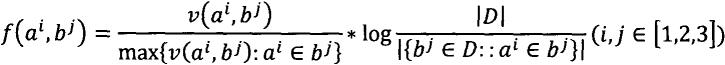技术特征:
1.基于lucene的强化学习代码检索模型:首先,分析代码文档并提取代码文档特征,使用lucene为代码文档特征生成索引文件,对代码文档的文本、令牌、api等特征建立索引库;其次,通过比较当前查询和先前查询来获得查询重构,并根据代码文档特征和查询重构计算特征分数,从用户反馈中提取用户满意度;然后,采用mdp并根据查询公式和用户满意度计算特征权重;最后,通过其特征得分和特征权重的内积来计算与每个代码文档之间的相关性得分,返回结果。用户满意则流程结束,否则提取用户满意度,继续执行。2.根据权利要求1所描述的基于lucene的强化学习代码检索模型,其特征包括以下几个步骤:1)分析代码文档并提取代码文档特征。2)使用lucene为代码文档特征生成索引文件。3)通过比较当前查询和先前查询来获得查询重构。4)相似度计算组件根据代码文档特征和查询重构计算特征分数,并从用户反馈中提取用户满意度。5)采用mdp来根据查询公式和用户满意度计算特征权重。6)通过其特征得分和特征权重的内积来计算与每个代码文档之间的相关性得分,返回结果。用户满意则流程结束,否则返回步骤4。3.根据权利要求2所述的基于lucene的强化学习代码检索模型,其特征是步骤1)中,分析代码文档提取了代码文档特征e。该特征分为三个部分:文本,令牌,api。其中:
·
文本:通过删除标点符号和停用词,减小大小写和词干来预处理文本功能。
·
令牌:令牌功能是通过删除java关键字,根据驼峰大小写分割单词并减小大小写来提取的。
·
api:使用与deep api learning中相同的步骤从每个java方法中提取api功能,使用编译器将源文件解析为ast并遍历ast。4.根据权利要求2所述的基于lucene的强化学习代码检索模型,其特征是步骤2)中,使用lucene为码文档特征生成索引文件。对代码文档的文本、令牌、api等特征使用词法分析和语法分析形成一系列词,经过索引创建形成词典和反向索引表,最终建立索引库。5.根据权利要求2所述的基于lucene的强化学习代码检索模型,其特征是步骤3)中,查询分析将生成查询重构g。查询重构是两个连续查询之间的句法编辑更改,令q
i
为当前查询,令q
i-1
为先前查询,g由q
same
,q
added
和q
removed
组成。其中:
·
q
same
是包含在q
i
和q
i-1
中都包含的项的项集:q
same
=q
i
∩q
i-1
。
·
q
added
是包括q
i
中但不包含在q
i-1
中的项的项集:q
added
=q
i-q
i
∩q
i-1
。
·
q
removed
是包含在q
i
中但不包含在q
i-1
中的项的项集:q
removed
=q
i-1-q
i
∩q
i-1
。6.根据权利要求2所述的基于lucene的强化学习代码检索模型,其特征是步骤4)中,计算特征分数相似度计算特征分数f由代码文档特征e和查询重构g计算,特征分数定义为:f(a
i
,b
j
)是查询文档相似性特征公式,其中a1,a2和a3用于表示分别在q
same
,q
added
和q
removed
中设置的查询字词。b1,b2和b3分别用于表示代码文档的文本集,令牌集和api集。f
(a
i
,b
j
)定义为:它定义了其查询词a
i
在b
j
中出现的时间除以在b
j
中出现次数最多的词的时间与包含a
i
的文档的对数反比的乘积。用户满意度u是从用户反馈生成的,定义为:u={c
num
,t
num
,t
long
},其中:
·
c
num
是单击的文档集c
i-1
的大小。
·
t
num
是t
i-1
的停留时间之和。
·
t
long
是t
i-1
中最长的停留时间。7.根据权利要求2所述的基于lucene的强化学习代码检索模型,其特征是步骤5)中,采用mdp对特征权重w的构造进行建模。mdp过程表示为元组{s,a,p,r,π}(图1),s代表了状态的集合,a代表了动作的集合,p描述了状态转移矩阵,r表示奖励函数,策略π描述行为可能发生的概率分布,定义为:它定义了由参数θ决定的动作的概率,其中θ={θ1,...,θ9},每个θ
i
的状态维度相同。8.根据权利要求2所述的基于lucene的强化学习代码检索模型,其特征是步骤6)中,计算特征分数和特征权重的内积l,定义为:将排序结果返回给用户,如果用户满意则流程终止,否则将用户满意度反馈到步骤4)继续执行。
技术总结
本发明公开了一种基于Lucene的强化学习代码检索模型,包括以下步骤:1)分析代码文档并提取代码文档特征。2)使用Lucene为代码文档特征生成索引文件。3)通过比较当前查询和先前查询来获得查询重构。4)相似度计算组件根据代码文档特征和查询重构计算特征分数,并从用户反馈中提取用户满意度。5)采用MDP来根据查询公式和用户满意度计算特征权重。6)通过其特征得分和特征权重的内积来计算与每个代码文档之间的相关性得分,返回结果。用户满意则流程结束,否则返回步骤4。本发明基于Lucene的强化学习代码检索模型,通过获取隐式的用户满意度反馈作为排名的奖励,动态调整特征权重,帮助用户获取更精确的查询。用户获取更精确的查询。用户获取更精确的查询。
技术研发人员:张卫丰 王国程 周国强
受保护的技术使用者:南京邮电大学
技术研发日:2020.12.01
技术公布日:2022/6/4
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。