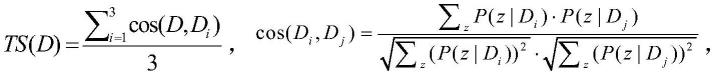
1.本发明涉及文本检索,信息检索或数据挖掘领域,具体涉及一种伪相关反馈中的文档主题相关性模型。
背景技术:
2.伪相关反馈(pseudo relevance),也称为盲相关反馈(blind relevance feedback),是一种自动局部分析的方法。它将相关反馈的人工操作部分自动化,从而可以获得检索性能的提升。该方法首先进行正常的检索过程,返回最相关的文档构成初始集,然后假设排名靠前的k篇文档是相关的,最后在此假设上像以往一样进行相关反馈。
3.通过查询扩展(query expansion,qe)的伪相关反馈(pseudo relevance feedback,prf)通常被认为是在信息检索(information retrieval,ir)中实现良好性能的一个非常有效的方法。尽管prf模型通常表现非常好,但在某些情况下也会失效。在经典的prf模型中,比如rocchio模型或相关性模型rm3,所有排名靠前的k个反馈文档都被假定为与查询同样相关。其中候选词项的权重只基于它们在集合中的重要性。这些模型在选择候选文件时并不能确定它们的可靠性。一般来说,不同的反馈文档中具有相同权重(如词频-逆文本频率(term frequency
–
inverse document frequency,tf-idf)指数)的词被认为对qe是同样可靠的。当一些反馈文档包括不同的主题,其中许多与原始查询无关时,采用经典prf策略的模型(例如,rocchio和rm3)表现不够好。在这种情况下,文档中涉及不相关主题的大量不相关词项也被添加到新的查询表示中,这会对第二遍检索的检索性能产生了负面影响。
4.最近,研究人员开始将主题模型用于prf,以获得最相关主题的反馈词。然而,它们中的大多数方法都是从第一轮检索返回的前k个文档中选择候选词项,而没有考虑这些文档的可靠性。由于原始查询一般都很短,而且它们的主题是模糊的,因此采用当前的方法有很大的缺陷。针对这个问题,miao等人通过将"主题空间"(topic space,ts)信息整合到rocchio模型中,提出了一个概率框架topprf,该框架通过考虑top-3文档和其它文档之间的相关性来估计反馈文档的可靠性。
技术实现要素:
5.发明目的:从背景的说明来看,在选择候选词项时,大多数研究都没有确定第一遍检索时返回的前k个文档的可靠性。为解决上述问题,本发明提出通过在语言模型中引入基于主题的反馈文档之间的相关性来估计反馈文档的可靠性。与miao等人提出的工作不同,本发明的方法可以被认为是一种通用的方法,能够被纳入任何其它prf模型中。在trec的5个公开数据集上对本发明提出的基于主题的伪相关反馈的相关性模型进行了验证,实验结果表明本发明算法具有良好的性能。
6.技术方案:
7.本发明的相关性模型基于经典的伪相关反馈框架,通过改进查询的表示方法来实
现(伪)相关性反馈。在相关性模型rm1中,一个候选词项w的权重是:p(w|r)
∝
∑
d∈f
p(w|d)
·
p(d|q)
ꢀꢀꢀ
(1)
8.其中,q是一个查询,d是反馈文档集f中的一个文档,p(w|d)是文档语言模型,p(d|q)是查询语言模型。本发明采用这个框架,但是利用了基于主题的文档相关性p
t
(d|f),而不是从文档得分估计p(d|q)。本发明提出的基于主题的相关性模型如下:
9.p
t
(w|r)
∝
∑
d∈f
p(w|d)
·
p
t
(d|f)
ꢀꢀꢀ
(2)
10.类似的,相关性模型的变体rm3,是对原始查询模型θq和反馈语言模型θf进行了线性组合,相应的公式如下:
11.θq=(1-α)
·
θq α
·
θfꢀꢀꢀ
(3)
12.rm3不仅在精度和召回率指标上获得了较好的性能,而且鲁棒性更加突出。用于平滑文档语言模型的dirichlet先验
21.被用于其中。在此基础上,充分考虑上述策略,本发明用基于主题的相关性模型p
t
(w|r)估计反馈语言模型θf,提出toprm3模型。
