技术特征:
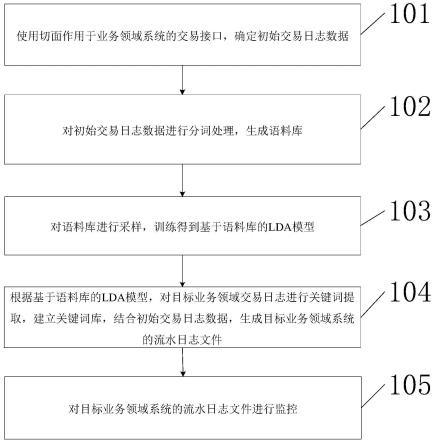
1.一种日志生成监控方法,其特征在于,包括:使用切面作用于业务领域系统的交易接口,确定初始交易日志数据;对初始交易日志数据进行分词处理,生成语料库;对语料库进行采样,训练得到基于语料库的lda模型;根据基于语料库的lda模型,对目标业务领域交易日志进行关键词提取,建立关键词库,结合初始交易日志数据,生成目标业务领域系统的流水日志文件;对目标业务领域系统的流水日志文件进行监控。2.如权利要求1所述的方法,其特征在于,使用切面作用于业务系统的交易接口,确定初始交易日志数据,包括:使用切面算法创建切面类,作用于全部业务领域系统的交易接口,获取交易参数详情;根据交易参数详情,生成初始交易日志数据。3.如权利要求1所述的方法,其特征在于,对初始交易日志数据进行分词处理,生成语料库,包括:获取设定时长内的初始交易日志数据;对设定时长内的初始交易日志数据进行交易参数字段名提取;对提取到的交易参数字段名使用分词工具进行英文分词操作,生成语料库。4.如权利要求1所述的方法,其特征在于,对语料库进行采样,训练得到基于语料库的lda模型,包括:采用gibbs采样算法对语料库进行采样,在采样收敛后确定每个词的主题;根据每个词的主题,训练得到基于语料库的lda模型。5.如权利要求4所述的方法,其特征在于,采用gibbs采样算法对语料库进行采样,在采样收敛后确定每个词的主题,包括:确定主题数目和超参向量;随机为语料库中每一个语料的每一个词赋予一个主题编号;重新扫描语料库,对于每一个词,利用gibbs采样公式重新采样更新该词的主题编号,并且更新该词在语料中的编号;重复执行采样更新,直至采样收敛,确定语料库中每个词的主题。6.如权利要求5所述的方法,其特征在于,根据每个词的主题,训练得到基于语料库的lda模型,包括:统计语料库中每个语料每个词的主题编号,得到文档-主题分布参数;统计语料库中各个主题-词的分布,获取lda模型的主题-词分布参数;根据文档-主题分布参数,确定语料库中文档的主题分布;根据lda模型的主题-词分布参数,确定语料库中每个主题的词分布;根据语料库中文档的主题分布和语料库中每个主题的词分布对lda主题模型进行训练,得到基于语料库的lda模型。7.如权利要求1所述的方法,其特征在于,根据基于语料库的lda模型,对目标业务领域交易日志进行关键词提取,建立关键词库,结合初始交易日志数据,生成目标业务领域系统的流水日志文件,包括:根据基于语料库的lda模型,建立基于lda的s-lda关键词提取算法;
根据基于lda的s-lda关键词提取算法,对目标业务领域交易日志进行关键词提取,建立关键词库;根据关键词库和初始交易日志数据,生成目标业务领域系统的流水日志文件。8.如权利要求7所述的方法,其特征在于,根据基于语料库的lda模型,建立基于lda的s-lda关键词提取算法,包括:根据给定的文本文件集,构建模型训练所需的训练语料库,利用基于语料库的lda模型对训练语料库进行训练得到lda模型;根据目标文本文件,构建目标语料,采用gibbs采样算法预测得到目标语料的主题分布;对目标文本文件的主题进行过滤,得到过滤后的主题集;对主题集的主题对应在目标文本文件主题分布中的比重构建主题的选词权重,按照主题分布从大到小的概率顺序,依次从每个主题中选出设定数量的词,并保持选出的词出现的先后顺序构建关键词候选词集合;对关键词候选词集合进行过滤,确定目标文本文件的关键词。9.如权利要求8所述的方法,其特征在于,对目标文本文件的主题进行过滤,得到过滤后的主题集,包括:设定第一辅助向量;计算目标文本文件中各个主题的词分布与第一辅助向量的相似度,确定第一js散度值;当第一js散度值小于第一设定散度阈值时,将当前主题从目标文本文件的主题分布中删除,得到过滤后的主题集。