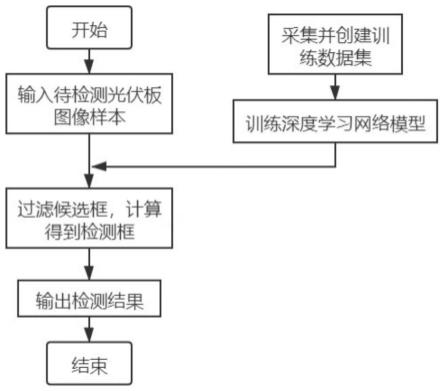
1.本发明涉及一种基于分支-主干网络的多分辨率人脸识别方法,属于人工智能、深度学习以及计算机视觉技术领域。
背景技术:
2.多分辨率人脸识别,按照图像的分辨率可分为三种变体:(1)低分辨率与低分辨率图像匹配(low resolution-to-low resolution matching,lr-to-lr matching):查询集(probe)和参考集(gallery)图像都是低分辨率;(2)低分辨率与高分辨率图像匹配(low resolution-to-high resolution matching,lr-to-hr matching):低分辨率probe图像与高分辨率gallery图像;(3)高分辨率与高分辨率图像匹配(high resolution-to-high resolution matching,hr-to-hr matching):probe和gallery图像都是高分辨率。按照1:1或1:n的匹配,可分为两种任务,一是1:1人脸验证(face verification),二是1:n人脸识别(face identification)。现有的人脸识别方法对低分辨率图像的处理存在缺陷,因此将(1)(2)合并为低分辨率人脸识别,是多分辨率人脸识别技术的核心。
3.近年来,借助于深度神经网络和大规模数据集,人脸识别技术发展迅速。现存的主流人脸识别方法能够在高分辨率的人脸数据集上达到非常高的识别精度。然而,由于训练和测试数据之间的分辨率不匹配,最先进的(state-of-the-art,sota)人脸识别模型在含有低分辨率图像的识别任务中表现不佳。具体而言,在lr-to-lr与lr-to-hr matching任务中,识别精度会急剧下降。
4.将不同的分辨率视作不同的域(domain),多分辨率人脸识别的任务是弥补各种分辨率域之间的差异性。现存的主流方法可以分为两类:投影方法(耦合映射)和合成方法(超分辨率)。
5.投影方法旨在提取不同域中图像的充分特征表示,并将它们投影到公共特征空间中。z.lu等在deep coupled resnet for low-resolution face recognition(in ieee signal process.lett.,25(4):526
–
530,2018)中提出的deep coupled resnet(dcr)方法是一种主干到分支的网络结构,包含一个主干网络用于提取不同分辨率人脸图像共享的识别特征,以及两个分支网络分别将高分辨率和对应低分辨率的人脸图像特征映射到一个公共特征子空间,使其距离最小化。l.s.luevano等在tcn:transferable coupled network for crossresolution face recognition(in proc.ieee int.conf.acoust.,speech signal process.,2019)中提出的transferable coupled network(tcn),采用了一种用于低分辨率网络的可转移三重损失(transferable triple loss,ttl),通过从预训练的高分辨率网络中提取出的信息来学习降低低分辨率和高分辨率域之间的差异性。
6.另一类是基于超分辨率(super-resolution,sr)的方法。超分辨率方法旨在上采样低分辨率图像以重构对应的高分辨率图像并将其用于特征提取。x.yin等在fan:feature adaptation network for surveillance face recognition and normalization(arxiv preprint arxiv:1911.11680,2019)中提出了特征适应网络(feature adaptive network,
radar,sar)遥感图像中的相应斑块。这是因为sar和光学图像位于不同的域,所以完全耦合的孪生网络不适应该识别任务。而伪孪生网络的结构有助于同时表达不同域图像之间的特征相似点和差异性。
技术实现要素:
13.本发明的目的是为了克服现有技术存在的缺陷,为实现多分辨率图像的统一表征,提升多分辨率人脸识别的精度,降低计算复杂度,创造性地提出了一种基于分支-主干网络的多分辨率人脸识别方法,其中,分支-主干网络,即branch-to-trunk network,简称btnet。
14.由于上采样并非解决lr-to-hr matching分辨率不匹配问题的有效方法,且lr-to-lr matching的性能受到上采样的限制。因此,上采样给低分辨率人脸识别带来的问题是不可忽略的,选择从输入图像的原始分辨率开始编码而非上采样到统一大小后再进行编码。t.-y.lin在feature pyramid networks for object detection(in proc.cvpr,2017)中通过卷积神经网络构建了特征金字塔。它是一种自顶而下的层次性架构,由不同分辨率的特征图组成,可以作为多个输入的连接口。由于图像金字塔和特征金字塔的尺度变化的连续性,具有相同分辨率的图像和其对应特征图之间存在相似性。然而,网络起始层的特征提取对于分辨率十分敏感。输入图像的分辨率不匹配会导致特征金字塔下部的特征图不一致。尤其对于超低分辨率的人脸图像(低于28
×
28)而言尤为突出,而这种不一致性会在特征金字塔中从下向上传播,影响最终获得统一的特征表示。
15.本发明的创新点在于:为了能够在网络更深层针对不同分辨率的输入图像中获得相似的特征图,从输入层开始便针对不同分辨率进行特定的特征提取。将具有不同分辨率的图像视为不同的域,基于高分辨率人脸识别进行迁移学习,由此解决分辨率不匹配的技术问题。与典型的迁移学习不同的是,分辨率空间是一个无穷的连续变化空间,因此存在无穷的域。在避免上采样的前提下,用有限数量的分辨率适配器来分别处理不同图像,降低无穷多的分辨率域之间的差异,同时保证由统一的编码器输出不同分辨率图像的统一表征。
16.本发明通过以下技术方案实现。
17.一种基于分支-主干网络的多分辨率人脸识别方法,包括以下步骤:
18.步骤1:搭建一个通用的端到端分支-主干网络btnet。
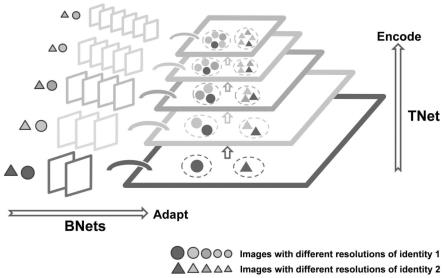
19.由于只有一种特定的高分辨率输入大小的网络会存在冗余的计算量,且仍然存在人为引入的错误。因此,本方法为多分辨率人脸识别搭建了一个通用的端到端分支-主干网络(btnet)。如图1所示,展示了btnet的基本思想。
20.btnet包括两个关键组件:分支网络(branch networks,bnets)和主干网络(trunk network,tnet)。
21.其中,分支网络(branch networks,bnets)是若干独立的子网络(例如,分辨率分别为28
×
28像素、14
×
14像素、7
×
7像素的子网络),用于将低分辨率图像(例如,分辨率不大于42
×
42像素)映射到具有相同分辨率的对应特征图;
22.主干网络(trunk network,tnet),是将不同分辨率的特征图映射到高维嵌入(例如512维、1024维等,具体取决于基础网络的结构),实现跨分辨率的统一编码。其中,主干网络具体可以选择各种基于金字塔层次结构的基础网络来实现。
23.采用btnet,避免了上采样的过程,实现了直接从输入图像的原始分辨率开始对其进行处理。
24.步骤2:选择btnet的基础网络。采用随机尺度方法进行预训练,得到主干网络tnet。
25.btnet作为一种通用的网络架构,可以选择各种基于金字塔结构的层次化图像特征提取网络作为基础网络,如resnet50,densenet201等。
26.随机尺度方法,即通过使用不同的插值采样方法和尺寸大小,模拟不同分辨率大小的人脸图像,从而为人脸表示构建具有分辨率鲁棒性的统一编码网络。
27.首先,针对高分辨率的人脸图像(通常不低于112
×
112像素),采用随机插值法(例如,最近邻插值、双线性插值、双三次插值、基于区域的插值、lanczos插值,等等)下采样到不同尺寸(例如,4
×
4像素至112
×
112像素等)。
28.然后,使用固定插值法(例如,用于放大图像的双三次插值)上采样回统一的高分辨率输入尺寸(例如不低于112
×
112像素)后,对基础网络进行训练。
