1.本发明涉及生成牙弓的图像。本发明尤其涉及用于在图像中逼真地可视化易于影响受益人、例如经受正畸治疗的患者的牙弓的牙科事件的影响的方法。
背景技术:
2.pct/ep2019/068558描述了一种方法,在该方法中,牙弓的数字三维模型、特别是牙科专业人员进行的扫描,被变形以模拟(也就是说,被适应以人工再现)在过去的模拟时间预期的或在未来的模拟时间预测的牙齿状况。变形后的模型用于创建与照片等效的超逼真视图。
3.因此,人们必须去看正畸医生才能创建他们的牙弓模型。因此,该方法的应用领域受到限制。
4.因此,需要一种用于生成牙弓图像的方法,该牙弓图像模拟牙科事件的影响并且不需要生成模型。
5.本发明的一个目的是解决这一需要。
技术实现要素:
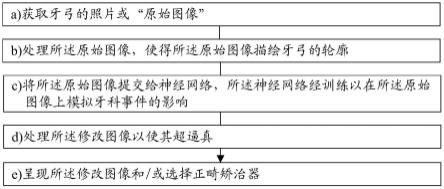
6.根据第一主要方面,本发明涉及一种用于生成受益人的称为“修改图像”的牙弓的图像的方法,所述方法包括以下连续步骤:
7.a)在获取时间,获取描绘所述牙弓的称为“原始图像”的照片;
8.b)处理所述原始图像,使得所述原始图像描绘辨别信息、优选牙弓的轮廓;
9.c)将所述原始图像提交给称为“模拟神经网络”的神经网络的输入,所述神经网络经训练,以在所述原始图像上模拟牙科事件的影响,从而获得所述修改图像;
10.d)优选地,处理所述修改图像以使其超逼真;
11.e)优选地,
[0012]-呈现所述修改图像,优选地至少呈现给所述受益人和/或牙科专业人员;和/或
[0013]-选择正畸矫治器,由计算机和/或受益人和/或牙科专业人员基于修改图像执行,然后优选地制造所述正畸矫治器。
[0014]
如将在说明书的其余部分中更详细地看到的,根据本发明的生成方法不需要生成受益人牙弓的模型。值得注意的是,任何人,无论是否经受治疗,都能够模拟牙科事件对其牙齿的影响,而无需去看正畸医生。
[0015]
特别是,修改图像描绘了在应用牙科事件后模拟的牙弓。因此受益人可以从模拟中受益,从而允许他们准确地衡量牙科事件的视觉影响。
[0016]
根据本发明的生成方法还可以包括以下可选特征中的一个或多个:
[0017]
–
牙科事件选自正畸或非正畸治疗情况下的时间流逝、病理学或磨牙症情况下的时间流逝、牙科构件在牙弓上的装配、没有治疗的情况下的时间流逝、以及这些牙科事件的组合;
[0018]
–
辨别信息选自:轮廓信息、颜色信息、密度信息、距离信息、亮度信息、饱和度信息、关于反射的信息、以及这些信息的组合;
[0019]
–
模拟神经网络通过根据本发明的训练方法进行训练,如下所述;
[0020]
–
重复步骤1)到4)的循环,在每个步骤4)结束时修改第一观察条件;
[0021]
–
在步骤a)中,在受益人优选佩戴牙科牵开器的情况下,通过口外方式获取照片,优选使用手机获取照片;
[0022]
–
所述方法包括处理所述修改图像以使其超逼真的步骤d),步骤d)包括以下步骤:
[0023]
d0)对于称为“纹理照片”的每张照片,从包含多于1000张纹理照片的集合描绘牙弓,
[0024]
处理所述纹理照片,优选如步骤b)处理所述纹理照片,以获得描绘轮廓的称为“纹理图像”的图像;
[0025]
d1)创建由称为“纹理记录”的记录组成的所谓的“纹理”学习库,每个纹理记录包括纹理照片和通过在步骤d0)中处理所述纹理照片而获得的纹理图像;
[0026]
d2)通过纹理学习库训练称为“纹理神经网络”的神经网络;
[0027]
d3)将修改图像提交给经训练的纹理神经网络,以获得超逼真的修改图像;
[0028]
–
牙科事件是从获取时间到获取时间之前或之后多于1天的模拟时间的时间流逝,并且在步骤e)中,将修改图像呈现给受益人,以便向受益人展示在所述模拟时间确定的、即模拟的牙齿状况;
[0029]
–
在步骤c)之前,通过指定模拟时间和/或应用于受益人的治疗参数和/或受益人佩戴的正畸矫治器的参数、和/或受益人的功能参数、和/或受益人的解剖参数而不是他们牙齿的定位参数、和/或受益人的年龄或年龄段和/或性别,来确定牙科事件;
[0030]
–
步骤a)到e)循环重复,连续获取原始图像,每个循环持续小于5秒,优选小于1秒。
[0031]
根据第二主要方面,本发明涉及一种用于训练神经网络的方法,对于称为“历史模型”的“历史”牙弓的多个数字三维模型中的每一个,所述方法包括以下连续的步骤1)至3):
[0032]
