1.本发明属于化工过程故障检测技术领域,涉及一种基于典型变量相异性分析(canonical variable dissimilarity analysis,简称cvda)的化工过程缓变故障检测方法。
背景技术:
2.随着科学技术的不断发展,现代化工系统的规模和复杂程度不断提升,同时对化工过程的系统性能和生产安全提出了更高的要求,正是由于现代化工系统的大规模化和高复杂性,导致故障事件不可避免地频繁发生。缓变故障具有变化缓慢,初期幅值小等特点,若能及时在化工过程的可控范围内检测缓变故障并采取相应的措施,将有效减少生产力损失和确保工作人员的生命安全,对化工过程的安全监控有着重要的实际意义。随着计算机技术的发展,化工过程的大量数据被存储下来,促使了基于数据驱动的故障诊断技术的广泛应用。
3.典型变量相异性分析法是化工过程监控领域的新型算法,2018年由pilario和cao首次提出。然而在过程监控中,传统cvda方法仅利用原始测量数据构造统计量且所有的cvda特征以同等的地位进行建模和监控,未考虑数据包含的概率信息和特征携带故障信息的差异性,导致缓变故障的检测效果不佳。因此,如何考虑过程数据所包含的概率信息和特征差异性以提高缓变故障的检测性能是目前化工过程监控中需要解决的关键问题。
技术实现要素:
4.本发明针对传统cvda方法存在的未考虑过程数据所包括的概率信息和特征携带故障信息的差异性等问题,提供一种基于典型变量相异性分析的化工过程缓变故障检测方法。该方法将wasserstein距离(英文:wasserstein distance,简称:wd)引入到cvda方法中,利用wd挖掘缓变故障数据所包含的概率信息,再进一步考虑特征差异性,引入了权重系数,根据特征携带故障信息的大小对特征进行在线加权,以达到提高缓变故障检测性能的目的。
5.为了达到上述目的,本发明提供了一种基于典型变量相异性分析的化工过程缓变故障检测方法,含有以下步骤:
6.(一)采集历史数据库中正常操作工况下的过程数据作为训练数据x0,并利用训练数据x0的均值和标准差对训练数据x0进行标准化处理,得到标准化后的训练数据x;由训练数据x构造训练历史数据矩阵p和未来数据矩阵f;
7.(二)将所述历史和未来数据矩阵p和f进行典型变量相异性分析得到cvda模型,利用所述cvda模型提取历史和未来数据矩阵p和f的状态向量s、残差向量e和相异性特征d,利用wasserstein距离分别计算所述状态向量s、残差向量e和相异性特征d所对应的训练wd特征s
wd
、e
wd
和d
wd
;
8.(三)由所述训练wd特征s
wd
、e
wd
和d
wd
计算相应统计量t2、统计量q和统计量d,给定
置信水平α,通过核密度估计方法计算统计量t2所对应的控制限统计量q所对应的控制限q
lim
和统计量d所对应的控制限d
lim
;
9.(四)采集测试数据x
new
,利用训练数据x0的均值和标准差对测试数据x
new
进行标准化处理,得到标准化后的测试数据x
t
,由测试数据x
t
构造测试历史数据向量p
t
和未来数据向量f
t
;
10.(五)利用步骤(二)所得到的cvda模型,获得测试历史数据向量p
t
和未来数据向量f
t
所对应的状态向量s
t
、残差向量e
t
和相异性特征d
t
,利用wasserstein距离分别计算所述状态向量s
t
、残差向量e
t
和相异性特征d
t
所对应的在线wd特征和
11.(六)依据所述wd特征相对于训练wd特征s
wd
的变化对wd特征赋予权重w
s,t
,wd特征相对于训练wd特征e
wd
的变化对在线wd特征赋予权重w
e,t
,wd特征相对于训练wd特征d
wd
的变化对在线wd特征赋予权重w
d,t
,获得在线加权wd特征和
12.(七)由所述在线加权wd特征和计算对应新的统计量t
t2
、统计量q
t
和统计量d
t
,并依据统计量t
t2
、统计量q
t
和统计量d
t
是否超出对应的控制限,判断测试数据x
