一种基于无监督神经网络的nmr弛豫时间反演方法
技术领域
1.本发明属于核磁共振技术领域,具体涉及一种基于无监督神经网络的nmr弛豫时间反演方法。
背景技术:
2.在核磁共振(nmr)研究领域,所研究样品的nmr弛豫时间是与物质分子的结构和动态过程以及所处的环境密切相关, 是表征物质特性以及所处的环境相互关系的特征参数。研究中最常用的nmr弛豫时间有两种:纵向(自旋
‑
晶格)弛豫时间t1和横向(自旋
‑
自旋) 弛豫时间t2。对于简单体系的nmr样品(如纯水)弛豫过程是单指数的时变函数形式,样品的弛豫时间(t1和t2)是易于分析的单组份。而如果所研究的样品含有多种物质成分或者是样品内部的局部微环境不均匀的复杂体系,样品的nmr弛豫过程不再是简单的单指数时变函数形式,而是比较复杂的多指数时变函数形式,样品nmr弛豫时间隐含有多种组分信息,复杂体系的数据分析要复杂和困难得多,必须通过合适的特定的nmr弛豫时间反演方法进行演算分析才能获得各种组分的弛豫时间(又称为:nmr弛豫时间谱,t1谱,t2谱),并由此分析和了解所研究样品的各组分对应的物质特性和动力学信息。
3.目前,nmr弛豫时间谱相关技术已被广泛地用于石油、化工、食品、农业、医药、材料等诸多领域。获得nmr弛豫时间谱的传统方法通常是对采集到的原始自旋弛豫信号进行拉普拉斯反演,该方法属于病态的算法。因为原始自旋弛豫信号中的小噪声就可能会导致反演结果发生重大的变化, 使得弛豫时间谱具有不确定性。传统反演方法可以分为线性反演方法和非线性反演方法。线性反演方法主要是截断奇异值分解和tikhonov正则化方法。非线性反演方法包括蒙特卡洛方法和最大熵方法等。线性反演方法通常采用非负正则化项来对解的幅度和形态,以降低解的不确定性,但解对正则化项参数比较敏感,依赖先验信息,需要人工手动来调节。非线性反演方法通常是使用多次迭代寻找到目标函数的全局最小值,该类方法的运算速度非常慢。
4.最近,深度学习网络已被用于解决这类反演问题。使用带有参考数据的有监督训练(supervised training of deep neural network,std)以获得弛豫时间谱。这种方法不需要人工参与调节正则化参数,与传统方法相比,减少了对正则化参数的依赖。但是std的训练是需要参考的弛豫时间谱作为标签,如果使用实验数据作为训练数据的话,标签的制作几乎是不切实际的。
5.本发明提出了一种无监督深度神经网络(unsupervised training of deep neural network,utd)解决上述问题。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。使用未被标记的训练样本来训练的神经网络,即为无监督神经网络。本发明使用未被标记的nmr弛豫信号作为训练样本来训练神经网络,使用前向问题作为训练期间的损失函数。本发明无需参考的nmr弛豫时间谱作为标签即可对网络进行训练,且网络自主学习正则化参数,进一步减少了对参数的依赖。
技术实现要素:
6.本发明的目的在于针对现有技术上存在的缺陷,提供一种基于无监督神经网络的nmr弛豫时间反演方法。
7.为了实现上述的目的,本发明采用以下技术措施:一种基于无监督神经网络的nmr弛豫时间反演方法,包括以下步骤:步骤1、模拟反演核矩阵k,模拟连续的nmr弛豫时间谱f,模拟噪声,根据计算nmr弛豫信号作为样本,各个样本构成样本集,将样本集分为训练样本集和测试样本集;步骤2、构建无监督神经网络模型,定义无监督神经网络模型的损失函数为:其中,为nmr弛豫信号的个数,为第个nmr弛豫信号,k为反演核矩阵,为第个nmr弛豫信号与对应的第个nmr弛豫时间谱之间的映射关系,为神经网络模型权重,,为第个nmr弛豫信号的标准差,范围在(0,1)区间内,和均是正则化参数,为1
‑
范数;为2
‑
范数的平方;步骤3、将训练样本集中的样本作为无监督神经网络模型的输入,依据损失函数最小,获得nmr弛豫信号与nmr弛豫时间谱的最佳映射关系。
8.如上所述的模拟反演核矩阵k包括以下步骤:预定义回波信号参数,预定义回波信号参数包括回波信号个数以及相邻两个回波信号的采样时间点的间隔;预定义nmr弛豫时间参数,nmr弛豫时间参数包括预定义nmr弛豫时间的范围和个数;根据回波信号参数以及nmr弛豫时间参数计算反演核矩阵k。
9.如上所述的模拟连续的nmr弛豫时间谱f包括以下步骤:通过在对数尺度上随机产生多个具有随机峰半高宽、随机位置和随机相对幅度的高斯函数来模拟连续的nmr弛豫时间谱f,谱峰的半高宽在0.1~1之间,谱峰的位置在各个预定义的nmr弛豫时间的最大值到最小值的范围内变化。
