技术特征:
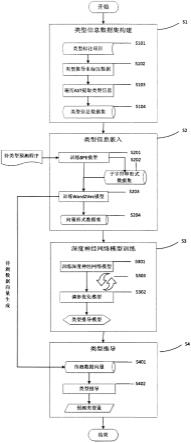
1.一种基于差分测试和嵌入模型的知识图谱评估方法,其特征在于,通过变异测试中的变异算子自动生成与知识图谱数据对应的错误数据,并利用错误数据重新训练已有的高效知识图谱嵌入模型kgem(knowledge graph embedding models),利用重训练优化的知识图谱嵌入模型{m1,m2,m3,m4,m5…
},将被评估的知识图谱g导入模型m
i
,进行差分测试得到三元组的分数预测序列对分数预测序列进行筛选。最后,利用相似性评估、投票重组,得到新的重组序列,再计算出有关知识图谱质量的相关指标;该方法包括以下步骤:1)变异数据构造。给定训练三元组集合t和变异算子集合mo={m0,m1,m2,m3,m4,m5…
};知识图谱中的数据一般使用三元组表示,故测试集中的数据也用三元组(h,r,t)表示,其中,h表示头实体,r表示关系,t表示尾实体。首先,对测试集t中的正确三元组rt
i
=(h
i
,r
i
,t
i
)执行mo中的某一变异算子m
j
,根据m
j
的所代表的典型错误不同对rt
i
进行不同的变换操作,获得不同的变异三元组mt
ij
=(h
ij
,r
i
,t
i
)或(h
i
,r
ij
,t
i
)或(h
i
,r
i
,t
ij
)。在此操作中某一变异算子对t中的每一个三元组都生成多个变异三元组。记所有变异三元组集合为n;接着,由于自动化生成的变异三元组中可能存在数据集已知的正确三元组,即可能存在h
ij
=h
k
或其他等价情况,故对获得的n
i
进行基于封闭世界假设(closed word assumption)的过滤操作,剔除n∩t的相交三元组获得错误变异三元组集合fn,并对剩下的错误变异三元组打标签为“false”,与原测试三元组集合t标签为“true”形成最终训练集t
mutation
。2)嵌入模型训练。给定待训练优化的知识图谱嵌入模型{m
1initial
,m
2initial
,m
3initial
,m
4initial
,m
5initial
…
}和包含ground truth标注的训练集t
mutation
。首先,将训练集t
mutation
中的三元组数据录入到嵌入模型m
iinitial
中,随机生成维度的向量来模拟训练数据三元组。其次,计算模拟数据的嵌入模型损失函数loss,对于标注为“true”的三元组loss
true
越小越好,标注为“false”的三元组loss
false
越大越好,通过梯度下降法不断更新随机生成的向量。最终,循环给定epochs,训练完毕得到对错误变异三元组敏感的嵌入模型集合。3)差分测试执行。给定重新训练优化的知识图谱嵌入模型{m1,m2,m3,m4,m5…
}和被评估的知识图谱g,对知识图谱g的数据集进行处理得到知识图谱g的实体序列entity,关系序列relation和三元组序列triple,再将序列entity、relation、triple分别带入模型{m1,m2,m3,m4,m5…
m
i
},得到每个模型对知识图谱g中每个三元组的分数预测序列s
i
:{t1:{p1,p2,p3,p4,p5…
p
i
},t2:{p1,p2,p3,p4,p5…
p
i
},
…
t
i
:{p1,p2,p3,p4,p5…
p
i
}},其中s
i
表示模型m
i
对知识图谱g的三元组分数预测序列,t
i
表示第i个三元组的分数预测序列,p
i
表示模型对三元组的第i个预测分数。得到每个模型的三元组分数预测序列s
i
后,再对每个三元组的分数预测序列t
i
进行排序,因为三元组分数预测越小越好,所以按照分数从小到大的顺序排序,得到新的三元组分数预测序列,s
inew
:{t1:{p1,p2,p3,p4,p5…
p
i
},t2:{p1,p2,p3,p4,p5…
p
i
}
…
t
i
:{p1,p2,p3,p4,p5…
p
i
}},其p1为三元组最小的预测分数。最后,根据得到已经排序的三元组分数预测序列s
inew
,对s
inew
中的每个三元组预测分数序列t
i
进行筛选过滤,选出t
i
中三元组预测分数在前1000名的预测结果,得到新的三元组分数预测序列:s
ifilter
:{t
1new
:{p1,p2,p3,p4,p5…
p
1000
},t
2new
