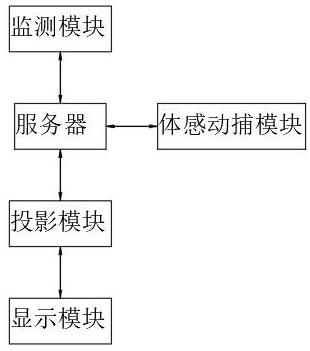
基于重构差异的oct指纹切面图像真伪检测方法
技术领域
1.本发明涉及生物特征识别、异常检测技术领域,具体应用于检测伪造oct指纹切面图像。
背景技术:
2.光学相干断层扫描技术(oct)的一大特点是可探得生物组织二维或三维结构图像。当应用在手指时,可以探得手指皮下信息,这除了可以用于重构指纹并识别之外,也提升了活体检测能力,具备一定程度上的防伪能力。不过,目前的基于oct的指纹识别系统,通常在采集完图像之后,需要人工参与进行判断图像的真实性,仍然缺乏一种高效、准确的自动辨伪方法。
3.伪造样本检测,是异常检测中的一项具体应用。近几年,异常检测领域中相关研究,更多的选用了深度学习方法,相比传统方法,其应用过程更简单、检测性能更佳。常规的神经网络分类模型,虽然取得了较好的真伪区分力,但是模型训练时需要正、负样本,两种样本数量得均衡,此外普遍为闭环模型,如果数据量增加,准确度又会下降,缺乏良好的泛化性。这些问题,无疑增添了许多训练成本。因此,一种只使用一类数据进行训练的想法出现了,也可以称作是单类别分类模型,目的是尽可能的只识别出参与训练的这种类别,而另外类别直接归为负类。目前普遍使用自动编码器、对抗生成网络等生成模型实现,根据重构差异程度来实现类别区别。但是直接将该种网络结构应用于伪造oct指纹切面图像检测上,效果并不理想,主要还是源于oct指纹切面图像并非自然图像,不做很好的预处理的话,存在大量的无关噪声、背景信息,影响最终的判别结果。
技术实现要素:
4.本发明要克服现有技术在oct指纹切面图像的辨伪上的缺点,提供一种简易、自动化且不需要大量复杂预处理的用于检测伪造指纹oct切面图像的方法。
5.本发明是基于oct指纹识别系统的一部分,属于图像质量判别部分,目的是在进行指纹识别之前便能把筛选出伪造指纹,提高识别正确性。
6.本发明的基本实现原理是仅使用正样本(真实手指b-scan图像)训练神经网络模型,由于模型只在正样本中训练,模型自学习到的是正样本数据分布状况,包括隐空间(latent space)和图像像素两者数据分布,模型只对正样本有很好的重构效果,该类样本经过编码器、解码器后生成的图像质量高,与输入图的差异也不大,拥有较小的重构差异,但若是负样本(仿体b-scan图像),则达不到上述效果。模型训练完成,输入图像若是负样本,由于重新复原出来的图像更像真实图像,所以和输入图像比较会表现出较大的差异,根据此点差异,可以设定阈值进行真伪判别。
7.其中,由于输入图像中存在的噪声会增加重构后两图在像素上的差异,所以只使用像素差异来作为衡量真假的标准是不准确的,而经过神经网络提取的特征,可以更多体现主要语义信息,一定程度上解决了这个问题,故本发明方法中的差异比较主要是从特征
向量层面上进行比较的。
8.本发明所提出的方法是基于重构差异的oct指纹切面图像辨伪方法,具体步骤为:
9.步骤s1、构建全卷积神经网络模型。该模型主体由编码器、生成器、特征提取器三部分组成,如附图说明图1所示。先由编码器获取输入图像在潜空间中的数据分布的特征图,然后再使用生成器从获取的数据分布中重新构造出与输入图像相似的图像。由于需要在特征空间进行相似度评估,但是解码器最终输出的特征图信息,特征耦合度仍然较高,而且原始图像中背景占据了较大部分,这使得特征中保留了相当大部分原始图像中的背景信息,难以直接作为图像的特征表示,用于后续特征比较,所以模型中又额外加入了特征提取器,即特征提取模块,来获取输入图像更具语义信息的特征表示,该部分使用resnet作为基本结构,为了能更准确定位到图像中感兴趣区域,减少背景内容干扰,加入了通道注意力模块以及空间注意力模块。
