1.本发明属于可视化技术领域,涉及一种基于主题挖掘和情感分析的微博舆情可视分析方法。
背景技术:
2.微博作为web2.0时代的标志性产物,具有重要的意义。微博是在广大社交网络中承载用户关系、分享和传播信息的平台。用户既是信息的接收者,也是信息的生产者和加工者,同时用户与用户间的交互使用户能更多地参与到信息的传播中。简单的收藏或点赞让用户成为了信息传播过程中的参与者。庞大的微博数据中不乏含有一些虚假、措辞激烈和言论不当的信息,同时也存在一些恶意引导舆论走向的用户,这使得微博监管人员不便于及时处理,也让普通用户在茫茫网络大海中不明真正的是非关系。如果微博管理员监管不当,让不实信息流入人群,会使得用户反响强烈,激起社会矛盾;如果用户相信了虚假信息,则让用户偏离了事实真相,同时会让事情的当事人成为网络暴力的受害者。所以对微博数据进行分析研究是当前亟需的问题。
3.面对这种挑战,微博可视化技术将微博中复杂的或者难以通过文字表达的内容和规律以视觉的形式表达出来,同时向人们提供与视觉信息进行快速交互的功能,使人们能够利用与生俱来的视觉感知的并行化处理能力快速获取大数据中所蕴含的关键信息。大数据分析是大数据研究领域的核心内容之一。想获得信息之中蕴含着的知识与智慧,就需要我们去挖掘数据背后隐藏着的信息。近年来,可视分析研究很大程度上也围绕着大数据的热点领域,例如互联网、社会网络、城市交通、商业智能、气象变化、安全反恐、经济与金融等。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种基于主题挖掘和情感分析的微博舆情可视分析方法,解决对现有微博舆情可视分析中缺乏舆情对比分析和对比可视化的问题,使用两次舆情期间的微博数据进行主题分类与话题提取,得出热点话题和主题演化情况。接着获取各时间段热点话题的微博评论,使用扩展词典和fasttext分类器进行多次情感分类,来挖掘人们对热点话题的情感趋势。最后,从多方面对两次舆情进行对比可视化,有效地帮助用户掌握并跟踪微博舆情,进行网络舆情监管,提前防范舆情高峰的发生。
5.为达到上述目的,本发明提供如下技术方案:
6.一种基于主题挖掘和情感分析的微博舆情可视分析方法,该方法包括以下步骤:
7.s1:研究数据的获取以及处理,具体分为确定需要爬取的微博账号,获取所研究微博账号在舆情期间的微博数据,提取所需研究字段,对获取的研究语料进行预处理;
8.s2:采用贝叶斯模型对微博数据进行主题分类,接着使用tf-idf特征提取和lda主题模型对分类好的语料进行文本主题挖掘;
9.s3:提取各时间段热点话题的微博评论,然后使用基于扩展词典的方法进行初步
情感分类;接着使用fasttext分类器进行二次情感分类,得到最终的分类结果;
10.s4:对前面得到的微博热点话题和情感趋势采用对比可视化的方法,从时间、空间、热度和用户属性多个层面上对两次舆情期间微博舆情进行可视分析。
11.可选的,所述s1中,确定需要爬取的微博账号是根据微博媒体的发文情况,选择包括人民网和人民日报有权威的账号。
12.可选的,所述s1中,对爬取的微博原始数据进行预处理,包括:去除停用词,去除标点,去除副词;
13.使用正则匹配,保留的数据包括微博的内容、作者、时间、点赞数、转发数、话题词和评论;
14.语料库包括话题词、内容、评论;之后将数据保存到新的csv文件中。
15.可选的,所述s2中,使用贝叶斯模型对预处理后的数据进行主题分类,主题类别根据舆情期间的微博分类决定;
16.朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立;具体操作为:
17.设每个数据样本用一个n维特征向量来描述n个属性的值,即:x={x1,x2,
…
,xn},假定有m个类,分别用c1,c2,
…
,cm表示;给定一个未知的数据样本x,即没有类标号,若朴素贝叶斯分类法将未知的样本x分配给类ci,则为:
18.p(ci|x)》p(cj|x)1≤j≤m,j≠i
19.根据贝叶斯定理:
20.由于p(x)对于所有类为常数,最大化后验概率p(ci|x)转化为最大化先验概率 p(x|ci)p(ci);如果训练数据集有许多属性和元组,设各属性的取值互相独立,从训练数据集求得先验概率p(x1|ci),p(x2|ci),
…
,p(xn|ci);
21.对一个未知类别的样本x,先分别计算出x属于每一个类别ci的概率p(x|ci)p(ci),然后选择其中概率最大的类别作为其类别。
22.可选的,所述s2中,对主题分类后的数据,使用tf-idf特征提取和生成,建立整个语料库的特征向量空间模型;
23.tf代表这一个词在一篇文档中出现的次数,idf代表这一个词在文档集中的多少篇文档中出现,由tf和idf相乘,得到一个具体的词对于一篇文档的重要程度;对每一篇文档的所有维度进行该文档的重要程度计算,生成每一篇文档的tf-idf特征向量。
24.可选的,所述s2中,lda算法利用语料库生成的特征向量空间模型建立主题模型,利用gibbs采样方法对所建立的主题模型进行计算,输出并存储主题-词矩阵;具体包括以下操作:
25.lda文档生成流程:
26.lda假设文档是由多个主题的混合产生的,每个文档的生成过程如下:
27.①
从全局的泊松分布参数为β的分布中生成一个文档的长度n;
28.②
从全局的狄利克雷参数为α的分布中生成一个当前文档的θ;
29.③
对当前文档长度n的每一个字都有;
30.(1)从θ为参数的多项式分布生成一个主题的下标zn;
31.(2)从θ和z共同为参数的多项式分布中,产生一个字wn;
32.lda的参数:
33.α:表示document-topic密度,α越高,文档包含的主题更多,反之包含的主题更少;
34.β:表示topic-word密度,β越高,主题包含的单词更多,反之包含的单词更少;
35.主题数量:主题数量从语料库中抽取得到,使用kullbackleiblerdivergence
36.score获取最好的主题数量;
37.主题词数:组成一个主题所需要的词的数量;
38.迭代次数:是的lda算法收敛的最大迭代次数。
39.可选的,所述s3中,在s2得到的微博数据中提取各时间段热点话题的微博评论,然后使用基于扩展词典的方法进行初步情感分类;接着使用fasttext分类器进行二次情感分类,得到最终的分类结果,来挖掘人们对热点话题的情感趋势。
40.可选的,所述s4中,舆情对比分析包括:主题演化趋势、微博热度、用户关注点和用户情感变化;通过地图、词云、折线图和散点图的可视化图元进行表达。
41.可选的,所述s4中,采用echarts可视分析技术,从多个维度分析两次舆情期间微博舆情的异同;具体包括以下操作:
42.探索微博主题演化趋势使用时间序列折线图、主题雷达图、时间序列堆叠图;
43.时间序列折线图用来展示舆情期间微博数量,间接说明舆情的发展状况和舆情,也间接表示每天各主题的总数,即主题总量的趋势;
44.主题雷达图表示2次舆情各主题数量对比,看出2次舆情主题上的异同;
45.时间序列堆叠图表示主题演化趋势,将微博数据分为4个阶段表示舆情期间的4个阶段进行主题演化的过程判断;
46.探索用户关注点设计热度散点图和时间线词云图;
47.用户情感分析采用总量环形饼图、时间序列情感图、热门评论词云图和用户地理信息情感分布图。
48.本发明的有益效果在于:
49.本发明在基于数据可视化的基础上,采用可视分析与主题分类,主题建模,情感分析相结合的思路,借助一定的可视化符号,对数据间的关系进行直观的展示,加深用户对微博数据中所蕴含的规律的理解。本发明数据具有一定的代表性,对主题分类得到的数据,加入时间维度,可以得到主题随时间演化的趋势;将主题分类后的微博数据在提取主题词,根据转发数等传播属性,分析热点话题随时间变化趋势。提取各时间段热点话题的微博评论,然后使用基于扩展词典的方法进行初步情感分类。接着使用fasttext分类器进行二次情感分类,最后根据热点话题对应的微博主题,挖掘人们对不同主题的情感趋势。探索微博主题演化趋势使用了时间序列折线图、主题雷达图、时间序列堆叠图,探索用户关注点而设计了热度散点图、时间线词云图,用户情感分析则采用总量环形饼图、时间序列情感图、热门评论词云图、用户地理信息情感分布图。从时间、空间、热度和用户属性等多个层面上对两次舆情期间微博舆情进行可视分析,发现两者舆情的异同,总结经验,如果今后遇到类似的重大卫生事件,可以提前防范舆情高峰的发生。
50.本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和
获得。
附图说明
51.为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
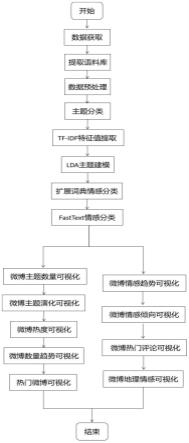
52.图1为本发明基于主题挖掘和情感分析的微博舆情可视分析方法的流程图。
具体实施方式
53.以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
54.其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
55.本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
56.请参阅图1,本发明提供的一种基于主题挖掘和情感分析的微博舆情可视分析方法,包括以下步骤:
57.s1:研究数据的获取以及处理,具体分为确定需要爬取的微博账号,获取所研究微博账号在舆情期间的微博数据,提取所需研究字段,对获取的研究语料进行预处理;
58.确定需要爬取的微博账号是根据微博媒体的发文情况,选择人民网,人民日报等有权威的账号。
59.对爬取的微博原始数据进行预处理,包括:去除停用词,去除标点,去除副词等;使用正则匹配,保留的数据包括微博的内容、作者、时间、点赞数、转发数、话题词、评论;语料库包括话题词、内容、评论;之后将数据保存到新的csv文件中。
60.s2:采用贝叶斯模型对微博数据进行主题分类,接着使用tf-idf特征提取和lda主题模型对分类好的语料进行文本主题挖掘。