29.基础网络通过以上的随机尺度方法,在高分辨率与合成得到的低分辨率人脸图像数据集上进行预训练后,学习得到具有分辨率鲁棒性和身份判别性的tnet,为bnets提供特征空间的监督信息。
30.步骤3:在深度方向部分耦合bnets和tnet,利用tnet的监督信息训练得到不同分辨率的分支网络bnets。
31.如图2所示,展示了两种不同的参数共享方案(网络耦合方式)。其中,宽度方向部分耦合,是将某一层的过滤器划分为共享卷积核与非共享卷积核,前者获取不同分辨率图像的共同特征,后者获取特定分辨率图像的专有特征。
32.但是,专有特征并未匹配,导致不能通过直接比较相似度来进行身份识别。因此,本方法采用在深度方向部分耦合。具体地,由多个并行的分支网络将各分辨率专有的特征转换为具备分辨率不变性的特征,获得用于身份识别的统一特征表示。
33.其中,各个bnet在固定tnet参数的情况下进行训练,将低分辨率图像近似映射到相同分辨率的特征图,该特征图从对应高分辨率图像中提取得到。
34.步骤4:对待识别图像进行分辨率裁剪(resolution trimming)。
35.由于实际输入图像的可能尺寸是无限的,而bnet的数量是有限的,因此在真实场景中检测到的人脸图像的尺寸并不与bnet的分辨率一一对应。尽管采用btnet可以大大降低上采样率,但由于过低分辨率图像进行小幅度上采样会不可避免地引入大量错误信息,因此,仅仅通过插值进行上采样依然不是最佳解决方案。
36.本发明通过替代对超低分辨率图像的上采样,构建分辨率修剪器对图像进行预处理(此处的图像指经检测、裁剪、对齐后的单张人脸图像),包括以下步骤:
37.步骤4.1:确定图像的代表分辨率。
38.忽略图像质量受损的情况,选择图像的长边尺寸作为表征图像隐含光学分辨率的可靠指标。
39.步骤4.2:选择合适的分支。
40.选择分辨率与给定图像分辨率最邻近的bnet,作为处理该输入图像的适配器。
41.步骤4.3:根据需要进行边缘填充。
42.如果图像的分辨率小于或等于选定bnet的分辨率,则按照bnet的分辨率对图像进行边缘填充。否则不进行填充处理。
43.步骤4.4:根据需要进行下采样。
44.如果图像的分辨率大于bnet的分辨率,则通过基于区域的插值对图像进行下采样,以匹配所选bnet的分辨率。否则不进行下采样处理。
45.图像经过分辨率修剪,能够与bnet的分辨率保持一致,而不会引入由上采样导致的错误信息。图3展示了分辨率修剪的两种可能情况。
46.步骤5:将经分辨率修剪后的图像输入btnet得到统一的特征表示,并按需求进行1:1人脸验证或1:n人脸识别。
47.步骤4输出的图像与btnet某一分支的分辨率一致(例如,112
×
112像素,28
×
28像素,14
×
14像素,7
×
7像素),因此可直接输入由对应bnet和tnet耦合得到的btnet,得到高维的特征向量(如512维、1024维等),并计算不同人脸特征向量间的余弦相似度,用于多分辨率人脸的1:1验证或者1:n的识别任务。
48.有益效果
49.本发明所述方法,与现有技术相比,具有如下有益效果:
50.1.本发明概念简洁,创新性强。首次基于多分辨率图像的原始信息进行编码,避免了对低分辨率图形的插值上采样,实验效果表明该模型的有效性。
51.2.本发明作为一个通用的网络架构,可以关联各种现存的人脸识别模型,并在降低计算基准模型复杂度的同时显著提升识别精度。
52.3.实验表明,本发明在精度和效率上都要明显优于基准模型,在不需要微调的条件下,btnet-r50模型在scface数据集d1距离实验上实现了现有的最佳效果(76.5%),但每秒浮点运算数(floating point operations per second,flops)比resnet50基准网络低4.0g。
53.4.本发明“分支适配-主干编码”的思想可以延伸到广泛的应用领域,实现不同场景下跨域(domain)的实体统一表征。
附图说明
54.图1为本发明btnet的示意图。首先某一特定实体的图像分别映射到相同分辨率的特征图,然后映射为一个统一的特征表示。其中,自底向上的轮廓图分别代表不同分辨率的特征图。