10.如权利要求8所述的方法,其特征在于,对关键词候选词集合进行过滤,确定目标文本文件的关键词,包括:设定第二辅助向量;计算关键词候选词集合中每一个候选词的主题分布与第二辅助向量的相似度,确定第二js散度值;当第二js散度值小于第二设定散度阈值时,将当前候选词从关键词候选词集合中删除,从剩余的关键词候选词集合中选取词性为名词或动词、在目标文本中出现且排名前s名的候选词作为目标文本文件的关键词;所述排名前s名的候选词,是按照候选词出现频率进行从大到小的排序,取排序前s个候选词所得。11.如权利要求7所述的方法,其特征在于,根据基于lda的s-lda关键词提取算法,对目标业务领域交易日志进行关键词提取,建立关键词库,包括:对目标业务领域交易日志进行分词处理;采用基于lda的s-lda关键词提取算法,对分词处理后的目标业务领域交易日志进行关键词提取,建立关键词库。12.如权利要求7所述的方法,其特征在于,根据关键词库和初始交易日志数据,生成目标业务领域系统的流水日志文件,包括:依次取关键词库中的每个关键词,从初始交易日志数据中查询出关键词对应的值,生成目标业务领域系统的流水日志文件。
13.如权利要求1所述的方法,其特征在于,对目标业务领域系统的流水日志文件进行监控,包括:针对生成的目标业务领域系统的流水日志文件,按照关键词进行监控,实时获取目标业务领域系统的运行状态信息。14.一种日志生成监控装置,其特征在于,包括:初始交易日志数据确定模块,用于使用切面作用于业务领域系统的交易接口,确定初始交易日志数据;语料库生成模块,用于对初始交易日志数据进行分词处理,生成语料库;基于语料库的lda模型训练模块,用于对语料库进行采样,训练得到基于语料库的lda模型;流水日志文件生成模块,用于根据基于语料库的lda模型,对目标业务领域交易日志进行关键词提取,建立关键词库,结合初始交易日志数据,生成目标业务领域系统的流水日志文件;流水日志文件监控模块,用于对目标业务领域系统的流水日志文件进行监控。15.如权利要求14所述的装置,其特征在于,初始交易日志数据确定模块,具体用于:使用切面算法创建切面类,作用于全部业务领域系统的交易接口,获取交易参数详情;根据交易参数详情,生成初始交易日志数据。16.如权利要求14所述的装置,其特征在于,语料库生成模块,具体用于:获取设定时长内的初始交易日志数据;对设定时长内的初始交易日志数据进行交易参数字段名提取;对提取到的交易参数字段名使用分词工具进行英文分词操作,生成语料库。17.如权利要求14所述的装置,其特征在于,基于语料库的lda模型训练模块,用于:采用gibbs采样算法对语料库进行采样,在采样收敛后确定每个词的主题;根据每个词的主题,训练得到基于语料库的lda模型。18.如权利要求17所述的装置,其特征在于,基于语料库的lda模型训练模块,还用于:确定主题数目和超参向量;随机为语料库中每一个语料的每一个词赋予一个主题编号;重新扫描语料库,对于每一个词,利用gibbs采样公式重新采样更新该词的主题编号,并且更新该词在语料中的编号;重复执行采样更新,直至采样收敛,确定语料库中每个词的主题。19.如权利要求18所述的装置,其特征在于,基于语料库的lda模型训练模块,还用于:统计语料库中每个语料每个词的主题编号,得到文档-主题分布参数;统计语料库中各个主题-词的分布,获取lda模型的主题-词分布参数;根据文档-主题分布参数,确定语料库中文档的主题分布;根据lda模型的主题-词分布参数,确定语料库中每个主题的词分布;根据语料库中文档的主题分布和语料库中每个主题的词分布对lda主题模型进行训练,得到基于语料库的lda模型。20.如权利要求14所述的装置,其特征在于,流水日志文件生成模块,具体用于:根据基于语料库的lda模型,建立基于lda的s-lda关键词提取算法;
