1.本发明涉及机载语音信号处理领域,更为具体的,涉及一种机载环境下多输入语音信号波束形成信息互补方法。
背景技术:
2.超短波通信系统在飞行任务过程中,由于飞机的多天线空域覆盖不全、超短波的绕射能力差、飞机系统中存在的电磁干扰等诸多原因,导致存在语音信号断续的问题,目前针对该问题的现有解决方案主要有选择合并方法方案、等增益合并方法方案和麦克风阵列波束形成方法方案等。
3.选择合并方法方案属于分集合并方案中的一种合并方法,它通过选择性能最好的一条通道进行输出,但选择合并仅输出一路信号,这样会导致信息丢失。其问题可参阅图1,和图1中问题相似。即以四天线接收语音123456789为例,出现语音断续时,多通道语音信号比较选通。由于仅做了选通处理,输出信号仍然会导致语音断续、字词丢失,无法得到完整的信息。
4.等增益合并方法方案属于分集合并方案中的一种合并方法,它仅能保证同相相加,如果各个输入之间不平衡,容易导致弱信号放大多倍参与到合并中,引入更多噪声,甚至可能造成合并损失。
5.麦克风阵列波束形成方法方案通过波束形成,可以控制施加到单个麦克风或阵列中的麦克风的输出的增益,优选的是最大化来自波束形成的麦克风阵列增益,但是增加增益也可能增加系统的内部噪声或自噪声。
6.由上可知,现有选择合并方法方案选择单一信号进行输出,存在造成信号丢失的问题。以及,现有等增益合并方法方案中存在容易引入更多噪声,导致合并损失的问题。
技术实现要素:
7.本发明的目的在于克服现有技术的不足,提供一种机载环境下多输入语音信号波束形成信息互补方法,旨在解决背景中提出的问题。
8.本发明的目的是通过以下方案实现的:
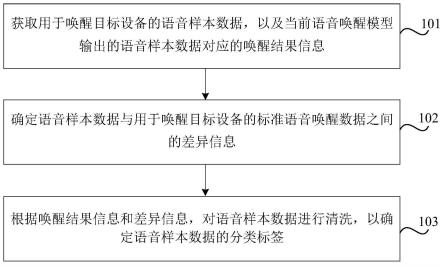
9.一种机载环境下多输入语音信号波束形成信息互补方法,包括以下步骤:
10.步骤s1,对输入的信号进行预处理;
11.步骤s2,对预处理后的信号进行语音活动性检测,得到输入信号的语音段范围以及输入信号的噪声段范围;
12.步骤s3,进行时延估计和同步,并调整对应语音段、噪声段的范围,且判断同步后各路信号间时延是否小于滤波器长度,如果小于则进行矩阵估计,否则继续进行时延同步;
13.步骤s4,进行噪声矩阵估计、带噪语音矩阵估计,并以二者进行最优矩阵估计;
14.步骤s5,用最优矩阵估计最优权向量,得到最优滤波器,并用输入信号通过最优滤波器输出合成信号。
15.进一步地,在步骤s1中,所述预处理包括分帧加窗处理。
16.进一步地,在步骤s2中,包括子步骤:对语音信号进行语音端点检测,并利用短时能量法和短时过零率法互相确定区间,得到一个准确的端点检测结果。
17.进一步地,在步骤s3中,包括子步骤:设输入的两路信号模型在时刻k分别为:
18.其中i=1,2,...,n;s(k)表示原始的纯净语音信号;τi表示各路通道所接收到的语音信号相对于原始纯净语音信号的相对时延;vi(k)表示各路通道所接收到的语音信号相对于原始纯净语音信号的噪声;
[0019]019]
是两路输入语音信号的互相关函数,y1(k)表示第一路接收到的信号,y2(k)表示第二路接收到的信号;
[0020]
τ=τ
1-τ2为两路信号的时延,α1表示第一路接收到的信号与纯净原始语音信号的比值系数,α2表示第二路接收到的信号与纯净原始语音信号的比值系数;
[0021]
若τ-(τ
1-τ2)=0,则s(k)的自相关矩阵r
ss
(τ-(τ
1-τ2))取得最大值,就取得最大值两路信号相关性最大,求到对应的位移点数λ,通过采样率fs和点数λ之间的关系,推算出两段信号的时延τ:
[0022][0023]
得到时延估计结果后进行位移同步,得到无时延差的信号。
[0024]
进一步地,在步骤s4中,包括子步骤:计算带噪语音自相关矩阵r
yy
:
[0025]ryy
=e[y(k)y
t
(k)],其中e[]表示求期望值。
[0026]
计算噪声自相关矩阵r
vv
:
[0027]rvv
=e[v(k)v
t
(k)],其中
[0028]
进一步地,在步骤s5中,所述最优矩阵估计包括子步骤:按如下公式计算最优矩阵w
i,0
:
[0029]