55.图2为不同方向的部分耦合方法的比较示意图。其中,一行代表网络的一层,包括一定数量的卷积核。
56.图3为分辨率裁剪的示意图。其中,左侧所示为边缘填充,右侧所示为下采样。
57.图4为本发明方法的网络结构示意图(以btnet-r50为例),展示了多分辨率人脸图像从输入到输出的全流程,其中“s”代表阶段(stage),“u”代表单元(unit),“/2”代表采用步长为2的卷积进行下采样。
具体实施方式
58.下面结合附图和实施例对本发明做进一步说明和详细描述。
59.实施例
60.本发明作为通用的网络框架,能关联现存的人脸识别方法。
61.例如,在两个基础模型resnet50和densenet201上,构建btnet-r50和btnet-d201,以进行基准测试。图4以btnet-r50为例,展示了本发明对图像处理的全流程。
62.其中,resnet50来自k.he在deep residual learning for image recognition(in proc.cvpr,2016)中提出的深度卷积网络。
63.densenet201来自g.huang在densely connected convolutional networks(in proc.cvpr,2017)中提出的深度卷积网络。
64.btnet可以看作是由多个独立的分支子网络(bnets)组成的“部分的孪生网络”,将给定的分辨率图像映射到特征金字塔中具有相同分辨率的对应特征图,然后直接耦合到主干子网络(tnet)用于进一步编码。
65.tnet:通过无适应(no adaptation,na)和随机尺度(random scale,rs)两种图像预处理方式,分别在包含了从85744个个体中获取的580万张图片构成的ms1m-arcface数据集上进行训练。对于na,图像的尺寸保持在112
×
112;对于rs,每张图像被等概率随机下采样到4到112之间的大小,然后通过双立方插值上采样回112
×
112。保存从嵌入表示映射到分类类别的权重矩阵,由于它象征着每个类的中心,从而保留了特征空间的信息。
66.bnets:针对不同的bnet对预训练好的模型进行微调。在训练每个bnet时,下采样层之后的层(分辨率与bnet相同或更小的层)的结构和参数是固定的,去除之前的下采样操作(用步长为1的卷积替代步长为2的卷积并且删去池化层)以重建同一分辨率的映射。对于每个具有特定分辨率的bnet,使用以该分辨率为中心的高斯分布对输入图像进行随机下采样,以适当缓解其对固定分辨率的依赖,然后依据采样结果对图像进行分辨率调整。使用j.deng等在arcface:additive angular margin loss for deep face recognition(in proc.cvpr,2019)中提出的arcface loss作为训练的损失函数。对于分辨率7、14、28的bnet,学习率分别初始化为0.1、0.03、0.01,并在100k,160k、220k次迭代时以0.1的系数降低。对btnet-r50使用从高斯分布中随机采样的xavier方法进行参数初始化,而对btnet-d201使用均匀采样的xavier初始化方法。对于btnet-r50,每个gpu的批大小设置为64,而对于btnet-d201设置为32。所有实验均在四块rtx2080ti上实现,总共训练20轮。
67.为验证本方法的有效性和通用性,在合成人脸数据集(synthetic face datasets)和原生人脸数据集(native face datasets)上进行了全面的验证实验。
68.首先,在四个人脸数据集上评估btnet:lfw、cfp-ff、cfp-fp、agedb-30。lfw广泛用于研究无约束的人脸识别问题,由5749个个体的13233张图像组成。cfp由500个受试者组成,每个受试者有10个正面图像和4个侧面图像,包括两个评估任务:正面-正面(cfp-ff)和正面-侧面(cfp-fp)的面部验证,分别具有10个文件夹,包含350个相同身份的配对和350个不同身份的配对。agedb-30包含16488张,共568人的图像,其年龄从1到101岁。
