1.本发明属于知识图谱评估领域,尤其适用于知识图谱数据质量的评估。其目的改变现状下知识图谱数据质量评估方法和过程缺失且评估多依赖于人工质检的现状,提供了一种自动化且高效率的知识图谱数据质量评估方法。
背景技术:
2.传统的知识图谱构建过程中,其三元组数据获取都来自于人工获取和审核,这在一定程度上保证了知识图谱数据的正确性,确保了知识图谱的质量稳定。但是近几年,互联网信息暴增,大量不同领域的知识图谱需要被构建,小规模知识库已经无法满足快速迭代的业务需求,获取三元组的方式告别了人力堆叠,转而使用各类信息抽取算法进行大规模挖掘。数据量大量扩充的同时,噪声数据也随着算法被一同引入。早期人力质检的方式在面对动辄千万级的三元组数据已经变得不可能了,因此知识图谱质量问题就渐渐凸显出来。这些知识图谱的源数据通常是由半结构化的知识和非结构化知识构建的,通过信息抽取算法获取数据,并且同时带入错误信息或者抽取信息不完善,其造成的结果就是构成的知识图谱经常面临着各种事实错误和各种链接的缺失,为了进一步提高这些知识图的效用,提高知识图谱质量,人们提出了各种细化方法,试图推断并向图中添加缺失的知识,或者识别错误的信息片段。同时,基于知识图谱的嵌入模型也大量发表,旨在对知识图谱实现错误检测和连接预测,并最终提高知识图谱质量。但是关于知识图谱的质量评估的系统方法却十分缺失,大多数评估方法还是依靠传统抽样加人工质检,这不仅耗费大量人力资源还耗费十分费时。因此,需要一种自动化的系统的评估方法帮助评估人员高效快捷的对知识图谱质量进行评估。
3.对此,本发明提出一种基于差分测试和嵌入模型的知识图谱评估方法。本发明的基本思想为:通过变异构造数据集对已发布的知识图谱嵌入模型进行重训练优化,得到最佳配置数据,使模型性能达到最佳。再依据差分测试的思想将知识图谱导入多个模型,分别得到预测序列,再对预测序列进行过滤和相似性评估进行剔除,最后投票得到的最终序列,对其进行指标计算,从而反映出知识图谱相关质量问题。首先通过变异算子对初始测试集进行变异得到变异数据集,对变异数据集进行基于封闭世界假设的过滤操作和标注形成嵌入模型所需的训练集;然后将变异训练集作为重训练嵌入模型的输入对嵌入模型进行针对知识图谱典型错误的优化;再次,根据重新训练优化后的知识图谱嵌入模型,将需要被评估的知识图谱进行数据处理后分别导入每个模型,得到每个三元组的在不同嵌入模型的中的预测分数序列,再对序列进行排序和筛选,得到过滤后的预测序列。最后,对预测序列分别进行差分测试,提出差异较大的序列,对剩余序列进行投票重组,得到最终序列,在根据最终序列计算相关质量指标。通过该方法,可以帮助评估人员更加快速的对知识图谱质量评估过程进行了解,帮助评估人员在有限的时间完成知识图谱的质量评估。
技术实现要素:
4.本文发明通过提供一种自动化的基于差分测试和嵌入模型的知识图谱质量评估方法,来有效解决目前存在的知识图谱质量评估方法和过程缺失的问题,进而帮助评估人员更加快速的对知识图谱质量进行了解,帮助评估人员在有限的时间完成知识图谱的质量评估。
5.为达成上述目标,提出一种基于差分测试和嵌入模型的知识图谱评估方法,其特征在于,通过变异测试中的变异算子自动生成与知识图谱数据对应的错误数据,并利用错误数据重新训练已有的高效知识图谱嵌入模型kgem(knowledge graph embedding models),利用重训练优化的知识图谱嵌入模型{m1,m2,m3,m4,m5…
},将被评估的知识图谱g导入模型mi,进行差分测试得到三元组的分数预测序列对分数预测序列进行筛选。最后,利用相似性评估、投票重组,得到新的重组序列,再计算出有关知识图谱质量的相关指标。具体而言,该方法包括以下步骤:
6.1)变异数据构造。给定训练三元组集合t和变异算子集合mo={m0,m1,m2,m3,m4,m5…
};知识图谱中的数据一般使用三元组表示,故测试集中的数据也用三元组(h,r,t)表示,其中,h表示头实体,r表示关系,t表示尾实体。首先,对测试集t中的正确三元组rti=(hi,ri,ti)执行mo中的某一变异算子mj,根据mj的所代表的典型错误不同对rtj进行不同的变换操作,获得不同的变异三元组mt
