1.本发明涉及工业缺陷检测领域,尤其是一种基于深度学习的自动化工业缺陷检测系统及装置。
背景技术:
2.在现代工业制造领域中,生产物件缺陷检测的准确性和自动化程度对质量控制起着至关重要的作用。
3.随着深度学习技术的发展和计算机算力的提升,基于大数据背景,挖掘工业缺陷数据内部的深层特征与内在联系,构建精度高、泛化性强的模型成为了可能。
4.当前,基于实例分割深度学习算法在目标检测领域已取得较高精度,相较于传统算法具有极大优势,目前已逐渐在工业智能制造领域中投入缺陷检测使用。但由于工业制造领域的缺陷形态多变,实际应用中常面临检测精度不足,不同生产线在生产初期由于所收集的样本不足,漏检、误检现象普遍存在;同时,由于人工判例的主观性,经常需要对缺陷类别进行拆分或合并,而由于模型算法训练时已将类别进行固定,因此算法验证时与人工判断往往存在缺陷类别上的出入;此外,由于mask-rcnn算法结构较为复杂,在算法部署与产品交付方面,算法理论与工业生产还存在一定的落地障碍。
技术实现要素:
5.本发明提供一种基于深度学习的自动化工业缺陷检测系统及装置,以至少解决由于所收集的样本不足,对形状、尺度不一的各类缺陷检测精度不佳,导致漏检、误检、效率低的问题。
6.本发明提供了一种基于深度学习的自动化工业缺陷检测系统,包括:特征提取模块,所述特征提取模块包括以下提取步骤:
7.s1,自下而上提取原始图片各阶段的特征图,生成数据集,设数据集为{c2,c3,c4,c5}时;
8.s2,自上而下进行采样,对{c2,c3,c4,c5}分别使用256个n*n的卷积运算,提取到{f2,f3,f4,f5}特征;
9.s3,再次采用n*n的卷积核进行特征提取,f2特征采用n*n卷积核提取出p2特征,同时用n*n卷积核处理f3特征,将f3处理后的特征与p2融合并进行下采样操作,得到p3特征,以此类推自下而上链路产生出{p2,p3,p4,p5}特征;
10.s4,用k*k卷积核提取出{s2,s3,s4,s5}特征,最后对s5进行最大池化操作得到s6;最终所有特征图构成集合{s2,s3,s4,s5,s6};
11.所述k值大于n。
12.进一步地,所述系统还包括:数据增广模块;
13.所述数据增广模块是在实际生产过程中随机采集产品图像;
14.所述数据增广是通过常数配置实现。
15.更进一步地,所述数据增广模块包括:图像随机翻转、图像随机裁剪、图像随机亮度、图像随机对比度、图像随机饱和度、图像随机旋转方法中的一种或多种。
16.进一步地,所述系统的模型训练包括:正则化项的模型训练;
17.设网络损失为l
rpn
,全连接损失为l
fc
,mask branch损失为l
mask
,在此基础上,模型的总损失为
18.l=l
rpn
l
fc
l
mask
,
19.设cnn提取出的权重为w,则增添l2正则项,有
[0020][0021]
l2范数作为惩罚项,其中n为样本总数,k为大于0的超参数,基于总损失进行模型端到端训练。
[0022]
进一步地,所述系统设有类别拆分-合并后处理模块,所述类别拆分-合并后处理模块进行类别校正。
[0023]
更进一步地,所述图像随机裁剪,为给定图像的随机裁剪值,按随机裁剪值进行裁剪增广,生成新的图像;
[0024]
所述图像随机亮度,为给定随机权重最小值w_min、最大值w_max;
[0025]
通过正态分布在最大最小权重值之中获取随机权重值
[0026]
w=random.uniform(w_min,w_max).
[0027]
计算
[0028]
dst_img=w*ori_img,
[0029]
dst_img=clip(dst_img,0,255).
[0030]
其中clip操作将超出0或255的图像亮度值约束回阈值范围。
[0031]
更进一步地,所述图像随机对比度为给定随机权重最小值w_min、最大值w_max;
[0032]
首先通过正态分布在最大最小权重值之中获取随机权重值
[0033]
w=random.uniform(w_min,w_max).
