁、更有价值的信息,加快网络的学习速度。如图8为kg-rl和mfac之间的战斗截图,图中,a的右侧为kg-rl、左侧为mfac;为了显示细节,在图8的右侧提供一张放大的截图c。在战斗开始时,两组士兵被初始化成左右对称的位置),是plan-extend和mfrl的一场对战的截图,可见rule-mix从一开始就占据了较好的优势位置,对对手形成半包围的状态。这种半包围的状态,有利于我方集中火力加强合作。虽然每个智能体是单独训练的但整体却展现出了这种群体的智能,这是十分有益的。
[0145]
其次,观察每个智能体的局部动作,可以发现,mfac的无效攻击(攻击没有人的区域)比plan-extend多得多。我们的方法借用人类规则的优势,通过rule-mix的方式直接屏蔽了那些无效和非法的动作,减小了算法的探索空间。
[0146]
显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0147]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0148]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0149]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0150]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0151]
以上仅为本发明的实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均包含在申请待批的本发明的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。