10.步骤s2:准备训练数据、测试数据。收集oct系统采集的图像,其中来源于不同个体真人手指的b-scan图像作为正样本图像,来源于不同仿制材料所制仿体的b-scan图像作为负样本图像,此外还需收集10张oct系统在不放置待测物体时的图像,只有背景的图像。不过由于部分原始采集图像存在质量欠佳问题,尤其是图像左右两侧无用信息过多,故需要在训练之前对图像进行增强处理。具体过程为:对原始尺寸1800*500的b-scan图像进行图像裁剪操作,分别裁去原始图像左右200像素,得到1400*500的b-scan图像,然后再对图像尺寸进行调整,使用双三次插值方法,将该裁剪后的图像大小缩放至需要的大小尺寸,实验中缩放至256*256并转换为灰度图像。在预处理方法后,仅从正样本图像中,随机选取70%的正样本图像作为训练数据。选取另外30%的正样本图像和负样本图像,数量均衡后作为测试数据。对10张只含背景的图像,进行数据增强扩充数量至100张,保存用于后续操作。数据增强具体方式包括:随机裁剪之后再重新调整成原来的大小、随机高斯模糊、随机翻转。
11.步骤s3、训练网络模型,整体训练流程可见附图说明图2。选用划分好的训练图像作为输入数据,每次加载数据,原始图像数据保存备份,再使用随机大小的黑色色块进行随机位置遮挡,遮挡操作后得到的图像数据记作x
′
,先后经过编码器e(*)、生成器g(*)得到对应重新构造出来的图像,记作g(e(x
′
))。计算重构图和输入原始未遮挡图在像素点上差异度,期望差异值尽量小,使得生成图分布尽量逼近原始输入图,使用l1 loss平均绝对误差,记作重构误差l
recon
,计算方式如下:
12.l
recon
=||g(e(x
′
))-||x||1ꢀꢀꢀꢀ
(1)
13.其中,x表示原始输入图像的数据分布状况,g(e(x
′
))表示经由网络模型后重构复原出图像的数据分布状况。该损失函数仅应用于编码器和生成器部分,用以提升图像重构质量。
14.为了缓解特征提取器训练后期可能存在的过拟合问题,提升模型鲁棒性,可以使用简单的数据增强操作对数据进行扩增。需要对x和g(e(x))做垂直翻转,得到对应增强后的图像数据x^、g(e(x))^,将未增强和增强后的数据共计4组数据输入到特征提取器中,获取到的特征向量作为正特征向量,记作z
pos
,同时随机选取同样数量,在步骤s2中准备的增强后的背景图像数据,送入特征提取器中,该部分获得的特征向量作为负特征向量,记作z
neg
。先从z
pos
中选取一正特征向量作为锚点,记作zo,依次和同批次中另一种特征向量成对组合,在这些组合中,锚点和正特征向量组成的配对组合称为正数据对,而和负特征向量组
成的配对组合称为负数据对,假设总特征向量数为m,经过上述组合操作可得3组正数据对,m-4组负数据对,合计m-1组。之后依次选取剩余的正特征向量,重复上述操作。
15.目标期望正数据对相似度高,而期望负数据对相似度低。数据对中的两向量的相似度由余弦相似度计算体现,其值越接近于1,表示两向量越相似,具体如下式所示:
[0016][0017]
其中,s(a,b)表示为向量za与向量zb数据对的余弦相似度,*
t
表示向量转置,||*||表示向量的模长,γ为尺度参数,用于调整余弦相似度原始[-1,1]范围。
[0018]
确定相似度衡量标准之后,设定对比损失函数l
con
,该损失函数在定义上类似于softmax-交叉熵损失函数,在损失函数优化的过程中,逐渐提高正数据对相似度的占比,从而实现特征提取器部分的学习目标:正数据对相似度最大化,负数据对相似度最小化。先计算其中一种锚点组成的正数据对在所有含该锚点组合中的占比,目标期望该占比越大越好,所以损失函数需要再取负号,如下式所示:
[0019][0020]
其中,l
con_anchor_n
表示以第n个正特征向量为锚点的正数据对的平均损失值,m为含锚点z
o_n
的正数据对总数量,s(z
o_n
,z
pos_i
)表示第i个含锚点z
o_n
的正数据对的余弦相似度,n为含锚点z
o_n
的负数据对总数量,s(z
o_n
,z
neg_j
)表示第j个含锚点z
o_n
的负数据对的余弦相似度。
[0021]
接着,计算剩余锚点组合的损失值,同样依次进行上述计算,最后对所有锚点组合取得的损失值进行求和平均操作,得到特征提取器部分最终对比损失l
con
。
[0022][0023]
其中,n为锚点总数量,该损失函数仅应用于特征提取器部分。
[0024]
