1.本发明涉及计算机视觉识别领域,尤其涉及基于难样本挖掘的深度网络模型构建方法及系统。
背景技术:
2.近几年以来,由于深度神经网络技术的发展,计算机视觉得到了快速发展,其中包括图像分类、图像检索、目标检测、人脸识别、行人重识别、人体姿态估计、动作识别等典型任务。
3.基于深度学习视觉任务的发展主要依赖于损失函数、模型的网络结构和训练数据集的等方面发展,研究人员更多的致力于构建新的损失函数来提升模型的判别力。中心损失函数在人脸识别中被证明能够有效的增强人脸特征分布的紧凑型,并且提升模型性能。近几年以来,基于角边界裕量的softmax损失的方法在计算机视觉领域得到了广泛应用,特别是在人脸识别、行人重识别、图像检索等任务上实现了先进水平。
4.难样本挖掘技术作为提升训练速度与模型泛化能力的重要手段,在深度度量学习领域应用广泛。难样本挖掘技术通常与损失函数相关,不同的损失函数可能会采用不同的难样本挖掘方法以应对损失函数所面临的问题。在深度度量学习领域使用广泛的tripletloss(三元损失)和contrastive loss(对比损失),通过难样本挖掘构建三元组或者样本对可以加快训练过程,并提升模型的拟合能力。然而,目前广泛使用的基于角边界裕量(margin)的softmax损失方法,由于模型训练更容易,识别精度高,通常忽略了对难样本的研究。事实上,基于角边界裕量softmax损失的方法依然存在一些局限性,一定程度上限制了模型的识别能力。
技术实现要素:
5.本发明提供了基于难样本挖掘的深度网络模型构建方法及系统,用于解决现有的计算机视觉方法在实际应用中识别精度低、鲁棒性差的技术问题。
6.为解决上述技术问题,本发明提出的技术方案为:
7.一种基于难样本挖掘的深度网络模型构建方法,包括:
8.构造深度网络模型,输入训练样本对所述深度网络模型进行训练:
9.在每次迭代训练过程中:
10.抽取训练样本的特征向量,计算所述特征向量及其类中心权重向量之间的角边界裕量,并根据所述角边界裕量判断所述特征向量是否为类内难样本,根据判断结果对所述特征向量进行难样本标记;其中,所述类中心权重向量为样本所属类别的地面真值权重
11.基于标记后的特征向量计算深度网络模型输出的角边界裕量损失值与类内难样本损失值,并结合角边界裕量损失值与类内难样本损失值,优化深度网络模型的网络参数。
12.优选的,计算所述特征向量及其类中心权重向量之间的角边界裕量,并根据所述
角边界裕量判断所述特征向量是否为类内难样本,包括以下步骤:
13.计算所述特征向量与其非地面真值类中心权重向量之间的夹角,并从所述夹角中选择最小类间角min(inter),计算所述最小类间角的余弦值cos(min(inter));
14.筛选特征向量与其类中心权重向量的角边界裕量余弦值小于所述余弦值cos(min(inter))的特征向量作为类内难样本。
15.优选的,计算所述特征向量与其非地面真值类中心权重向量之间的夹角,通过以下公式实现:
[0016][0017]
式中,xi为第i类特征向量,wj为第j个非地面真值类中心权重向量。
[0018]
优选的,根据判断结果对所述特征向量进行难样本标记,通过以下公式实现:
[0019][0020]
其中,h(x)表示标记函数,当特征向量为类内难样本时,标记为1,非难样本标记为0;yi代表第i类的地面真值;是一个边界裕量函数,用于计算所述特征向量在增加边界裕量之后到其类中心权重向量的余弦距离;是第i类特征向量与其类中心权重向量的夹角。
[0021]
优选的,结合角边界裕量损失值与类内难样本损失值,通过以下损失函数实现:
[0022][0023]
式中,n为训练的批量数,n为类别总数,是一个在单调递减的函数,yi代表第i类特征的地面真值;是一个边界裕量函数,用于计算类内样本特征向量在增加边界裕量之后到类中心权重向量的余弦距离;是样本的特征向量与第i类特征的类中心权重向量的夹角,s是一个用于缩放的超参数,λ是一个用于调节难样本类内损失函数权重的超参数,θj是权重wj与特征向量xi之间的夹角。
[0024]
优选的,所述通过以下公式计算得到:
[0025][0026]
优选的,还包括以下步骤:
[0027]
采用训练好的深度网络模型进行视觉识别。
[0028]
一种计算机系统,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