t
是否发生故障。
13.进一步的,所述步骤(一)中,训练数据x0进行标准化处理,并建立训练历史数据矩阵p和未来数据矩阵f的具体过程为:
14.首先利用训练数据x0的均值和标准差通过公式(1)对训练数据x0进行标准化处理,公式(1)的表达式为:
[0015][0016]
训练数据x0经上述公式(1)标准化化处理后即可获得标准化后的训练数据x。
[0017]
通过公式(2)和(3)计算所述训练数据x=[x1,x2,...,xi,
…
,xn]
t
∈rn×m中xi对应的训练历史数据向量pi和未来数据向量fi,其中,i表示采样时刻,xi表示第i时刻采集的过程变量,n表示样本个数,m表示变量个数,公式(2)、公式(3)表示为:
[0018][0019][0020]
式中,h表示时间滞后数,
[0021]
计算所述训练历史数据向量和未来数据向量分别对应的历史数据矩阵p和未来数据矩阵f通过公式(4)和(5),公式(4)、公式(5)表示为:
[0022][0023][0024]
式中,m=n-2h 1,p
h 1
表示第h 1时刻对应的历史数据向量,f
h 1
表示第h 1时刻对应的未来数据向量;
[0025]
进一步的,所述步骤(二)中,针对建立cvda模型提取将所述历史和未来数据矩阵p和f的状态向量s、残差向量e和相异性特征d,并计算所述状态向量s、残差向量e和相异性特征d所对应的训练wd特征s
wd
、e
wd
和d
wd
的具体步骤为:
[0026]
首先,通过公式(6)-(8)计算所述历史和未来数据矩阵p和f所对应的协方差矩阵σ
pp
和σ
ff
以及互协方差矩阵σ
pf
,公式(6)-(8)表示为:
[0027][0028][0029][0030]
对所述协方差矩阵σ
pp
和σ
ff
以及互协方差矩阵σ
pf
开展公式(9)所示的广义特征值分解,公式(9)的表达式为:
[0031][0032]
式中,u表示左奇异矩阵,v表示右奇异矩阵,是由特征值降序排列构成的对角矩阵;
[0033]
通过求解公式(9),可以开展公式(10)和(11)计算投影矩阵和公式(10)和(11)表示如下:
[0034][0035][0036]
投影向量对{ai,bi}对应第i个相关系数λi,根据λi值的大小,将所述投影向量对划分成典型变量子空间和残差子空间,前k个特征值λ1>λ2>
…
>λk代表主要相关系数对应典型变量子空间投影矩阵ak=[a1,a2,
…
,ak],剩余个特征值代表微弱相关系数对应残差子空间投影矩阵,所述k的值由平均值法确定;
[0037]
对于所述训练数据x中在第i个采样时刻对应的训练历史数据向量pi和未来数据向量fi,通过公式(12)-(13)提取对应的状态向量si、残差向量ei和相异性特征di,公式(12)-(13)的表达式为:
[0038][0039][0040][0041]
式中,uk表示所述矩阵u的前k列,相异性特征度量由所述未来数据向量fi预测的典型变量与历史数据向量pi获得的典型变量的差值。
[0042]
计算所述状态向量s=[s1,s2,
…
,sj,
…
sk]的第j个状态向量sj所对应的均值μj与方差σj;
[0043]
利用滑动窗口求取状态向量s
i,j
的局部均值与方差,由公式(15)计算所述状态向
量s
i,j
对应的wd特征公式(15)的表达式为:
[0044][0045]
式中,表示利用滑动窗口所求的状态向量s
i,j
的局部均值,表示利用滑动窗口所求的状态向量s
i,j
的局部方差。
[0046]
通过计算训练wd特征相同地,计算所述残差向量ei和相异性特征di所对应的训练wd特征和其中残差向量e
i,j
对应的wd特征相异性特征d
i,j
对应的wd特征
[0047]
进一步的,步骤(三)中,计算训练wd特征s
wd
、e
wd
和d
wd
相应统计量t2、统计量q和统计量d的具体步骤为:
[0048]
依据wd特征s
wd
、e
wd
和d