69.通过基于区域的插值方法将图像下采样到不同的低分辨率:28
×
28、14
×
14、7
×
7,从而构建合成人脸数据集。对于btnet以外的模型,需要进一步通过双三次插值将低分辨率人脸图像上采样到统一大小:112
×
112。基于两个不同的基础模型resnet50和densenet201,在lr-to-lr matching和lr-to-hr matching任务上比较btnet与na、rs方法。
70.表1给出了na、rs、btnet在两个基础模型上的验证精度。因为分辨率自适应的
btnet只需要专注于在很小的范围内捕捉特征的细微变化,所以在所有情况下都可以实现比na更高的准确度,在几乎所有情况下都实现比rs更高的准确度。
71.表1在合成数据集上的lr-to-lr,lr-to-hr匹配任务的准确性
[0072][0073][0074]
其中,“r50”代表resnet50,“d201”代表densenet201。特别的,hr-to-hr匹配(112&112)被用作对多分辨率人脸识别模型的基准测试。在btnet中,rs模型被用来作为主干子网络(tnet)。由于在hr-to-hr匹配中没有分支网络(bnets),btnet和rs模型达到了一样的识别精度。
[0075]
表2展示了不同方法下使用不同probe尺寸的flops。基准方法(例如,resnet50、densenet201)由于将低分辨率人脸图像上采样到统一输入大小而引入了大量不必要的计算。表1和表2中的结果表明,与低分辨率人脸识别的基准方法相比,btnet用更少的计算量得到了更好的识别精度。例如,对于在lfw数据集上分辨率为7的识别任务而言,btnet-r50的准确率相比na-r50提高了21.6%,相比rs-r50提高了4.9%,但flops比它们少近四分之一。实际应用场景下计算资源有限,本方法为低分辨率人脸识别部署应用提供了可行的替代方案。
[0076]
表2.不同方法采用不同probe尺寸时对应的flops(g)
[0077]
probe size112
×
11228
×
2814
×
147
×
7r50[20]12.612.612.612.6btnet-r5012.610.58.63.0d201[21]8.58.58.58.5btnet-d2018.56.75.11.8
[0078]
其中,“r50”代表resnet50,而“d201”代表densenet201。
[0079]
上述合成的低分辨率人脸图像都是通过一定的下采样操作生成的。然而,一种特定的下采样方法不能完全模拟原生低分辨率人脸图像的质量下降,而受损的图像质量会放大分辨率不匹配的问题。由于原生的低分辨率人脸数据集的稀缺性,无法从头开始训练低分辨率人脸图像。这种矛盾可能会导致btnet的优势被数据域的巨大差异所掩盖。为了评估模型的泛化性能,在未进行微调的前提下评估btnet在原生人脸数据集scface上的性能。
[0080]
scface是一个原生的人脸数据集,其中包含130个个体的4160张图像,这些图像是使用各种质量的监控摄像头在无约束的室内环境中拍摄的。在可见光谱中,每个个体总共包含15张图像,位于三个不同的距离:d1(4.2m)、d2(2.6m)和d3(1.0m)。
[0081]
按照m.grgic等在scface
–
surveillance cameras face database(in multimedia tools and applications,51(3):863
–
879,2011)中的设置,将正面面部照片作为gallery图像,将五个视频监控摄像机分别从三个距离拍摄的图像作为probe图像。首先,采用k.zhang等在joint face detection and alignment using multitask cascaded convolutional networks(in ieee signal processing letters,23(10):1499-1503,2016)中提出的mtcnn方法检测、裁剪、对齐输入人脸图像;然后,gallery图像被下采样到统一大小112
×
112,probe图像通过分辨率修剪器进行预处理,并分配给适当的bnet。
