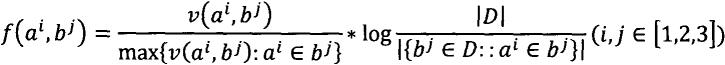
基于lucene的强化学习代码检索模型
技术领域
1.本发明提出了一种基于lucene的强化学习代码检索模型,属于计算机应用中的信息检索领域。利用马尔科夫决策过程(mdp)来简化强化学习的建模,在代码检索中,用户需要迭代地检索代码片段,通过扩展语义相似的api类名来探索满足其需求且具有较高排名的代码片段列表。本发明根据扩展语义相似的api类名和用户的隐式反馈作为调整特征权重,能够提高代码检索的准确率。
背景技术:
2.当遇到不熟悉的编程任务时,软件开发人员通常需要寻找潜在的工作代码示例,像许多通用检索一样,代码检索也面临会话检索问题:在代码检索会话中,用户需要迭代地检索代码片段,探索满足其需求的具有较高排名的结果。
3.stackoverflow中的搜索引擎基于elasticsearch,elasticsearch是基于lucene库的全文本搜索引擎。它不会优化代码检索会话,并且被视为基准方法。扩展语义相似的api类名,再去使用lucene执行扩展的查询,从代码片段语料库中检索代码片段列表。
4.强化学习是机器学习的范式和方法论之一,用于描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。常见模型是标准的马尔科夫决策过程。
5.本文提出基于lucene和马尔科夫决策过程的强化学习代码检索模型,生成扩展语义相似的api类名,从代码片段语料库中检索代码片段列表。
技术实现要素:
6.发明目的:代码检索面临会话检索问题,在代码检索会话中,用户需要迭代地检索代码片段,探索满足其需求的新代码片段或使某些结果具有较高的排名。本文提出了一种强化的学习方法,用于带有文本说明的代码片段进行会话检索。通过将代码检索会话转换为马尔科夫决策过程,其中测量查询与生成的代码文档之间的相关性将指导整个会话检索。
7.技术方案:为了实现上述目的,本发明采用的技术方案为:
8.基于lucene的强化学习代码检索模型,包括以下步骤:
9.步骤1)、分析代码文档并提取代码文档特征。
10.步骤2)、使用lucene为代码文档特征生成索引文件。
11.步骤3)、通过比较当前查询和先前查询来获得查询重构。
12.步骤4)、相似度计算组件根据代码文档特征和查询重构计算特征分数,并从用户反馈中提取用户满意度。
13.步骤5)、采用mdp来根据查询公式和用户满意度计算特征权重。
14.步骤6)、通过其特征得分和特征权重的内积来计算与每个代码文档之间的相关性得分,返回结果。用户满意则流程结束,否则返回步骤4。
15.进一步的,所述步骤1)的具体步骤如下:
16.分析代码文档提取了代码文档特征e,该特征分为三个部分:文本,令牌,api。
17.·
文本:通过删除标点符号和停用词,减小大小写和词干来预处理文本功能。
18.·
令牌:令牌功能是通过删除java关键字,根据驼峰大小写分割单词并减小大小写来提取的。
19.·
api:使用与deep api learning中相同的步骤从每个java方法中提取api功能,使用编译器将源文件解析为ast并遍历ast。
20.进一步的,所述步骤2)的具体步骤如下:
21.使用lucene为码文档特征生成索引文件,即对代码文档的文本、令牌、api等特征使用词法分析和语法分析形成一系列词,经过索引创建形成词典和反向索引表,最终建立索引库。
22.进一步的,所述步骤3)的具体步骤如下:
23.查询分析将生成查询重构g,查询重构是两个连续查询之间的句法编辑更改。令qi为当前查询,令q
i-1
为先前查询。g由q
same
,q
added
和q
removed
组成,其中
24.·qsame
是包含在qi和q
i-1
中都包含的项的项集:q
same
=qi∩q
i-1
。
25.·qadded
是包括qi中但不包含在q
i-1
中的项的项集:q
added
=q
i-qi∩q
i-1
。
26.·qremoved
是包含在qi中但不包含在q
i-1
中的项的项集:q
removed
=q
i-1-qi∩q
i-1
。
27.进一步的,所述步骤4)的具体步骤如下:
28.步骤4.1)、相似度计算特征分数f由代码文档特征e和查询重构g计算,特征分数定义为:
[0029][0030]
f(ai,bj)是查询文档相似性特征公式,其中a1,a2和a3用于表示分别在q
same
,q
added
和q
removed
中设置的查询字词。b1,b2和b3分别用于表示代码文档的文本集,令牌集和api集。f(ai,bj)定义为:
[0031][0032]
它定义了其查询词ai在bj中出现的时间除以在bj中出现次数最多的词的时间与包含ai的文档的对数反比的乘积。
[0033]
步骤4.2)、用户满意度u是从用户反馈生成的,定义为
[0034]
u={c
num
,t
num
,t
long
},其中
[0035]
·cnum
是单击的文档集c
i-1
的大小。
[0036]
·
t
num
是t
i-1
的停留时间之和。
[0037]
·
t
long
是t
i-1
中最长的停留时间。
[0038]
进一步的,所述步骤5)的具体步骤如下:
[0039]
采用mdp对特征权重w的构造进行建模,mdp过程表示为元组{s,a,p,r,π}(图1),s代表了状态的集合,a代表了动作的集合,p描述了状态转移矩阵,r表示奖励函数,策略π描述行为可能发生的概率分布,定义为:
[0040][0041]