其中i代表通道数,其中i代表通道数,w
i,0
表示对通道i的最优矩阵;
[0030]
lh表示长度,表示阶数为lh的单位矩阵,w0表示所有通道的最优矩阵和构成的最优矩阵。
[0031]
进一步地,在步骤s5中,所述用最优矩阵估计最优权向量,包括子步骤:按如下公式计算最优权向量:
[0032][0033]
其中u'=[1,0,...,0]
t
是长度为lh的矢量,其中h
表示最优滤波器,和表示在最优滤波器变换的条件下,h
ytryyhy
和h
vtrvvhv
分别代表带噪语音和噪声的输出功率,s.t.表示在约束条件下,w
t
表示最优滤波矩阵的转置,u'=[1,0,...,0]
t
是长度为lh的矢量;
[0034]
通过拉格朗日乘子方法对以上两个最优化问题求解:
[0035]
ly(hy,λ)=h
ytryyhy
λy(w
thy-u')
[0036]
lv(hv,λv)=h
vtrvvhv
λv(w
thv-u')
[0037]
其中ly(hy,λ)和lv(h,λv)分别表示带噪语音和噪声在约束条件下的拉格朗日函数,λv表示拉格朗日乘子矢量参数;
[0038]
对ly(hy,λ)和lv(h,λv)中的h求导,得到:
[0039]
l'y(hy,λ)=r
yyhy
wλ
yt
[0040]
l'v(h,λv)=r
vv
h wλ
vt
[0041]
其中l'y(hy,λy)和l'v(h,λv)分别为ly(hy,λy)和lv(hv,λv)的导数;令l'y(hy,λy)和l'v(hv,λv)都等于0,求得:
[0042][0043][0044]
将两式带入约束条件w
thy
=u'和w
thv
=u',得到:
[0045][0046][0047]
再代入和中得到:
[0048][0049][0050]
代入含有空时信息的w0矩阵,得到:
[0051][0052][0053]hst,y
表示对带噪语音求得的最优滤波器,h
st,v
表示对噪声求得的最优滤波器。
[0054]
进一步地,在步骤s5中,所述用输入信号通过最优滤波器输出合成信号,包括子步骤:
[0055]
使用h
st,v
作为滤波矩阵,最优滤波器输出的合成信号为:
[0056]
其中为滤波输出信号,h
i,st,v
代表通道i的最优滤波矩阵,x
ir
(k)和v
ir
(k)分别为经过最优滤波器滤波后的语音和残留噪声。
[0057]
进一步地,所述利用短时能量法和短时过零率法互相确定区间,包括子步骤:
[0058]
设第n帧的语音信号为xn(k),则该帧的短时能量为短时过零率为其中,代表阶跃函数,k表示时刻,n表示总帧数。
[0059]
本发明的有益效果包括:
[0060]
本发明利用多输入语音信息之间互相补充来防止语音断续问题,保证信息完整度,增强空地、机间的通话质量以及通话稳定性。相较于比较选通或者是等增益合并方法,不仅保留了完整的语音信息,还能够有效的提高信噪比。
附图说明
[0061]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0062]
图1为现有选择合并方法进行多通道语音信号比较选通的原理示意图;
[0063]
图2为本发明实施例方法的步骤流程图;
[0064]
图3为噪声段对应的估计点数和输出信噪比的关系;
[0065]
图4为带噪语音段ly和输出信噪比的关系;
[0066]
图5为最大时延长度(0-1000)和输出信噪比的关系;
[0067]
图6为存在语音断续的四输入信号,信噪比均为5db的归一化语音波形;
[0068]
图7为图6中四输入信号使用本发明实施例方法输出的语音波形;
[0069]
图8为本发明实施例方法的步骤流程图。
具体实施方式
[0070]
本说明书中所有实施例公开的所有特征,或隐含公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合和/或扩展、替换。
[0071]
本发明实施例针对超短波通信系统在飞行任务过程中,由于飞机的多天线空域覆盖不全、超短波的绕射能力差、飞机系统中存在的电磁干扰等诸多原因,导致的语音信号断续这一问题,以及对该问题现有的解决方案(选择合并,等增益合并)存在的缺陷,提出一种针对机载环境下多输入语音信号的波束形成方法。