13.给定一个查询q,在第一遍检索中的前k个反馈文档集f可以表示为它们在主题空间中的主题分布p
t
(z|d)(d∈f)。然而,p
t
(z|d)不能表征直接测量查询和文档之间基于主题的相关性。原因是短查询的主题分布表示通常是非常稀疏和粗糙的。相关的研究工作
10.发现反馈文档集中的前s(s《《k)的文档最有可能与查询主题相关。通常情况下,一个特定查询的相关文件涵盖了几个主题。为了保持主题多样性和文档相关性的平衡,在本发明中把s的值设为3,并把前s个文档中的主题视为查询主题。
14.本发明通过余弦公式测量两个文档的主题向量之间的相似度。文件di和dj的主题相似性如下:
[0015][0016]
其中z是主题,p(z|d)是d中的一个主题分布。当s=3时,主题相似度ts(d)计算如下:
[0017][0018]
其中,前三个文档的指数被设置为1,因为默认它们是与查询相关的。
[0019]
接着,将主题相似度ts(d)转换为基于主题的文档相对相关性p
t
(d|f)。由于p
t
(d|f)是一个分布,可以采用两种归一化方案,即线性方法和soft-max方法,具体如下:
[0020][0021][0022]
其中公式(6)表示线性方法,公式(7)表示soft-max方法。
[0023]
基于以上两种相关性表示方法,本发明提出了基于主题的相关性模型,分别表示为toprm3-l和toprm3-s。
[0024]
本发明将基于主题的相关性信息进一步整合到rocchio模型中,即得到基于主题的rocchio模型toproc。具体描述如下:
[0025]
(1)所有的文档都使用一个特定的ir模型对给定的查询进行排名。在第一遍检索中使用bm25,排名最前面的|f|个文档被确定为伪相关集f。
[0026]
(2)在排名最前面的|f|个文档中的每个候选词都被分配一个扩展权重。一般来说,扩展权重是由加权模型和基于主题的文档相关性提供的权重的点积。本发明使用tf-idf模型
[22]
作为加权模型。
[0027]
(3)查询词权重的向量是初始查询词权重和扩展权重的线性组合。其公式如下:
[0028]
q1=α
·
q0 β
·
∑
d∈f
r(d)
·
p
t
(d|f)
ꢀꢀꢀ
(8)
[0029]
式中q0和q1分别代表原始查询向量和经过一次迭代生成的查询向量,α和β是控制原始查询向量和反馈信息依赖程度的调整参数,r(d)是反馈文档d的tf-idf权重向量,f是prf的反馈文档集,p
t
(d|f)衡量反馈文档d主题相关性的程度。在实践中,可以始终将α固定为1,而只研究β,以获得更好的性能。如果p
t
(d|f)服从均匀分布,toproc模型就是原来的roccho模型。此外,还可以使用前面定义的p
t
(d|f)的两种计算方法,相应的模型分别表示为toproc-l和toproc-s。
[0030]
有益效果:本发明在5个公开的trec数据集上的进行了验证,取得了良好的实验结果。表1的结果表明,rm3在所有的集合上都优于lm,rocchio模型优于bm25。这表明rm3和rocchio模型仍然是ir研究工作中非常强大的基础模型。与rocchio模型相比,rm3在反馈文档数量变化时表现得更加稳定。在表1中,本发明提出的toprm3模型优于rm3,而toproc模型在所有的集合上都优于rocchio模型。特别是,toprm3-l和toproc-l分别比rm3和rocchio模型有明显的改善。在大多数情况下,toproc-l在map方面获得了最佳性能。在表2中,本发明还将所提的toproc与ts-cos进行了比较,ts-cos是topprf的最有效变体,被认为是最有效的、最先进的prf模型之一。为了进行公平的比较,这里采用他们与相应的rocchio模型的改进百分比进行比较。结果展示在表2中。从表2来看,本发明提出的toproc-l在大多数情况下有更大的改进,这表明本发明提出的基于主题的相关性模型更加有效。
[0031]
