技术特征:
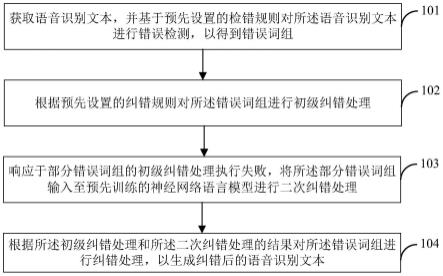
1.一种语音识别文本的处理方法,其特征在于,所述方法包括:获取语音识别文本,并基于预先设置的检错规则对所述语音识别文本进行错误检测,以得到错误词组,所述检错规则基于分词词典和统计学语言模型设置;根据预先设置的纠错规则对所述错误词组进行初级纠错处理,所述纠错规则基于预定语言模型构建而成;响应于部分错误词组的初级纠错处理执行失败,将所述部分错误词组输入至预先训练的神经网络语言模型进行二次纠错处理;根据所述初级纠错处理和所述二次纠错处理的结果对所述错误词组进行纠错处理,以生成纠错后的语音识别文本。2.根据权利要求1所述的方法,其特征在于,所述统计学语言模型为n元模型n-gram语言模型,基于预先设置的检错规则对所述语音识别文本进行错误检测包括:基于所述分词词典对所述语音识别文本进行分词处理;基于所述n-gram语言模型对分词处理后的每个字在上下文中出现的概率进行错误检测。3.根据权利要求1所述的方法,其特征在于,所述预定语言模型为word2vec模型,基于预定语言模型构建所述纠错规则包括:将预定专业词语输入至所述word2vec模型,以输出拼音相似的多个候选词;根据所述预定专业词语和相应的多个候选词构建所述纠错规则。4.根据权利要求3所述的方法,其特征在于,根据预先设置的纠错规则对所述错误词组进行初级纠错处理包括:将所述错误词组与所述纠错规则中的候选词进行匹配操作;响应于匹配操作成功,根据与匹配到的候选词相应的预定专业词语对错误词组进行纠错处理。5.根据权利要求1所述的方法,其特征在于,所述神经网络语言模型为双向rnn模型,将所述部分错误词组输入至预先训练的神经网络语言模型进行二次纠错处理包括:将所述部分错误词组中的错误词组拼音、错误词组的上下文及该上下文的拼音输入至所述双向rnn模型进行二次纠错处理,以生成与该错误词组相应的多个候选词。6.根据权利要求5所述的方法,其特征在于,所述方法还包括:根据所述与该错误词组相应的多个候选词与该错误词组之间的拼音相似度进行二次纠错处理。7.根据权利要求5所述的方法,其特征在于,通过如下方式训练所述双向rnn模型:获取历史语音识别文本,所述历史语音识别文本包括:历史准确文本和历史错误文本;根据所述历史准确文本和所述历史错误文本的文字及拼音对所述双向rnn模型进行训练。8.一种语音识别文本的处理装置,其特征在于,所述装置包括:错误检测单元,用于获取语音识别文本,并基于预先设置的检错规则对所述语音识别文本进行错误检测,以得到错误词组,所述检错规则基于分词词典和统计学语言模型设置;初级纠错处理单元,用于根据预先设置的纠错规则对所述错误词组进行初级纠错处理,所述纠错规则基于预定语言模型构建而成;
二次纠错处理单元,用于响应于部分错误词组的初级纠错处理执行失败,将所述部分错误词组输入至预先训练的神经网络语言模型进行二次纠错处理;语音识别文本纠错单元,用于根据所述初级纠错处理和所述二次纠错处理的结果对所述错误词组进行纠错处理,以生成纠错后的语音识别文本。9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现权利要求1至7中任一项所述方法的步骤。10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1至7中任一项所述方法的步骤。
技术总结
本发明公开了一种语音识别文本的处理方法、装置、电子设备及存储介质,涉及人工智能领域,其中,该方法包括:获取语音识别文本,并基于预先设置的检错规则对所述语音识别文本进行错误检测,以得到错误词组,所述检错规则基于分词词典和统计学语言模型设置;根据预先设置的纠错规则对所述错误词组进行初级纠错处理,所述纠错规则基于预定语言模型构建而成;响应于部分错误词组的初级纠错处理执行失败,将所述部分错误词组输入至预先训练的神经网络语言模型进行二次纠错处理;根据所述初级纠错处理和所述二次纠错处理的结果对所述错误词组进行纠错处理,以生成纠错后的语音识别文本。通过本发明,可以提高语音识别的准确率。可以提高语音识别的准确率。可以提高语音识别的准确率。
技术研发人员:刘华杰 冯歆然 王雅欣 王娜
受保护的技术使用者:中国工商银行股份有限公司
技术研发日:2022.03.14
技术公布日:2022/6/7
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。