1)在第一观察条件下获取历史模型的第一视图,如果所述第一视图没有描绘历史牙弓的称为“第一辨别信息”的辨别信息、优选地没有描绘历史牙弓的称为“第一轮廓”的轮廓,则处理所述第一视图以使其描绘所述第一辨别信息、优选第一轮廓;
[0033]
2)修改所述历史模型,例如通过变形和/或添加牙科构件来修改所述历史模型,以再现牙科事件对所述历史牙弓的影响;
[0034]
3)在与第一观察条件相同的第二观察条件下获取历史模型的第二视图,如果所述第二视图没有描绘所述历史牙弓的称为“第二辨别信息”的辨别信息,特别是如果所述第二视图没有描绘历史牙弓的称为“第二轮廓”的轮廓,则处理第二视图以使其描绘所述第二辨别信息、优选第二轮廓,并使用第一视图和第二视图创建历史记录;
[0035]
然后,为所有历史模型创建所有历史记录:
[0036]
4)在神经网络的输入和输出处分别引入所述第一视图和第二视图,以训练所述神经网络将描绘分析牙弓的输入视图转换为描绘在应用所述牙科事件后的分析牙弓的输出视图。
[0037]
在相同的观察条件下观察历史模型可以很容易地获得完美对准的第一视图和第二视图。不需要裁剪。
程度的校准参数。“灵敏度”是修改数字获取装置的传感器对入射光的反应的校准参数。
[0058]
在确定的观察条件下观察的模型称为“视图”。
[0059]“图像”是由像素形成的牙弓的二维描绘。因此,“照片”是用相机拍摄的特定图像,通常是彩色的。“相机”被理解为意指用于拍照的任何装置,包括专用相机、手机、平板电脑或计算机。视图是图像的另一个示例。
[0060]“牙弓照片”、“牙弓描绘”、“牙弓扫描”、“牙弓模型”、“牙弓图像”、“牙弓视图”或“牙弓轮廓”被理解为意指所述牙弓的全部或一部分(优选至少2颗、优选至少3颗、优选至少4颗牙齿)的照片、描绘、扫描、模型、图像、视图或轮廓。
[0061]“牙科事件”被理解为意指易于改变牙弓的事件,例如正畸矫治器的佩戴或简单的时间流逝。
[0062]“辨别信息”是能够从图像中提取的特征信息(“图像特征”),通常通过该图像的计算机处理来提取。
[0063]
辨别信息可以表现出可变数量的值。例如,轮廓信息可以表示像素属于轮廓的概率,并且例如采用0到255的值,0表示像素属于轮廓的概率非常低,255表示概率非常高。在一个实施方式中,辨别信息被阈值化,也就是说,仅描绘超过预定阈值的辨别信息。例如,在上述轮廓信息的示例中,仅描绘大于200的值。亮度信息可以采用很多值。图像处理使得可以提取和量化辨别信息。
[0064]
可以在图像(有时称为“图”)中描绘辨别信息。因此,图是处理图像以揭示辨别信息的结果。例如,牙齿和牙龈的轮廓可以是来自原始图像的轮廓信息的描绘。因此轮廓的描绘是以图像形式的轮廓信息的描绘。
[0065]“轮廓”是界定对象、优选地界定构成该对象的元素的一条线或一组线。例如,齿列的轮廓可以是限定该齿列的外部界限的线。优选地,“轮廓”还包括限定相邻牙齿之间的边界的线。因此优选地,齿列的轮廓由形成该齿列的牙齿的所有轮廓组成。
[0066]
图像中描绘的轮廓可能是完整的并因此自身是闭合的,或者是不完整的。
[0067]
牙弓的轮廓优选地描绘了该牙弓的齿列的轮廓,并且优选地,描绘了所描绘的每颗牙齿的轮廓,称为“基本轮廓”。
[0068]
在根据本发明的方法中,应用于图像的处理操作优选地被配置为揭示、优选地分离相同的轮廓、优选以下轮廓,这些轮廓包括如图7所描绘的牙齿的所有基本轮廓,优选地基本上由如图7所描绘的牙齿的所有基本轮廓组成。
[0069]“神经网络”或“人工神经网络”是本领域技术人员熟知的一组算法。要运行,必须通过来自学习库的称为“深度学习”的学习过程来训练神经网络。
[0070]“学习库”是适合于训练神经网络的计算机记录库。神经网络执行的分析的质量直接取决于学习库中的记录数量。通常,学习库包含多于10000条记录。
[0071]
神经网络的训练适于期望的目标,并且不会对本领域技术人员造成任何特别的困难。
[0072]
训练神经网络包括使其面对学习库,该学习库包含关于神经网络必须学习以进行“匹配”的两种类型的对象的信息,即相互关联的信息。
[0073]
可以根据由“对”记录组成的“成对”学习库或“具有对”的学习库来执行训练,也就是说,每个记录都包括用于神经网络的输入的第一类型的第一对象,以及用于神经网络的
输出的第二类型的第二相应对象。也可以说神经网络的输入和输出是“成对的”。用所有这些对训练神经网络会教神经网络根据第一类型的任何对象中提供第二类型的相应对象。
[0074]