:{p1,p2,p3,p4,p5…
p
1000
}
…
t
inew
:{p1,p2,p3,p4,p5…
p
1000
}}4)评估指标计算。给定每个模型对知识图谱g中三元组经过排序过滤后的分数预测序列s
ifilter
,利用rbo相似性度量每个三元组在每个模型的分数预测序列,具体操作为从两个模型分数预测序列s
ifilter
,s
jfilter
中提取三元组t
i
的预测序列t
iinew
:{p1,p2,p3,p4,p5…
p
1000
}和t
ijnew
:{p1,p2,p3,p4,p5…
p
1000
},t
ijnew
代表第i个三元组在第j个模型中的预测分数序列的
前1000名。序列相似性n
i
=rbo(t
iinew
,t
ijnew
,p),p为rbo算法的自定义参数,当每个模型关于三元组t
i
的预测序列都两两相似性计算后,得到相似性度量的指标序列m:{n1,n2,n3,n4…
n
n
},长度为n=i(i-1)/2,i为模型的数量。计算出指标序列后,再计算相似性度量指标平均数:数:记录相似性指标n
i
<n^的指标对应的两个模型,统计每个模型出现的次数,最后剔除统计出现次数最多的模型对应的三元组分数预测序列t
ijnew
,其预测结果与其他模型预测结果相差较大。最后,将剔除后第i个三元组剩余的预测序列{t
i1new
,t
i2new
…
t
i(j-1)new
,t
i(j 1)new
…
},重新投票合并成新最终预测序列,投票规则为:1:出现次数最多的预测分数三元组优先;2:当出现次数相同时,排名靠前的优先。得到三元组的最终预测序列t
iend
,对其他三元组进行同样的操作,最后得到,所有知识图谱g中所有三元组对应的分数预测序列组score:{t
1end
,t
2end
,t
3end
,t
4end
…
t
iend
},最后根据预测所有三元组分数序列score计算知识图谱质量相关指标mr,hit@10。2.根据权利要求1所述的基于差分测试和嵌入模型的知识图谱评估方法,其特征在于,在步骤1)中,利用变异算子对数据进行变异,给定三元组数据集合和变异算子集合,对每一个三元组执行集合中每一个代表知识图谱典型错误的变异算子,通过过滤和标注,从而得到有标注的变异训练集。3.根据权利要求1所述的基于差分测试和嵌入模型的知识图谱评估方法,其特征在于,在步骤2)中,使用带有标注的变异训练集对嵌入模型进行重训练。嵌入模型需要在计算损失函数时判别变异数据的标签true/false,并进行多个周期的训练最终得到优化后的对知识图谱典型错误敏感的嵌入模型。4.根据权利要求1所述的基于差分测试和嵌入模型的知识图谱评估方法,其特征在于,在步骤3)中,进行差分测试,给定被评估的知识图谱分别导入重训练优化后的知识图谱嵌入模型,生成每个模型对每个三元组的预测分数序列,再对每个序列进行排序筛选,从而得到过滤后的三元组分数预测序列。5.根据权利要求1所述的基于差分测试和嵌入模型的知识图谱评估方法,其特征在于,在步骤4)中,进行指标计算,给定过滤后的三元组分数预测序列,分别对三元组在每个模型中的预测序列,两两进行rbo相似性度量,剔除分数预测序列与其他序列相差较大的序列,再通过投票融合剩余分数预测序列的结果得到最终三元组的分数预测序列,最后通过三元组预测序列计算相关指标。
技术总结
本发明涉及知识图谱质量评估领域,提供一种基于差分测试和嵌入模型的知识图谱评估方法。该方法基于变异测试的思想,变异生成可代表知识图谱数据中典型错误的三元组,并将其作为输入重训练出对知识图谱典型错误敏感的优化嵌入模型。该方法还基于差分测试的思想,输入普通知识图谱数据获取不同优化嵌入模型的输出,根据相似性评估保证输出的一致性和有效性;从而可通过符合相似性评估的输出结果再使用投票策略,最终计算出符合实际的质量评估指标。本发明目的在于解决目前存在的知识图谱质量评估人工成本高,耗时长且缺失自动化评估方法和过程的难题,进而帮助评估人员快速地对知识图谱质量进行了解并在短时间内获取可靠的知识图谱评估结果。知识图谱评估结果。知识图谱评估结果。
技术研发人员:冯洋 孙静玉 谭嘉俊 刘子夕 陈振宇 徐宝文
受保护的技术使用者:南京大学
技术研发日:2022.01.17
技术公布日:2022/6/4
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。