[0029]
本发明具有以下有益效果:
[0030]
1、本发明中的基于难样本挖掘的深度网络模型构建方法及系统,通过构造深度网络模型,输入训练样本对所述深度网络模型进行训练:在每次迭代训练过程中抽取训练样本的特征向量,计算所述特征向量及其类中心权重向量之间的角边界裕量,并根据所述角边界裕量判断所述特征向量是否为类内难样本,根据判断结果对所述特征向量进行难样本
标记;基于标记后的特征向量计算深度网络模型输出的角边界裕量损失值与类内难样本损失值,并结合角边界裕量损失值与类内难样本损失值,优化深度网络模型的网络参数。本发明考虑了类内难样本对模型精度的影响,在训练模型时,结合基于角边界裕量损失与类内难样本损失对训练过程进行监督,能提升类内特征分布的紧凑性,从而提升模型的判别力,即在训练过程中更加强调困难样本特征分布的紧凑性,从而使得类内特征分布整体上更加紧凑,模型获得更高的识别精度和更强的鲁棒性。
[0031]
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照附图,对本发明作进一步详细的说明。
附图说明
[0032]
构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0033]
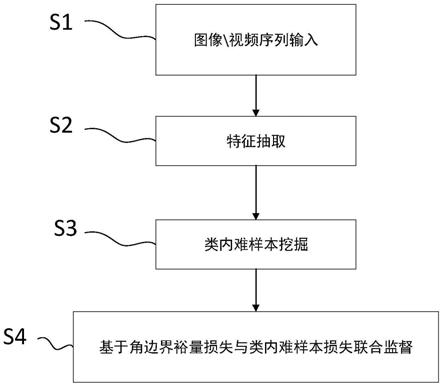
图1是本发明优选实施例中基于难样本挖掘的深度网络模型构建方法的流程图;
[0034]
图2是本发明优选实施例中的难样本挖掘的流程图。
具体实施方式
[0035]
以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
[0036]
实施例一:
[0037]
本实施中公开了一种基于难样本挖掘的深度网络模型构建方法,包括:
[0038]
构造深度网络模型,输入训练样本对所述深度网络模型进行训练:
[0039]
在每次迭代训练过程中:
[0040]
抽取训练样本的特征向量,计算所述特征向量及其类中心权重向量之间的角边界裕量,并根据所述角边界裕量判断所述特征向量是否为类内难样本(下文简称难样本),根据判断结果对所述特征向量进行难样本标记;其中,所述类中心权重向量为样本所属类别的地面真值权重即模型权重的第yi行向量。
[0041]
基于标记后的特征向量计算深度网络模型输出的角边界裕量损失值与类内难样本损失值,并结合角边界裕量损失值与类内难样本损失值,优化深度网络模型的网络参数。
[0042]
此外,在本实施例中,还公开了一种计算机系统,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
[0043]
本发明中在训练过程中更加强调困难样本特征分布的紧凑性,从而使得类内特征分布整体上更加紧凑,模型获得更高的识别精度和更强的鲁棒性。
[0044]
实施例二:
[0045]
实施例二是实施例一的优选实施例,其与实施例一的不同之处,对基于难样本挖掘的深度网络模型构建方法的具体步骤进行了细化:
[0046]
在本实施例中,公开了一种基于难样本挖掘的深度网络模型构建方法,包括以下步骤:
[0047]
构造深度网络模型,输入训练样本对所述深度网络模型进行训练:
[0048]
在每次迭代训练过程中:
[0049]
抽取训练样本的特征向量,计算所述特征向量及其类中心权重向量之间的角边界裕量,并根据所述角边界裕量判断所述特征向量是否为难样本,根据判断结果对所述特征向量进行难样本标记;
[0050]
其中,筛选并标记正难样本,采用样本距离非地面真值(non-ground truth)类中心权重向量的最小角的余弦值作为判断依据,表示为:cos(min(inter))。如果存在距离地面真值(ground truth)类中心权重向量的角边界裕量的余弦值小于cos(min(inter))的样本,则将该样本被标记为难样本。其中,样本距离类中心权重向量的角度在[0,π]范围内,其对应的余弦值单调递减,角度越小,余弦值越大。难样本判断的具体公式定义如下:
[0051][0052]
其中,yi代表第i类的地面真值;是一个边界裕量函数,用于计算类内样本特征向量在增加边界裕量之后到类中心权重向量的余弦距离;是样本的特征向量与类i的类中心权重向量的夹角。