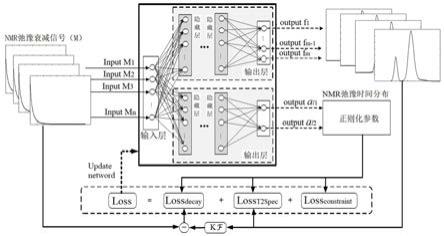
10.如上所述的无监督神经网络模型包括第一子网络和第二子网络,第一子网络包括一个输入层,四个隐藏层和一个输出层;第二子网络包括一个输入层,二个隐藏层和一个输出层;第一子网络和第二子网络共用同一个输入层。
11.如上所述的第一子网络输出层的激活函数为softmax函数;第二子网络的输出层的激活函数为softplus函数。
12.本发明相比于现有技术具有以下有益效果:1、本发明的训练样本无需标记,为采用实验数据作为样本进行训练提供了可能。
13.2、本发明可自动学习出最优的正则化参数,不依赖初始值及人工经验。
14.3、本发明的预测模型,预测速度快,为实时在线监测提供了可能。
附图说明
15.图1为无监督神经网络模型的结构示意图;图2a为模拟的nmr横向弛豫时间谱峰宽较窄的nmr横向弛豫多指数衰减信号;图2b为输入图2a中nmr横向弛豫多指数衰减信号到预测模型,经预测模型预测的nmr横向弛豫时间谱(实线)和对应的模拟连续的nmr横向弛豫时间谱(虚线)的对比图;图3a为模拟的nmr横向弛豫时间谱峰宽较宽的nmr横向弛豫多指数衰减信号;图3b为输入图3a中nmr横向弛豫多指数衰减信号到预测模型,经预测模型预测的nmr横向弛豫时间谱(实线)和对应的模拟连续的nmr横向弛豫时间谱(虚线)的对比图。
具体实施方式
16.为了便于本领域普通技术人员理解和实施本发明,下面结合实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
17.弛豫时间包括横向弛豫时间和纵向弛豫时间,本实施例是以横向弛豫时间为例进行说明,纵向弛豫时间与横向弛豫时间的区别仅在弛豫信号的公式上。横向弛豫信号是衰减信号(随时间减小),而纵向弛豫信号是恢复信号(随时间增大)。纵向弛豫时间t1谱和横向弛豫时间t2谱的反演求解算法在数学原理上是一致的,所以一般在探讨研究多指数反演算法时常以t2为例。所以本实施例以nmr横向弛豫时间t2反演来进行说明。
18.使用模拟的nmr弛豫信号作样本,在本实施例中,nmr弛豫信号为nmr横向弛豫多指数衰减信号。本实施例中,nmr弛豫信号的数学模型如公式(1)所示:
ꢀꢀꢀꢀꢀꢀ
公式(1)其中,是回波采样时间,是nmr弛豫时间,本实施例中,nmr弛豫时间为nmr横向弛豫时间,是nmr弛豫信号强度,在本实施例中,nmr弛豫信号强度为nmr横向弛豫多指数衰减信号强度,是nmr弛豫时间的分布,即对应nmr弛豫时间谱f,本实施例中,nmr弛豫时间谱为nmr横向弛豫时间谱,为噪声。
19.nmr弛豫时间反演,是指给定的一系列值,测量得到一组nmr弛豫信号强度,求解出nmr弛豫时间谱的分布。
20.对上述问题的求解,首先,将公式(1)离散化:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(2)其中,,,
ꢀ
k为反演核矩阵,为nmr弛豫信号,f为连续的nmr弛豫时间谱,为预定义的nmr弛豫时间的个数,j为预定义的nmr弛豫时间的序号,为第j个预定义的nmr弛豫时间,为回波信号的总个数,为回波信号的序号,为第j个预定义nmr弛豫时间所对应的幅值,为第个回波的采样时间。为第个回波信号强度,是多个单指数回波信号强度的叠加,本实施例中,单指数回波信号强度为单指数衰减回波信号强度。
21.然后,求解到之间的映射关系,如公式3所示。
22.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(3)本发明提出的反演方法是通过无监督的深度神经网络来实现的,无监督神经网络模型可表示为以下公式:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(3)nmr弛豫信号为无监督神经网络模型的输入;nmr弛豫时间谱为无监督神经网络模型的输出;为无监督神经网络模型的权重;为nmr弛豫信号与nmr弛豫时间谱之间的映射关系。
23.一种基于无监督神经网络的nmr弛豫时间反演方法,包括以下步骤:步骤1、训练样本集合测试样本集准备模拟的nmr弛豫信号作样本,本实施例中,nmr弛豫信号为nmr横向弛豫多指数衰减信号,样本的生成具体如下:1)模拟反演核矩阵k:预定义回波信号参数,具体为:预定义回波信号个数为2048,te为0.2ms,即回波信号的采样时间点数为2048个,相邻两个回波信号的采样时间点的间隔为0.2ms;预定义nmr弛豫时间参数,本实施例中,nmr弛豫时间为nmr横向弛豫时间,具体为:预定义nmr弛豫时间的个数为128,即在nmr弛豫时间范围0.1ms