ij
=(h
ij
,ri,ti)或(hi,r
ij
,ti)或(hi,ri,t
ij
)。在此操作中某一变异算子对t中的每一个三元组都生成多个变异三元组。记所有变异三元组集合为n;接着,由于自动化生成的变异三元组中可能存在数据集已知的正确三元组,即可能存在h
ij
=hk或其他等价情况,故对获得的ni进行基于封闭世界假设(closed word assumption)的过滤操作,剔除n∩t的相交三元组获得错误变异三元组集合fn,并对剩下的错误变异三元组打标签为“false”,与原测试三元组集合t标签为“true”形成最终训练集t
mutation
。
7.2)嵌入模型训练。给定待训练优化的知识图谱嵌入模型{m
1initial
,m
2initial
,m
3initial
,m
4initial
,m
5initial
…
}和包含ground truth标注的训练集t
mutation
。首先,将训练集t
mutation
中的三元组数据录入到嵌入模型m
iinitial
中,随机生成维度的向量来模拟训练数据三元组。其次,计算模拟数据的嵌入模型损失函数loss,对于标注为“true”的三元组loss
true
越小越好,标注为“false”的三元组loss
false
越大越好,通过梯度下降法不断更新随机生成的向量。最终,循环给定epochs,训练完毕得到对错误变异三元组敏感的嵌入模型集合。
8.3)差分测试执行。给定重新训练优化的知识图谱嵌入模型{m1,m2,m3,m4,m5…
}和被评估的知识图谱g,对知识图谱g的数据集进行处理得到知识图谱g的实体序列entity,关系序列relation和三元组序列triple,再将序列entity、relation、triple分别带入模型{m1,m2,m3,m4,m5…
mi},得到每个模型对知识图谱g中每个三元组的分数预测序列si:{t1:{p1,p2,p3,p4,p5…
pi},t2:{p1,p2,p3,p4,p5…
pi},
…
tj:{p1,p2,p3,p4,p5…
pi}},其中si表示模型mi对知识图谱g的三元组分数预测序列,ti表示第i个三元组的分数预测序列,pi表示模型对三元组的第i个预测分数。得到每个模型的三元组分数预测序列si后,再对每个三元组的分数预测序列ti进行排序,因为三元组分数预测越小越好,所以按照分数从小到大的顺序排序,得到新的三元组分数预测序列,s
inew
:{t1:{p1,p2,p3,p4,p5…
pi},t2:{p1,p2,p3,p4,p5…
pi}
…
ti:{p1,p2,p3,p4,p5…
pi}},其p1为三元组最小的预测分数。最后,根据得到已经排序的三元
组分数预测序列s
inew
,对s
inew
中的每个三元组预测分数序列ti进行筛选过滤,选出ti中三元组预测分数在前1000名的预测结果,得到新的三元组分数预测序列:
9.4)评估指标计算。给定每个模型对知识图谱g中三元组经过排序过滤后的分数预测序列s
ifilter
,利用rbo相似性度量每个三元组在每个模型的分数预测序列,具体操作为从两个模型分数预测序列s
ifilter
,中提取三元组ti的预测序列t
iinew
:{p1,p2,p3,p4,p5…
p
1000
}和代表第i个三元组在第j个模型中的预测分数序列的前1000名。序列相似性p为rbo算法的自定义参数,当每个模型关于三元组ti的预测序列都两两相似性计算后,得到相似性度量的指标序列m:{n1,n2,n3,n4…nn
},长度为n=i(i-1)/2,i为模型的数量。计算出指标序列后,再计算相似性度量指标平均数:记录相似性指标ni<n^的指标对应的两个模型,统计每个模型出现的次数,最后剔除统计出现次数最多的模型对应的三元组分数预测序列其预测结果与其他模型预测结果相差较大。最后,将剔除后第i个三元组剩余的预测序列重新投票合并成新最终预测序列,投票规则为:1:出现次数最多的预测分数三元组优先;2:当出现次数相同时,排名靠前的优先。得到三元组的最终预测序列t
iend