[0082]
如表3所示,btnet显著提高了两个基础模型的性能。考虑到我们的模型没有在scface数据集上进行微调,这表明我们提出的模型具有显著的通用性。
[0083]
表3在scface数据集上的人脸匹配rank-1准确率(%)
[0084][0085]
其中,“r50”代表resnet50,“d201”代表densenet201。
[0086]
ricnn是d.zeng等在towards resolution invariant face recognition in uncon-trolled scenarios(in proc.int.biometrics,2016)中提出的人脸识别方法。
[0087]
lightcnn是x.wu等在a light cnn for deep face representation with noisy labels(in ieee transactions on information forensics and security,13(11):
2884
–
2896,2018)中提出的人脸识别方法。
[0088]
vggface是o.m.parkhi等在deep face recognition(in proc.british machine vision conf,2015)中提出的人脸识别方法。
[0089]
centerloss是y.wen等在a discriminative feature learning approach for deep face recognition(in proc.eccv,2016)中提出的人脸识别方法。
[0090]
为了比较下采样导致的信息丢失和上采样导致的错误信息对识别精度的影响,将probe图像下采样到不同的分辨率(28
×
28、14
×
14、7
×
7)并使用对应分辨率的btnet来获得缩小后的人脸图像的特征表示。
[0091]
表4不同分辨率的分支情况下btnet在scface数据集上的人脸匹配rank-1准确率(%)
[0092]
distanced1d2d3avg.btnet-r50-r2868.397.498.988.2btnet-r50-r1476.583.788.582.9btnet-r50-r79.518.719.415.9btnet-d201-r2848.692.393.178.0btnet-d201-r1451.262.262.658.7btnet-d201-r79.814.216.213.4
[0093]
其中,“r28”,“r14”,“r7”分别代表分辨率为28,14,7的分支。
[0094]
如表4所示,对于d2和d3,在probe图像下采样到14
×
14和7
×
7时,与缩放到112
×
112相比,识别准确度都会下降。特别的是,可以看到分辨率为7
×
7的原生人脸图像几乎失去了它们的身份判别信息,因为低质量图像可能具有甚至低于7
×
7的光学分辨率,即使是专业的人员也很难通过肉眼进行识别。这一假设得到了进一步证明:对于从d1拍摄的probe图像,它在下采样到14
×
14时比28
×
28表现更好,这在所有未在scface上进行微调的方法中达到了最佳效果。可以得出结论,由于噪声、模糊、遮挡等导致质量下降,原生人脸图像通常具有显著低于其尺寸的隐含分辨率(例如,从d1拍摄得到的probe图像隐含分辨率平均小于28)。
[0095]
实验表明,尽管使用了不同的基准网络,btnet在两种设定:lr-to-lr matching和lr-to-hr matching,以及两种数据集:合成人脸数据集和原生人脸数据集下都可以带来显著的性能进步。这表明,通过避免上采样,btnet的网络结构是降低不同分辨率域之间差异的有效方法,因此能够有效地改进低分辨率图像表征,实现多分辨率人脸识别。此外,分辨率分支网络还可以进一步扩展到域分支网络,以用于其他迁移学习的场景。分支到主干的网络架构,能够有效且高效地提高模型对不同因素(包括但不限于分辨率)差异的适应性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。