‑
1000ms内对数布点128个预定义的nmr弛豫时间;根据上述设置的回波信号参数以及nmr弛豫时间参数计算反演核矩阵k。
24.2)模拟连续的nmr弛豫时间谱,本实施例中,nmr弛豫时间谱为nmr横向弛豫时间谱:通过在对数尺度上随机产生4个具有随机峰半高宽(the full width half maxima)、随机位置和随机相对幅度的高斯函数来模拟连续的nmr弛豫时间谱f。谱峰的半高宽在0.1~1之间,谱峰的位置在上述128个预定义的nmr弛豫时间的最大值到最小值的范围内变
化;谱峰的幅度进行归一化处理。
25.3)模拟噪声(信噪比在10~80随机产生),噪声为瑞利噪声,根据即可计算出含噪声的nmr弛豫信号作为样本,各个样本构成样本集,将样本集分为训练样本集和测试样本集。
26.在本实施例中,在训练样本集中的样本的总数为50000。
27.步骤2、建立无监督深度神经网络模型本实施例建立的无监督神经网络模型由两个子网络组成,分别为第一子网络和第二子网络。如图1所示,第一子网络包括一个输入层,四个隐藏层和一个输出层;第二子网络包括一个输入层,二个隐藏层和一个输出层。第一子网络和第二子网络共用同一个输入层,输入层神经元个数为2048。第一子网络每个隐藏层均有2048个神经元,输出层的神经元为128。第二子网络每个隐藏层均有2048个神经元,输出层的神经元个数为2。第一子网络和第二子网络的隐藏层的激活函数均为线性整流函数(rectified linear unit, relu)。第一子网络输出层的激活函数为softmax函数;第二子网络的输出层的激活函数为softplus函数。
28.无监督神经网络训练过程即是最小化预定义的损失函数以确定神经网络模型权重的过程。
29.本实施例建立的无监督神经网络模型的预定义损失函数为:其中,为nmr弛豫信号的个数,为第个nmr弛豫信号,k为反演核矩阵,为第个nmr弛豫信号与对应的第个nmr弛豫时间谱之间的映射关系,为神经网络模型权重, ,为第个nmr弛豫信号的标准差,范围在(0,1)区间内。和均是正则化参数,第二子网络的输出结果,为1
‑
范数;为2
‑
范数的平方。
30.损失函数中第一项:为nmr弛豫信号保真度损失项。保真度损失是根据前向物理模型和数据噪声特性定义。保真项,用来约束网络输出与测量数据的一致性。
31.损失函数中第二项:为网络输出的nmr弛豫时间谱的连续性约束项。
32.损失函数中第三项:为正则化参数项,是损失函数第一项与第二项的平衡项。
33.步骤3、无监督神经网络模型训练将训练样本集中的样本作为无监督神经网络模型的输入,对步骤2中建立的无监
督神经网络模型进行训练,自学习最佳的正则参数和,自学习nmr弛豫信号与nmr弛豫时间谱的最佳映射关系。对于训练样本集中所有的样本,损失函数最小,即得到最佳的映射关系。训练完成的无监督神经网络模型,称之为预测模型t2inversion
‑
utd。
34.本实施例中,对无监督神经网络模型训练前,无监督神经网络模型的超参数的设置如下:学习的批次大小为2;输入层、各个隐藏层和最后的输出层的初始偏置矢量均为零,迭代回合(epoch)为2000。迭代算法采用的是自适应矩估计算法(adam),学习率为1e
‑
5。
35.步骤4、反演将测试样本集中的样本输入到步骤3中学习得到的预测模型t2inversion
‑
utd中进行预测,输出对应的计算nmr弛豫时间谱。
36.图2a为模拟的nmr横向弛豫时间谱峰宽较窄的nmr横向弛豫多指数衰减信号;图3a为模拟的nmr横向弛豫时间谱峰宽较宽的nmr横向弛豫多指数衰减信号;图2b为输入图2a中nmr横向弛豫多指数衰减信号到预测模型,经预测模型预测的nmr横向弛豫时间谱(实线)和对应的模拟连续的nmr横向弛豫时间谱(虚线)的对比图;图3b为输入图3a中nmr横向弛豫多指数衰减信号到预测模型,经预测模型预测的nmr横向弛豫时间谱(实线)和对应的模拟连续的nmr横向弛豫时间谱(虚线)的对比图。图2a中模拟的nmr横向弛豫衰减信号是nmr横向弛豫时间谱峰宽较窄的信号,图3a中模拟的nmr横向弛豫衰减信号是nmr横向弛豫时间谱峰宽较宽的信号。
37.从实验结果可以看出,本发明方法在一定信噪比条件下,能较好地确定nmr横向弛豫时间谱峰的宽度和位置。
38.在配有gtx1080ti的计算机上, 对测试样本集中的629个样本进行预测,总的预测时间为1.03125s,一个样本的预测时间为1.6395ms。
39.本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。