[0034]
计算
[0035]
dst_img=w*mean(ori_img) (1-w)*ori_img,
[0036]
dst_img=clip(dst_img,0,255)。
[0037]
所述图像随机饱和度为给定随机权重最小值w_min、最大值w_max。
[0038]
首先通过正态分布在最大最小权重值之中获取随机权重值
[0039]
w=random.uniform(w_min,w_max).
[0040]
计算
[0041]
grayscale=dot(ori_img,[0.299,0.587,0.114]),
[0042]
dst_img=w*grayscale (1-w)*ori_img,
[0043]
dst_img=clip(dst_img,0,255).
[0044]
其中[0.299,0.587,0.114]为rgb图像在灰度图像中相应的视觉转换系数,grayscale为原始图像的灰度图。
[0045]
进一步地,所述数据增广为图像随机旋转,
[0046]
所述图像随机旋转为给定旋转角,通过旋转角度和原始图像生成纺射矩阵,计算
后获得旋转后图像。
[0047]
进一步地,所述系统采用rpn网络,所述rpn网络生成候选区域,并将这些区域映射到特征图;
[0048]
所述系统使用roialign进行像素对齐,用于提取mask掩码。
[0049]
本发明另一方面提供一种基于深度学习的自动化工业缺陷检测装置,所述装置应用上述一种基于深度学习的自动化工业缺陷检测系统。
[0050]
本发明相对于现有技术由于改进系统算法,解决实际工业生产中数据不足,缺陷类型表征不够丰富,样本类别不平衡的问题,减轻模型过拟合,提升模型泛化性能,提高检测效率。
附图说明
[0051]
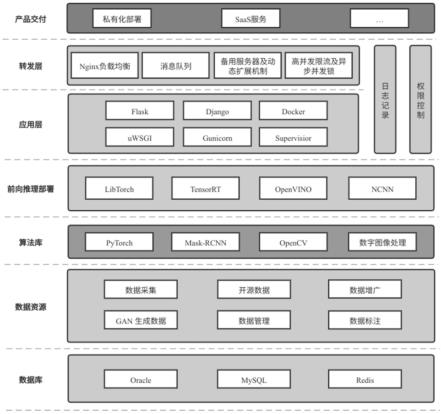
图1为本发明架构图;
[0052]
图2为cnn处理 fpn组合提取特征顺序图。
具体实施方式
[0053]
为了使本技术领域的人员更好地理解本发明方案,下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。
[0054]
本实施例公开的基于深度学习的自动化工业缺陷检测系统,所述系统包括:数据增广模块;
[0055]
所述数据增广模块是在实际生产过程中随机采集产品图像;
[0056]
所述数据增广是通过常数配置实现。
[0057]
其中,所述数据增广模块包括:图像随机翻转、图像随机裁剪、图像随机亮度、图像随机对比度、图像随机饱和度、图像随机旋转方法中的一种或多种。
[0058]
本实施例中常数配置包括:是否对各类别缺陷图像进行数据增广,数据增广概率;以及对于该批数据,将选择多少占比用于模型训练,剩余占比的数据用于模型测试;
[0059]
以常规数据增广为例,给定随机增广概率p,设原始图像为ori_img,宽和高分别为w和h,新生成的图像为dst_img。
[0060]
本实施例中数据增广功能,对不同类别缺陷数据进行扩充,动态增加训练数据样本库,解决工业缺陷检测领域中数据不足问题。
[0061]
优选的,数据增广可采用图像随机翻转;
[0062]
随机翻转方法是根据随机增广概率,对于每张传入的图片,进行图像水平或垂直翻转。
[0063]
优选的,所述数据增广为图像随机裁剪;
[0064]
所述图像随机裁剪方法为给定图像的随机裁剪值,按随机裁剪值进行裁剪增广,生成新的图像。
[0065]
具体的,若给定的是裁剪值为概率值α(0-1之间的数值),若对其进行裁剪增广,则将生成新的图像
[0066]
dst_img=randomcrop(ori_img,new_size=[w*α,h*α].
[0067]
若给定的是裁剪值为整数数组
[0068]
l=[l1,l2,...,lmax],
[0069]
若对其进行裁剪增广,则将在l中随机选择一个值ln,作为新图像的最短边,对图像进行拉伸,即
[0070]
dst_img=imageresize(ori_img,new_size=[ln,max(w,h)]。
[0071]
优选的,所述数据增广为图像随机亮度;
[0072]
具体的,所述图像随机亮度方法为给定随机权重最小值w_min、最大值w_max;
[0073]
通过正态分布在最大最小权重值之中获取随机权重值
[0074]
w=random.uniform(w_min,w_max).