它定义了由参数θ决定的动作的概率,其中θ={θ1,...,θ9},每个θi的状态维度相同。
[0042]
进一步的,所述步骤6)的具体步骤如下:
[0043]
计算特征分数和特征权重的内积l,定义为:
[0044][0045]
将排序结果返回给用户,如果用户满意则流程终止,否则将用户满意度反馈到步骤4继续执行。
附图说明
[0046]
图1是马尔科夫决策过程流程图
[0047]
图2是基于lucene的强化学习代码检索模型流程图
具体实施方案
[0048]
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0049]
代码检索面临会话检索问题,在代码检索会话中,用户需要迭代地检索代码片段,探索满足其需求的新代码片段或使某些结果具有较高的排名。本文提出了一种强化的学习方法,用于带有文本说明的代码片段进行会话检索。通过将代码检索会话转换为马尔科夫决策过程,其中测量查询与生成的代码文档之间的相关性将指导整个会话检索。
[0050]
技术方案:为了实现上述目的,本发明采用的技术方案为:
[0051]
基于lucene的强化学习代码检索模型,包括以下步骤:
[0052]
步骤1)、分析代码文档并提取代码文档特征。
[0053]
步骤2)、使用lucene为代码文档特征生成索引文件。
[0054]
步骤3)、通过比较当前查询和先前查询来获得查询重构。
[0055]
步骤4)、相似度计算组件根据代码文档特征和查询重构计算特征分数,并从用户反馈中提取用户满意度。
[0056]
步骤5)、采用mdp来根据查询公式和用户满意度计算特征权重。
[0057]
步骤6)、通过其特征得分和特征权重的内积来计算与每个代码文档之间的相关性得分,返回结果。用户满意则流程结束,否则返回步骤3。
[0058]
进一步的,所述步骤1)的具体步骤如下:
[0059]
分析代码文档提取了代码文档特征e,该特征分为三个部分:文本,令牌,api。
[0060]
·
文本:通过删除标点符号和停用词,减小大小写和词干来预处理文本功能。
[0061]
·
令牌:令牌功能是通过删除java关键字,根据驼峰大小写分割单词并减小大小写来提取的。
[0062]
·
api:使用与deep api learning中相同的步骤从每个java方法中提取api功能,
使用编译器将源文件解析为ast并遍历ast。
[0063]
进一步的,所述步骤2)的具体步骤如下:
[0064]
使用lucene为码文档特征生成索引文件,即对代码文档的文本、令牌、api等特征使用词法分析和语法分析形成一系列词,经过索引创建形成词典和反向索引表,最终建立索引库。
[0065]
进一步的,所述步骤3)的具体步骤如下:
[0066]
查询分析将生成查询重构g,查询重构是两个连续查询之间的句法编辑更改。令qi为当前查询,令q
i-1
为先前查询。g由q
same
,q
added
和q
removed
组成,其中
[0067]
·qsame
是包含在qi和q
i-1
中都包含的项的项集:q
same
=qi∩q
i-1
。
[0068]
·qadded
是包括qi中但不包含在q
i-1
中的项的项集:q
added
=q
i-qi∩q
i-1
。
[0069]
·qremoved
是包含在qi中但不包含在q
i-1
中的项的项集:q
removed
=q
i-1-qi∩q
i-1
。
[0070]
进一步的,所述步骤4)的具体步骤如下:
[0071]
步骤4.1)、相似度计算特征分数f由代码文档特征e和查询重构g计算,特征分数定义为:
[0072][0073]
f(ai,bj)是查询文档相似性特征公式,其中a1,a2和a3用于表示分别在q
same
,q
added
和q
removed
中设置的查询字词。b1,b2和b3分别用于表示代码文档的文本集,令牌集和api集。f(ai,bj)定义为:
[0074][0075]
它定义了其查询词ai在bj中出现的时间除以在bj中出现次数最多的词的时间与包含ai的文档的对数反比的乘积。
[0076]
步骤4.2)、用户满意度u是从用户反馈生成的,定义为
[0077]
u={c
num
,t
num
,t
long
},其中
[0078]
·cnum
是单击的文档集c
i-1
的大小。
[0079]
·
t
num
是t
i-1
的停留时间之和。
[0080]
·
t
long
是t
i-1
中最长的停留时间。
[0081]
进一步的,所述步骤5)的具体步骤如下:
[0082]
采用mdp对特征权重w的构造进行建模,mdp过程表示为元组{s,a,p,r,π}(图1),s代表了状态的集合,a代表了动作的集合,p描述了状态转移矩阵,r表示奖励函数,策略π描述行为可能发生的概率分布,定义为:
[0083][0084]
它定义了由参数θ决定的动作概率,其中θ={θ1,...,θ9},每个θi的状态维度相同。
[0085]
进一步的,所述步骤6)的具体步骤如下:
[0086]
计算特征分数和特征权重的内积l,定义为:
[0087]
[0088]
将排序结果返回给用户,如果用户满意则流程终止,否则将用户满意度反馈到步骤4继续执行。
[0089]
在信息检索领域中,代码检索模型各有优缺,本发明基于lucene的强化学习代码检索模型,通过获取隐式的用户满意度反馈作为排名的奖励,动态调整特征权重,帮助用户获取更精确的查询。
[0090]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。