一种基于集成学习和多层dropnode传播的节点分类方法
技术领域
1.本发明属于图挖掘技术领域,尤其涉及一种基于集成学习和多层dropnode传播的节点分类方法。
背景技术:
2.在现在的大数据时代,很多数据都是以网络的形式存在的,比如社交网络、学术网络、引文网络、交通网络等。由于大量的且多种多样的网络存在,针对网络分析和挖掘的研究开始大量涌出,比如对网络中的节点进行分类。半监督节点分类任务是指预测给定图网络中只有少量标记节点的未标记节点的类别。通过节点分类,我们可以在社交网络中推荐好友和在学术网络中给学者推荐合作者。在最近的研究中,图神经网络算法被广泛应用在半监督节点分类任务中并且取得了很好的结果。如中国发明专利114036298a公开号中公开了一种基于图卷积神经网络的节点分类方法,中国发明专利112861936a公开号中公开了一种基于图神经网络知识蒸馏的节点分类方法。
3.以往基于图神经网络算法去实现节点分类的大多数方法面临着不鲁棒和过平滑的问题。基于此问题,在本发明中提出了一个包含集成学习和多层dropnode传播的节点分类方法,该方法实现了很好的分类结果。
技术实现要素:
4.本发明提供了一种基于集成学习和多层dropnode传播的节点分类方法,该方法可以有效地提高节点分类的准确率,并且可以很好地缓解大多数图神经网络面临的不鲁棒和过平滑的问题。
5.本发明的技术方案:
6.一种基于集成学习和多层dropnode传播的节点分类方法,步骤如下:
7.步骤1:获取实验所需要使用的数据集
8.在分析分类结果的实验过程中,采用的数据集分别为cora、citeseer、pubmed三个引文数据集。
9.步骤2:针对图数据,执行多层dropnode传播
10.给定一个图g=(v,e),其中v={v1,v2,
…
,vn}是一个顶点集合,e是边集代表着顶点与顶点之间的连接。同时,图g的邻接矩阵a和特征矩阵x也被给出。在标签传播过程中,图g中的节点vi会被分配一个概率p,以此来实现对每一个节点执行多层dropnode传播的过程。具体来说,就是当前节点的每阶邻居节点传播信息给当前节点时,每一阶邻居节点被删除的概率为p。也就是,当前节点经过多层dropnode传播后,特征矩阵x改变为:其中k为传播步长,代表着当前节点的k阶邻居会传递信息给自己,为对称归一化邻接矩阵,代表每一阶邻居节点的特征矩阵被删除的概
率为p。经过多层dropnode传播,每个节点随机地从多个邻居子集节点中聚合信息,减少了当前节点对于特定邻居节点的依赖。因此,不同于特定性传播,这种传播方式加强了模型的鲁棒性并且缓解了过平滑问题。
11.步骤3:预测,将多层传播获得的矩阵送入一个多层感知机(mlp模型)进行预测
12.接下来,多层传播获得的矩阵都会被送入一个多层感知机模型(mlp模型)进行预测,得到相应的分类结果,即输出未知标签节点的预测标签:其中θ是mlp模型的参数集合。
13.步骤4:集成多个模型的分类结果
14.如图2所示,在整个框架中,多个mlp模型去完成分类任务产生多个分类结果。除了第一个模型之外,每一个模型将会使用前一个模型的输出作为知识以获得更准确的分类结果。在集成过程中,考虑模型与模型之间的交互,而不是单一的模型进行简单地集成,这样做的好处是当前模型收到前一个模型的先验知识,当面对一些干扰时,当前模型因为前一个的先验知识可以很好地避免因为相同的扰动所导致的错误的分类输出。
15.步骤5:计算总损失及监督损失和集成学习损失
16.在整个算法中,损失主要分为模型中的损失和模型之间的损失两部分。模型中的损失为监督损失。
17.步骤6:验证模型的鲁棒性
18.通过随机添加假边的攻击方法对图进行扰动,检验了整个框架的鲁棒性。
19.步骤7:验证模型的过平滑性
20.通过扩大传播步长,研究了整体框架对过平滑问题的敏感性。
21.一种基于集成学习和多层dropnode传播的节点分类装置,包括:
22.数据集获取模块:用于获取实验中所需要的数据集及有限标签;
23.多层dropnode传播模块:用于对特征矩阵进行信息传播;
24.预测模块:用于预测并且输出分类结果;
25.集成模块:用于集成多个模型的分类结果;
26.计算损失模块:用于计算监督损失和集成损失及总损失;
27.验证模块:用于验证模型的鲁棒性和过平滑性。
28.许多图神经网络方法都存在过平滑问题。当扩大传播步长时,大多数图神经网络可能会使具有不同标签的节点难以区分。为了验证本模型是否缓解了过平滑问题,我们通过扩大传播步长,研究了在cora和citeseer数据集上整体框架对过平滑问题的敏感性。
29.本发明的有益效果:
30.本发明提供了一种基于集成学习和多层dropnode传播的节点分类方法。本发明首先在传播过程中执行多层dropnode策略,将传播后的矩阵送入mlp模型中进行分类,然后将多个模型的结果进行集成,集成过程中考虑模型之间的交互性,即当前模型将前一个模型的输出结果作为自己预测的先验知识。此模型不但能提高节点分类准确率,同时有效地缓解了大多数图神经网络在节点分类中存在的过平滑和不鲁棒的问题。
附图说明
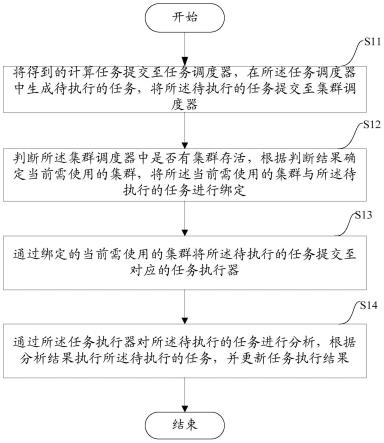
31.图1为本发明提出的一种基于集成学习和多层dropnode传播的节点分类方法的整体流程示意图;
32.图2是本发明提出的一种基于集成学习和多层dropnode传播的节点分类方法的处理过程示意图;
33.图3是本发明实施集成过程的示意图;
34.图4是本发明在cora数据集上加入假边分类准确率和其它方法对比的示意图;
35.图5是本发明在cora数据集上分类准确率随着传播步长增加变化的示意图;
36.图6是本发明在citeseer数据集上分类准确率随着传播步长增加变化的示意图。
具体实施方式
37.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
38.本发明的目的是提供一种基于集成学习和多层dropnode传播的节点分类方法,本发明实施例将模型命名为gel,gel不仅能够提高节点分类任务的准确率,同时有效地缓解大多数模型面临的过平滑和不鲁棒的问题。
39.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
40.图1为本发明实施基于集成学习和多层dropnode传播的节点分类方法的框架示例图,如图1所示,包括如下步骤:
41.s1:获取实验过程中所需要使用的数据集。在分析半监督节点分类任务的分类结果过程中,使用了三个引文数据集,分别为:cora、citeseer、pubmed。如下表1为三个数据集的统计信息。
42.表1数据集统计信息
43.数据集节点数边数类别数特征数cora2708542971433citeseer3327473263703pubmed19717443383500
44.关于三个数据集的详细信息如下:
45.cora是一个机器学习论文间引用相关的基准数据集。它在图学习领域中被广泛使用。每个节点代表一篇论文,每条边代表论文之间的引用。节点的标签表示论文的研究领域。
46.与cora类似,citeseer是另一个基准数据集,它表示计算机科学论文之间的相互引用。
47.pubmed是一个与糖尿病相关的论文的引用数据集。节点特征是tf-idf加权词频向量。节点的标签表示糖尿病的类型。本发明实施在三个公开基准数据集上进行了实验。实验结果表明,本方法的表现优于现有经典的基线模型。
48.s2:针对图数据,执行多层dropnode策略。在半监督节点分类任务中,节点信息的传播遵循以下假设:由相同的边连接的节点极有可能具有相同的标签。基于这样的假设,节点的标签极易依赖于特定的邻居,为了避免这种情况,在传播过程中采用多层dropnode传播。也就是,图g的节点vi会被分配一个概率p。具体来说,就是当前节点的每阶邻居节点传播信息给当前节点时,每一阶邻居节点被删除的概率为p。举例来说,当p=0.5,当前节点的一阶邻居节点为10个,二阶邻居节点为8个时,经过多层dropnode传播,当前邻居节点的一阶邻居节点会被随机地删除5个,二阶邻居节点会被随机地删除4个,特征矩阵x改变为:其中k为传播步长,代表着当前节点的k阶邻居会传递信息给自己,为对称归一化邻接矩阵,代表每一阶邻居节点的特征矩阵被删除的概率为p。是到的平均数,对比直接使用这样做的好处是每个节点可以聚合更远的节点信息,降低了过平滑的风险。同时,每个节点从其多个不同的邻居子集中随机聚合信息,因此其特征可能会受到更多的远处邻居的影响。另外,这种传播规则保证了减少噪声节点信息的干扰,增强了模型的鲁棒性。
49.s3:预测,将多层传播获得的矩阵送入一个mlp模型进行预测。多层传播获得的矩阵都会被送入一个两层的mlp模型进行预测,得到相应的分类结果:其中θ是模型的参数集合。
50.s4:集成多个模型的分类结果。如图3所示为本方法中模型的集成过程示意图,分类器mlp1输出分类结果z(1),此分类结果z(1)会被传递给下一个模型mlp2。当mlp2做分类时,它会接收前一个模型的输出结果,然后给出自己的分类结果z(2)。因此,每个第i个模型都会接收到第(i-1)个模型的输出作为自己的预测的知识。第i个模型与(i-1)个模型之间的预测的优化目标可以表示为:其中,distance(