,对其他三元组进行同样的操作,最后得到,所有知识图谱g中所有三元组对应的分数预测序列组最后根据预测所有三元组分数序列score计算知识图谱质量相关指标mr,hit@10。
10.进一步,其中上述步骤1)的具体步骤如下:
11.步骤1)-1:起始状态;
12.步骤1)-2:输入初始训练集t和变异算子{m0,m1,m2,m3,m4,m5…
};
13.步骤1)-3:对t执行变异得到变异三元组集合n;
14.步骤1)-4:过滤n中的正确三元组并打true/false标签;
15.步骤1)-5:对si进行排序得到新三元组预测序列
16.步骤1)-6:输出过滤和打标签后的最终训练集t
mutation
;
17.步骤1)-7:结束状态;
18.进一步,其中上述步骤2)的具体步骤如下:
19.步骤2)-1:起始状态;
20.步骤2)-2:输入训练集t
mutation
和嵌入模型
21.步骤2)-3:从嵌入模型中选取模型mi
initial
;
22.步骤2)-4:随机生成三元组的向量表示并计算loss;
23.步骤2)-5:判断条件“循环次数《epoch”是否满足,若是则执行步骤2)-4,若否则执行下一步;
24.步骤2)-6:得到优化后的模型mi;
25.步骤2)-7:判断条件“遍历完所有模型”是否满足,若是则执行下一步,若否则执行步骤2)-3;
26.步骤2)-8:输出优化后的嵌入模型集合{m1,m2,m3,m4,m5…
};
27.步骤2)-9:结束状态;
28.进一步,其中上述步骤3)的具体步骤如下:
29.步骤3)-1:起始状态;
30.步骤3)-2:输入评估知识图谱g和模型
31.步骤3)-3:处理g的数据集得到entity序列,relation序列,triple序列;
32.步骤3)-4:计算每个模型对每个三元组的分数预测序列si;
33.步骤3)-5:对si进行排序得到新三元组预测序列s
inew
;
34.步骤3)-6:筛选s
inew
中排名前1000的三元组序列得到s
ifilter
;
35.步骤3)-7:输出筛选后的分数预测序列s
ifilter
;
36.步骤3)-8:结束状态;
37.进一步,其中上述步骤4)的具体步骤如下:
38.步骤4)-1:起始状态;
39.步骤4)-2:输入筛选后的分数预测序列s
ifilter
;
40.步骤4)-3:选择三元组在不同模型预测序列两两计算相似性ni;
41.步骤4)-4:分别统计每个三元组统计所有相似性评估值得到相似性列表m;
42.步骤4)-5:计算相似性平均数n^;
43.步骤4)-6:统计相似性ni<n^预测序列的嵌入模型次数;
44.步骤4)-7:剔除出现最多的模型预测序列;
45.步骤4)-8:剩余序列投票合并成最终预测序列t
iend
;
46.步骤4)-9:统计所有三元组最终分数预测序列组得到score;
47.步骤4)-10:根据score计算指标mr,hit@10;
48.步骤4)-11:输出计算指标mr,hit@10;
49.步骤4)-12:结束状态;
附图说明
50.图1为本发明实施中的一种基于差分测试和嵌入模型的知识图谱评估方法的的流程图。
51.图2为图1中变异数据构造的流程图。
52.图3为图1中嵌入模型训练的流程图。
53.图4为图1中差分测试执行的流程图。
54.图5为图1中评估指标计算的流程图。
具体实施方式
55.为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
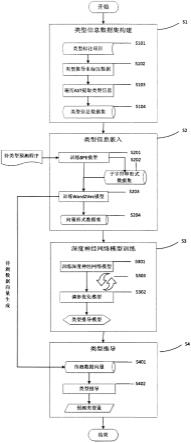
56.图1为本发明实施中的一种基于差分测试和嵌入模型的知识图谱评估方法的流程图。
57.一种基于差分测试和嵌入模型的知识图谱评估方法,其特征在于,包括下列步骤。
58.s1变异数据构造,给定初始训练集和变异算子集合,使用代表知识图谱典型错误的变异算子对训练集进行变异,初步变异得到的结果经过封闭世界假设的过滤和自动化打标签后输出可用的最终训练集。
59.s2嵌入模型训练,给定上一步输出的含有标签的训练集和初始嵌入模型集合,使用训练集对嵌入模型进行重训练。标注不同对模型的损失函数值要求不同,经过多个周期最后得到优化后的对变异数据所代表的典型错误敏感的嵌入模型。