此外,这里对本发明提出的toprm3-l对反馈文件数量和反馈插值系数α在map方面的敏感性进行了研究。结果如图1和图2所示。在图1中,当反馈文档的数量发生变化时,toprm3-l的性能略有不同。此外,这些结果表明,为了获得良好的整体性能,建议将反馈文件的数量设定为20个。图2表明,toprm3-l在所有5个公开的trec数据集上的检索效果都是相似的,建议反馈系数α取值在0.6左右。
附图说明
[0032]
图1展示了toprm3-l对反馈文件数量|f|的敏感度。
[0033]
图2展示了toprm3-l对反馈系数α的敏感度。
具体实施方式
[0034]
本发明主要使用trec的5个公开数据集来测试所提出的模型,以验证所提方法的有效性,具体包含查询序数为51-150的disk1&2,查询序数为401-450的disk4&5,查询序数为401-450的wt2g,查询序数为451-550的wt10g以及查询序数为701-850的gov2。这些数据集的规模和类型各不相同。在本发明的实验中,只检索trec查询的标题字段,因为搜索引擎的用户总是在他们的查询中输入足够短的内容来表示查询意图。本发明删除了没有评价标
准的查询,还删除了标准的英文停顿词,并使用porter英文词干器对所有每个词进行词干处理。最后,本发明使用trec的官方评价指标,即均值平均精确率(mean average precision,map),来评估本发明提出模型的有效性。所有的统计测试都是基于wilcoxon配对符号秩检验。
[0035]
在本发明基于主题的实验中,将所提方法与lm、bm25和两个典型的prf模型rm3和rocchio模型进行了比较。虽然还有其它的prf方法,但本发明的模型是基于rm3和rocchio提出的,所以这里不考虑其它的prf方法。为了公平起见,本发明对基准模型和所提出模型的参数都采用ir领域的通用设置。在lm中,dirichlet平滑参数设置为μ=1000,论文
[23]
表明,对于大多数集合来说,实现了最佳的map值。在bm25中,将b、k1和k3分别设置为0.35、1.2和8.0,论文
[24]
表明,对于大多数集合可以提供最佳map。对于prf模型中的参数,扩展词(项)的数量被固定为30。遍历的前列文档参数为|f|∈10,20,30,50,相关性模型中插值参数α∈{0.0,0.1,......,1.0},rocchio模型中β∈{0.0,0.1,......,1.0}。在lda
[11]
中,主题的数量被建议为5、10和20
10.。所有的实验结果都通过两折交叉验证进行评估。采用查询系数的奇偶性对trec查询进行划分。在其中一个查询集合上训练参数,并将其被应用于另一个查询集合评估,反之亦然。
[0036]
此外,为了获得良好的整体性能,建议将反馈文件的数量设定为20个,建议反馈系数α取值在0.6左右。
[0037]
表1在5个公开的trec数据集上,比较基准模型、toprm3和toproc的map值的所有实验结果。其中,符号"*"表示根据wilcoxon配对符号秩检验,在0.05水平上比相应的prf模型有统计学意义的改进(p《0.05)。括号内的百分比是对比相应的prf模型的提高比例。粗体字标出了每组的最佳结果。rm3表示以lm作为第一遍检索模型的相关性模型,rocchio表示bm25 rocchio。
[0038]
表2将所提的toproc与ts-cos进行了比较,ts-cos是topprf的最有效变体,被认为是最有效的、最先进的prf模型之一。为了进行公平的比较,表中采用他们与相应的rocchio模型的改进百分比进行比较。在表2中展示了toproc-l和ts-cos的改进百分比比较,表示toproc-l有更大的改进。
[0039]
表1比较基准模型、toprm3和toproc的map值
[0040][0041]
表2 toproc-l和ts-cos的改进百分比比较,表示toproc-l有更大的改进
[0042]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