[0053]
基于标记后的特征向量计算深度网络模型输出的角边界裕量损失值与类内难样本损失值,并结合角边界裕量损失值与类内难样本损失值,优化深度网络模型的网络参数。
[0054]
其中,计算类内难样本损失值通过难样本类内损失函数实现,难样本类内损失函数用于优化类内正难样本的特征分布,提升类内紧凑性。其公式定义如下:
[0055][0056]
其中,是一个在单调递降的函数,其定义如下:
[0057][0058]
进一步的,结合角边界裕量损失值与类内难样本损失值,优化深度网络模型的网络参数通过以下损失函数实现:
[0059][0060]
其中,s是一个用于缩放的超参数,λ是一个用于调节难样本类内损失函数权重的超参数,θj是权重wj与特征xi之间的夹角。
[0061]
具体的,本实施例中的深度网络模型可应用与各种视觉识别任务中,包括但不限于图像分类、图像检索、目标检测、人脸识别、行人重识别、人体姿态估计、动作识别等典型任务。
[0062]
具体的,本实施例中的深度网络模型可采用alexnet、vggnet、inception、resnet、densenet以及mobilenet中任意一种或几种的组合,具体模型框架可根据应用场景以及需求,结合经验选取或搭建,在此不做限定。
[0063]
实施例三:
[0064]
实施例三是实施例二的优选实施例,其与实施例一的不同之处,对基于难样本挖掘的深度网络模型构建方法在人脸识别领域的应用进行了具体介绍:
[0065]
在本实施例中,如图1所示,公开了一种基于难样本挖掘的深度网络模型构建方法,所述深度网络模型用于人脸识别,包括以下步骤:
[0066]
s1、图像输入,人脸训练图像采用112*112像素尺寸,利用mtcnn进行人脸检测并对齐;
[0067]
s2、特征抽取,对当前迭代过程中人脸图像进行特征抽取,为获得更强的特征表示能力,选择特征维度为512,采用resnet100作为模型的网络结构;
[0068]
s3、类内难样本挖掘,根据难样本选择公式(3)完成当前迭代过程中难样本的筛选、标记;
[0069]
其中,如图2所示,类内难样本挖掘具体包括以下步骤:
[0070]
101)计算样本特征xi与非地面真值类中心权重向量wj之间的夹角,公式定义为:
[0071][0072]
102)计算样本特征与非地面真值类中心权重向量的最小角的余弦值,表示为cos(min(inter))。其中min(inter)为最小类间角,也就是样本特征xi与非地面真值类中心权重向量wj之间的夹角的最小值。
[0073]
103)筛选类内样本特征与类中心权重向量的角边界裕量余弦值小于cos(min(inter))的难样本。其中,本实施例采用arcface,直接在角上加边界裕量,难样本选择函数等价于:
[0074][0075]
其中,m为边界裕量超参数,训练中设置为0.5。
[0076]
104)标记当前迭代中的难样本。
[0077]
s4、基于角边界裕量损失与类内难样本损失联合监督训练,本实施例采用基于角边界裕量损失中的典型代表arcface,并结合所述类内难样本损失进行联合监督训练深度网络模型。联合损失函数定义如下:
[0078][0079]
其中,m为边界裕量超参数,训练中设置为0.5,λ设置为10,s设置为64。
[0080]
综上所述,本发明中的基于难样本挖掘的深度网络模型构建方法及系统,通过构造深度网络模型,输入训练样本对所述深度网络模型进行训练:在每次迭代训练过程中抽取训练样本的特征向量,计算所述特征向量及其类中心权重向量之间的角边界裕量,并根据所述角边界裕量判断所述特征向量是否为难样本,根据判断结果对所述特征向量进行难样本标记;基于标记后的特征向量计算深度网络模型输出的角边界裕量损失值与类内难样本损失值,并结合角边界裕量损失值与类内难样本损失值,优化深度网络模型的网络参数,本发明考虑了类内难样本对模型精度的影响,在训练模型时,结合基于角边界裕量损失与类内难样本损失对训练过程进行监督,能提升类内特征分布的紧凑性,从而提升模型的判别力,即在训练过程中更加强调困难样本特征分布的紧凑性,从而使得类内特征分布整体上更加紧凑,模型获得更高的识别精度和更强的鲁棒性。
[0081]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。