61.使用贝叶斯模型对预处理后的数据进行主题分类,主题类别根据舆情期间的微博分类决定。
62.朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。也就是说没有哪个属性变量对于决策结果来说占有着较大的比
重,也没有哪个属性变量对于决策结果占有着较小的比重。虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。
63.具体包括以下操作:
64.设每个数据样本用一个n维特征向量来描述n个属性的值,即:x={x1,x2,
…
,xn},假定有m个类,分别用c1,c2,
…
,cm表示。给定一个未知的数据样本x(即没有类标号),若朴素贝叶斯分类法将未知的样本x分配给类ci,则一定是
65.p(ci|x)》p(cj|x)1≤j≤m,j≠i
66.根据贝叶斯定理
67.由于p(x)对于所有类为常数,最大化后验概率p(ci|x)可转化为最大化先验概率 p(x|ci)p(ci)。如果训练数据集有许多属性和元组,计算p(x|ci)的开销可能非常大,为此,通常假设各属性的取值互相独立,这样
68.先验概率p(x1|ci),p(x2|ci),
…
,p(xn|ci)可以从训练数据集求得。
69.根据此方法,对一个未知类别的样本x,可以先分别计算出x属于每一个类别ci的概率 p(x|ci)p(ci),然后选择其中概率最大的类别作为其类别。
70.对主题分类后的数据,使用tf-idf特征提取和生成,建立整个语料库的特征向量空间模型。
71.tf代表这一个词在一篇文档中出现的次数,idf代表这一个词在文档集中的多少篇文档中出现,由tf和idf相乘,得到一个具体的词对于一篇文档的重要程度;对每一篇文档的所有维度进行该文档的重要程度计算,生成每一篇文档的tf-idf特征向量:
72.feature-vector={f1,f2,f3……
,fn}
73.lda算法利用语料库生成的特征向量空间模型建立主题模型,利用gibbs采样方法对所建立的主题模型进行计算,输出并存储主题-词矩阵。具体包括以下操作:
74.lda文档生成流程
75.lda假设文档是由多个主题的混合产生的,每个文档的生成过程如下:
76.①
从全局的泊松分布参数为β的分布中生成一个文档的长度n
77.②
从全局的狄利克雷参数为α的分布中生成一个当前文档的θ
78.③
对当前文档长度n的每一个字都有
79.(1)从θ为参数的多项式分布生成一个主题的下标zn
80.(2)从θ和z共同为参数的多项式分布中,产生一个字wn
81.lda的参数
82.α:表示document-topic密度,α越高,文档包含的主题更多,反之包含的主题更少。
83.β:表示topic-word密度,β越高,主题包含的单词更多,反之包含的单词更少。
84.主题数量:主题数量从语料库中抽取得到,使用kullbackleiblerdivergence
85.score可以获取最好的主题数量。
86.主题词数:组成一个主题所需要的词的数量。这些词的数量通常根据需求得到。
87.迭代次数:是的lda算法收敛的最大迭代次数。
88.s3:在步骤s2得到的微博数据中提取各时间段热点话题的微博评论,然后使用基于扩展词典的方法进行初步情感分类。接着使用fasttext分类器进行二次情感分类,得到
最终的分类结果,来挖掘人们对热点话题的情感趋势。
89.fasttext的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层softmax分类。
90.s4:对前面得到的微博热点话题和情感趋势采用对比可视化的方法,从时间、空间、热度和用户属性等多个层面上对两次舆情期间微博舆情进行可视分析;
91.采用echarts可视分析技术,从多个维度分析两次舆情期间微博舆情的异同。具体包括以下操作:
92.探索微博主题演化趋势使用了时间序列折线图、主题雷达图、时间序列堆叠图。时间序列折线图用来展示舆情期间微博数量,间接说明舆情的发展状况和舆情,也间接表示每天各主题的总数,即主题总量的趋势。主题雷达图表示2次舆情各主题数量对比,可以看出2次舆情主题上的异同。时间序列堆叠图表示主题演化趋势,将微博数据分为4个阶段表示舆情期间的4个阶段进行主题演化的过程判断。探索用户关注点而设计了热度散点图、时间线词云图。热度散点图为了发现2次舆情微博热度前100分布情况,了解用户对舆情的关注度。添加词云视图来展示舆情各阶段热度前6的微博话题的具体信息。用户情感分析则时间序列情感图、热门评论词云图、用户地理信息情感分布图。时间序列情感图从另一个层面证明了环形饼图的结果。热门评论词云图使用时间线将各阶段用户评论内容直观地展示出来,并额外设计了不同颜色的词云表示评论的情感倾向。用户地理信息情感分布图展示舆情各阶段热度前50评论的用户地理信息数据对应的情感倾向。
93.最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