例如,学习库中的每个记录可以包括牙弓模型的第一视图和在牙科事件发生之后该模型的第二视图。在使用该学习库进行训练后,神经网络将能够将牙弓模型的视图转换为该模型的经修改的视图,以模拟所述牙科事件的影响。
[0075]
加州大学伯克利分校伯克利人工智能研究(bair)实验室的phillip isola jun-yan zhu、tinghui zhou、alexei a.efros的文章“image-to-image translation with conditional adversarial networks”示出了配对学习库的使用。
[0076]
在本说明书中,为了清楚起见,使用了限定词“历史”、“原始”、“纹理”、“模拟”和“分析”。
[0077]
除非另有说明,否则“包括”或“具有”或“表现出”应被非限制性地解释。
附图说明
[0078]
通过阅读以下详细描述和研究附图,本发明的其他特征和优点将变得更加明显,其中:
[0079]-[图1]图1示意性地示出了根据本发明的图像生成方法的一个优选实施方式的各个步骤;
[0080]-[图2]图2示意性地示出了根据本发明的训练方法的一个优选实施方式的各个步骤;
[0081]-[图3]图3示出了在步骤a)中获取的照片的一个示例,以及通过根据本发明的方法获得的修改图像的示例,该方法使用诸如图7中的记录进行训练;
[0082]-[图4]图4示出了牙弓模型的一个示例;
[0083]-[图5]图5示出了牙弓模型的视图;
[0084]-[图6]图6示出了牵开器的一个示例;
[0085]-[图7]图7示出了用于训练模拟神经网络的记录的一个示例,以模拟事件“使用带有弓丝和托槽的正畸矫治器进行正畸治疗”,左侧图像和右侧图像分别在模拟神经网络的输入和输出处引入;
[0086]-[图8]图8示出了被分为多个牙齿模型的模型的一个示例,未示出牙弓的其他元素。
具体实施方式
[0087]
以下详细描述是优选实施方式的详细描述,但不是限制性的。
[0088]
特别是,以下详细描述描述了辨别信息、即轮廓信息的使用。然而,辨别信息可以是另一种类型。
[0089]
训练神经网络
[0090]
根据本发明的用于训练神经网络的方法优选地包括步骤1)至4)(图1)。
[0091]
该方法的步骤1)至3)有利地使得可以增加在步骤4)中使用的记录的数量。
[0092]
在这些步骤之前,生成一个、优选地多个、优选地多于100个、优选地多于1000个、优选地多于10000个历史模型。
[0093]
每个历史模型都描绘了所谓的“历史”个体的牙弓。
[0094]
历史模型可以根据对历史个体的牙齿或他们牙齿的铸型(例如石膏铸型)进行的测量来制备。
[0095]
历史模型优选地从真实状况中获得,优选地使用3d扫描仪创建。这种模型称为“3d”模型,可以从任何角度观察(图4)。
[0096]
优选地,历史模型被划分。特别地,优选地,对于每颗牙齿,所述牙齿的模型或“牙齿模型”基于历史模型来定义。
[0097]
将牙弓的历史模型划分为多个牙齿模型是一种常规操作,通过该操作划分牙弓模型以便界定模型中一颗或多颗牙齿的描绘(图8)。
[0098]
历史模型可以由操作者使用计算机手动划分,或者由计算机自动划分,优选通过实施深度学习装置、优选神经网络来划分。特别地,牙齿模型可以如例如在国际申请pct/ep2015/074896中所描述的那样定义。
[0099]
在历史模型中,牙齿模型优选地由牙龈边缘界定,牙龈边缘可以分解为内牙龈边缘(相对于牙齿在口腔内侧的一侧),外牙龈边缘(相对于牙齿面向口腔外侧的一侧)和两个侧牙龈边缘。
[0100]
类似地,基于历史模型,可以定义除牙齿模型之外的基本模型,特别是舌头和/或嘴巴和/或嘴唇和/或颌部和/或牙龈和/或牙科构件、特别是正畸矫治器的模型。
[0101]
在一个实施方式中,历史模型是理论的,也就是说不对应于真实状况。特别地,可以通过组装从数字图书馆中选择的一组牙齿模型来创建历史模型。牙齿模型的排列被确定为使得历史模型是现实的,也就是说对应于个人可能遇到的状况。特别是,牙齿模型根据它们的性质以弧形排列,并逼真地取向。使用理论历史模型可以有利地模拟表现出罕见特征的牙弓。
[0102]
历史模型优选地以小于5/10mm、优选地小于3/10mm、优选地小于1/10mm的误差提供关于牙齿定位的信息。
[0103]
历史模型例如是.stl或.obj、.dxf 3d、iges、step、vda或点云类型。有利地,可以从任何角度观察这种称为“3d”模型的模型。
[0104]