·
,
·
)表示两个模型之间的距离,所以优化目标是指最小化第i个模型与第i-1个模型对同一个没有标签的节点v的预测结果的距离。
51.s5:计算总损失及监督损失和集成学习损失
52.在整个算法中,损失主要分为模型中的损失和模型之间的损失两部分。模型中的损失为监督损失。n个节点中有m个标记节点,每个epoch的监督损失表示为:其中y为节点的标签,zi为第i节点经步骤3的mlp模型预测得到的分类结果。模型之间的损失为集成学习损失,表示为:其中n表示一共集成n个模型,j表示第j个模型,i表示第i个节点。总的损失为l=l
sup
λl
ensem
,其中λ为控制监督损失和集成损失平衡的参数。在整个训练过程中,控制总损失最小,准确率最大。
53.s6:验证模型的鲁棒性
54.通过随机添加假边的攻击方法对图进行扰动,验证了整体框架的鲁棒性。图4显示了当使用不同的扰动率对cora数据集进行扰动时,不同方法的分类准确率。可以看到,在所有扰动率上,gel的表现都优于gcn和gat。与最近的模型grand相比,可以看到,虽然gel在扰动概率小于100%时的分类准确率比grand略低,但当扰动概率大于100%时,gel表现出明显的优势。当在cora数据集中添加200%条随机边时,gel的分类准确率仅下降17.6%,而grand的分类准确率下降了26.5%,gat的分类准确率下降了28.4%,gcn的分类准确率下降了70.8%。本研究表明随着扰动率的增加,本模型具有鲁棒性的优势。
55.s7:验证模型的过平滑性
56.通过增加传播步长,分别研究了在cora和citeseer数据集上所提出的方法对过平滑问题的敏感性。如图5,图6所示,随着传播步长增加,由于过平滑问题,gcn和gat在两个数据集上的分类准确率都大幅度下降。然而,gel方法和grand的表现完全不同。gel和grand都几乎不受传播步长的影响。同时,在两个数据集上,随着传播步长的增加,gel的表现始终优于grand。这样的结果表明,在缓解过平滑问题上,我们所提出的方法更强大。
57.下面通过算法1展示整体框架的伪代码。
58.输入:图g=(v,e),邻接矩阵a,特征矩阵x,模型数量n,dropnode概率p,学习率η,mlp模型
59.输出:预测结果z。
60.第1步骤,while没有收敛do;
61.第2步骤,for n=1,2,...,n do;
62.第3步骤,执行多层dropnode传播:
63.第4步骤,使用mlp模型预测分布:
64.第5步骤,end for;
65.第6步骤,计算监督损失集成损失
66.第7步骤,更新参数θ通过梯度下降
67.第8步骤,end while;
68.第9步骤,输出预测
69.为了说明本发明实施例的实现效果,有如下描述:
70.我们用pytorch进行实验。对三个数据集进行预处理的过程参考planetoid。这三个基本数据集的实验设置与半监督学习任务的实验设置完全相同。对于cora数据集,训练节点、验证节点、测试节点的值分别为140、500和1000。对于citeseer数据集,训练节点、验证节点、测试节点的值分别为120、500和1000。对于pubmed数据集,训练节点、验证节点、测试节点的值分别为60、500和1000。此外,在训练过程中,我们采用patience为200的早期停
止作为终止指标。为了评价方法的性能,我们在实验中使用的分类任务的度量标准是准确率(accuracy)。
71.分类结果分析。
72.表2分类准确率(%)
73.方法coraciteseerpubmedgcn81.570.379.0gat83.773.279.3dgi82.972.577.4appnp84.172.180.0mixhop82.372.281.4graphsage79.768.178.4grand85.875.883.3rdd86.174.281.5gel86.576.084.2
74.从表2中,我们可以清楚地看到,与其他基线相比,gel在三个数据集上始终有着最好的表现。具体来说,对比gcn,gel在cora、citeseer、pubmed上的改善幅度分别为5%、5.6%、5.2%。与gat相比,gel分别提高了3.5%、3.4%、5.2%。与grand相比,gel分别达到了1.1%,0.4%,1.5%的改善。
75.通过对参数进行敏感性分析,表2为本方法的各个参数设置。
76.表3参数设置
[0077][0078]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。