wd
,由公式(16)-(18)分别构造统计量t2、统计量q和统计量d,公式(16)-(18)的表达式为:
[0049][0050][0051][0052]
式中,λd表示相异性特征d所对应的协方差矩阵。
[0053]
给定置信水平α,通过核密度估计方法计算统计量t2所对应的控制限统计量q所对应的控制限q
lim
和统计量d所对应的控制限d
lim
。
[0054]
进一步的,步骤(四)中,利用训练数据x0的均值和标准差通过公式(19)对测试数据x
new
进行标准化处理,公式(19)的表达式为:
[0055][0056]
第t采样时刻采集的测试数据x
new
经上述公式(19)标准化处理后即可获得标准化后的测试数据x
t
。
[0057]
所述测试数据x
t
对应测试历史数据向量p
t
和未来数据向量f
t
通过公式(20)和(21)计算,公式(20)和(21)的表达式为:
[0058][0059][0060]
进一步的,步骤(五)中,所述测试历史向量p
t
和未来向量f
t
对应的状态向量s
t
、残差向量e
t
和相异性特征d
t
通过公式(22)-(24)计算,公式(22)-(24)的表达式为:
[0061][0062]
[0063][0064]
式中,uk为求解公式(9)获得是左奇异矩阵u的前k列,ak和bk为求解公式(10)和(11)获得的前k对投影向量;
[0065]
由步骤(二)得到所述状态向量s=[s1,s2,
…
,sj,
…
sk]的第j个状态向量sj所对应的均值μj与方差σj;
[0066]
利用滑动窗口求取状态向量s
t,j
的局部均值与方差,由公式(25)计算所述状态向量s
t,j
对应的wd特征公式(25)的表达式为:
[0067][0068]
式中,表示利用滑动窗口所求的状态向量s
t,j
的局部均值,表示利用滑动窗口所求的状态向量s
t,j
的局部方差。
[0069]
通过计算测试wd特征相同地,计算所述残差向量e
t
和相异性特征d
t
所对应的训练wd特征和其中残差向量e
t,j
对应的wd特征相异性特征d
t,j
对应的wd特征
[0070]
进一步的,步骤(六)中,对所述获得在线加权wd特征和的具体步骤为:
[0071]
首先,依据所述wd特征相对于训练wd特征s
wd
的变化对wd特征赋予权重w
s,t
,wd特征相对于训练wd特征e
wd
的变化对在线wd特征赋予权重w
e,t
,wd特征相对于训练wd特征d
wd
的变化对在线wd特征赋予权重w
d,t
,通过公式(26)-(28)计算,公式(26)-(28)的表达式为:
[0072][0073][0074][0075]
式中,权重w
s,t
=[w
s,t
(1),
…
,w
s,t
(j),
…
,w
s,t
(k)]
t
中的w
s,t
(j)表示第j个在线wd特征的加权系数,权重中的w
e,t
(j)表示第j个在线wd特征的加权系数,权重w
d,t
=[w
d,t
(1),
…
,w
d,t
(j),
…
,w
d,t
(k)]
t
中的w
d,t
(j)表示第j个在线wd特征的加权系数;
[0076]
所述加权阈值和一般选择训练wd特征和元素中最大值的1~2倍。
[0077]
获得在线加权wd特征和通过公式(29)-(31)计算,公式(29)-(31)表达式为:
[0078][0079][0080][0081]
进一步的,步骤(七)中,由在线加权wd特征和计算对应新的统计量t
t2
、统计量q
t
和统计量d
t
的具体步骤为:
[0082]
依据在线加权wd特征和由公式(32)-(34)分别构造统计量t2、统计量q和统计量d,公式(32)-(34)的表达式为:
[0083][0084][0085][0086]
式中,λd表示相异性特征d所对应的协方差矩阵。
[0087]
判断测试数据x
t
是否发生故障的步骤为:当q
t
≤q
lim
且d
t
≤d
lim