对于每个历史模型,进行步骤1)到4)。
[0105]
在步骤1)中,在第一观察条件下获取历史模型的第一视图,也就是说通过在这些第一观察条件下虚拟地放置虚拟图像获取装置,然后使用以这种方式配置的该装置获取第一视图。
[0106]
第一视图优选地是口外视图,例如对应于可能已经优选地使用牵开器、面向患者拍摄的照片的视图。
[0107]
图6示出了牵开器的一个示例。
[0108]
如果第一视图没有描绘轮廓,或者不能识别轮廓,则应用处理操作来分离轮廓、优选牙齿的轮廓。
[0109]
图5示出了在处理以分离轮廓之前的第一视图的一个示例。
[0110]
图7的左侧部分示出了在处理以分离牙齿轮廓之后的第一视图的一个示例。
[0111]
在步骤2)中,修改历史模型以模拟牙科事件的影响。
[0112]
修改历史模型特别可以包括在基本模型中使一颗或多颗牙齿(“牙齿模型”)和/或
牙龈,和/或一个或两个颌部,和/或正畸矫治器移位、变形或移除。
[0113]
修改可以由操作者手动执行,优选由牙科专业人员、更优选地由正畸医生,优选使用允许他们查看当前正在修改的模型的计算机来执行。
[0114]
步骤2)导致描绘理论牙齿状况的历史模型。
[0115]
该模型可以有利地模拟不可测量的牙齿状况。特别是,可以创建与罕见病理的不同阶段相对应的历史模型。
[0116]
在步骤3)中,在与能够获取第一视图的观察条件相同的历史模型的观察条件下获取在步骤2)中修改的称为“第二视图”的历史模型的视图。换言之,在第一视图和第二视图中,未在步骤1)和3)之间移动的牙齿的描绘可以完美地重叠,即“对准”。
[0117]
如果第二视图没有描绘轮廓,或者不能识别轮廓,则应用处理操作来分离轮廓、优选牙齿的轮廓。
[0118]
图7的右侧部分示出了在处理以分离牙齿轮廓之后的第二视图的一个示例。比较图7的左侧部分和右侧部分,可以看到牙科事件的影响,在这种情况下,是通过具有弓丝和托槽的矫治器进行正畸治疗的影响。
[0119]
因此生成了对(pair)或“历史记录”,其包括第一视图和相关联的第二视图,该第二视图表示将牙科事件应用于第一图像中描绘的牙弓。历史记录被添加到历史学习库中。
[0120]
图2示出了历史记录的一个示例。
[0121]
在一个实施方式中,在步骤1)中,在每次不同的第一观察条件下获取多于10个、多于100个、多于1000个、多于10000个第一视图,然后,在步骤3)中,对于在第一观察条件下获取的每个第一视图,在与所述第一观察条件相同的第二观察条件下获取第二视图,并利用所述第一视图和第二视图创建历史记录。
[0122]
此过程相当于在步骤3)之后,通过修改每个循环中的第一观察条件,来执行步骤1)和3)而没有步骤2)的多于10个、多于100个、多于1000个、多于10000个循环。换言之,第一视图和第二视图是通过围绕历史模型移动、特别是通过围绕历史模型旋转,和/或通过接近或移开,和/或通过修改用于获取第一视图和第二视图的虚拟获取装置的校准来获取的。
[0123]
本发明因此有利地使得可以增加具有同一历史模型的历史记录的数量。
[0124]
接下来,改变历史模型并返回到步骤1)。
[0125]
因此形成历史学习库,该学习库包括优选地多于5000条、优选地多于10000条、优选地多于30000条、优选地多于50000条、优选地多于100000条历史记录。
[0126]
在步骤4)中,然后使用历史学习库来训练神经网络。这种训练对于本领域技术人员来说是众所周知的。
[0127]
这种训练通常包括:通过为每个第一视图建立与相应的第二视图的双射关系(也就是说属于同一记录),在神经网络的输入处提供所有的所述第一视图并且在神经网络的输出处提供所有的所述第二视图。
[0128]
通过这种训练,神经网络学会将描绘分析牙弓的轮廓的输入视图(例如第一视图)转换为描绘同一牙弓但在牙科事件发生之后的输出视图。
[0129]
神经网络特别可以选自专门用于图像生成的网络,例如:
[0130]-循环一致对抗网络(2017)
[0131]-增强型cyclegan(2018)
[0132]-深度照片风格转移(2017)
[0133]-快速照片风格(fastphotostyle)(2018)
[0134]-pix2pix(2017)
[0135]-基于样式的gan生成器架构(2018)
[0136]-srgan(2018)。
[0137]
上面的列表不是限制性的。
[0138]