[0075]
计算
[0076]
dst_img=w*ori_img,
[0077]
dst_img=clip(dst_img,0,255).
[0078]
其中clip操作将超出0或255的图像亮度值约束回阈值范围。
[0079]
优选的,所述数据增广为图像随机对比度;
[0080]
具体的,所述图像随机对比度方法为给定随机权重最小值w_min、最大值w_max;
[0081]
首先通过正态分布在最大最小权重值之中获取随机权重值
[0082]
w=random.uniform(w_min,w_max).
[0083]
计算
[0084]
dst_img=w*mean(ori_img) (1-w)*ori_img,
[0085]
dst_img=clip(dst_img,0,255)。
[0086]
优选的,所述数据增广为图像随机饱和度;
[0087]
具体的,所述图像随机饱和度方法为给定随机权重最小值w_min、最大值w_max。
[0088]
首先通过正态分布在最大最小权重值之中获取随机权重值
[0089]
w=random.uniform(w_min,w_max).
[0090]
计算
[0091]
grayscale=dot(ori_img,[0.299,0.587,0.114]),
[0092]
dst_img=w*grayscale (1-w)*ori_img,
[0093]
dst_img=clip(dst_img,0,255).
[0094]
其中[0.299,0.587,0.114]为rgb图像在灰度图像中相应的视觉转换系数,grayscale为原始图像的灰度图。
[0095]
优选的,所述数据增广为图像随机旋转;
[0096]
所述图像随机旋转方法为给定旋转角,通过旋转角度和原始图像生成纺射矩阵,计算后获得旋转后图像。
[0097]
具体的,若通过choice类型确定旋转角,则需给定一组旋转角
[0098]
angles=[ang1,ang2,...,angk],
[0099]
该方法将从数组中随机选择一个角度angle作为旋转角。
[0100]
若通过range类型确定旋转角,则需给定最小和最大旋转角ang_min和ang_max,然后采用正态分布random.uniform(ang_min,ang_max)生成一个随机旋转角度angle。
[0101]
根据旋转角度angle和原始图像生成纺射矩阵mat,然后计算仿射变化公式,所得
结果即为旋转后的图像:
[0102]
dst_img=warpaffine(ori_img,mat,(w,h))。
[0103]
优选的,所述系统包括:特征提取模块,如图2所示,所述特征提取模块包括以下提取步骤:
[0104]
s1,自下而上提取原始图片各阶段的特征图,生成数据集,设数据集为{c2,c3,c4,c5}时;
[0105]
s2,自上而下进行采样,对{c2,c3,c4,c5}分别使用256个n*n的卷积运算,提取到{f2,f3,f4,f5}特征;
[0106]
s3,再次采用n*n的卷积核进行特征提取,f2特征采用n*n卷积核提取出p2特征,同时用n*n卷积核处理f3特征,将f3处理后的特征与p2融合并进行下采样操作,得到p3特征,以此类推自下而上链路产生出{p2,p3,p4,p5}特征;
[0107]
s4,用k*k卷积核提取出{s2,s3,s4,s5}特征,最后对s5进行最大池化操作得到s6;最终所有特征图构成集合{s2,s3,s4,s5,s6};
[0108]
所述k值大于n。
[0109]
以cnn fpn为例,传统的cnn fpn处理策略,首先使用resnet-101网络自下而上提取原始图片各阶段的特征图,生成{c2,c3,c4,c5},再通过fpn网络自上而下进行特征图上采样和横向连接,具体地,以p5和p4为例,首先对c5使用256个1*1的卷积运算得到f5,然后对f5进行256个3*3的卷积运算得到p5,然后将对f5进行两倍上采样得到的结果与c4经过256个1*1卷积运算得到的结果相加,得到f4,再将f4进行256个3*3卷积计算得到p4;使用同样的方法计算得到p2和p3;最后对p5进行最大池化操作,得到p6;最终所有特征图构成集合{p2,p3,p4,p5,p6}。
[0110]
本实施例如图2所示,当自上而下的特征提取链路提取到{f2,f3,f4,f5}特征时,再次采用1*1的卷积核进行特征提取,进行上下层特征融合后再进行下采样操作。
[0111]