[0072]
本发明实施例技术方案为:对输入的信号进行分帧加窗预处理;对每一个输入的信号进行语音端点检测,确定是否为语音段;对已有的语音段进行时延估计处理,并进行时延同步,确保最大时延不大于滤波器长度;根据时延同步后各输入信号的语音段信息确定噪声段,进行语音段和噪声段的互相关矩阵估计,并以两者结果计算最优滤波矩阵和最优权向量;最后滤波输出信号。
[0073]
如图2所示,包括如下步骤:
[0074]
对输入的信号进行分帧加窗等预处理;
[0075]
对分帧后的信号进行语音活动性检测,得到输入信号的语音段范围以及输入信号
的噪声段范围;
[0076]
进行时延估计预处理,估计最大时延并进行同步,并调整对应语音段、噪声段的范围,且判断同步后各路信号间时延是否小于滤波器长度,如果小于则进行矩阵估计,否则继续进行时延同步;
[0077]
进行噪声矩阵估计、带噪语音矩阵估计,并以二者进行最优矩阵估计;
[0078]
用最优矩阵估计最优权向量,得到最优滤波器,并用输入信号通过滤波器输出合成信号。
[0079]
在具体实施过程中,包括如下子步骤:
[0080]
第一步,进行分帧加窗等预处理;
[0081]
分帧时间:25ms
[0082]
加窗:sw(n)=s(n)
·
w(n),其中sw(n)为加窗后的函数,s(n)为需要加窗的函数,w(n)为窗函数,w(n)选取汉明窗,
[0083][0084]
第二步,对语音信号进行语音端点检测;
[0085]
短时能量:设第n帧的语音信号为xn(k),则该帧的短时能量为短时过零率为
[0086]
利用短时能量法和短时过零率法互相确定区间,就可以得到一个准确的端点检测结果。
[0087]
第三步,进行时延估计同步。多输入通道间的时延需要消除或很小,至少需要在滤波器阶数之下,否则接收的语音中会出现质量下降,参阅图5,且无法用统一的语音段和噪声段位置进行计算,增大了计算量;
[0088]
时延估计:假设输入的两路信号模型分别为
[0089]
其中i=1,2,...,n;s(k)表示原始的纯净语音信号;τi表示各路通道所接收到的语音信号相对与原始纯净语音信号的相对时延;vi(k)表示各路通道所接收到的语音信号相对于原始纯净语音信号的噪声。
[0090][0090]
是两路输入语音信号的互相关函数。
[0091]
τ=τ
1-τ2为两路信号的时延
[0092]
若τ-(τ
1-τ2)=0,则r
ss
(τ-(τ
1-τ2))取得最大值,就取得最大值两路信号相关性最大,可以求到对应的位移点数λ,通过采样率fs和点数λ之间的关系,可以推算出两段
信号的时间差τ。
[0093][0094]
得到时延估计结果后进行位移同步,得到无时延差的信号。
[0095]
第四步,语音段和噪声段互相关矩阵估计,参阅图3、图4,语音段和噪声段的有效点数对结果的影响很大;
[0096]
带噪语音自相关矩阵计算:r
yy
=e[y(k)y
t
(k)],其中
[0097]
噪声自相关矩阵计算:r
vv
=e[v(k)v
t
(k)],其中
[0098]
第五步,最优滤波矩阵估计;
[0099]
其中i代表通道数,其中i代表通道数,w
i,0
表示对通道i的最优滤波矩阵。
[0100][0101]
第六步,按如下公式计算最优权向量:
[0102][0103]
其中u'=[1,0,...,0]
t
是长度为lh的矢量,其中h表示最优滤波器,和表示在最优滤波器变换的条件下,h
ytryyhy
和h
vtrvvhv
分别代表带噪语音和噪声的输出功率,s.t.表示在约束条件下,w
t
表示最优滤波矩阵的转置,u'=[1,0,...,0]
t
是长度为lh的矢量;
[0104]
通过拉格朗日乘子方法对以上两个最优化问题求解:
[0105]
ly(hy,λ)=h
ytryyhy
λy(w
thy-u')
[0106]
lv(hv,λv)=h
vtrvvhv
λv(w
thv-u')
[0107]
其中ly(hy,λ)和lv(h,λv)分别表示带噪语音和噪声在约束条件下的拉格朗日函数,λv表示拉格朗日乘子矢量参数;