以这种方式训练的神经网络可用于按照下述步骤a)至e)模拟简单照片中描绘牙科事件对牙弓的影响。该神经网络于是被称为“转换神经网络”。
[0139]
模拟牙科事件
[0140]
在步骤a)中,通过使用相机获取照片来创建原始图像,相机优选地选自包括照片获取系统的手机、所谓的“连接”相机、所谓的“智能手表”、平板电脑或者固定或便携式个人计算机。优选地,相机是手机。
[0141]
优选地,在获取照片时,相机与牙弓的间距大于5cm、大于8cm、或甚至大于10cm,从而避免水蒸气在相机光学器件上凝结,并促进对焦。此外,优选地,相机、特别是手机,不配备任何用于获取照片的特定光学器件,这是可能的,特别是由于在获取期间与牙弓有间距。
[0142]
为了促进照片的获取,优选将牵开器和相机固定在同一个支架上,从而可以固定它们的相对位置。优选地,支架是便携式的,并且在拍照时应该由受益人手持。
[0143]
优选地,照片是彩色的,优选地是真彩的。
[0144]
优选地,照片由受益人获取,而优选地不使用用于固定相机的支架,特别是不使用三脚架。
[0145]
该照片优选地是口外视图,例如对应于可能已经优选地使用牵开器、面向患者拍摄的照片的视图。
[0146]
牵开器可以具有常规牵开器的特征。
[0147]
在步骤b)中,原始图像的处理旨在突出、或甚至分离原始图像中包含的辨别信息。使用辨别信息显著提高了步骤c)中实现的神经网络的效率。
[0148]
优选地,对原始图像进行处理以揭示并且优选地分离轮廓。
[0149]
优选地,对原始图像进行处理以基本上不再描绘除了轮廓之外的任何事物。优选地,该轮廓包括所描绘的每个牙齿的基本轮廓,或者甚至由牙齿的所有基本轮廓组成。
[0150]
该轮廓还可以包括,或者甚至仅由所描绘的所有牙齿的轮廓组成。然而,该实施方式不是优选的。
[0151]
本领域技术人员知道如何处理照片或视图以分离轮廓。这种处理包括例如应用图像处理软件附带的众所周知的掩模或滤波器。这样的处理操作使得可以例如检测高对比度区域。
[0152]
这些处理操作尤其包括以下已知和优选方法中的一种或多种:
[0153]-应用canny过滤器,特别是使用canny算法来搜索轮廓;
[0154]-应用sobel滤波器,以特别是通过扩展的sobel算子计算导数;
[0155]-应用laplace滤波器,以计算图像的拉普拉斯算子;
[0156]-检测图像中的斑点(“斑点检测器(blobdetector)”);
[0157]-应用“阈值”,以对向量的每个元素应用固定的阈值;
[0158]-使用像素区域之间的关系(“调整大小(面积)(resize(area))”)、或像素环境中的双三次插值调整大小;
[0159]-通过特定的结构元素侵蚀图像;
[0160]-通过特定的结构元素扩展图像;
[0161]-特别是使用恢复区域附近的区域进行图像校正;
[0162]-应用双边滤波器;
[0163]-应用gaussian模糊;
[0164]-应用otsu滤波器以搜索使类之间的方差最小化的阈值;
[0165]-应用a*滤波器以搜索点之间的路径;
[0166]-应用“自适应阈值”以将自适应阈值应用于向量;
[0167]-特别是将直方图均衡滤波器应用于灰度图像;
[0168]-模糊检测(“blurdetection”),以使用其拉普拉斯算子计算图像的熵;
[0169]-检测二值图像的轮廓(“findcontour”);
[0170]-颜色填充(“floodfill”)、特别是以用确定的颜色来填充关联的元素。
[0171]
以下非限制性方法虽然不是优选的,但也可以实施:
[0172]-应用“meanshift”滤波器,以便在图像的投影中找到对象;
[0173]-应用“clahe”滤波器,clahe代表“对比度受限自适应直方图均衡化”;
[0174]-应用“kmeans”滤波器,以确定集群的中心和集群周围的样本组的中心;
[0175]-应用dft滤波器,以便对向量进行正向或逆向离散傅立叶变换;
[0176]-计算力矩;
[0177]-应用“humoments”滤波器以计算不变的hu不变量;
[0178]-计算图像的积分;
[0179]-应用scharr滤波器,从而可以通过实施scharr算子来计算图像的导数;
[0180]-搜索点的凸包(“convexhull”);
[0181]-搜索轮廓的凸点(“convexitydefects”);
[0182]-比较形状(“matchshapes”);
[0183]-检查点是否在轮廓上(“pointpolygontest”);