60.s3差分测试执行,给定重新训练优化的知识图谱嵌入模型和被评估的知识图谱,对知识图谱数据集进行处理,再分别导入每个模型预测得到每个三元组的预测分数序列,再对序列进行排序和筛选,最后得到过滤后的三元组分数预测序列。
61.s4评估指标计算,给定过滤后的三元组分数预测序列,对三元组的在不同模型的分数预测序列进行rbo相似性度量,剔除与其他预测序列相差较大的序列,再对剩余序列进行投票重组,得到最终分数预测序列,最后通过最终预测序列计算知识图谱质量评估相关指标。
62.图2为变异数据构造的流程图。针对初始训练集里的每一个三元组,通过不同的变异算子构造出知识图谱常见的典型错误,从而实现变异数据构造的目的。具体步骤如下:
63.步骤1:起始状态;步骤2:输入初始训练集t和变异算子{m0,m1,m2,m3,m4,m5…
};步骤3:对t执行变异得到变异三元组集合n;步骤4:过滤n中的正确三元组并打true/false标签;步骤5:对si进行排序得到新三元组预测序列步骤6:输出过滤和打标签后的最终训练集t
mutation
;步骤7:结束状态。
64.图3为嵌入模型训练的流程图。以构造好的变异数据训练集为输入,对不同的初始嵌入模型进行重训练。将训练集数据输入并随机生成向量表示,计算嵌入模型所设计的损失函数,数据标签不同对损失函数的最终要求不同,经过多个周期训练后得到优化后的模型。对每个嵌入模型重训练后得到可用的优化嵌入模型集合。具体步骤如下:
65.步骤1:起始状态;步骤2:输入训练集t
mutation
和嵌入模型步骤3:从嵌入模型中选取模型mi
initial
;步骤4:随机生成三元组的向量表示并计算loss;步骤5:判断条件“循环次数《epoch”是否满足,若是则执行步骤2)-4,若否则执行下一步;步骤6:得到优化后的模型mi;步骤7:判断条件“遍历完所有模型”是否满足,若是则执行下一步,若否则执行步骤2)-3;步骤8:输出优化后的嵌入模型集合{m1,m2,m3,m4,m5…
};步骤9:结束状态。
66.图4为差分测试执行的流程图。以重训练优化后的知识图谱嵌入模型和被评估的知识图谱为输入,分别得到三元组的分数预测序列,再对序列进行排序筛选,得到过滤后的序列s
ifilter
。具体步骤如下:
67.步骤1:起始状态;步骤2:输入评估知识图谱g和模型{m1,m2,m3,m4,m5…
};步骤3:处理g的数据集得到entity序列,relation序列,triple序列;步骤4:计算每个模型对每个三元组的分数预测序列si;步骤5:对si进行排序得到新三元组预测序列s
inew
;步骤6:筛选s
inew
中排名前1000的三元组序列得到s
ifilter
;步骤7:输出筛选后的分数预测序列s
ifilter
;步骤8:结束状态。
68.图5为评估指标计算的流程图。以筛选后的分数预测序列s
ifilter
为输入,对其中三元组的不同模型分数预测序列两两进行相似性度量,剔除与其他序列差异较大的序列,再将剩余序列投票整合成最终预测序列t
iend
,最后根据此序列计算知识图谱质量评估相关指标。具体步骤如下:
69.步骤1:起始状态;步骤2:输入筛选后的分数预测序列s
ifilter
;步骤3:选择三元组
在不同模型预测序列两两计算相似性ni;步骤4:分别统计每个三元组统计所有相似性评估值得到相似性列表m;步骤5:计算相似性平均数n^;步骤6:统计相似性ni<n^预测序列的嵌入模型次数;步骤7:剔除出现最多的模型预测序列;步骤8:剩余序列投票合并成最终预测序列t
iend
;步骤9:统计所有三元组最终分数预测序列组得到score;步骤10:根据score计算指标mr,hit@10;步骤11:输出计算指标mr,hit@10;步骤12:结束状态。
70.综上所述,本发明解决了目前关于知识图谱质量评估相关方法和过程缺少的难题,进而帮助评估人员更加快速的对知识图谱质量进行了解,帮助评估人员在有限的时间完成知识图谱的质量评估。最终起到提高知识图谱数据质量、保障信息安全的目的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。