时,认为化工过程处于正常工作状态,否则,认为化工过程出现故障。
[0088]
与现有技术相比,本发明的有益效果在于:
[0089]
本发明提供的基于典型变量相异性分析的化工过程缓变故障检测方法,利用wasserstein距离度量状态向量、残差和相异性特征的概率分布变化,实现了过程数据概率信息的挖掘,同时进一步考虑了特征差异性,利用权重系数对特征进行加权,提高携带故障信息多的特征权重,使得统计量能够更为明显的反应化工过程中的缓变故障信息,进而改善缓变故障检测结果,提高缓变故障故障检测率。
附图说明
[0090]
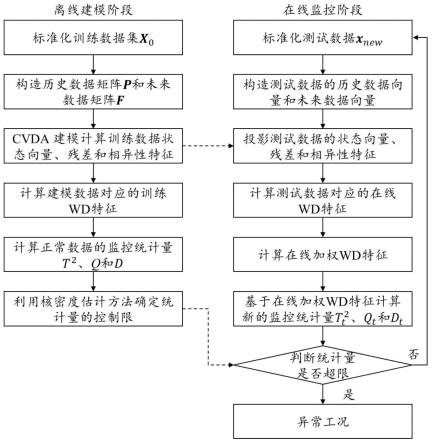
图1为本发明基于典型变量相异性分析的化工过程缓变故障检测方法的流程图;
[0091]
图2为本发明实施例所述田纳西-伊斯曼(te)过程的结构图;
[0092]
图3a为本发明实施例采用传统cvda方法对te过程故障21的监控结果示意图;
[0093]
图3b为本发明实施例采用本发明所述基于典型变量相异性分析的化工过程缓变故障检测方法对te过程故障21的监控结果示意图;
具体实施方式
[0094]
下面,通过示例性的实施方式对本发明进行具体描述。然而应当理解,在没有进一
步叙述的情况下,一个实施方式中的元件、结构和特征也可以有益地结合到其他实施方式中。
[0095]
参见图1,本发明揭示了一种基于典型变量相异性分析的化工过程缓变故障检测方法,含有以下步骤:
[0096]
(一)采集历史数据库中正常操作工况下的过程数据作为训练数据x0,并利用训练数据x0的均值和标准差对训练数据x0进行标准化处理,得到标准化后的训练数据x;由训练数据x构造训练历史数据矩阵p和未来数据矩阵f,具体步骤为:
[0097]
利用训练数据x0的均值和标准差通过公式(1)对训练数据x0进行标准化处理,公式(1)的表达式为:
[0098][0099]
通过公式(2)和(3)计算所述训练数据x=[x1,x2,...,xi,
…
,xn]
t
∈rn×m中xi对应的训练历史数据向量pi和未来数据向量fi,其中,i表示采样时刻,xi表示第i时刻采集的过程变量,n表示样本个数,m表示变量个数,公式(2)、公式(3)表示为:
[0100][0101][0102]
式中,xi表示第i时刻采集的过程变量,h表示时间滞后数,
[0103]
计算训练历史数据向量和未来数据向量分别对应的历史数据矩阵p和未来数据矩阵f通过公式(4)和(5),公式(4)、公式(5)表示为:
[0104][0105][0106]
式中,m=n-2h 1,p
h 1
表示第h 1时刻对应的历史数据向量,f
h 1
表示第h 1时刻对应的未来数据向量;
[0107]
(二)将所述历史和未来数据矩阵p和f进行典型变量相异性分析得到cvda模型,利用所述cvda模型提取历史和未来数据矩阵p和f的状态向量s、残差向量e和相异性特征d,利用wasserstein距离分别计算所述状态向量s、残差向量e和相异性特征d所对应的训练wd特征s
wd
、e
wd
和d
wd
,具体步骤为:
[0108]
首先,通过公式(6)-(8)计算所述历史和未来数据矩阵p和f所对应的协方差矩阵σ
pp
和σ
ff
以及互协方差矩阵σ
pf
,公式(6)-(8)表示为:
[0109][0110][0111][0112]
对所述协方差矩阵σ
pp
和σ
ff
以及互协方差矩阵σ
pf
开展公式(9)所示的广义特征
值分解,公式(9)的表达式为:
[0113][0114]
式中,u表示左奇异矩阵,v表示右奇异矩阵,是由特征值降序排列构成的对角矩阵;
[0115]
通过求解公式(9),可以开展公式(10)和(11)计算投影矩阵和公式(10)和(11)表示如下:
[0116][0117][0118]
投影向量对{ai,bi}对应第i个相关系数λi,根据λi值的大小,将所述投影向量对划分成典型变量子空间和残差子空间,前k个特征值λ1>λ2>