[0184]-检测harris角点(“cornerharris”);
[0185]-搜索梯度矩阵的最小特征值,以检测角点(“cornermineigenval”);
[0186]-应用hough变换以在灰度图像中找到圆圈(“houghcircles”);
[0187]
‑“
主动轮廓建模”(根据潜在的“嘈杂”2d图像绘制对象的轮廓);
[0188]-在图像的一部分中计算力场,称为gvf(“梯度向量流”);
[0189]-级联分类(“cascadeclassification”)。
[0190]
该处理也可以通过为此目的训练的神经网络来执行。该神经网络优选地选自专门用于图像中对象的定位和检测的网络,例如如下“对象检测网络”:
[0191]-r-cnn(2013)
[0192]-ssd(单发多盒(multibox)检测器:对象检测网络)、faster(更快的)r-cnn(基于更快区域的卷积网络方法:对象检测网络)
[0193]-更快的r-cnn(2015)
[0194]-ssd(2015)。
[0195]
牙齿轮廓的确定可以通过pct/ep2015/074900或fr1901755中的教导进行优化。
[0196]
步骤b)有利地使得能够获得能够由神经网络非常容易地处理的图像。
[0197]
在步骤c)中,来自步骤b)的原始图像呈现在模拟神经网络的输入处。然后模拟神经网络修改原始图像以模拟牙齿事件对其中描绘的牙弓的影响。
[0198]
有利地,在模拟神经网络的输入处只需要呈现原始图像。不需要向模拟神经网络呈现三维信息,例如三维数字模型。此外,可以将整个原始图像提交给模拟神经网络。没有必要分离此图像的元素。模拟神经网络根据原始图像生成新图像。换言之,原始图像的任何部分都不会被简单地复制。在生成新图像时,原始图像的任何部分都易于被修改。
[0199]
优选地,模拟神经网络已经通过向其提供以下内容预先进行了训练:
[0200]-在输入处,提供一组“输入”图像,每个“输入”图像都描绘了描绘相应牙弓的相应“输入”真实图像的辨别信息,例如提供一组该牙弓的照片或该牙弓的三维模型的超逼真视图,以及
[0201]-在输出处,提供一组“输出”图像,每个“输出”图像与输入图像相关联,并描绘相应“输出”逼真图像的辨别信息,该“输出”逼真图像描绘相关联“输入”超逼真图像中描绘的但是在牙科事件发生后的牙弓,该输出逼真图像例如是该牙弓的照片或该牙弓的三维模型的超逼真视图。
[0202]“逼真”被理解为意指描绘的牙弓与现实中人能够用肉眼观察到的牙弓相似。
[0203]
通过这种训练,模拟神经网络学习将输入图像转换为输出图像,从而学习模拟牙科事件。
[0204]
优选地,输入图像和输出图像中描绘的辨别信息是轮廓。
[0205]
所使用的模拟神经网络特别可以按照步骤1)到4)进行训练。
[0206]
在步骤d)中(可选但优选的),对在步骤c)结束时获得的修改图像进行修改,使得它是超逼真的,也就是说,使得它看起来是照片。
[0207]
使修改图像超逼真的所有方法都是可能的。
[0208]
zhu、jun-yan等人的文章“unpaired image-to-image translation using cycle-consistent adversarial networks”中描述了一些图像纹理技术。
[0209]
优选地,使用所谓的“纹理”神经网络,该“纹理”神经网络被训练以制作描绘轮廓超逼真的图像,例如修改图像,并且优选地包括以下步骤d0)到d3)。
[0210]
对于在根据本发明的训练方法中实施的神经网络,可以从上面呈现的神经网络列表中选择纹理神经网络。纹理神经网络尤其可以选自专门用于图像生成的网络,例如:
[0211]-循环一致对抗网络(2017)
[0212]-增强型cyclegan(2018)
[0213]-深度照片风格转移(2017)
[0214]-快速照片风格(fastphotostyle)(2018)
[0215]-pix2pix(2017)
[0216]-基于样式的gan生成器架构(2018)
[0217]-srgan(2018)。
[0218]
然而,纹理神经网络不限于上面的列表。
[0219]
在步骤d0)中,对于称为“纹理照片”的每张照片,根据包含多于1000张纹理照片的集合描绘牙弓,
[0220]
处理所述纹理照片,优选如步骤b)处理所述纹理照片,以获得称为“纹理图像”的描绘轮廓的图像;
[0221]