设定好损失函数后,对所建网络模型进行多轮次训练,通过反向传播,对模型权重参数进行更新优化,直到损失函数趋向收敛时,可以停止训练。
[0025]
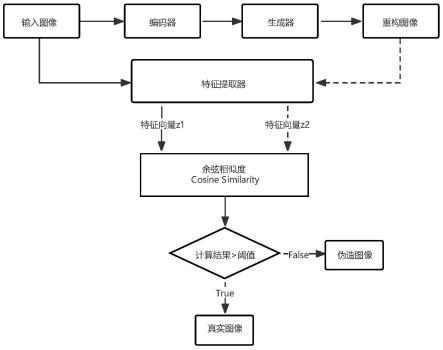
步骤s4、测试网络模型,整体测试流程可见附图说明图3。选用划分好的测试数据作为输入数据,记作x,进行测试,测试过程类似于步骤s3训练过程,x经过编码器e(*)、生成器g(*)得到对应重新构造出来的图像,记作g(e(x)),输入特征提取器中,同样使用余弦相似度计算x、g(e(x))对应特征向量z1、z2的相似度并保存,通常来说正样本的相似度普遍会是高值,负样本普遍会是低值。紧接着根据所有测试数据的余弦相似性计算结果,绘制roc曲线,综合准确率、误检率、漏检率设定合适的阈值。设定只要余弦相似性计算高于阈值,可以认定是真实手指图像,反之则认定是仿制手指图像。
[0026]
本发明的优点是:
[0027]
本发明所提出的网络模型,相比常规用于防伪的神经网络模型——一种典型二分类网络模型,模型训练需要真、假两类数据均衡,而本发明仅需使用一个类别的数据再增添少量的补充数据即可,在实际应用中使用真实手指b-scan图像作为主训练数据,b-scan背景图像作为补充数据,有效降低了网络模型样本训练成本。
[0028]
本发明所网络模型提出的特征提取器中,使用通道、空间注意力机制,一点程度上
减少了背景信息对所提特征的干扰。使用对比损失函数,使正正样本更贴近、正负样本更疏远,提升正负样本特征区分度,具有良好的泛化性。
[0029]
本发明所提出的模型是一种端到端的模型,不需要复杂的预处理,不需要保存标准正样本的特征向量,使用训练好的模型,输入一张常规oct切面图像,根据输入图像和重构图像在特征向量上的差异度,即可判断该图像的真伪。
附图说明
[0030]
图1a~图1c是本发明神经网络模型结构图,其中图1a是编码器、生成器网络结构,图1b是特征提取器网络结构图,图1c特征提取器注意力模块图;
[0031]
图2是本发明检测模型的训练流程图;
[0032]
图3是本发明检测模型的测试流程图;
[0033]
图4a~图4b是本发明实验中正样本输入以及对应模型重构出图像,其中图4a是输入图像,图4b是重构图像;
[0034]
图5a~图5b是本发明实验中负样本输入以及对应模型重构出图像,其中图5a是输入图像,图5b是重构图像。
具体实施方式
[0035]
为了更加清晰明确地表述本发明的目的、技术方案和优势,下面对本发明的具体实施方案进行详细描述。
[0036]
本发明是一种基于重构差异的oct指纹切面图像真伪检测方法,构建了全卷积神经网络模型,包括了编码器、生成器、特征提取器三个部分,其中编码器、生成器部分用于重构图像。重构图像与正样本表现出较小的重构差异,而面对负样本时,会表现出较大的差异。考虑到直接从像素层面上体现差异不准确,编码器的特征编码耦合度较高,故设置特征提取器,在其中加入了通道注意力以及空间注意力模块,用以提取图像更具语义信息的特征表示。使用余弦相似度,评估原始输入图像和重构图像经由特征提取器后的特征相似度,其计算结果低于设定阈值即可判定为伪造图像。
[0037]
本发明的基于重构差异的oct指纹切面图像真伪检测方法,包括如下步骤:
[0038]
步骤s1、构建全卷积神经网络模型。该模型主体由编码器、生成器、特征提取器三部分组成,如附图说明图1所示。先由编码器获取输入图像在潜空间中的数据分布的特征图,然后再使用生成器从获取的数据分布中重新构造出与输入图像相似的图像。由于输入图像中存在的噪声会增加重构后两图在像素上的差异,所以只使用像素差异来作为衡量真假的标准是不准确的,而经过神经网络提取的特征,可以更多体现主要语义信息,一定程度上解决了这个问题。由于需要在特征空间进行相似度评估,但是解码器最终输出的特征图信息,特征耦合度仍然较高,保留了原始图像中背景信息,难以直接作为图像的特征表示,用于后续特征比较,所以此外又额外加入了特征提取模块,来获取输入图像更具语义信息的特征表示,该部分使用restnet作为基本结构,为了能更准确定位到图像中主要区域,减少背景内容干扰,加入了通道注意力模块以及空间注意力模块。