…
>λk代表主要相关系数对应典型变量子空间投影矩阵ak=[a1,a2,
…
,ak],剩余个特征值代表微弱相关系数对应残差子空间投影矩阵,所述k的值由平均值法确定;
[0119]
对于所述训练数据x中在第i个采样时刻对应的训练历史数据向量pi和未来数据向量fi,通过公式(12)-(13)提取对应的状态向量si、残差向量ei和相异性特征di,公式(12)-(13)的表达式为:
[0120][0121][0122][0123]
式中,uk表示所述矩阵u的前k列,相异性特征度量由所述未来数据向量fi预测的典型变量与历史数据向量pi获得的典型变量的差值。
[0124]
计算所述状态向量s=[s1,s2,
…
,sj,
…
sk]的第j个状态向量sj所对应的均值μj与方差σj;
[0125]
利用滑动窗口求取状态向量s
i,j
的局部均值与方差,由公式(15)计算所述状态向量s
i,j
对应的wd特征公式(15)的表达式为:
[0126][0127]
式中,表示利用滑动窗口所求的状态向量s
i,j
的局部均值,表示利用滑动窗口所求的状态向量s
i,j
的局部方差。
[0128]
通过计算训练wd特征相同地,计算所述残差向量ei和相异性特征di所对应的训练wd特征和其中残差向量e
i,j
对应的wd特征相异性特征d
i,j
对应的wd特征
[0129]
(三)计算训练wd特征s
wd
、e
wd
和d
wd
对应的统计量t2、统计量q和统计量d并计算统计
量t2所对应的控制限统计量q所对应的控制限q
lim
和统计量d所对应的控制限d
lim
,具体步骤为:
[0130]
依据wd特征s
wd
、e
wd
和d
wd
,由公式(16)-(18)分别构造统计量t2、统计量q和统计量d,公式(16)-(18)的表达式为:
[0131][0132][0133][0134]
式中,λd表示相异性特征d所对应的协方差矩阵。
[0135]
给定置信水平α,通过核密度估计方法计算统计量t2所对应的控制限统计量q所对应的控制限q
lim
和统计量d所对应的控制限d
lim
。
[0136]
(四)采集测试数据x
new
,利用训练数据x0的均值和标准差对测试数据x
new
进行标准化处理,得到标准化后的测试数据x
t
,由测试数据x
t
构造测试历史向量p
t
和未来向量f
t
,具体步骤为:
[0137]
利用训练数据x0的均值和标准差通过公式(19)对测试数据x
new
进行标准化处理,公式(19)的表达式为:
[0138][0139]
第t采样时刻采集的测试数据x
new
经上述公式(19)标准化处理后即可获得标准化后的测试数据x
t
。
[0140]
所述测试数据x
t
对应测试历史数据向量p
t
和未来数据向量f
t
通过公式(20)和(21)计算,公式(20)和(21)的表达式为:
[0141][0142][0143]
(五)利用步骤(二)所得到的cvda模型,获得测试历史数据向量p
t
和未来数据向量f
t
所对应的状态向量s
t
、残差向量e
t
和相异性特征d
t
,利用wasserstein距离分别计算所述状态向量s
t
、残差向量e
t
和相异性特征d
t
所对应的在线wd特征和具体步骤为:
[0144]
首先,所述测试历史数据向量p
t
和未来数据向量f
t
对应的状态向量s
t
、残差向量e
t
和相异性特征d
t
通过公式(22)-(24)计算,公式(22)-(24)的表达式为:
[0145][0146][0147][0148]
式中,uk为求解公式(9)获得是左奇异矩阵u的前k列,ak和bk为求解公式(10)和
(11)获得的前k对投影向量;
[0149]
由步骤(二)得到所述状态向量s=[s1,s2,
…
,sj,
…
sk]的第j个状态向量sj所对应的均值μj与方差σj;
[0150]
利用滑动窗口求取状态向量s
t,j
的局部均值与方差,由公式(25)计算所述状态向量s