在步骤d1)中,创建由称为“纹理记录”的记录组成的所谓的“纹理”学习库,每个纹理记录包括:
[0222]-描绘牙弓的纹理照片,和
[0223]-在步骤d1)之前的步骤d0)中通过处理步骤d0)的所述纹理照片而获得的纹理图像;
[0224]
在步骤d2)中,通过纹理学习库训练纹理神经网络。这种训练对于本领域技术人员来说是众所周知的。
[0225]
这种训练通常包括在纹理神经网络的输入处提供所有所述纹理图像并且在纹理神经网络的输出处提供所有所述纹理照片,同时将对应于每个纹理图像的纹理照片通知给纹理神经网络。
[0226]
通过这种训练,纹理神经网络学习将描绘牙弓轮廓的图像(例如修改图像)转换为超逼真图像。
[0227]
在步骤d3)中,将修改图像提交给经训练的纹理神经网络。纹理神经网络将修改图像转换为超逼真图像。
[0228]
图3示出了在步骤a)中获取的照片(左侧)和在步骤d)结束时获得的修改图像(右侧)的一个示例。可以观察牙科事件对某些牙齿位置的影响。
[0229]
在步骤e)中,优选地变得超逼真的修改图像可以特别地被呈现给受益人,优选地呈现在屏幕上,优选地呈现在手机、平板电脑、便携式计算机或虚拟现实头盔的屏幕上。屏幕也可以是镜子的玻璃。
[0230]
生成方法和训练方法通过计算机实现。通常,计算机尤其包括处理器、存储器、人机界面,通常包括屏幕、用于通过互联网、wi-fi、或电话网络进行通信的模块。被配置为实现所考虑的本发明的方法的软件被加载到计算机的存储器中。
[0231]
计算机也可以连接到打印机。
[0232]
在一个实施方式中,人机界面使得可以与计算机进行以下通信:
[0233]-当牙科事件包括获取时间和模拟时间之间的时间流逝时的所述模拟时间,和/或
[0234]-应用于受益人的治疗参数;和/或
[0235]-受益人佩戴的正畸矫治器的参数,例如与正畸矫治器的类别和/或构造相关的参数;和/或
[0236]-受益人的功能参数,特别是神经功能参数,例如呼吸、吞咽或嘴巴闭合的难易程度;和/或
[0237]-受益人的解剖参数而不是他们牙齿的定位参数,例如骨组织(特别是颌部)和/或牙槽牙组织和/或软组织(特别是牙龈和/或系带和/或舌头和/或脸颊)的排列和/或结构;和/或
[0238]-所述受益人的年龄或年龄段和/或性别。
[0239]
因此,计算机可以选择相应训练的模拟神经网络。
[0240]
例如,对于30至40岁、具有“正常”骨组织的男性,可以选择经训练的模拟神经网络来模拟带有正畸矫治器的牙齿的移动,该正畸矫治器具有弓丝和托槽。
[0241]
该方法使得尤其可以模拟各种正畸治疗的效果,从而促进选择最适合受益人的需要或愿望的治疗。
[0242]
优选地,人机界面包括具有用于输入模拟时间的字段的屏幕。
[0243]
在一个实施方式中,人机界面使得可以在屏幕上选择性地显示或不显示受益人佩戴的正畸矫治器。
[0244]
示例
[0245]
过去或未来牙齿状况的模拟
[0246]
在一个实施方式中,受益人例如用他们的手机拍摄原始图像(步骤a)),并且集成到手机中或手机能够与之通信的计算机执行步骤b)至e)。修改图像优选地呈现在手机的屏幕上。
[0247]
优选地,将计算机集成到手机中,从而允许受益人完全自主地实施根据本发明的生成方法。
[0248]
因此受益人可以基于他们牙齿的一张或优选多张照片,非常容易地请求模拟牙齿状况,甚至不必移动。
[0249]
特别地,可以模拟在过去或未来的模拟时间的牙齿状况。模拟时间可以例如在原始图像的获取时间之前或之后,例如在获取时间之前或之后多于1天、多于10天或多于100天。
[0250]
在一种特定情况下,牙科事件是治疗(例如受益人佩戴正畸矫治器期间的正畸治疗)情况下的时间流逝。
[0251]
优选地,该方法包括步骤d)。所呈现的修改图像然后显示为已经在模拟时间拍摄的照片。修改图像可以呈现给受益人,以便向他们示出他们未来或过去的牙齿状况,从而激励他们遵循治疗。
[0252]
在一种特定情况下,牙科事件是在如下正畸治疗的情况下的时间流逝,在此正畸治疗期间受益人不遵守医疗建议,例如没有正确佩戴他们的正畸矫治器。因此,逼真的修改图像的呈现使得可以可视化不正确的遵守的影响。
[0253]
根据本发明的生成方法可以特别用于模拟:
[0254]-一种或多种正畸矫治器对受益人牙齿的影响,特别是为了选择最适合该受益人的正畸矫治器;
[0255]-暂时或最终停止正在进行的治疗的影响;
[0256]-应用指令的影响;