[0039]
1)编码器。
[0040]
先使用8个大小f=3*3的卷积核,设定步长s=1,四周填充padding=1进行卷积操
作,保持图像尺寸大小,将输入图像通道数扩大至8通道。
[0041]
紧接着使用5层下采样卷积层,每层设定卷积核大小f=3*3,步长s=2,四周填充padding=1,使用instance normalization进行标准化。每经过这样的卷积层后,图像尺寸缩小一倍,通常设定输出通道数也即特征图数量为原来通道数的两倍。假定输入到第一个下采样卷积层的输入大小为batchsize*channel*width*height,其中batchsize为每一训练批次的数量,channel为通道数量,width为图像宽度,height为图像高度。模型中总共使用了5层下采样卷积层,因此到最后一层时,输出大小应该为batchsize*(channel*32)*width/32*height/32,即得到channel*32个尺寸大小为缩放32倍后的特征图。
[0042]
2)生成器。
[0043]
该部分由5层上采样层组成,其中上采样层由两部分组成,包含两个过程:使用upsample函数进行上采样,将特征图尺寸扩大一倍。再使用大小f=3*3的卷积核,设定步长s=1,四周填充padding=1进行卷积操作,调整输出通道数,通常设定输出通道数减半。整个上采样复原图像的过程,类似于编码器的逆向过程。其中第一个上采样层的输入来源于编码器主支中的最后一层输出,每经过一次,通道(特征图)数量缩小一倍,同时特征图的尺寸扩大一倍。经过5次类似过程输出大小即可恢复到输入图像大小,不过此时通道数为8,仍需要最后再使用一次卷积调整大小通道数为1,即得到了复原的图像,由此实现了从提取的特征中重新复原出图像。
[0044]
3)特征提取器。
[0045]
使用resnet网络结构,本发明在其中加入通道、空间注意力机制,通道注意力的生成方式:对特征图在空间维度进行全局最大池化和全局平均池化得到两个c*1*1向量,再进行相加,用sigmoid激活函数归一化,得到最终的通道权重矩阵。空间注意力的生成方式:特征图在通道维度上进行最大池化和平均池化,得到两个大小为1*w*h特征图,使用7x7卷积保持特征图尺寸不变,融合成一个特征图,sigmoid归一化,得到最终的空间权重矩阵。每经过一层卷积,特征图都需依次和对应通道、空间权重矩阵加权。
[0046]
步骤s2:准备训练数据、测试数据。收集oct系统采集的b-scan(切面)指纹图像,其中b-scan图像,包括20组的真人手指b-scan图像和10组的仿体b-scan图像,每组图像各400张图像,来源于不同个体、不同仿制材料。此外还需收集10张oct系统在不放置待测物体时的图像,即只有背景的图像。不过由于部分原始采集图像存在质量欠佳问题,尤其是图像左右两侧无用信息过多,故需要在训练之前对图像进行增强处理。具体过程为:对原始尺寸1800*500的b-scan图像进行图像裁剪操作,分别裁去原始图像左右200像素,得到1400*500的b-scan图像,然后再对图像尺寸进行调整,使用双三次插值方法,将该裁剪后的图像大小缩放至需要的大小尺寸,实验中缩放至256*256并转换为灰度图像。在预处理方法后,仅从20组真人手指b-scan图像中,随机选取10组真人手指b-scan图像作为训练数据。选取另外10组的真人手指b-scan图像和10组的仿体b-scan图像作为测试数据。对10张只含背景的图像,进行数据增强扩充数量至100张,保存用于后续操作。数据增强具体方式包括:随机裁剪之后再重新调整成原来的大小、随机高斯模糊、随机翻转。
[0047]
步骤s3、训练网络模型,整体训练流程可见附图说明图2。选用划分好的训练图像作为输入数据,每次加载数据,原始图像数据保存备份,再使用随机大小的黑色色块进行随机位置遮挡,遮挡操作后得到的图像数据记作x
′
,先后经过编码器e(*)、生成器g(*)得到对
应重新构造出来的图像,记作g(e(x
′