例如,对于f2特征,首先采用1*1卷积核提取出p2特征,同时用1*1卷积核处理f3特征,将f3处理后的特征与p2融合并进行下采样操作,得到p3特征,以此类推自下而上链路产生出{p2,p3,p4,p5}特征,然后再用3*3卷积核提取出{s2,s3,s4,s5}特征,最后对s5进行最大池化操作得到s6;最终所有特征图构成集合{s2,s3,s4,s5,s6}。
[0112]
本实施例基于工业制造领域中缺陷形态各异、尺寸不一的问题,在传统cnn处理 fpn组合提取特征的基础上,如图2虚线部分所示,增加了自下而上的特征提取链路,旨在充分利用多尺度特征信息,以解决形状、尺度不一的各类缺陷检测精度不佳的问题。
[0113]
优选的,所述系统选用rpn网络,所述rpn网络生成候选区域(region proposals),并将这些区域映射到特征图;
[0114]
具体的,将特征图{p2,p3,...,p6}输入rpn网络,然后使用256个3*3滑动窗口进行处理,滑动窗口在每个位置都会生成尺寸为{8,16,32,64,128}和宽高比为{0.5,1,2}的15个anchors。滑动窗口处理后,特征图会被映射为256维,然后输入全连接层,全连接层包含一个回归层和一个分类层,其中回归层对anchor的中心点坐标和边长进行回归,作为region proposal的位置信息;而分类层则用于判断anchor中是否包含缺陷。在此过程中将生成大量region proposals,最终将使用非极大值抑制算法(nms)过滤冗余区域。
[0115]
rpn在训练过程中,会为每个anchor分配一个它是否是缺陷的标签,该标签通过计
proposals的修正参数,q为真实的修正参数。
[0137]
l
cls
(p,g)=-log(pg),
[0138][0139]
其中yg和q的计算方式类似rpn中的损失函数。
[0140]
可选的,映射特征图的分割。
[0141]
将roialign输出的region proposals映射特征图输入mask分割网络预测分割掩膜。首先将特征图通过4层256个3*3的卷积计算,再将计算结果输出到反卷积层进行上采样操作,得到每个像素归属于各个类别,缺陷类别或背景的置信度,将最大置信度对应的类别作为最终的分割结果。
[0142]
mask branch使用的损失函数为:
[0143]
l
mask
=sigmoid[km2]1,
[0144]
对应每个region proposal,分割网络将输出k*m*m维向量,其中k为类别数,m为特征图的尺寸。
[0145]
优选的,检测系统模型训练包括:正则化项的模型训练;
[0146]
具体的,可选cnn特征提取网络,设上文提出的rpn网络损失为lrpn,全连接损失为lfc,mask branch损失为lmask,在此基础上,模型的总损失为
[0147]
l=l
rpn
l
fc
l
mask
,
[0148]
设cnn提取出的权重为w,则增添l2正则项,有
[0149][0150]
即增加l2范数作为惩罚项,其中n为样本总数,k为大于0的超参数,基于总损失进行模型端到端训练。
[0151]
本实施例在cnn特征提取网络上,增加了l2正则项进行权重衰减,减轻模型过拟合现象。
[0152]
优选的,所述系统设有类别拆分-合并后处理模块,所述类别拆分-合并后处理模块进行类别校正。
[0153]
处理过程伪代码如下。
[0154]
/*
[0155]
设算法判例结果变量为labels
[0156]
设人工判例合并规则为map_concat
[0157]
设人工判例拆分规则为map_split
[0158]
设判例结果类别映射到缺陷标准编码的规则为map_code
[0159]
*/
[0160]
label_concat=[map_concat(label)for label in labels]
[0161]
label_split=[map_split(label)for label in label_concat]
[0162]
label_std_code=[map_code(label)for label in label_split]
[0163]
本实施例在算法后处理模块增加了类别拆分-合并功能进行类别校正,解决现有
技术模型算法训练时已将类别进行固定,使用时无法对缺陷类别进行拆分或合并的问题,减轻类别判断不一致的情况,应用更灵活、合理。
[0164]
可选的,模型部署。
[0165]
模型训练完毕后,将生成本地模型文件,加载模型后调用网络前向计算,即可传入图片计算缺陷检测。基于不同的计算设备可选用不同的前向推理框架,包括libtorch、常规服务器端与pc计算平台;tensorrt、一般用于带有gpu的服务器;openvino、一般用于仅带有intel cpu的服务器;ncnn、一般用于端侧设备等。