[0257]-治疗性或非治疗性医治的影响。
[0258]
特别地,该方法可以用于特别是出于教育目的,以可视化改变刷牙频率和/或刷牙持续时间和/或刷牙技术的影响,或延迟更换正畸夹板和/或延迟与牙科专业人员预约的影响。
[0259]
动态模拟
[0260]
在一个实施方式中,步骤a)到e)在环路中重复,其中连续获取原始图像。优选地,每个循环持续少于5秒,优选少于2秒,优选少于1秒。在步骤a)中,优选使用相机。
[0261]
例如,受益人可以在他们在其中看着自己的配备有相机的镜子上看到修改图像。优选地,修改图像以与镜子反射的图像对准的方式呈现,也就是说,受益人看到修改图像就好像图像是通过反射获得的一样。因此,受益人有在模拟时间观察他们自己的印象。
[0262]
优选地,在从步骤a)到e)的两个循环之间,可以修改模拟时间,例如通过修改屏幕上示出的光标的位置来修改模拟时间。优选地,屏幕是触摸屏,并且模拟时间通过手指在所述屏幕上的交互,优选地通过滑动来修改。
[0263]
具有瞬时影响的事件
[0264]
在一种特定情况下,牙科事件具有希望可视化的即时效果。
[0265]
例如,牙科事件是正畸矫治器的装配。因此,该方法可以将正畸矫治器的描绘整合到原始图像中,或者修改原始图像中描绘的正畸矫治器,或者移除原始图像中描绘的正畸矫治器,而无需修改牙齿的位置。
[0266]
训练模拟神经网络以从提供给它的原始图像创建修改图像。因此,该方法与例如将元素、例如现有正畸矫治器的描绘添加到图像的方法完全不同。事实上,为了将正畸矫治器的描绘整合到原始图像中,模拟神经网络创建该描绘。因此,该描绘不是真实正畸矫治器的再现或真实正畸矫治器的3d模型,而是由模拟神经网络与图像的其余部分同时人工生成的。
[0267]
令人惊讶的是,正畸矫治器的描绘高度逼真,并允许很好地模拟受益人。特别是,训练模拟神经网络教导它在原始图像的情况中描绘正畸矫治器,并具有相应的对比度、清晰度、阴影和反射。因此,所述模拟比简单地将正畸矫治器的预先存在的描绘添加到描绘牙弓的图像中要逼真得多。
[0268]
神经网络对原始图像的修改可以导致对原始图像中除描绘正畸矫治器的区域之外的区域进行修改。如果修改图像用于干预牙齿,例如在钻孔操作期间指导牙医,则这些差异可能是有害的,但当修改图像旨在呈现给受益人时,这些差异不会有害。神经网络的性能甚至可以使得几乎不可能检测到正畸矫治器所描绘区域之外的差异。
[0269]
正如现在清楚地看到的,本发明允许受益人模拟牙科事件对其牙弓的牙齿的影响,而无需他们对该牙弓进行扫描。在一个优选实施方式中,任何配备手机的人都可以有利地执行这种模拟。
[0270]
当然,本发明不限于上述和所示的实施方式。
[0271]
特别地,受益人不限于人。根据本发明的方法可以用于其他动物。
[0272]
此外,训练方法不一定包括步骤1)至4),但步骤1)至4)是优选的。
[0273]
神经网络、特别是模拟神经网络,例如可以通过实施一种方法来训练,对于优选地包括多于100个、优选地多于1000个、优选地多于10000个个体的一组个体,该方法包括以下步骤:
[0274]
1')获取个人的牙弓的照片并处理所述照片以获得描绘照片中所描绘的牙弓的轮廓的第一图像;
[0275]
2')生成描绘在牙科事件发生后的所述牙弓的数字三维模型;
[0276]
3')获取勾勒有所述照片的所述模型的视图,并且如果所述视图未描绘轮廓,则处理该视图以使其描绘所描绘的牙弓的轮廓;然后,为所有个人获取所有的第一图像和视图:
[0277]
4')在神经网络的输入和输出处分别引入所述照片和视图,以训练所述神经网络
将描述分析牙弓的输入视图转换为在应用所述牙科事件后描述所述分析牙弓的输出视图。
[0278]
在步骤2')中,生成在牙科事件发生后的描绘牙弓的模型可以是以下的结果:
[0279]-在牙科事件发生之前生成所述模型,例如在与获取照片(步骤1'))的时间基本同时生成所述模型,然后
[0280]-如步骤2)所述,在所述模型上模拟牙科事件。
[0281]
在步骤3')中,所述视图应勾勒有所述照片。优选地,寻求与照片获取条件最佳(“最佳拟合”)对应的模型观察条件。换言之,所寻求的是虚拟获取装置的位置、取向和校准,这些位置、取向和校准允许用视图来观察模型,在该视图中,在牙科事件期间未移动的牙齿的描绘能够以与照片中所述牙齿的描绘对准的方式重叠。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。