t,j
对应的wd特征公式(25)的表达式为:
[0151][0152]
式中,表示利用滑动窗口所求的状态向量s
t,j
的局部均值,表示利用滑动窗口所求的状态向量s
t,j
的局部方差。
[0153]
通过计算测试wd特征相同地,计算所述残差向量e
t
和相异性特征d
t
所对应的训练wd特征和其中残差向量e
t,j
对应的wd特征相异性特征d
t,j
对应的wd特征
[0154]
(六)依据所述wd特征相对于训练wd特征s
wd
的变化对wd特征赋予权重w
s,t
,wd特征相对于训练wd特征e
wd
的变化对在线wd特征赋予权重w
e,t
,wd特征相对于训练wd特征d
wd
的变化对在线wd特征赋予权重w
d,t
,获得在线加权wd特征和具体步骤为:
[0155]
首先,依据所述wd特征相对于训练wd特征s
wd
的变化对wd特征赋予权重w
s,t
,wd特征相对于训练wd特征e
wd
的变化对在线wd特征赋予权重w
e,t
,wd特征相对于训练wd特征d
wd
的变化对在线wd特征赋予权重w
d,t
,通过公式(26)-(28)计算,公式(26)-(28)的表达式为:
[0156][0157][0158][0159]
式中,权重w
s,t
=[w
s,t
(1),
…
,w
s,t
(j),
…
,w
s,t
(k)]
t
中的w
s,t
(j)表示第j个在线wd特征的加权系数,权重中的w
e,t
(j)表示第j个在线wd特征的加权系数,权重w
d,t
=[w
d,t
(1),
…
,w
d,t
(j),
…
,w
d,t
(k)]
t
中的w
d,t
(j)表示第j个在线wd特征的加权系数;
[0160]
所述加权阈值和一般选择训练wd特征和元素中最大值的1~2倍。
[0161]
获得在线加权wd特征和通过公式(29)-(31)计算,公式(29)-(31)表达式为:
[0162][0163][0164][0165]
(七)由所述在线加权wd特征和计算对应新的统计量t
t2
、统计量q
t
和统计量d
t
,并依据统计量t
t2
、统计量q
t
和统计量d
t
是否超出对应的控制限,判断测试数据x
t
是否发生故障,具体步骤为:
[0166]
依据在线加权wd特征和由公式(32)-(34)分别构造统计量t2、统计量q和统计量d,公式(32)-(34)的表达式为:
[0167][0168][0169][0170]
式中,λd表示相异性特征d所对应的协方差矩阵。
[0171]
判断测试数据x
t
是否发生故障的步骤为:当t
t2
≤t
li2m
、q
t
≤q
lim
且d
t
≤d
lim
时,认为化工过程处于正常工作状态,否则,认为化工过程出现故障。
[0172]
上述方法中,步骤(一)至(三)为离线建模阶段,步骤(四)至(七)为在线监控阶段。
[0173]
本发明上述故障检测方法,对训练数据进行标准化处理后,利用标准化后的训练数据建立历史和未来数据矩阵,再根据历史和未来数据矩阵建立cvda模型,并从训练数据中提取cvda特征,并计算对应的训练wd特征,进一步计算训练wd特征对应的统计量t2、统计量q和统计量d并确定相应的控制限;采集测试数据,构造测试数据的历史数据向量和未来数据向量,利用已建立的cvda模型提取对应的在线cvda特征,并计算在线wd特征,进一步计算在线加权wd特征,基于在线加权wd特征计算统计量t2、统计量q和统计量d,并利用控制限进行监控。本发明上述故障检测方法引入了wasserstein距离和在线加权策略,提高了化工过程数据中缓变故障的检测性能。
[0174]
为了能更清楚地说明本发明上述故障检测方法的有益效果,以下结合实施例对本发明上述故障检测方法做出进一步说明。
[0175]
实施例:
[0176]