[0166]
接口服务部署方面,对于生产模式,底层均为采用基于uwsgi协议的flask supervisior的restful风格的web接口,可选用gunicorn或django处理一般应用或需要强自定义的场景,并通过nginx和消息队列等工具优化服务性能和增强服务异步拓展性,处理高并发场景。
[0167]
本实施例公开了一种应用基于深度学习的自动化工业缺陷检测系统的装置。
[0168]
本实施例架构,如图1所示,底层可选关系型数据库oracle、mysql用于存储图像数据及其相关的信息数据,存储算法服务运行期间所需的缓存信息可选用redis;数据部分从业务生产线和开源领域等收集真实图像数据,可采用数据增广进行扩充,也可选用对抗生成网络(gan)等技术合成数据进行扩充,增强模型泛化能力,经过统一的数据管理平台分配与整合,进行数据标注,本实施例优选数据增广进行动态扩充。
[0169]
在算法架构层面,主要基于pytorch和改进的mask-rcnn框架进行一站式模型训练与优化,并基于opencv库和传统的数字图像处理算法进行图像数据的前后处理;对于模型前向推理部署,使用libtorch、tensorrt、openvino、ncnn等框架将算法模型部署在不同硬件设备端(传统服务器、端侧设备)和不同算力设备(cpu、gpu)之上。对于算法服务,接口搭建基于restful风格框架进行封装,整体底层基于uwsgi架构,使用gunicorn或django提供持续化的生产服务,并通过nginx和消息队列等工具优化服务性能和增强服务异步拓展性;产品交付方面,可提供私有化部署、saas服务等交付形式,并可通过docker工具实现低成本的快速产品交付。
[0170]
检测效果对比:
[0171]
基于某批电子元件的实际生产数据(共2000张图,包含ng与ok图),将其按本发明所提策略进行标注,并按7:3的比例划分为训练集和测试集训练,本发明所提改进的mask-rcnn算法、常规的mask-rcnn算法、otsu hog svm、otsu sift svm共4组算法,使用检出率、过检率、map指标计算测试集精度,得到如下结果:
[0172]
算法检出率过检率map本发明改进的mask-rcnn99.32%0.18%91.21%mask-rcnn96.69%0.67%82.18%otsu hog svm86.4%3%60.93%otsu sift svm80.13%3.5%62.21%
[0173]
本发明使用的mask-rcnn算法采用resnet-101作为backbone,并使用特征金字塔网络(feature pyramid networks,fpn)作为neck进行特征提取,同时改进fpn部分进行上下文尺度特征融合,充分利用多尺度信息;通过区域建议网络(region proposal networks,rpn)提取候选区域roi,使用roialign方法进行像素对齐,最终与全连接层
(fcn)、掩膜分支(mask branch)相连接,并在训练过程中增加正则化项;最后,在算法后处理方面,增加类别合并-拆分策略,得到最终的分类与实例分割结果。具有以下特点:
[0174]
(1)检测算法在mask-rcnn的基础上,改进其特征提取网络,增加自下而上特征融合策略提取多尺度特征,以解决形状、尺度不一的各类缺陷检测精度不佳的问题;同时在训练过程中增加正则化项,以减轻模型过拟合现象。
[0175]
(2)针对工业缺陷检测领域中数据不足,缺陷类型表征不够丰富的问题,提出数据增广组合策略,以动态增加训练数据样本库,以端到端形式训练工业缺陷检测模型。
[0176]
(3)在检测后处理方面,提出一种类别合并-拆分的策略,以减轻人工判图主观性与算法检测结果之间的误差。
[0177]
(4)针对mask-rcnn部署困难的现象,经反复实践后提出一套行之有效的部署方案,选用libtorch、tensorrt、openvino或ncnn等不同前向推理框架适配不同硬件平台,并采用flask nginx gunicorn框架和异步技术进行模型服务部署。
[0178]
最后应当说明的是,以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解,技术人员阅读本技术说明书后依然可以对本发明的具体实施方式进行修改或者等同替换,但这些修改或变更均未脱离本发明申请待批权利要求保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。