根据基于lda的s-lda关键词提取算法,对目标业务领域交易日志进行关键词提取,建立关键词库;根据关键词库和初始交易日志数据,生成目标业务领域系统的流水日志文件。21.如权利要求20所述的装置,其特征在于,流水日志文件生成模块,还用于:根据给定的文本文件集,构建模型训练所需的训练语料库,利用基于语料库的lda模型对训练语料库进行训练得到lda模型;根据目标文本文件,构建目标语料,采用gibbs采样算法预测得到目标语料的主题分布;对目标文本文件的主题进行过滤,得到过滤后的主题集;对主题集的主题对应在目标文本文件主题分布中的比重构建主题的选词权重,按照主题分布从大到小的概率顺序,依次从每个主题中选出设定数量的词,并保持选出的词出现的先后顺序构建关键词候选词集合;对关键词候选词集合进行过滤,确定目标文本文件的关键词。22.如权利要求21所述的装置,其特征在于,流水日志文件生成模块,还用于:设定第一辅助向量;计算目标文本文件中各个主题的词分布与第一辅助向量的相似度,确定第一js散度值;当第一js散度值小于第一设定散度阈值时,将当前主题从目标文本文件的主题分布中删除,得到过滤后的主题集。23.如权利要求21所述的装置,其特征在于,流水日志文件生成模块,还用于:设定第二辅助向量;计算关键词候选词集合中每一个候选词的主题分布与第二辅助向量的相似度,确定第二js散度值;当第二js散度值小于第二设定散度阈值时,将当前候选词从关键词候选词集合中删除,从剩余的关键词候选词集合中选取词性为名词或动词、在目标文本中出现且排名前s名的候选词作为目标文本文件的关键词;所述排名前s名的候选词,是按照候选词出现频率进行从大到小的排序,取排序前s个候选词所得。24.如权利要求20所述的装置,其特征在于,流水日志文件生成模块,还用于:对目标业务领域交易日志进行分词处理;采用基于lda的s-lda关键词提取算法,对分词处理后的目标业务领域交易日志进行关键词提取,建立关键词库。25.如权利要求20所述的装置,其特征在于,流水日志文件生成模块,还用于:依次取关键词库中的每个关键词,从初始交易日志数据中查询出关键词对应的值,生成目标业务领域系统的流水日志文件。26.如权利要求14所述的装置,其特征在于,流水日志文件监控模块,具体用于:针对生成的目标业务领域系统的流水日志文件,按照关键词进行监控,实时获取目标业务领域系统的运行状态信息。27.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至13任一项所述
方法。28.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现权利要求1至13任一所述方法。29.一种计算机程序产品,其特征在于,所述计算机程序产品包括计算机程序,所述计算机程序被处理器执行时实现权利要求1至13任一所述方法。
技术总结
本发明提供了一种日志生成监控方法和装置,属于大数据,该方法包括:使用切面作用于业务领域系统的交易接口,确定初始交易日志数据;对初始交易日志数据进行分词处理,生成语料库;对语料库进行采样,训练得到基于语料库的LDA模型;根据基于语料库的LDA模型,对目标业务领域交易日志进行关键词提取,建立关键词库,结合初始交易日志数据,不用人力去分析和确定各业务领域的流水日志标准,自动生成目标业务领域系统的流水日志文件,有效降低人力成本,针对目标业务领域系统的流水日志文件进行监控,可以实时获取系统的运行状态,提高流水日志监控的准确性,保障系统运行安全。保障系统运行安全。保障系统运行安全。
技术研发人员:张馨
受保护的技术使用者:中国银行股份有限公司
技术研发日:2022.03.15
技术公布日:2022/6/10
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。