田纳西-伊斯曼(以下简称:te)过程是由美国伊斯曼化学公司的downs和vogel根据一个实际的化工过程建立的实验平台,现被广泛用于验证控制算法和过程监控方法的优劣。参见图2,te过程主要由五个单元组成,包括反应器、产品冷凝器、气液分离器、循环压缩机和汽提塔组成。te过程共53个变量,其中包括22个连续测量变量、19个成分变量和12个操
作变量。本实施例中,参见表1,选取te过程中的33个变量;参见表2,共有4个故障。
[0177]
表1
[0178]
变量标号变量描述变量标号变量描述1a进料(流1)18汽提器温度2d进料(流2)19汽提器流量3e进料(流3)20压缩机功率4a和c进料(流4)21反应器冷却水出口温度5再循环流量(流8)22分离器冷却水出口温度6反应器进料速度(流6)23d进料量(流2)7反应器压力24e进料量(流3)8反应器等级25a进料量(流1)9反应器温度26a和c料量(流4)10放空速率27压缩机再循环阀11产品分离器温度28放空阀12产品分离器液位29分离器罐液流量(流10)13产品分离器压力30汽提器液体产品流量(流11)14产品分离器塔底流量(流10)31汽提器水流阀15汽提器等级32反应器冷水流量16汽提器压力33冷凝器冷水流量17汽提器塔底流量(流11)
ꢀꢀ
[0179]
表2
[0180]
故障名称描述类型fll反应器冷却水的入口温度随机f15冷凝器冷却水阀门粘滞f19未知未知f21流4的阀门粘住恒定
[0181]
在本实施例中,采用传统cvda方法和本发明wpcvda方法两种方法作为仿真对比。三个性能指标,即故障检出率fdr、故障误报率far和故障检出时刻fdt用于评估不同故障检测方法的故障检测性能。具体地说,故障检出率fdr定义为超出控制限的故障样本与实际全部故障样本的百分比;故障误报率far定义为超出控制限的正常样本与实际全部正常样本的百分比;故障检出时刻fdt定义为连续六个故障样本超出控制限时的第一个故障样本。设置99%置信度以求取统计量置信限,本发明wpcvda方法中滑动窗口宽度为30,特征加权阈值设置为1.5倍,测试数据前160个样本为正常样本,之后样本为故障样本。
[0182]
以故障21为例说明故障检测效果。故障21由流4的阀门粘住引起的。采用传统cvda方法和本发明wpcvda方法作仿真对比,对故障21的监控图参见图3a和图3b。参见图3a,由于故障缓慢变化,传统cvda方法具有一定的检测效果但检测效果不佳,其统计量d检出率为74.75%,统计量t2检出率为46.88%,统计量q检出率为38.38%,最早在第360个样本检测出故障发生。本发明提供的wpcvda在cvda方法的基础上,考虑过程数据概率信息和特征差异性后,统计量d检出率提升到79.13%,统计量t2检出率提升到82.75%,统计量q检出率提
升到67.13%,在190个样本点检测到故障的发生,故障检出时刻提前了170个样本点,同时相比与cvda方法具有最高的故障检出率。因此,本发明提供的wpcvda方法明显提高了对te过程故障21的检测性能。
[0183]
表3和表4分别给出了传统cvda方法和本发明wpcvda方法对于te过程故障11、15、19和21的故障检出率和故障检出时刻。
[0184]
表3
[0185][0186]
表4
[0187][0188]
由表3和表4可知,本发明提供的wpcvda方法总体上取得了最好的监控结果,具有最佳的故障检测性能。并且对于故障11、15、19和21这4个故障的监控效果改善尤为明显。
[0189]
综合以上分析,本发明提供的pwcvda方法,通过利用wasserstein距离挖掘化工过程数据所包含的概率信息并考虑特征带故障信息的差异性对特征进行在线加权,其故障检出效果要优于传统的cvda方法。
[0190]
以上所举实施例仅用为方便举例说明本发明,并非对本发明保护范围的限制,在本发明所述技术方案范畴,所属技术领域的技术人员所作各种简单变形与修饰,均应包含在以上申请专利范围中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。