))。计算重构图和输入原始未遮挡图在像素点上差异度,期望差异值尽量小,使得生成图分布尽量逼近原始输入图,使用l1 loss平均绝对误差,记作重构误差l
recon
,计算方式如下:
[0048]
l
recon
=||g(e(x
′
))-x||1ꢀꢀꢀꢀ
(1)
[0049]
其中,x表示原始输入图像的数据分布状况,g(e(x
′
))表示经由网络模型后重构复原出图像的数据分布状况。该损失函数仅应用于编码器和生成器部分,用以提升图像重构质量。
[0050]
为了缓解特征提取器训练后期可能存在的过拟合问题,提升模型鲁棒性,可以使用简单的数据增强操作对数据进行扩增。需要对x和g(e(x))做垂直翻转,得到对应增强后的图像数据x^、g(e(x))^,将未增强和增强后的数据共计4组数据输入到特征提取器中,获取到的特征向量作为正特征向量,记作z
pos
,同时随机选取同样数量,在步骤s2中准备的增强后的背景图像数据,送入特征提取器中,该部分获得的特征向量作为负特征向量,记作z
neg
。先从z
pos
中选取一正特征向量作为锚点,记作zo,依次和同批次中另一种特征向量成对组合,在这些组合中,锚点和正特征向量组成的配对组合称为正数据对,而和负特征向量组成的配对组合称为负数据对,假设总特征向量数为m,经过上述组合操作可得3组正数据对,m-4组负数据对,合计m-1组。之后依次选取剩余的正特征向量,重复上述操作。
[0051]
目标期望正数据对相似度高,而期望负数据对相似度低。数据对中的两向量的相似度由余弦相似度计算体现,其值越接近于1,表示两向量越相似,具体如下式所示:
[0052][0053]
其中,s(a,b)表示为向量za与向量zb数据对的余弦相似度,*
t
表示向量转置,||*||表示向量的模长,γ为尺度参数,用于调整余弦相似度原始[-1,1]范围。
[0054]
确定相似度衡量标准之后,设定对比损失函数l
con
,该损失函数在定义上类似于softmax-交叉熵损失函数,在损失函数优化的过程中,逐渐提高正数据对相似度的占比,从而实现特征提取器部分的学习目标:正数据对相似度最大化,负数据对相似度最小化。先计算其中一种锚点组成的正数据对在所有含该锚点组合中的占比,目标期望该占比越大越好,所以损失函数需要再取负号,如下式所示:
[0055][0056]
其中,l
con_anchor_n
表示以第n个正特征向量为锚点的正数据对的平均损失值,m为含锚点z
o_n
的正数据对总数量,s(z
o_n
,z
pos_i
)表示第i个含锚点z
o_n
的正数据对的余弦相似度,n为含锚点z
o_n
的负数据对总数量,s(z
o_n
,z
neg_j
)表示第j个含锚点z
o_n
的负数据对的余弦相似度。
[0057]
接着,计算剩余锚点组合的损失值,同样依次进行上述计算,最后对所有锚点组合取得的损失值进行求和平均操作,得到特征提取器部分最终对比损失l
con
。
[0058][0059]
其中,n为设定的锚点总数量,该损失函数仅应用于特征提取器部分。
[0060]
设定好损失函数后,对所建网络模型进行多轮次训练,通过反向传播,对模型权重
参数进行更新优化,直到损失函数趋向收敛时,可以停止训练。
[0061]
步骤s4、测试网络模型,整体测试流程可见附图说明图3。选用事先划分好的测试数据作为输入图像,同样分批次测试,每次从中随机选取20张图像数据,即每批次大小20*1*256*256,记作x,进行测试,测试过程类似于步骤s3训练过程,x经过编码器e(*)、生成器g(*)得到对应重新构造出来的图像,记作g(e(x))(实验过程中的部分重构图像可见附图说明图4、图5),输入特征提取器中,同样使用余弦相似度计算x、g(e(x))对应特征向量z1、z2的相似度并保存,通常来说正样本的相似度普遍会是高值,负样本普遍会是低值。紧接着根据所有测试数据的余弦相似性计算结果,绘制roc曲线,综合准确率、误检率、漏检率设定合适的阈值。设定只要余弦相似性计算高于阈值,可以认定是真实手指图像,反之则认定是仿制手指图像。
[0062]
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。