[0108]
对ly(hy,λ)和lv(h,λv)中的h求导,得到:
[0109]
l'y(hy,λ)=r
yyhy
wλ
yt
[0110]
l'v(h,λv)=r
vv
h wλ
vt
[0111]
其中l'y(hy,λy)和l'v(h,λv)分别为ly(hy,λy)和lv(hv,λv)的导数;令l'y(hy,λy)和l'v(hv,λv)都等于0,求得:
[0112][0113][0114]
将两式带入约束条件w
thy
=u'和w
thv
=u',得到:
[0115][0116]
[0117]
再代入和中得到:
[0118][0119][0120]
代入含有空时信息的w0矩阵,得到:
[0121][0122][0123]hst,y
表示对带噪语音求得的最优滤波器,h
st,v
表示对噪声求得的最优滤波器。
[0124]
第七步,算法条件下语音和噪声是完全不相关,所以当整个带噪语音滤波后输出功率最小时,噪声的输出功率也同时是最小的。但实际上并不会完全成立,为了防止语音段的信息被滤,所以在这里使用h
st,v
作为滤波矩阵,滤波输出信号:
[0125]
其中为滤波输出信号,h
i,st,v
代表通道i的最优滤波矩阵,x
ir
(k)和v
ir
(k)分别为经过最优滤波器滤波后的语音和残留噪声。
[0126]
如图3所示,噪声段有效点数和输出信噪比的关联。在实验中控制时延、语音段有效点数等其他变量,仅改变噪声段对应有效点数,输入为两路5db的信号。
[0127]
如图4所示,语音段有效点数和输出信噪比的关联。在实验中控制时延、噪声段有效点数等其他变量,仅改变语音段有效点数,输入为两路5db的信号。横轴代表了同一句语音中的多少个字进入了选取范围,字越多,也就是语音段有效点数越大。
[0128]
如图5所示,多输入间最大时延长度和输出信噪比的关联。在实验中控制语音段有效点数、噪声段有效点数等其他变量,仅改变输入信号间的最大时延,输入为两路5db的信号。此时设置的滤波器阶数为64,看到经过当时延点数大于滤波器阶数时,输出信噪比将会出现极大的下滑。
[0129]
如图6所示,存在语音断续的四输入信号,信噪比均为5db。
[0130]
如图7所示,图6中四输入信号使用该方法输出的语音波形。
[0131]
实施例1
[0132]
如图8所示,一种机载环境下多输入语音信号波束形成信息互补方法,包括以下步骤:
[0133]
步骤s1,对输入的信号进行预处理;
[0134]
步骤s2,对预处理后的信号进行语音活动性检测,得到输入信号的语音段范围以及输入信号的噪声段范围;
[0135]
步骤s3,进行时延估计和同步,并调整对应语音段、噪声段的范围,且判断同步后各路信号间时延是否小于滤波器长度,如果小于则进行矩阵估计,否则继续进行时延同步;
[0136]
步骤s4,进行噪声矩阵估计、带噪语音矩阵估计,并以二者进行最优矩阵估计;
[0137]
步骤s5,用最优矩阵估计最优权向量,得到最优滤波器,并用输入信号通过最优滤
波器输出合成信号。
[0138]
实施例2
[0139]
基于实施例1,在步骤s1中,所述预处理包括分帧加窗处理。
[0140]
实施例3
[0141]
基于实施例1,在步骤s2中,包括子步骤:对语音信号进行语音端点检测,并利用短时能量法和短时过零率法互相确定区间,得到一个准确的端点检测结果。
[0142]
实施例4
[0143]
基于实施例1,在步骤s3中,包括子步骤:设输入的两路信号模型在时刻k分别为:
[0144]
其中i=1,2,...,n;s(k)表示原始的纯净语音信号;τi表示各路通道所接收到的语音信号相对于原始纯净语音信号的相对时延;vi(k)表示各路通道所接收到的语音信号相对于原始纯净语音信号的噪声;
[0145][0145]
是两路输入语音信号的互相关函数,y1(k)表示第一路接收到的信号,y2(k)表示第二路接收到的信号;
[0146]
τ=τ
1-τ2为两路信号的时延,α1表示第一路接收到的信号与纯净原始语音信号的比值系数,α2表示第二路接收到的信号与纯净原始语音信号的比值系数;
[0147]
若τ-(τ
1-τ2)=0,则s(k)的自相关矩阵r
ss
(τ-(τ
1-τ2))取得最大值,就取得最大值两路信号相关性最大,求到对应的位移点数λ,通过采样率fs和点数λ之间的关系,推算出两段信号的时延τ:
[0148][0149]
得到时延估计结果后进行位移同步,得到无时延差的信号。
[0150]
实施例5
[0151]
基于实施例1,在步骤s4中,包括子步骤:计算带噪语音自相关矩阵r
yy
:
[0152]ryy
=e[y(k)y
t
(k)],其中e[]表示求期望值。
[0153]
计算噪声自相关矩阵r
vv
:
[0154]rvv
=e[v(k)v
t
(k)],其中
[0155]
实施例6
[0156]
基于实施例5,在步骤s5中,所述最优矩阵估计包括子步骤:按如下公式计算最优矩阵w
i,0
:
[0157]
其中i代表通道数,其中i代表通道数,w
i,0
表示对通道i的最优矩阵;
[0158]
lh表示长度,表示阶数为lh的单位矩阵,w0表示所
有通道的最优矩阵和构成的最优矩阵,这样可以保证矩阵的满秩,以便后续进行拉格朗日乘子方法时求导。
[0159]
实施例7
[0160]
基于实施例6,在步骤s5中,所述用最优矩阵估计最优权向量,包括子步骤:按如下公式计算最优权向量:
[0161][0162]
其中u'=[1,0,...,0]
t
是长度为lh的矢量,其中h表示最优滤波器,和表示在最优滤波器变换的条件下,h
ytryyhy
和h
vtrvvhv
分别代表带噪语音和噪声的输出功率,s.t.表示在约束条件下,w
t
表示最优滤波矩阵的转置,u'=[1,0,...,0]
t
是长度为lh的矢量;
[0163]
通过拉格朗日乘子方法对以上两个最优化问题求解:
[0164]
ly(hy,λ)=h
ytryyhy
λy(w
thy-u')
[0165]
lv(hv,λv)=h
vtrvvhv
λv(w
thv-u')
[0166]
其中ly(hy,λ)和lv(h,λv)分别表示带噪语音和噪声在约束条件下的拉格朗日函数,λv表示拉格朗日乘子矢量参数;
[0167]
对ly(hy,λ)和lv(h,λv)中的h求导,得到:
[0168]
l'y(hy,λ)=r
yyhy
wλ
yt
[0169]
l'v(h,λv)=r
vv
h wλ
vt
[0170]
其中l'y(hy,λy)和l'v(h,λv)分别为ly(hy,λy)和lv(hv,λv)的导数;令l'y(hy,λy)和l'v(hv,λv)都等于0,求得:
[0171][0172][0173]
将两式带入约束条件w
thy
=u'和w
thv
=u',得到:
[0174][0175][0176]
再代入和中得到:
[0177][0178][0179]
代入含有空时信息的w0矩阵,得到:
[0180][0181][0182]hst,y
表示对带噪语音求得的最优滤波器,h
st,v
表示对噪声求得的最优滤波器。
[0183]
实施例8
[0184]
基于实施例7,在步骤s5中,由于算法条件下语音和噪声是完全不相关,所以当整个带噪语音滤波后输出功率最小时,噪声的输出功率也同时是最小的。但实际上并不会完全成立,为了防止语音段的信息被滤,所以本发明实施例在这里使用h
st,v
作为滤波矩阵。所述用输入信号通过最优滤波器输出合成信号,包括子步骤:
[0185]
最优滤波器输出的合成信号为:
[0186]
其中为滤波输出信号,h
i,st,v
代表通道i的最优滤波矩阵,x
ir
(k)和v
ir
(k)分别为经过最优滤波器滤波后的语音和残留噪声。
[0187]
实施例9
[0188]
基于实施例3,所述利用短时能量法和短时过零率法互相确定区间,包括子步骤:
[0189]
设第n帧的语音信号为xn(k),则该帧的短时能量为短时过零率为其中,代表阶跃函数,k表示时刻,n表示总帧数。
[0190]
除以上实例以外,本领域技术人员根据上述公开内容获得启示或利用相关领域的知识或技术进行改动获得其他实施例,各个实施例的特征可以互换或替换,本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。